卡内基梅隆大学王建:一种新型光幕传感器在机器人避障和无人驾驶中的应用 | AI 研习社 80 期大讲堂总结

AI 研习社按: 以 LIDAR 为代表的 3D 传感器经常用于今日的道路场景理解中。在 GPS 与 IMU 的帮助下,我们将大量捕获的点云注册到预先构建的 3D 地图上,再通过复杂、计算量大且存储密集的深度学习方法来检测与分割运动中的障碍物。这些方法已经被证明是有效的,但是对于一些简单的问题如「一个物体切入我的车道吗?」或者「人行道上有人吗?」,这些计算却是不必要的。
因此,嘉宾的团队提出了一种替代解决方案——「可编程光幕」传感器(light curtain sensor),该解决方案几乎不需要增加任何开销,同时还能具有高能效与灵活性等特点。在本次公开课中,嘉宾将分享关于这个光幕传感器的设计思路与实际应用效果。
分享嘉宾:
王建,Snap 公司 Research Scientist,卡内基梅隆大学博士,导师是 Aswin Sankaranarayanan 教授和 Srinivasa Narasimhan 教授,主要研究方向为计算机视觉,三维视觉,计算摄影等。其研究工作曾在 CVPR、ICCV、ECCV、ICCP 等发表并且多次获得 oral presentation 机会。
公开课回放地址:
http://www.mooc.ai/open/course/561?=Leiphone
分享主题:一种新型光幕传感器 Light curtain sensor 在机器人避障和无人驾驶中的应用
分享提纲:
传统 3D 传感器。
提出的光幕传感器的原理。
传感器设计和优化
展示大量实验结果
雷锋网 AI 研习社将其分享内容整理如下:
