干货 | 基于深度学习的目标检测算法综述(二)
AI 科技评论按:本文转载自 美图技术 公众号
目标检测(Object Detection)是计算机视觉领域的基本任务之一,学术界已有将近二十年的研究历史。近些年随着深度学习技术的火热发展,目标检测算法也从基于手工特征的传统算法转向了基于深度神经网络的检测技术。从最初 2013 年提出的 R-CNN、OverFeat,到后面的 Fast/Faster R-CNN、SSD、YOLO 系列,再到 2018 年最近的 Pelee。短短不到五年时间,基于深度学习的目标检测技术,在网络结构上,从 two stage 到 one stage,从 bottom-up only 到 Top-Down,从 single scale network 到 feature pyramid network,从面向 PC 端到面向手机端,都涌现出许多好的算法技术,这些算法在开放目标检测数据集上的检测效果和性能都很出色。
基于深度学习的目标检测算法综述分为三部分:
1. Two/One stage 算法改进。这部分将主要总结在 two/one stage 经典网络上改进的系列论文,包括 Faster R-CNN、YOLO、SSD 等经典论文的升级版本。
2. 解决方案。这部分我们归纳总结了目标检测的常见问题和近期论文提出的解决方案。
3. 扩展应用、综述。这部分我们会介绍检测算法的扩展和其他综述类论文。
图 1
上篇文章(基于深度学习的目标检测算法综述(一))介绍了 Two/One stage 算法改进,本篇文章将详细介绍解决方案,这部分我们归纳总结了目标检测的常见问题和近期论文提出的解决方案。
本部分针对小物体检测、不规则形状物体检测、检测算法中正负样本不均衡问题、物体被遮挡、检测算法的 mini-batch 过小、物体之间的关联信息被忽略等问题提出了解决方案。在这个部分最后本篇综述将介绍四篇改进网络结构以提升检测效果(包括准确率和速度)的论文,如改进基础网络以提升准确率的 DetNet 和针对移动端优化速度的 Pelee 网络等。
#小物体检测
Feature Pyramid Networks for Object Detection
论文链接:arxiv.org/abs/1612.03144
开源代码:github.com/unsky/FPN
录用信息:CVPR2017
论文目标
引入 Top-Down 结构提升小物体检测效果。
核心思想
Feature Pyramid Networks (FPN) 是比较早提出利用多尺度特征和 Top-Down 结构做目标检测的网络结构之一,虽然论文中整个网络是基于 Faster R-CNN 检测算法构建,但其整体思想可以广泛适用于目前常见的大部分目标检测算法甚至分类等的其他任务中。
