目标检测20年综述之(二)
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:橙煦猿
https://zhuanlan.zhihu.com/p/73069250
本文已授权,未经允许,不得二次转载
回顾:
5. 检测器的构建模块及其技术演化
5.1 Early Time’s Dark Knowledge
早期的目标检测(2000年以前)没有遵循滑动窗口检测等统一的检测理念。当时的探测器通常基于低层和中层的视觉。
5.1.1 Components, shapes and edges
“依靠组件识别”作为一种重要的认知理论,长期以来一直是图像识别和目标检测的核心思想。一些早期的研究人员将目标检测看作目标组件、形状和轮廓之间相似性的度量,包括Distance Transforms, Shape Contexts和Edgelet 等。尽管最初的结果还不错,但在更复杂的检测问题上,表现并不好。因此,基于机器学习的检测方法开始发展。
基于机器学习的检测经历了多个阶段,包括外观统计模型(the statistical models of appearance,before 1998), 小波特性表示(wavelet feature representations ,1998-2005)和基于梯度的表示(gradient-based representations,2005-2012).
构建目标统计模型,如Eigenfaces,是目标检测历史上第一批基于学习的方法。1991年,M. Turk等人利用Eigenface decomposition在实验室环境中实现了人脸的实时检测。与当时基于规则或模板的方法相比,统计模型通过从数据中学习特定任务的知识,能够更好地全面描述目标的外观。
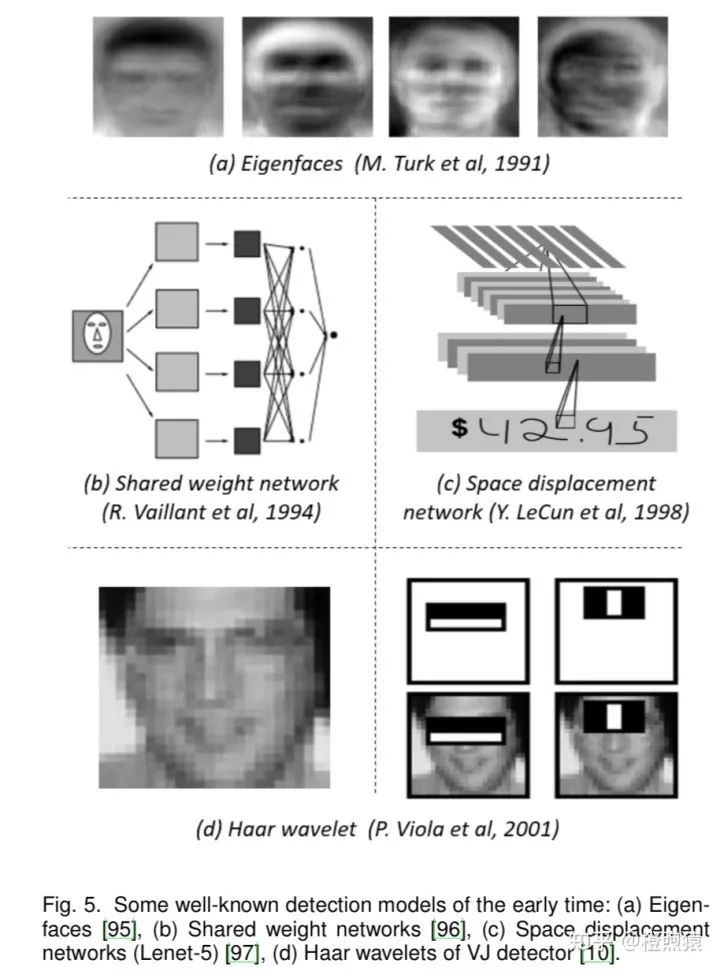
从2000年以来,小波特征变换(Wavelet feature transform)开始主导视觉识别和目标检测。该类方法的本质是通过将图像从像素点转换为一组小波系数来学习。在这些方法中,Haar小波(Haar wavelet)由于其较高的计算效率,应用于许多目标检测任务中,如通用目标检测、人脸检测、行人检测等。图5 (d)为VJ检测器学习到的一组人脸Haar小波基(Haar wavelets basis)。
5.1.2 早期的CNN目检测
CNN进行目标检测的历史可以追溯到1990年代,Y. LeCun等人做出了巨大贡献。针对计算资源的限制,做了shared-weight replicated neural network和 space displacement network等工作,通过扩展卷积网络的每一层来覆盖整个输入图像,减少计算量,如图5-(b)(c)所示。这样,网络只需进行一次正向传播,就可以提取出整个图像任意位置的特征。这可以看作是当今全卷积网络(FCN)的原型。
5.2 多尺度检测(Multi-Scale Detection)
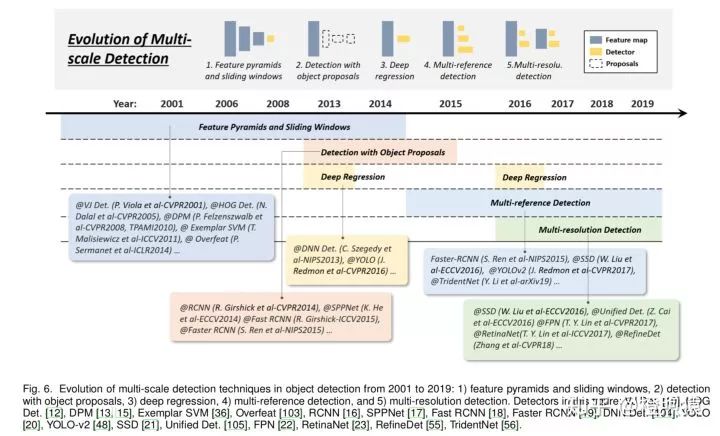
“不同尺寸”和“不同宽高比”目标的多尺度检测(multi- scale detection)是目标检测的主要挑战之一。近20年来,多尺度检测经历了多个历史时期:“特征金字塔和滑动窗口(feature pyramids and sliding windows,2014年前)”、“基于proposal的检测(2010-2015)”、“深度回归(deep regression,2013-2016)”、“多候选框检测(multi-reference detection,2015年后)”、“多分辨率检测(multi-resolution detection,2016年后)”,如图6所示。