我们先看一下我们已经熟悉的一种电梯里的 light curtain。电梯门的两边装有传感器,一边是红外发射器,一边是红外接收器。当有人或物体在电梯门之间阻挡了红外接收器对红外光的接收,电梯会立马知道,从而知道是否可以关门。Light curtain 在工业界有很多应用。比如自动化工厂里,在机器的周围会装有这种 safety light curtain——当工人接近时,传感器感知到,可以通知机器关闭。
接下来讲一下我们提出的传感器。以前的电梯里的 light curtain 传感器可以看成由一个线光源和线阵 sensor 构成,并且 light source 和 sensor 是面对面的。
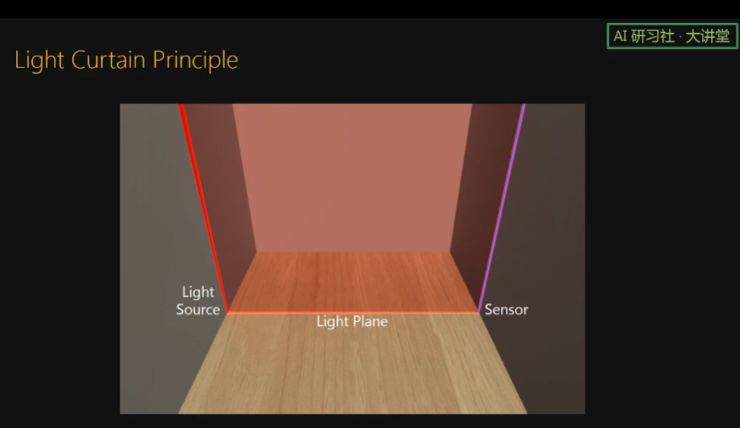
我们提出的传感器是把 light source 和 sensor 放在同一边。Light plane 和 imaging plane,两个平面交于一条线。当这条线上没有物体时,相机没有任何读数,图像是黑的。当有物体时,相机的读数就是非0,传感器可以立马感知到物体的存在。通过同时旋转 light plane 和 imaging plane,我们可以扫描空间中的任何一个平面。

通过改变 light plane 和 imaging plane 的相对旋转速度,我们也可以扫描空间中的一个圆柱面。
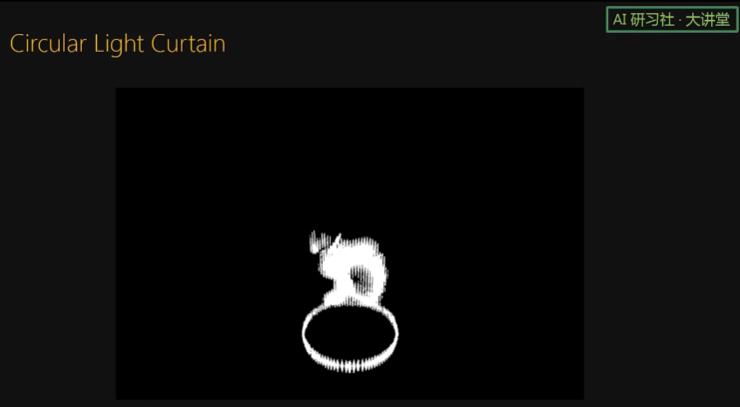
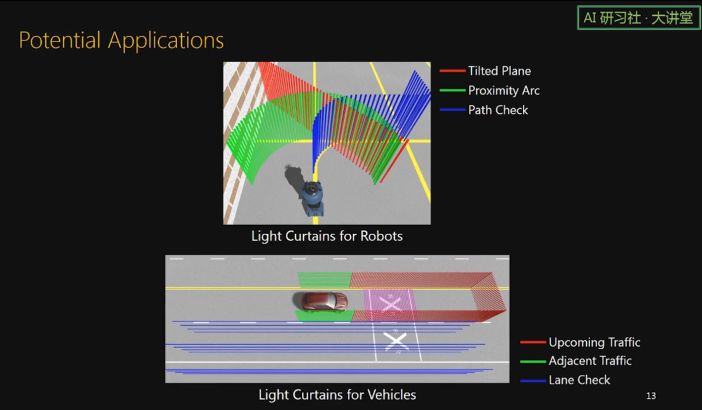
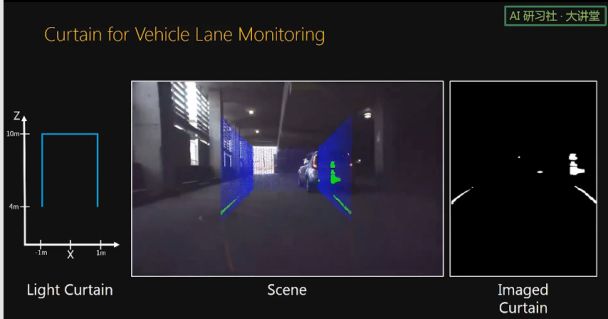
由于我们传感器的成本很低,一个机器人或者无人车上面可以搭载好几个这样的传感器。并且各个传感器可以扫描不同的曲面来达到不同的监控目的。比如这个机器人上面可以有我们的传感器,用来监测一个 tilted plane,一个圆柱面,或者看前进路线上有没有障碍物。无人车上面有监测前方的 curtain,有监测车两边的 curtain,也有监测路面的 curtain.