整体来讲, FPN 解决的问题如下:只用网络高层特征去做检测,虽然语义信息比较丰富,但是经过层层pooling等操作,特征丢失太多细节信息,对于小目标检测这些信息往往是比较重要的。所以,作者想要将语义信息充分的高层特征映射回分辨率较大、细节信息充分的底层特征,将二者以合适的方式融合来提升小目标的检测效果。
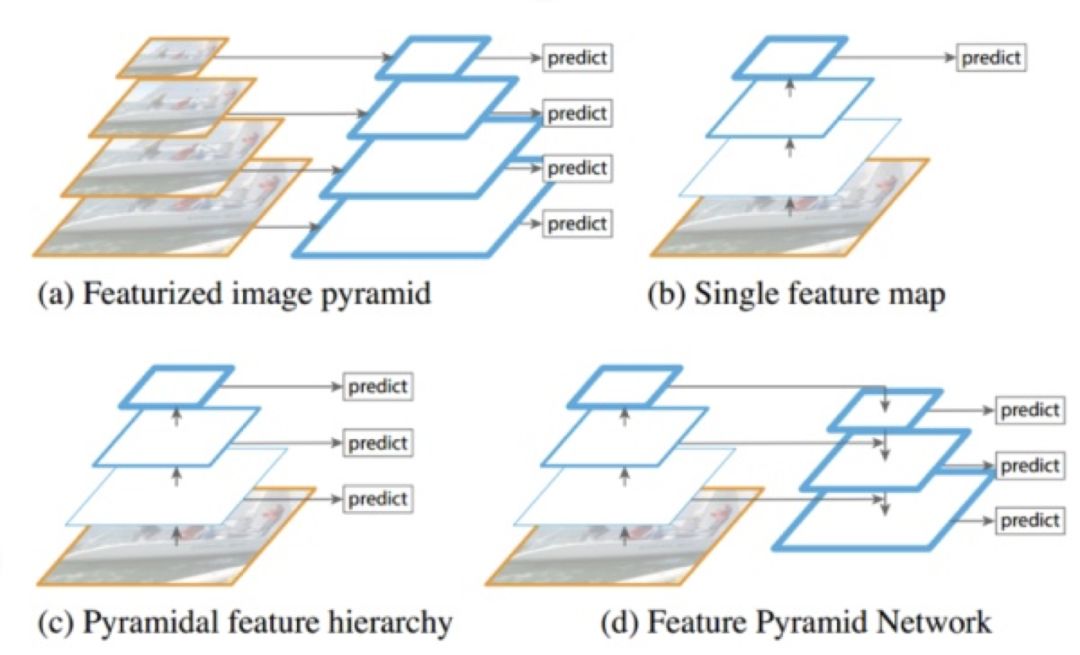
图 2:特征利用算法
上图中作者首先介绍了四种常见的特征利用的方式,这里我们一一说明。图中a部分展示了利用图像特征金字塔的方式做预测的方法,即通过将预测图片变换为不同尺寸的图片输入网络,得到不同尺寸的特征进行预测。这种方法行之有效,可以提升对各个尺寸目标的检测效果。
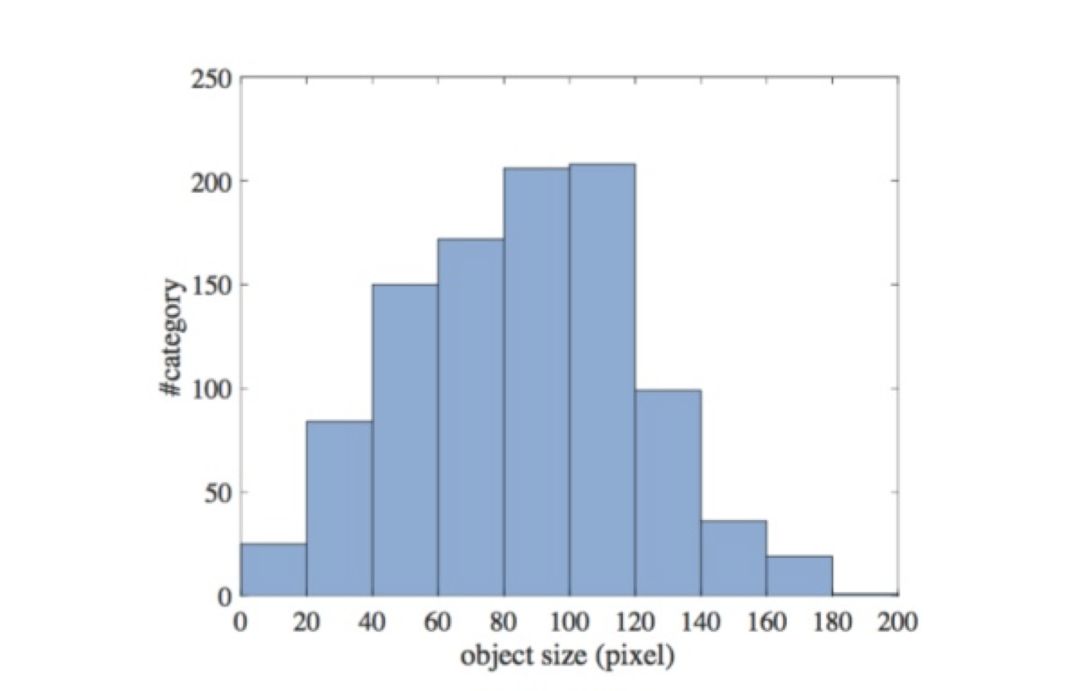
图 3
上图是 imageNet 数据集中各个物体的尺寸分布,可以看到大部分物体尺寸集中在 40-140 像素之间。当我们采用 imageNet 的 pretrain 参数初始化我们的基础网络时,网络实际上对 40-140 像素间的物体是较为敏感的。所以当物体目标过大过小的时候效果都会打折扣。而图像多尺度金字塔预测的方法也解决了这一问题。这个方法虽然行之有效但是缺点是效率低下。尤其是应用于类似于 Faster R-CNN 这样的网络,迫于速度和显存的压力,端对端的训练难以实现。通常这种方法只应用于网络预测的阶段。
图中 b 部分展示的方法为利用单一尺度图片的最高层信息进行预测的方法,是平时最广泛被使用的一种方法,简单高效。但是缺点是由于尺度单一,应对多尺度的目标效果受限。图中 c 部分展示了利用特征金字塔来做预测的方法。即采用不同尺寸不同深度的特征层分别进行预测,每层的感受野和特征信息的丰富程度都不一样,对不同尺寸的目标响应也有所区别。其中高层特征更适合用于检测大目标,而低层特征细节信息更加丰富,感受野也偏小,更适合用于检测小目标。我们经常使用的 SSD 检测算法即使用了这种思路。该方法的缺点是低层的特征信息因为层数较浅,语义信息不太丰富,所以小目标的检测效果仍然不尽如人意。图中 d 部分即为 FPN 的解决方案,利用 Top-Down 结构,融合了高层和底层的特征信息,使得底层的语义信息仍然很丰富的同时保持较大的分辨率,提升小物体的检测效果。
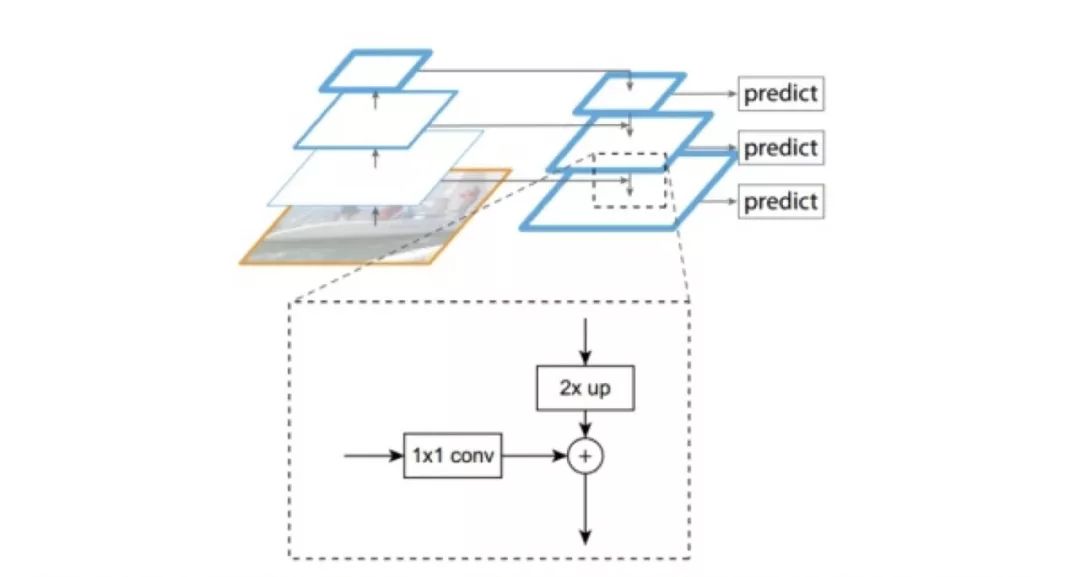
图 4