5.2.1 Feature pyramids + sliding windows
HOG检测器,DPM,甚至是深度学习时代的Overfeat检测器。
早期的检测模型,如VJ检测器和HOG 检测器,都是专门设计用来检测具有“固定宽高比”的目标(如人脸和直立的行人),只需要简单地构建特征金字塔并在其上滑动固定大小的检测窗口。为了检测PASCAL VOC中外观更复杂的物体,R. Girshick等人开始在特征金字塔外寻找更好的解决方案。“混合模型”(mixture model)是当时最好的解决方案之一,它通过训练多个模型来检测不同宽高比的物体。此外,基于实例的检测(exemplar-based detection)通过为训练集的每个目标实例训练单独的模型,提供了另一种解决方案。
5.2.2 Detection with object proposals
目标proposa参考一组可能包含任何目标的与类别无关的候选框,它于2010年首次应用于目标检测。使用proposal进行检测有助于避免对整张图像进行冗余的滑动窗口搜索。
现代的proposal检测方法可以分为三类
1) segmentation grouping approaches
2) window scoring approaches
3) neural network based approaches
早期的proposal检测方法遵循自底向上的检测理念,深受视觉显著性检测的影响。后来,研究人员开始转向low-level vision(如边缘检测)和更精细的手工技能,以改进候选框的定位。2014年以后,随着CNN在视觉识别领域的普及,自上而下、基于学习的方法开始在这个问题上显示出更多的优势,目标proposal检测已经从自底向上的视觉发展到“对一组特定目标类的过度拟合”,检测器和proposal生成器之间的区别变得越来越模糊。
随着“object proposal”对滑动窗口检测的革命性变革,并迅速主导基于深度学习的检测器,2014-2015年,许多研究者开始提出以下问题:object proposal在检测中的主要作用是什么?是为了提高准确度,还是为了提高检测速度?为了回答这个问题,一些研究人员试图削弱proposal的作用,或者只是对CNN特征进行滑动窗口检测,但都没有得到令人满意的结果。在one-stage检测器和(下面的的)“deep regression”技术兴起了。
5.2.3 Deep regression
使用deep regression来解决多尺度问题的思想非常简单,即,根据深度学习特征直接预测边界框的坐标。这种方法的优点是简单易行、速度较快,缺点是定位不够准确,特别是对于一些小目标。“Multi-reference detection解决了这一问题。
5.2.4 Multi-reference/-resolution detection
Multi-reference detection是目前最流行的多尺度目标检测框架。它的主要思想是在图像的不同位置预先定义一组不同大小和宽高比的参考框(即anchor boxes),然后根据这些参考框预测检测框。
每个预定义anchor box的损失包括两部分:1)用于分类的交叉熵损失和2)目标定位的L1/L2回归损失。损失函数的一般形式可以写成:
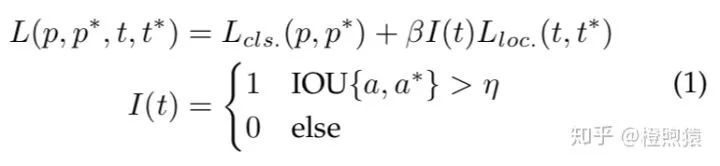
其中,t和t是预测的位置和groundtruth边界框,p和p是它们的类别概率。IOU{a, a}是anchor a与其groundtruth a之间的IOU。η是一个IoU阈值,通常取0.5。如果anchor没有覆盖任何目标,其定位损失不计入最终损失。