现在的无人车基本都装载 LIDAR 传感器。通过 LIDAR 可以得到 3D 点云,然后通过对点云进行处理来知道车前方是否有行人和车辆。我们认为,如果只是单纯的想知道车前方几米处是否有障碍物,完全可以用我们的传感器来解决,并且我们的传感器很便宜,计算复杂度也非常低,只需要一个 thresholding 就可以了。
这个动画展示了使用我们传感器的一个场景。一辆汽车上搭载了好几个传感器。有一个前方的 curtain 一直监控前方道路上有没有别的车。当车要换道时,首先打开侧边的 curtain,看测道上是否有别的车。当车要转弯时,注意 curtain 可以根据车速动态变化。当有雾来临时,由于我们的 light curtain 可以看透烟雾,可以在这时打开路面 curtain,由此看到地面上的铁路标志。
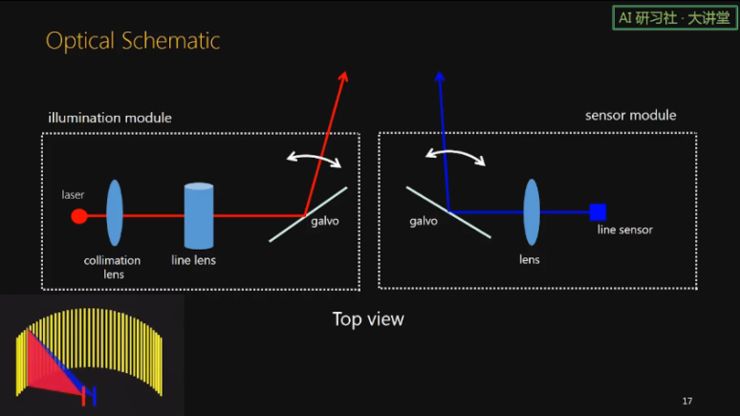
接下来看一下我们的硬件实现。这里显示了我们传感器的光路。左边是线光源,右边是线相机。左边线光源部分,首先是一个点激光,然后经过 collimation lens 和 line lens 变成一条线,再使用一个一维振镜来转动这个光平面。右边线相机部分,首先是 line sensor,然后是成像物镜,再是一个一维振镜来扫描看的角度。
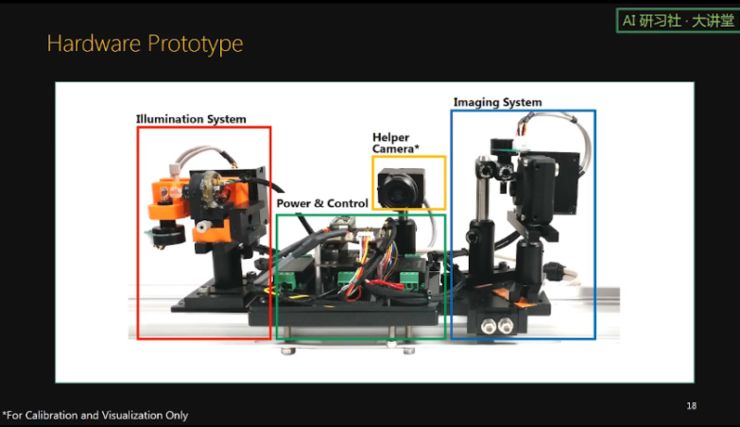
这里展示了我们做的 hardware prototype. 左边是线激光部分,右边是线相机部分,中间是 power 和控制电路,还有一个 2d helper 相机,只是用来标定和更方便的展示检测结果用。
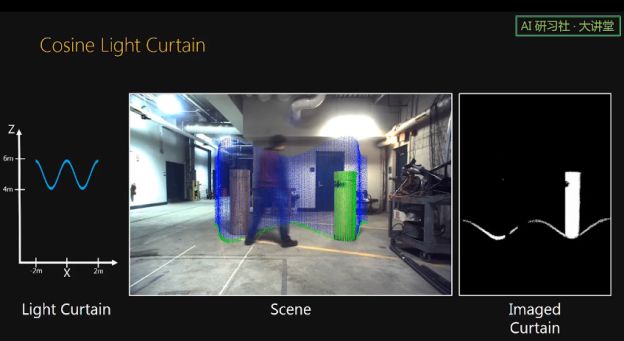
接下里我们用实际实验来展示我们传感器的扫描的 light curtain 形状的可编程性。
这里通过控制 line laser 和 line sensor 的相对旋转速度,传感器扫描出了 cosine 形状的 light curtain。中间的视频来自于 2D helper camera,图中的蓝色部分是我们预设的 curtain,绿色是检测到的结果,右边的视频则是来自线相机的原始读数。我们可以看到,当物体或人出现在预设的 curtain 上时,它们很容易被检测出来。