图 4 展示了 FPN 网络的特征融合方式,其中高层特征通过最近邻差值的方式增大两倍的尺寸,而底层的特征经过一个 1*1 的卷积做降维操作,这两层特征分别作像素级的相加完成融合。融合之后的特征可以经过一个 3*3 的卷积层之后输入用来预测,也可以再重复上面的操作,和更低层的特征进行融合。
算法效果
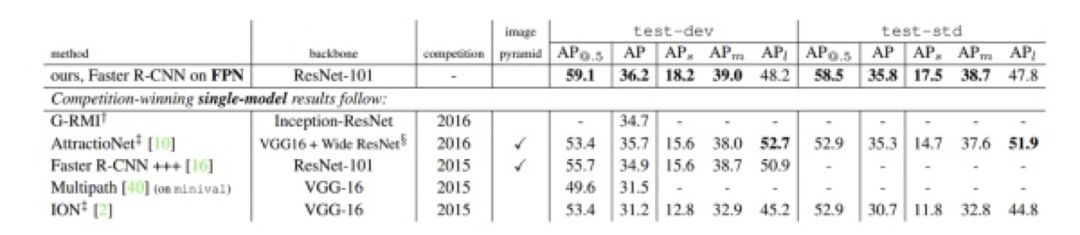
图 5
上图展示了各个算法在 COCO 数据集上的对比。
Beyond Skip Connections Top Down Modulation for Object Detection
论文链接:arxiv.org/abs/1612.06851
开源代码:/
录用信息:CVPR2017
论文目标
1. 有效利用网络前层信息。使其既包含小物体细节信息,又包含高层抽象语义信息,提高小物体召回率。
2. 避免直接特征叠加导致维度过高。
核心思想
本文是Google 对标Facebook FPN的一个算法,用与FPN不同的方式实现了Top Down结构,主要是为了融合低层的细节特征和高层语义特征来提升小物体检测效果的一个方法。
本论文提出的Top Down modulation的结构主要关键点在于modulation这一过程,在该算法中,高底层的信息融合不是像FPN一样像素级叠加,而是通过卷积进行融合。由神经网络自主的选择选择哪些特征进行融合,实现这一“调制”过程。
整体网络结构
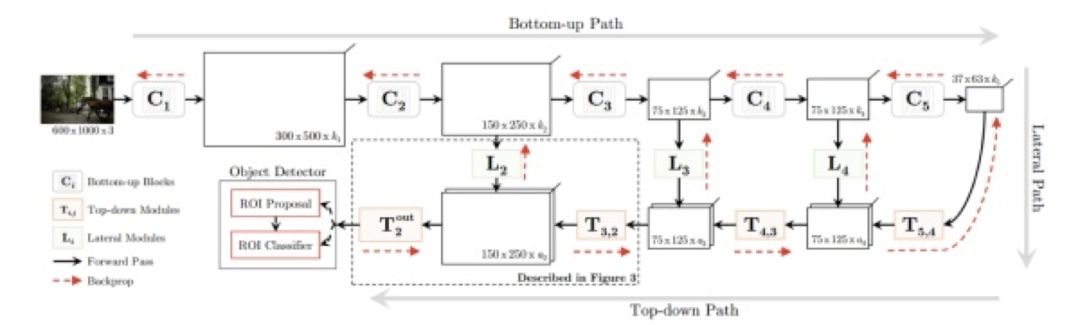
图 6:整体网络结构图
首先对自下而上的 CNN 网络加入一个自上而下的 Top Down 网络,使用 lateral connections 连接起来。通过这些 connections 筛选合适的特征,通过 Top Down 网络进行特征融合。
Top Down Modulation(TDM)网络基础模块
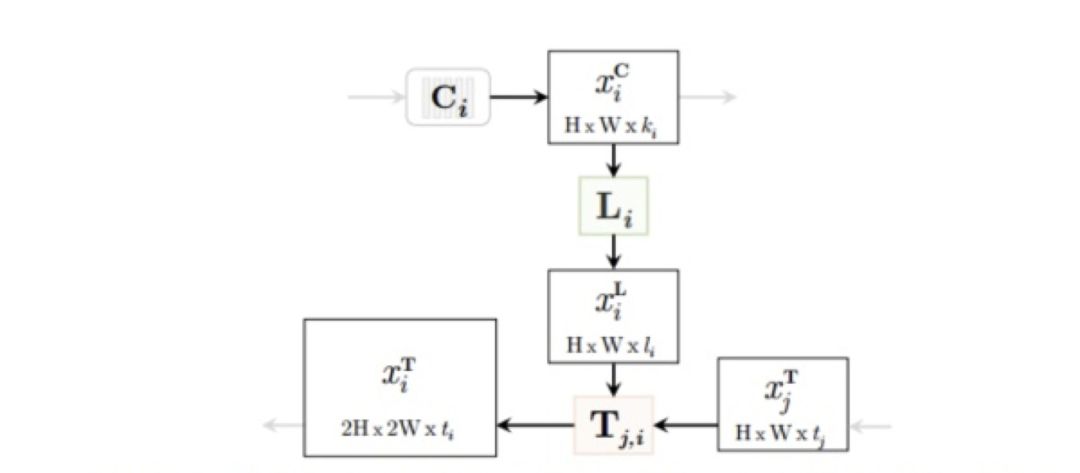
图 7
基础单元由两个部分组成:
L:a lateral module
侧向连接主要提取低层信息特征,并筛选可用特征。
T : a Top Down module
邻近层语意信息的传递,及特征融合。
算法细节以 VGG16 为例:
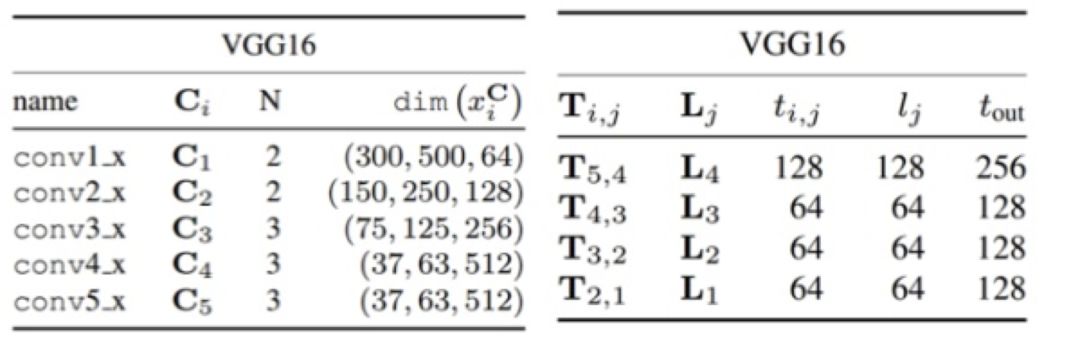
图 8
下文具体分析 VGG16 ,Conv2 层。
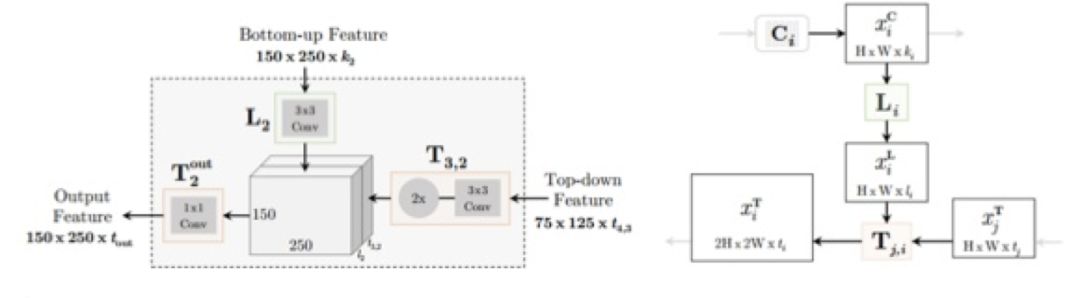
图 9
解构流程:
1. 将上层 Top Down 的 feature map 经过 3 x 3 x 64 卷积,再接 Relu 激活函数,最后接 UpSample 上采样。
2. 将 bottom up 对应的 feature map 经过 3 x 3 卷积,再接 Relu 激活函数。