另一种流行的技术是multi-resolution detection,即在网络的不同层检测不同尺度的目标。由于CNN在正向传播过程中自然形成了一个特征金字塔,所以更容易在较深的层中检测到较大的目标,在较浅的层中检测到较小的目标。Multi-reference and multi-resolution detection已成为当前最先进的目标检测系统的两个基本组成部分。
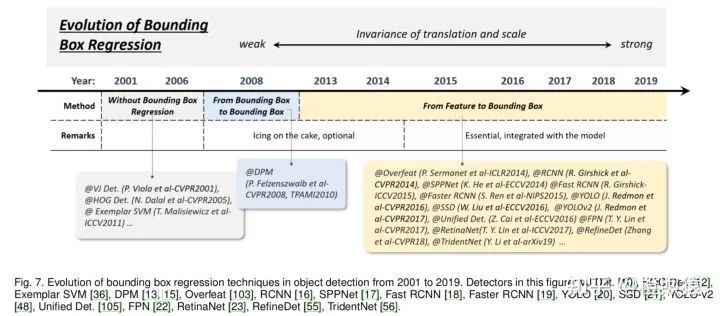
5.3 Bounding Box Regression
边界框回归的目标是在初始proposal或anchor box的基础上refine预测边界框的位置。
三个时期:
(1)without BB regression (before 2008)
(2)from BB to BB (2008- 2013)
(3)from feature to BB (after 2013)
5.3.1 Without BB regression
早期的检测方法,如VJ检测器和HOG检测器等,大多不使用BB回归,通常直接将滑动窗口作为检测结果。为了获得精确的目标位置,研究人员别无选择,只能构建金字塔,并在每个位置上密集地滑动探测器。
5.3.2 From BB to BB
第一次将BB回归引入目标检测系统是在DPM中。那时的BB回归通常作为一个后处理模块,因此它是可选的。由于PASCAL VOC的目标是预测每个对象的单个边界框,因此DPM生成最终检测的最简单方法应该是直接使用其root filter位置。后来,R. Girshick等人提出了一种更复杂的方法来预测一个基于目标假设完整配置的边界框(a bounding box based on the complete configuration of an object hypothesis),并将这个过程表示为一个线性最小二乘回归问题,该方法对PASCAL标准下的检测有明显的改进。
5.3.3 From features to BB
在2015年Faster RCNN之后,边界框回归不再作为一个单独的后处理模块,而是与检测器集成在一起,以端到端的方式进行训练。同时,边界框回归已经发展到基于CNN特征直接预测边界框。
为了得到更鲁棒的预测,通常使用smooth-L1函数,或者平方根函数作为其回归损失。与DPM中使用的最小二乘损失相比,该方法对异常值具有更强的鲁棒性。一些研究人员还选择将坐标标准化以获得更鲁棒的结果。

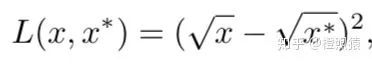
5.4 Context Priming
(1)detection with local context
(2)detection with global context
(3)context interactives
5.4.1 Detection with local context
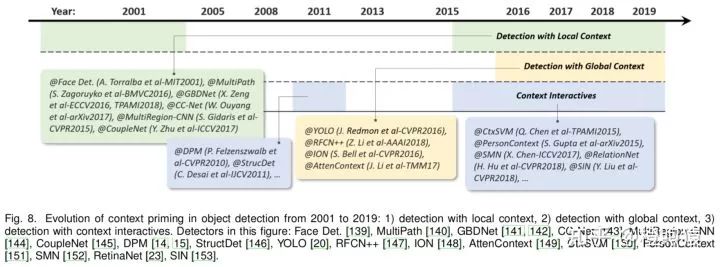
局部上下文是指要检测的目标周围区域的视觉信息。长期以来,人们一直认为局部上下文有助于改进目标检测。在21世纪初,Sinha和Torralba发现,包含局部上下文区域(如面部边界轮廓)可以显著提高人脸检测性能。Dalal和Triggs还发现,加入少量的背景信息可以提高行人检测的准确性。最近的基于深度学习的检测器也可以通过简单地扩大网络的感受野或目标proposal的大小来根据局部上下文进行改进。
5.4.2 Detection with global context