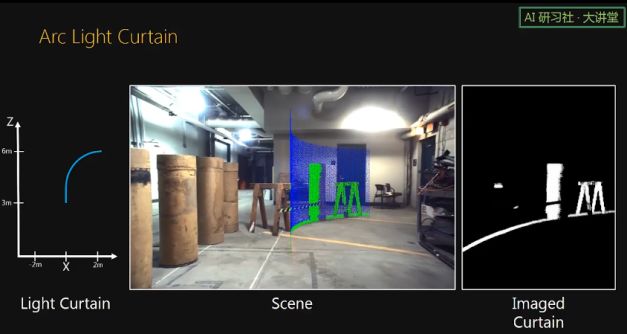
这个是机器人使用 Arc light curtain 来寻找前方可行的道路。
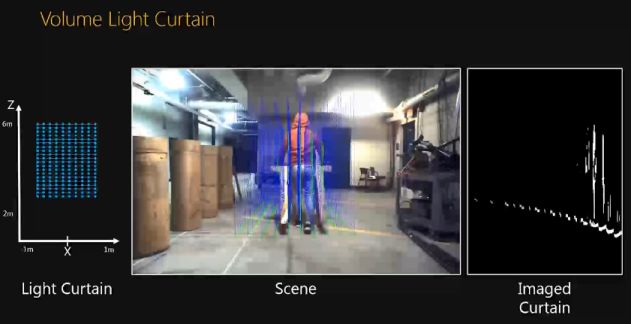
这里使用 volume light curtain 来监测一个空间。这个 volume light curtain 由很多离散的线组成。
这是车库使用 light curtain 来监测车库里汽车的情况。
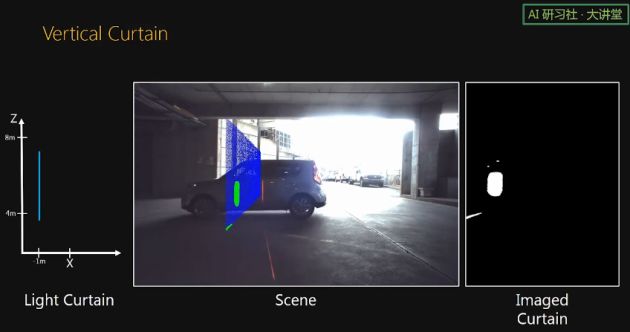
这是搭载在汽车上的 curtain,来监测前方道路情况。
这是 tilted curtain 来监测一个机器人。

接下来我们看一下我们传感器在强烈太阳光下的表现。 对于主动打出光的设备,户外能否工作是非常有挑战性的。因为太阳光是个非常大的噪声源,强烈的太阳光的光子噪声会将主动光设备打出的光淹没。这也是为什么 Microsoft Kinect 不能在户外工作的原因。

一个有效的方法是:将主动光聚集起来,然后扫描。这里有主动光设备可选的三种机制,第一个是像 Microsoft Kinect 那样,光就这么发散着打到空间中;第二个是将光聚集到一条线上,然后使用一维振镜进行一维扫描,这也是我们的传感器使用的方案;第三个是将所有光聚集到一个点上,然后使用二维振镜进行扫描。从信噪比上看,第二种机制比第一种机制,也就是 Microsoft Kinect 使用的机制增加了 N 倍, N 可以认为是 1000. 第三种机制的信噪比提高了 N^2 倍。从帧率的角度看,第一种是最快的,但是它没法在太阳光下面工作。第三种尽管信噪比很高,速度超级慢。第二种,也就是我们使用的机制,既有较高的信噪比保证可以在阳光下使用,又有较快的帧率。

这里展示的是一个 sidewalk curtain 。当有行人从路边走到路上时,我们的传感器很容易的将其检测了出来。