3. 将 L 模块的 feature map 与 T 模块的 feature map concat。
4. 接 1 x 1 x 128 卷积做特征融合。
训练方法
以预训练好的原网络作为开始,论文发现逐步构建 bottom-up 的网络比一次性构建要好。用整体网络结构图举例说明,论文先添加(





网络设计准则:
1.Top Down 的深度通常是越深越有效,但是过于深的时候如 VGG 融合到 conv1 深度,性价比就相当低了。
2. 侧向连接和 bottom-up 的连接应该减少特征维度。
3. 网络训练需要采取一层一层增加,冻结之前层的方式。这样可以保证训练收敛稳定。
算法总结
整体来讲高层和底层信息都经过卷积进行了降维操作,控制了计算量的增加,如 VGG16 最后一层输入 RPN 的特征数由 512 减小为 256 。同时特征融合是 concat 一起的,避免了特征叠加对信息造成的负面影响。另外需要说明一点,由于RPN网络输入特征图会变大很多倍,如果还遵循原始 Faster R-CNN 逐像素判断正负例的做法,网络会变得很慢,所以作者采取通过更改 stride step 来控制计算量保持不变。如特征图面积增大 4 倍,stride 就设置为 2。
算法效果
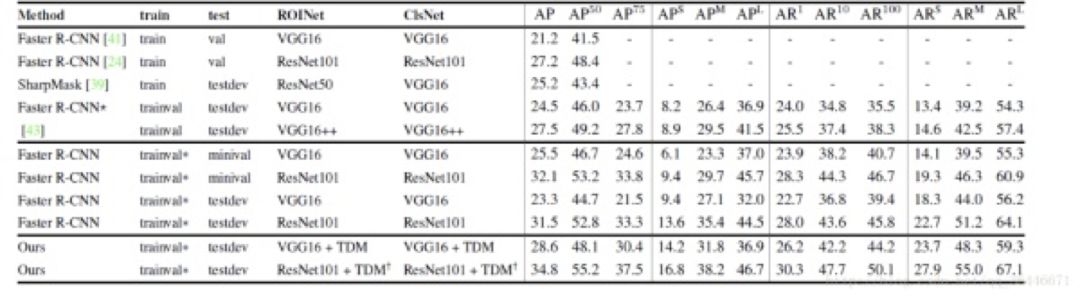
图 10
从效果表格上看小物体识别率得到了提升,说明 TDM 结构发挥了作用。笔者实际使用时也发现 TDM 结构就速度和效果来讲,相较类似于像素叠加式的方式也要好一些。
另外,关于 TDM、FPN 和 DSSD 在 Top-Down 结构设计上的区别已在本综述的第一篇文章中详细阐述,这里不再重复,具体细节请查看上一篇文章的 DSSD 部分。
#不规则形状物体的检测
Deformable Convolutional Networks
论文链接:arxiv.org/abs/1703.06211
开源代码:github.com/msracver/Deformable-ConvNets
录用信息:ICCV2017
论文目标
提升可变性物体的检测效果。卷积神经网络由于其固定的几何结构限制了其几何变换的建模能力。传统方法通常使用数据增强(如仿射变换等)、SIFT 特征以及滑动窗口算法等方法来解决几何形变的问题。但这些数据增强方法都需假设几何变换是固定的,无法适应未知的几何形变,手工设计特征和算法也非常困难和复杂。所以需要设计新的 CNN 结构来适应空间几何形变。
核心思想
论文主要是引进可形变卷积和可形变 RoI pooling 来弥补 CNN 在几何变换上的不足。同时实验也表明在深度 CNN 中学习密集空间变换对于复杂的视觉任务(如目标检测和语义分割)是有效的。