全局上下文利用场景作为目标检测的附加信息源。对于早期的目标检测器,集成全局上下文的一种常见方法是集成组成场景的元素的统计和,比如Gist。对于现代的基于深度学习的检测器,有两种方法来集成全局上下文。第一种方法是利用大的感受野(甚至比输入图像更大)或CNN特征的全局池化;第二种方法是把全局上下文看作是一种序列信息,然后用递归神经网络来学习它
5.4.3 Context interactive
上下文交互是指通过视觉元素的交互(如约束和依赖关系)来传递的信息。大部分检测器并没有利用目标实例之间的关系来检测和识别它们。近年来的研究表明,考虑上下文的交互可以有效地提高目标检测器的性能。最近的一些改进可以分为两类,第一类是研究单个对象之间的关系,第二类是研究目标和场景之间的依赖关系。
5.5 Non-Maximum Suppression
采用非最大抑制作为后处理步骤,去除冗余的检测框,得到最终的检测结果。
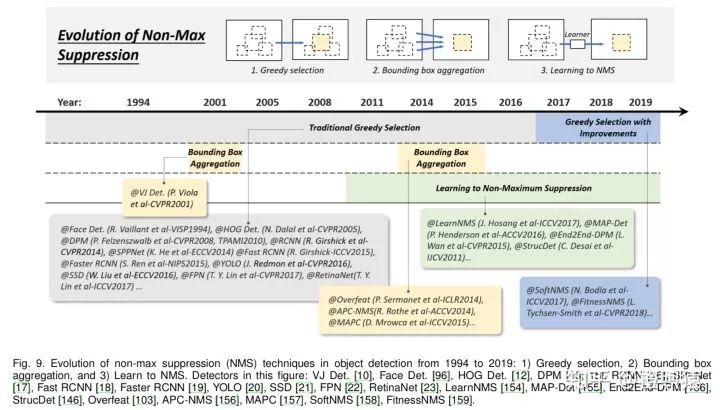
5.5.1 Greedy selection
贪婪选择背后的思想简单直观:对于一组重叠检测结果,选择得分最大的边界框,并根据预定义的重叠阈值(如0.5)删除相邻框。上述处理在以贪婪的方式迭代执行。
缺点
(1)得分最高的框可能不是最合适的
(2)它可能会抑制附近的物体
(3)它不抑制false positives

5.5.2 BB aggregation
边界框聚合是针对NMS的另一种技术,其思想是将多个重叠的边界框组合或聚类成一个最终的检测结果。
优点
充分考虑了目标关系及其空间分布,VJ检测器和Overfeat使用这种方法。
5.5.3 Learning to NMS
Learning to NMS的主要思想是将NMS看作一个过滤器,对所有原始检测进行重新评分,并以端到端方式将NMS训练为网络的一部分。与传统的手工NMS方法相比,这些方法在改善遮挡和密集目标检测方面取得了良好的效果。
5.6 Hard Negative Mining
目标检测器的训练本质上是一个不平衡数据学习问题。负样本过多导致使用所有的背景数据对训练不利,因为大量容易的负样本将压倒学习过程。HNM是针对训练过程中数据不平衡的问题。
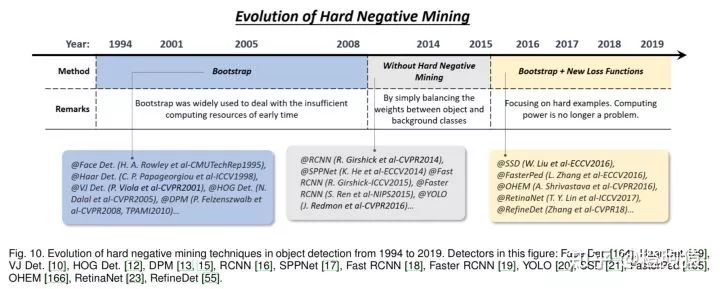
5.6.1 Bootstrap
目标检测中的Bootstrap是指一组训练技术,训练从一小部分背景样本开始,然后在训练过程中迭代地添加新的错分类背景。在早期的目标检测器中,最初引入bootstrap的目的是减少对数百万个背景样本的训练计算量。后来成为DPM和HOG检测器中解决数据不平衡问题的标准训练技术。
5.6.2 深度学习检测器中的HNM
在深度学习时代后期,由于计算能力的提高,在2014-2016年的目标检测中,bootstrap很快被丢弃。为了缓解训练过程中的数据不平衡问题,Faster RCNN和YOLO只是在正负样本之间平衡权重。然而,研究人员后来发现,权重平衡不能完全解决数据不平衡问题。为此,2016年以后,bootstrap被重新引入到基于深度学习的检测器中。例如,在SSD和OHEM中,只有很小一部分样本(损失值最大的样本)的梯度会被反向传播。在RefineDet中,一个anchor refinement module用来过滤容易的负样本。另一种改进是设计新的损失函数,通过重新定义标准的交叉熵损失,使其更关注于困难的、分类错误的样本(比如RetinaNet中提出的Focal Loss)。
CVer-目标检测交流群
扫码添加CVer助手,可申请加入CVer-目标检测交流群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!