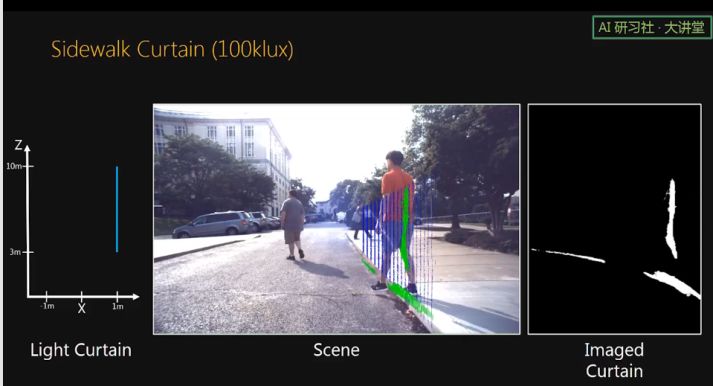
这里我们使用 volume light curtain 来监测人行道。

在强烈的太阳光下,我们的传感器依然可以看到 25m 外的白板,35m 外的白板也依稀可见。
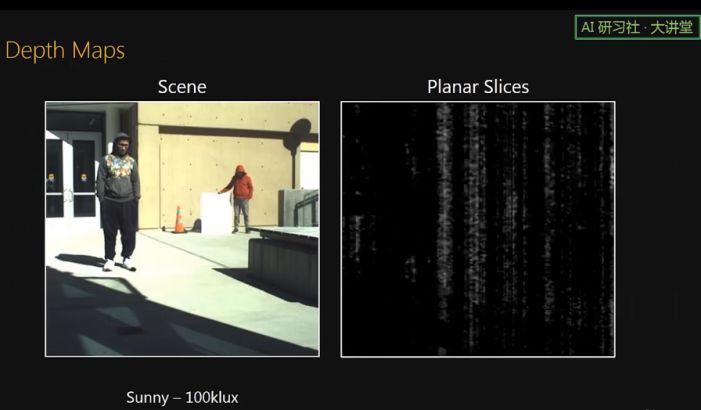
对于一般反射率的物体,我们的传感器可以看到 13m 远。这里我们通过 sweeping 40 个 planar curtains 来合成一个 depth map。需要注意的是,我们的传感器一般不用做 depth sensor,而只是用作 half depth sensor,就是只是监测空间中某个预设的 depth,所以更准确的讲,是一个 proximity sensor。
接下来我们看下我们的传感器在散射介质,比如烟雾中的表现。
在烟雾中,如果使用传统的成像,那就是有一个光源,然后有一个 2D 相机。相机中的每个像素除了接收到物体反射的光之外,还接收到在烟雾媒介中散射的光。这些散射的光中既有散射一次的,也有散射多次的。
在我们 light curtain 成像中,我们线激光打出去,线相机接收,对于线相机上的每个像素,它除了接收到物体反射的光外,也会接收到烟雾媒介散射的光,但是在媒介中只散射一次的散射光是进不来的,也就是在光路中就被隔离掉了。相较于传统的成像,我们的成像隔离掉了只散射一次的散射光,而只散射一次的散射光的强度要比散射多次的光强很多倍。由此,我们的传感器成的像的对比度要比传统的成像高很多。
这是我们的传感器在烟雾中的表现。中间的视频是普通的相机得到的,右边是我们的传感器得到的。当有烟雾时,通过我们的传感器依然能看到路牌,但是普通的相机就看不到了。

接着我们来讨论下 light curtain 的厚度问题。