可形变卷积
1.标准卷积采用固定的 kernel 在输入的 feature map 上采样。可形变卷积则是在标准卷积采样的基础上,每一个采样位置分别在水平和竖直方向进行偏移,已达到不规则采样的目的,即卷积具有形变能力。
2.偏移是网络学习出来的,通常是小数。论文采用双线性差值的方式求这些带有小数采样点在 feature map 上对应的值。
3.偏移量可以采用标准卷积来实现。
4.图文说明
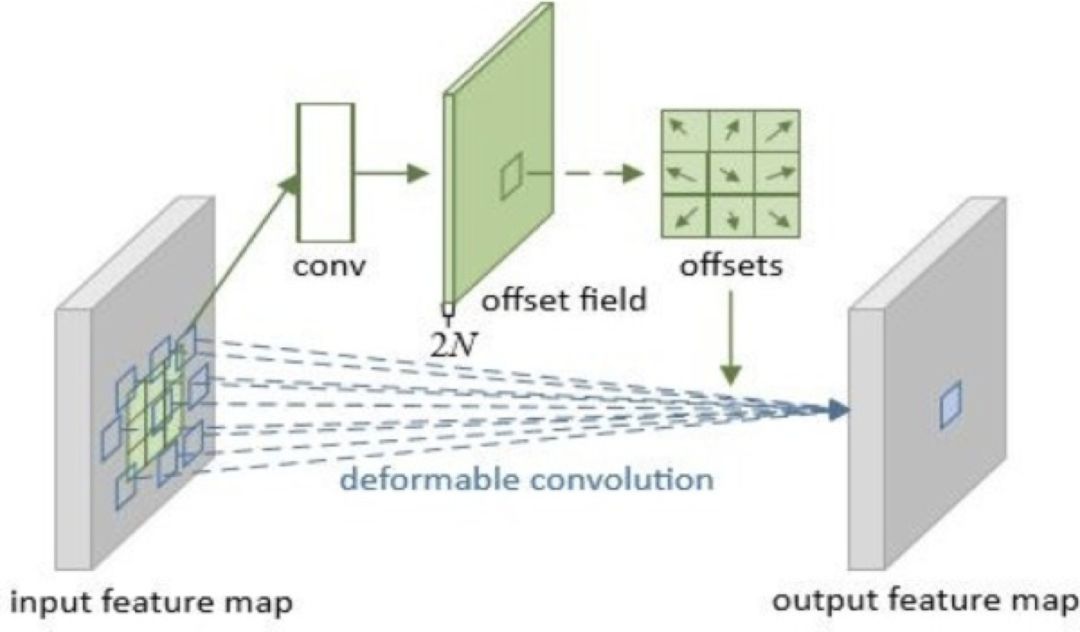
图 11
可形变 RoI pooling
1.RoI pooling 是把不同大小的 RoI(w*h) 对应的 feature map 统一到固定的大小(k*k)。可形变 RoI pooling 则是先对 RoI 对应的每个 bin 按照 RoI 的长宽比例的倍数进行整体偏移(同样偏移后的位置是小数,使用双线性差值来求),然后再 pooling。
2.由于按照 RoI 长宽比例进行水平和竖直方向偏移,因此每一个 bin 的偏移量只需要一个参数来表示,具体可以用全连接来实现。
3.图文说明
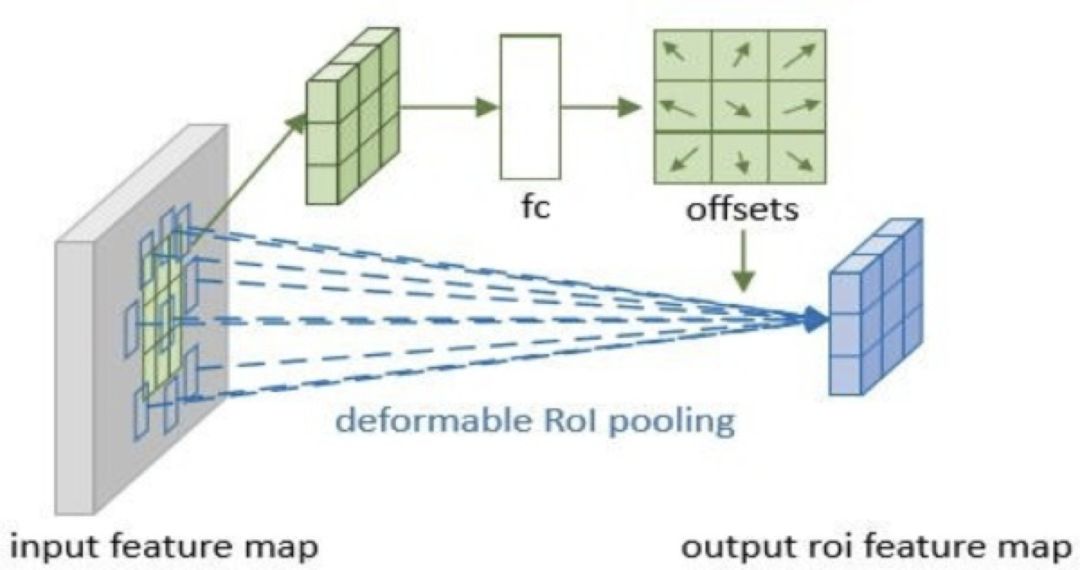
图 12
算法效果
三层 3*3 可形变卷积分别在背景(左),小目标(中),大目标(右)上的采样结果(共 9^3=729 个点)。

图 13
#解决正负样本不均衡的问题
Focal Loss for Dense Object Detection
论文链接:arxiv.org/abs/1708.02002
开源代码:github.com/unsky/RetinaNet
github.com/unsky/focal-loss
录用信息:ICCV2017
论文目标
论文作者认为,one stage 检测精度之所以低于 two stage 方案的一个重要原因是检测样本不均衡:easy negative samples 数量大大超过其他正样本类别。这使得训练过程中,easy negative samples 的训练 loss 主导了整个模型的参数更新。
为解决这个问题,论文提出了 focal loss。在计算交叉熵损失时,引入调制因子,降低概率值较大的 easy negative samples 的 loss 值的权重,而对于概率值较小的误分类样本的 loss 值,权重保持不变。以此提高占比较低的误分类别的样本在训练时对 loss 计算的作用。
核心思想
Focal Loss