由于相机的像素是有大小的,一般是几个微米;线激光也是有厚度的,一般也有几个微米到几十微米;triangulation 的结果就不是一个点,而是一个四边形。我们把这个四边形的纵深称为 triangulation uncertainty. 由于 Triangulation uncertainty 的存在,原本我们设定在 3.8 米处的 planar curtain,变成了一个有一定厚度的 curtain。所以当面对的是楼梯这个场景时,有三个楼梯被检测到。
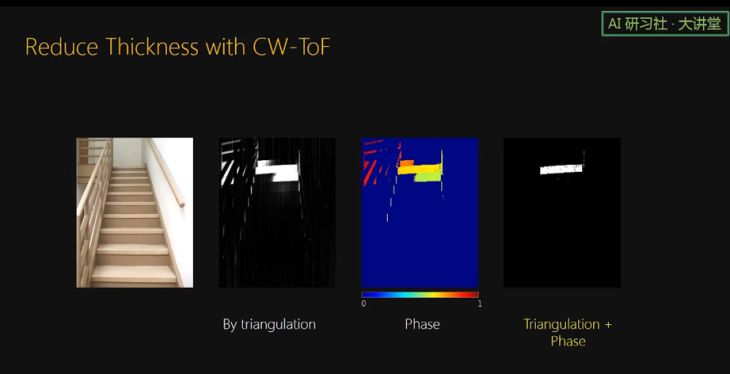
在一些情况下 curtain 有点厚有些好处,比如可以预防漏检。但是在一些情况下,我们也希望 curtain 越薄越好,比如我们只想检测车子左边 2 米处有没有物体,超过 2 米的我们不关心,如果 curtain 比较厚,就很可能会出现虚警。
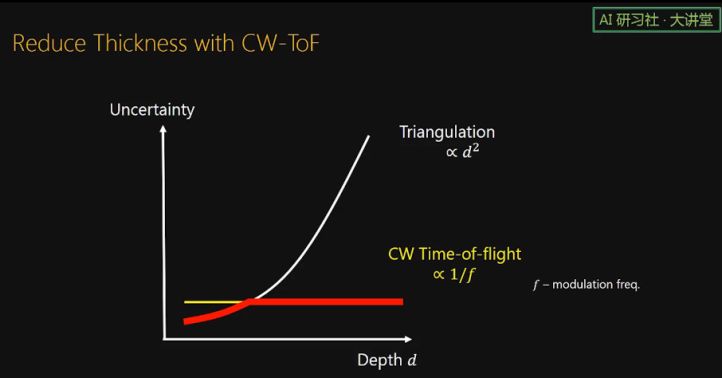
根据理论推算,triangulation uncertainty 是跟深度的平方成正比的。这说明 curtain 会随着深度的增加越来越厚。怎么降低 curtain 的厚度呢?我们提出在相机端使用 line TOF sensor。根据理论推算,我们知道 continuous wave TOF 的 uncertainty 只跟调制频率有关,频率越高,uncertainty 越小,是不随深度变化的。
所以,当在相机端使用 TOF 时可以取 triangulation 和 TOF 两个 uncertainty 的最小值,这样 uncertainty,也就是厚度,可以一直比较低。
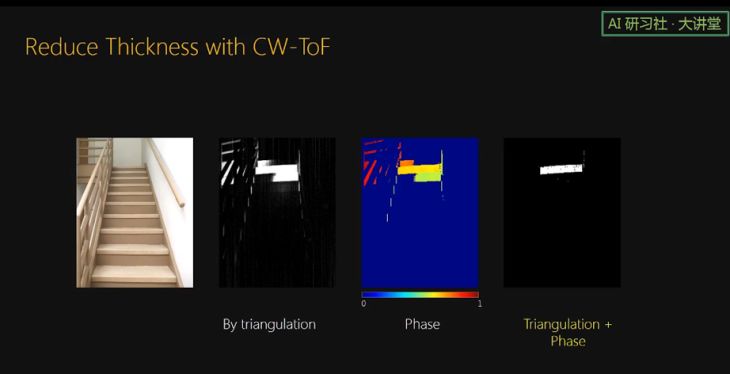
对于楼梯这个场景,当只使用 triangulation 时,有三个楼梯被检测到。当结合 TOF 的 phase 信息时,那么厚的 curtain 变得很薄,所以只有一个楼梯亮了。
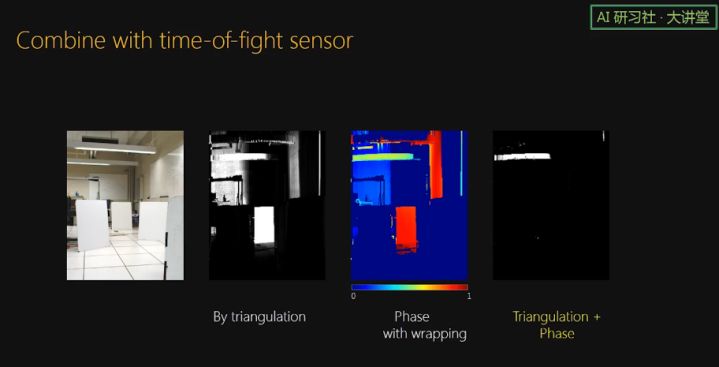
要想 TOF 的 uncertainty 比较小,TOF 使用的频率就得比较高,但是当面对较大的场景时,TOF 会出现 phase wrapping 的问题。巧的是,Triangulation 可以和 phase 相结合,triangulation 可以帮助做 phase unwrapping。这是因为虽然 triangulation 的 uncertainty 比较高,但也提供了一定的深度信息。所以依然可以得到非常薄的 curtain。
接下来讲一下 depth-adaptive imaging. 主动光系统一般都会面临 light fall off 的问题。主动光系统发出的光会随着深度逐渐减弱,这使得近处的物体的像很容易饱和,而远处的物体会因为光太弱而非常暗,导致检测不到。
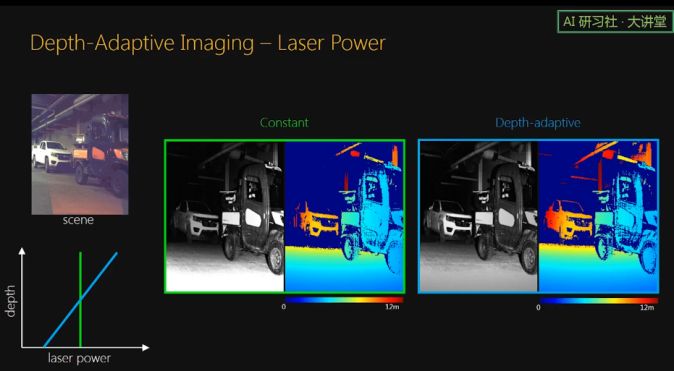
但是对于我们的系统来说,由于我们扫描的面是由一条一条线组成的,对于每条线,它的曝光时间是可以改变的,我们的设备有这个自由度,所以我们可以对近处的线进行短曝光,而对远处的线进行长曝光。这样,总的发射能量是一样的,但是可以看得更远。
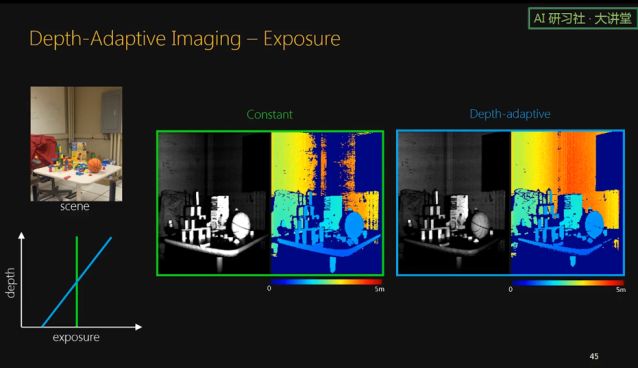
我们也可以控制每条线的激光强度。效果是一样的,也就是总的使用能量一样,但是能看得更远,比如这里后面车的 frame 看得更清楚。
总结一下,为什么我们的 light curtain 有诸多好处呢,是因为我们预设了一个 depth of interest,所以整个设备就可以进行相应的最优化了。
我们的传感器成本很低,消耗的能量很少,需要的运算也非常少;
它可以在强烈太阳光下工作,也可以穿透烟雾;
它的形状和厚度也可以很灵活的改变;
它的帧率也很高。
最后再讲一下很多人关心的激光安全问题。激光安全距离需要非常多严格的计算。根据计算,我们的 prototype 中使用的激光在 0.72m 之外是绝对安全的。我们在 prototype 中使用的激光是可见红色激光,在实际使用时应该使用红外激光,红外激光比红色激光还要安全。
我今天的分享就到这里,谢谢大家!
以上就是本期嘉宾的全部分享内容。更多公开课视频请到雷锋网 AI 研习社社区(http://ai.yanxishe.com/)观看。关注微信公众号:AI 研习社(okweiwu),可获取最新公开课直播时间预告。