Focal Loss 是在 Cross Entropy 上进行的改进,主要有一个 γ 参数(实际应用中会增加 Balanced Cross Entropy 中的 α 参数),γ 是作者引入用来关注 hard example 的参数,减少 hardexample 对 loss 的影响。下图是其公式及效果曲线图:
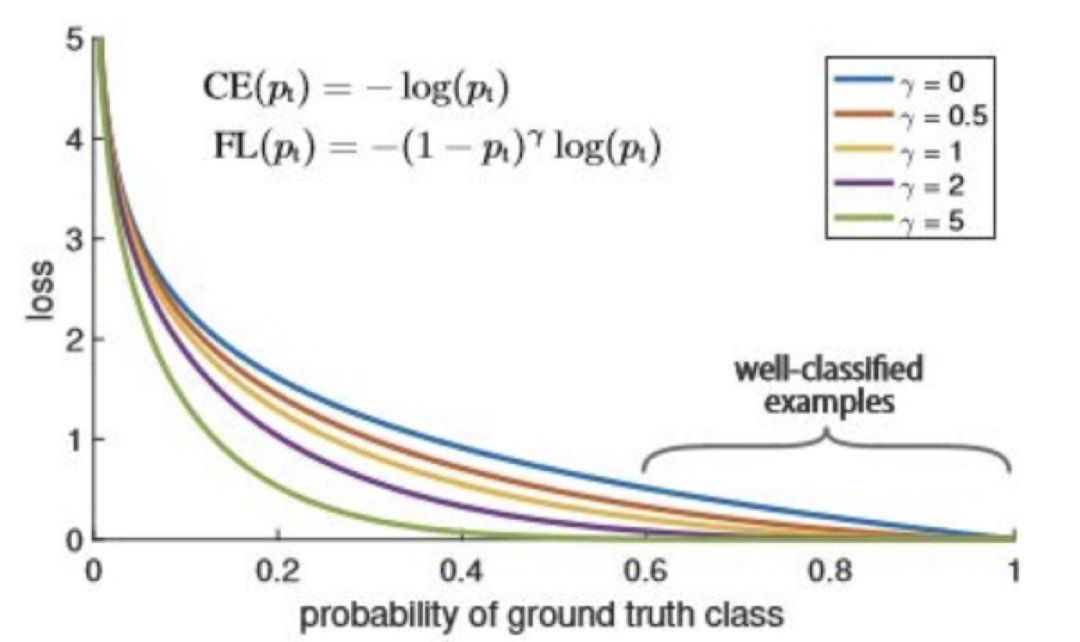
图 14
Focal Loss 的具体形式并不是很重要,主要是发现在目标检测中正负样本极度不平衡导致检测精度低的问题,论文也验证了其它形式的 loss。虽然先前的检测器也考虑到这个问题并提出解决方案(例如 OHEM),但是这种修改 loss 并且由数据驱动的形式更加有效和简洁。
RetinaNet
作者为了证明 Focal Loss 的有效性,设计了一个 one-stage 的网络结构,并命名为 RetinaNet,其是以 ResNet+FPN 作为基础网络来提取特征,然后分别接两个子网络进行识别和定位。其中 rpn 的 Top-Down pathway 和 lateral connetions(横向融合)用来构建大量多尺度的特征金字塔,然后用 anchor 机制在其上产生 box 用于下一步的分类和回归。下图是 RetinaNet 的结构示意图:
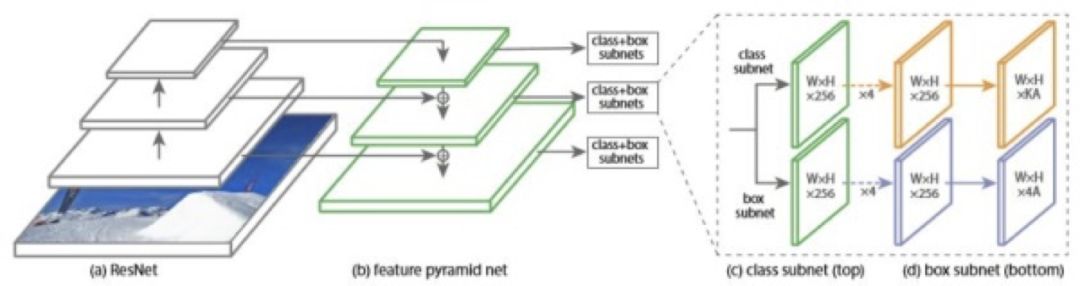
图 15
算法效果
论文阐述了 one stage 检测器相比 two stage 检测器精度低的问题以及原因,并通过设计新的 loss 给出了解决方案。
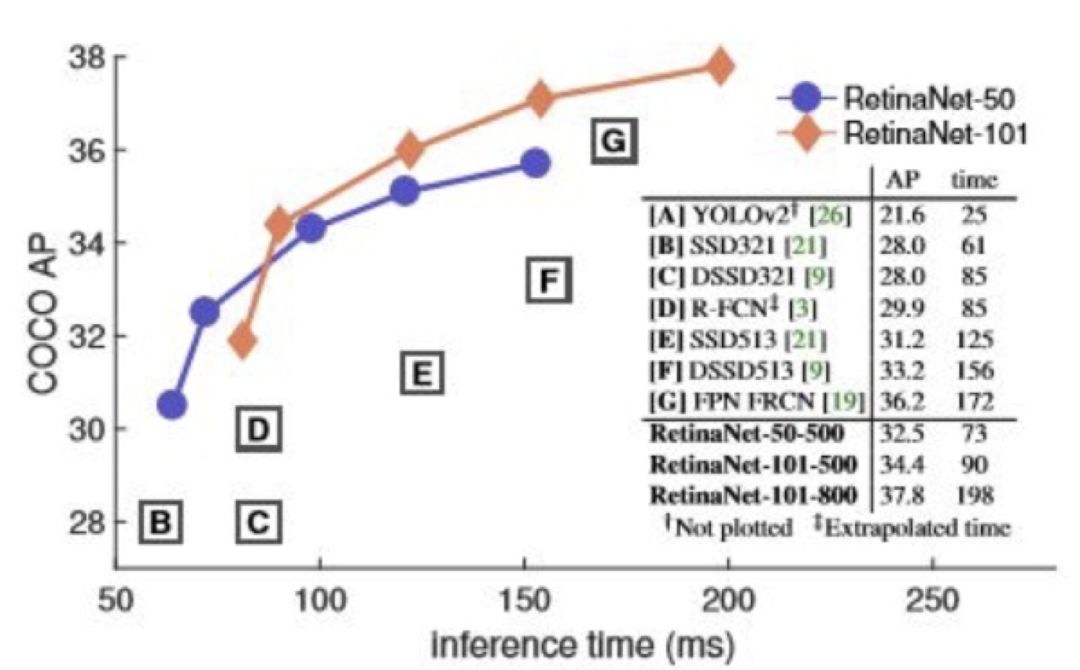
图 16
Chained Cascade Network for Object Detection
论文链接:
openaccess.thecvf.com/content_ICCV_2017/papers/Ouyang_Chained_Cascade_Network_ICCV_2017_paper.pdf
开源代码:github.com/wk910930/ccnn
录用信息:ICCV2017
论文目标
物体检测任务中背景样本会比前景多很多,在训练中会造成正负样本不均衡的情况。作者设计出一套级联的方式来去除无用的背景,浅层中的无用信息过滤掉后无需进入更深的网络中计算,后阶段的特征和分类器只负责处理少量更困难的样本。由于需处理样本数量减少(主要减少了简单样本),此级联网络可节省训练预测时间,且更困难样本经过级联后作用会加强,所以检测效果也会有一定提升。
核心思想
主要的网络结构如图所示,可以分为两个部分:前阶段层和深阶段语义层。
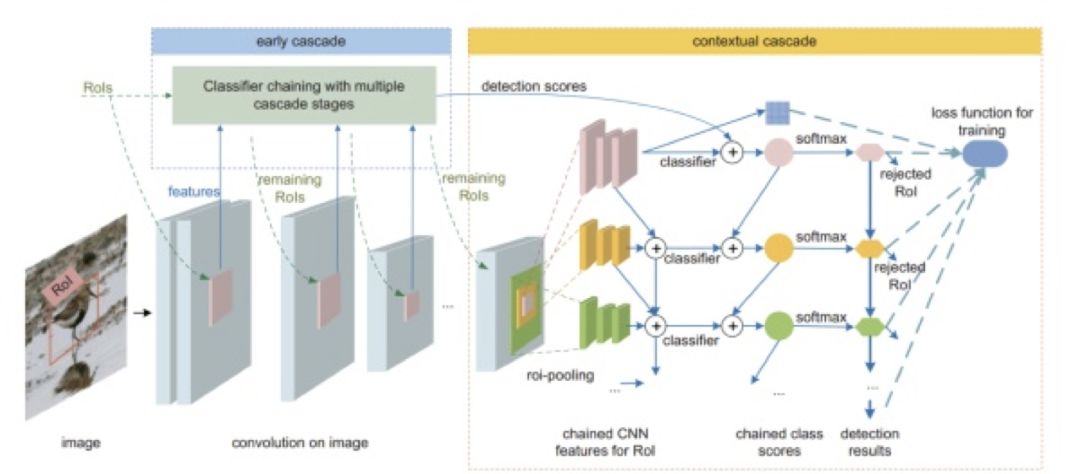
图 17
在浅层中,通过多级级联,网络可以拒绝来自背景的无用 RoI。经过 RoI pooling 后的特征用来做分类,但被上一层拒绝的 RoI 不会再用他们的信息做 RoI pooling 了。在上下文级联阶段,那些没有被拒绝的 RoI 用来生成特征。特征再经过级联,最终没有被拒绝的部分用来做最终的预测。
作者设计的网络在训练和预测阶段都有层级网络,可以在节省训练和预测时间的情况下提升检测效果。因为在浅层网络拒绝 RoI 在深层网络不会用来被使用。 前阶段的网络用来学简单的分类,可以去除那些比较容易区分的背景,而深层用来学难的分类。以图为例,第一层,学习是不是哺乳动物。第二层学习是哪种动物如羊牛猪。最后一层学习区分都有角的动物,如牛羊。
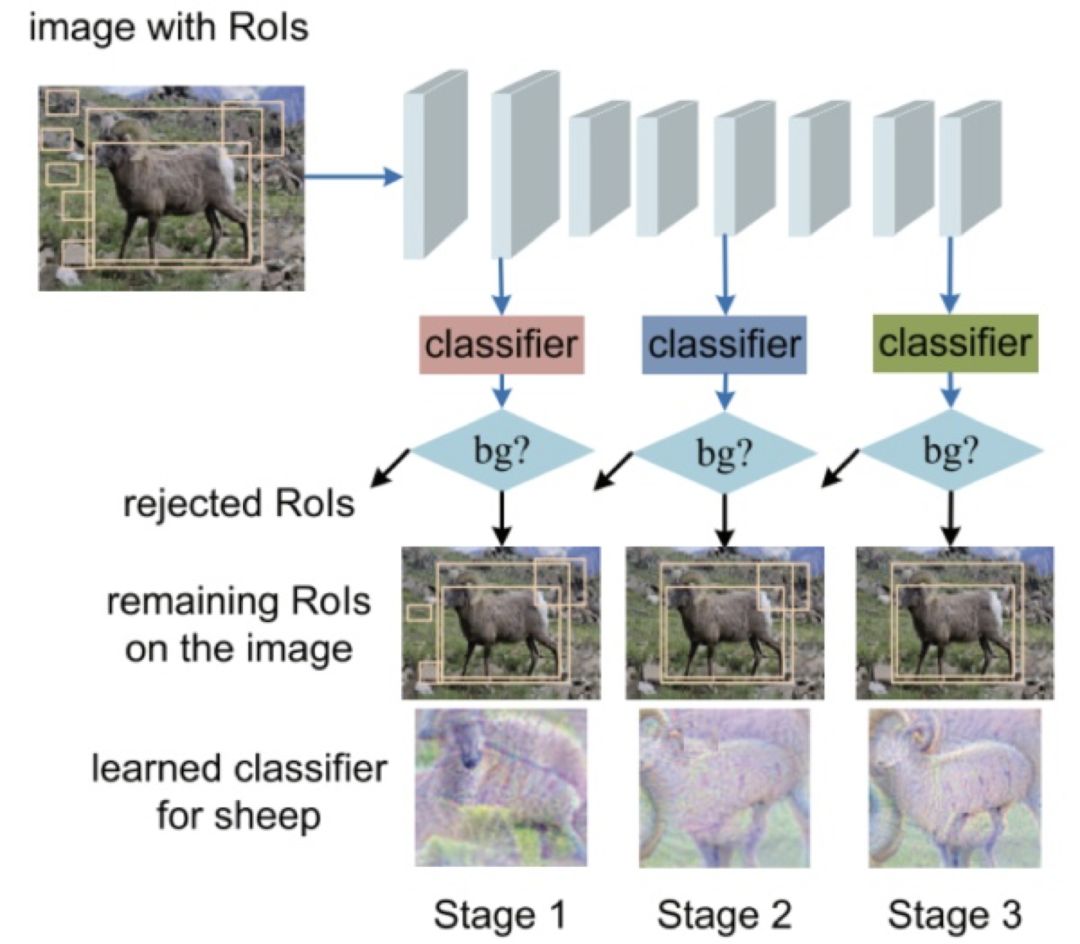
图 18
作者的创新主要可以归于以下几点:把级联分类器用在物体检测中,分类器级联中在上一层的分类得分在下一层也会被用到。不同层用到不同的特征,这些特征可以是不同深度、不同参数、分辨率和语义信息。上一层的特征可以被用到当前层,作为本层的先验知识。而所有的处理,如框回归、特征级联、分类级联都是在一个完整的网络中可以 E2E 处理。
算法效果
图 19
RON-Reverse Connection with Objectness Prior Networks for Object Detection
论文链接:arxiv.org/abs/1707.01691
开源代码:github.com/taokong/RON
录用信息:CVPR2017
论文目标
该算法结合 region free 和 region based 检测算法的优点,主要尝试解决两个问题:
1.多尺度目标定位预测的问题。本文提出了 RON 的检测方法,首先利用一个类似于 FPN 的 Top-Down 的连接方式,融合高层特征和底层特征(其目的在这里不做过多复述),并将融合后的不同分辨率的多层特征用来进行预测。与此同时利用一个 objectness prior map 过滤掉大量背景区域,提高检测效率。
2.难例挖掘的问题。提出难例挖掘方法,提出了一套自己的选择正负样本的逻辑,以及训练时 loss 更新的策略,但整体和其他算法的思路差别不是很大。
核心思想
文章介绍了 two-stage 目标检测算法的流程,包括四个步骤:a)利用 CNN 网络提取图像特征;b)在图像的特征图的基础上确定带检测的 proposals,去掉大量的背景区域(相对于滑窗来讲);c)对提取的 proposals 进行分类与精修;d)去掉重复的预测框,输出最终的检测结果。而 region free 的(如 SSD)的算法精简了 b、c 两个步骤,将检测问题转变为一个 single shot 的问题。通过人为设置的一些固定的 proposals 直接让 CNN 学习如何对目标进行定位回归,加快了检测速度。
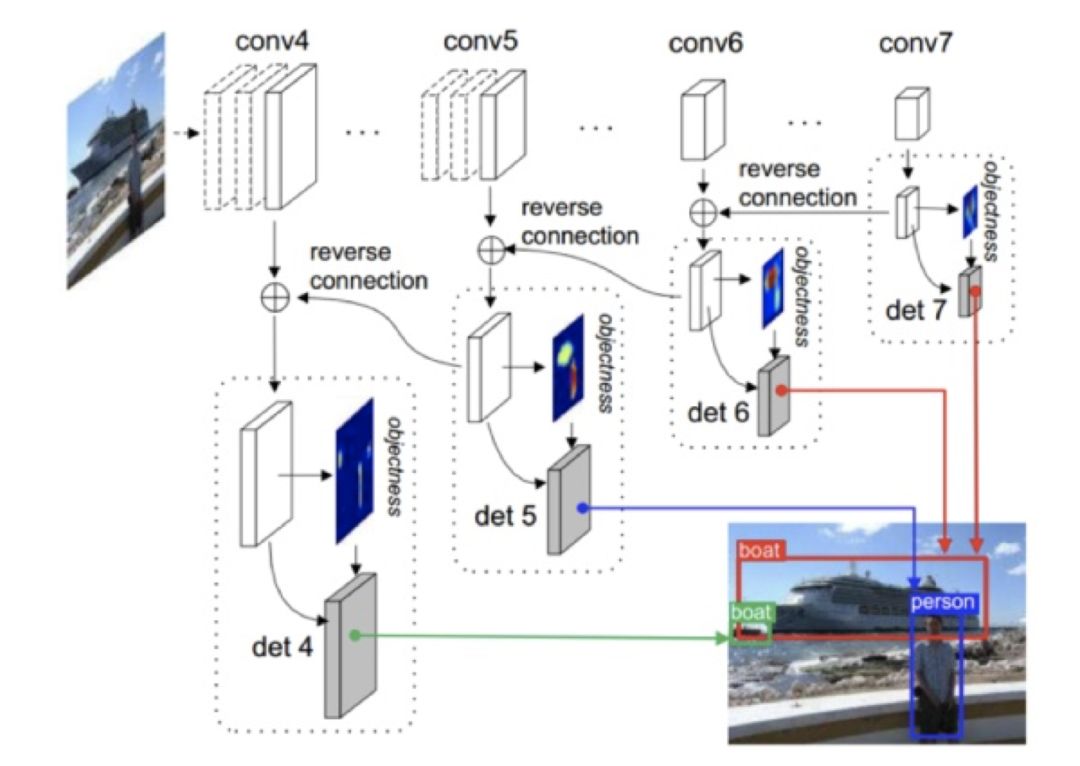
图 20
其网络结构图大致如上图所示,就 Top-Down 的结构来讲,考虑到该论文的发表时间,其实并无新意,它利用了类似于 FPN 的连接方法,即一个反卷积将高层特征图上采样,低层特征图经过一个 3*3 卷积处理,然后两者相素级相加。这种方式其实没有太多特点,采用别的其他方式应该也能达到大致相同的效果。融合后的特征层用来做最终的结果预测,其 reference box 的设置方法也和 SSD 的 default box 的设置思路大致类似,即采用如下公式:
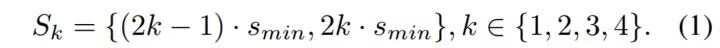
其中 Smin 定义为图像 1/10 尺寸,而每个像素点对应 5 个 aspect ratios { 1 3 , 1 2 , 1, 2, 3}。
而在读这篇论文时真正感到有新意的是作者引入了 objectness prior map 用来指导训练和预测,网络对每个预测的特征层都通过 3*3*2 卷积产生了一个分辨率完全一致的 objectness prior map,其 channel 的个数为 10,其后接一个 Softmax 的分类用于确定该像素所对应的 default box 为前景或背景。

图 21
如图所示,图中的热力图样子的图片为 objectness prior map 各个通道的均值,可以看到不同尺度的物体均只在特定的层产生了响应。利用这样的 objectness prior map,可以过滤掉大量的背景区域,也同时提高了多尺度物体的检测性能。
在训练时作者采用了和其他检测算法类似的方法,通过特定的 overlaps 的阈值对每一个 default box 进行了类别划分,前传的阶段 objectness prior map 和网络的预测输出同时进行,而反传阶段,先对 objectness prior map 的网络进行更新,然后通过设定的阈值,只对 objectness prior map 超过阈值的区域的正例进行更新。整体的正负样本比例保持在 1:3,负样本是随机选取的。
在目标预测阶段,其结构也有一点改进,如下图所示,主要工作是将分类的模块改成了 Inception 的结构提高分类的准确率。
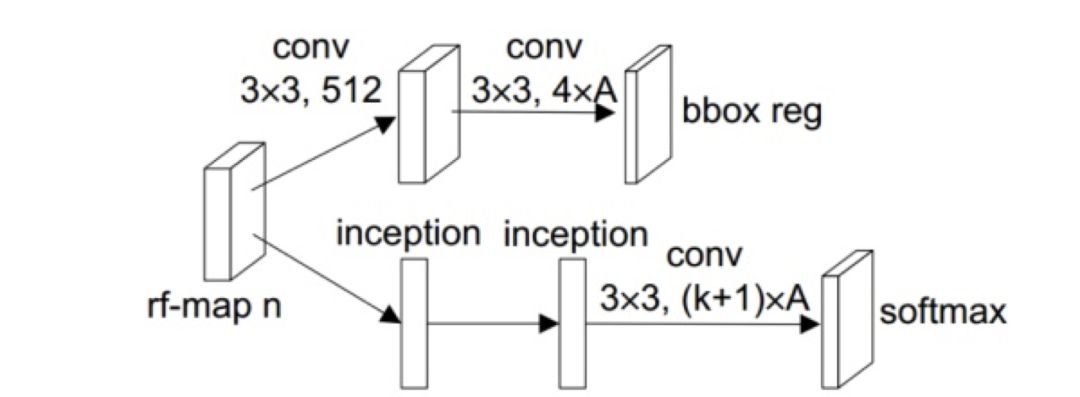
图 22
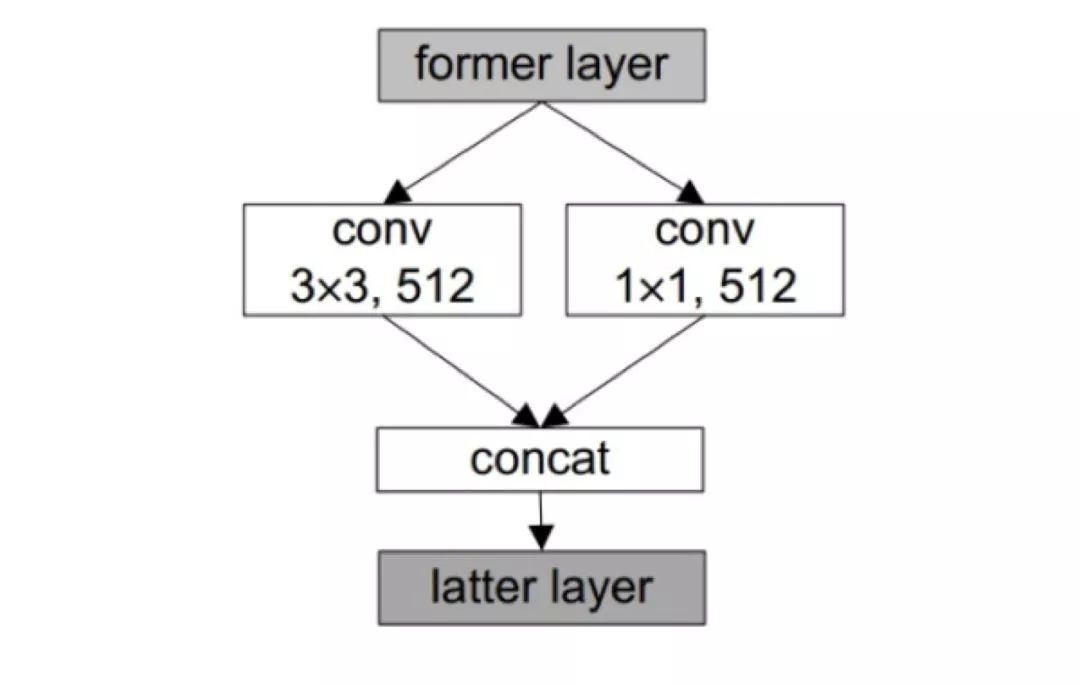
图 23
算法效果
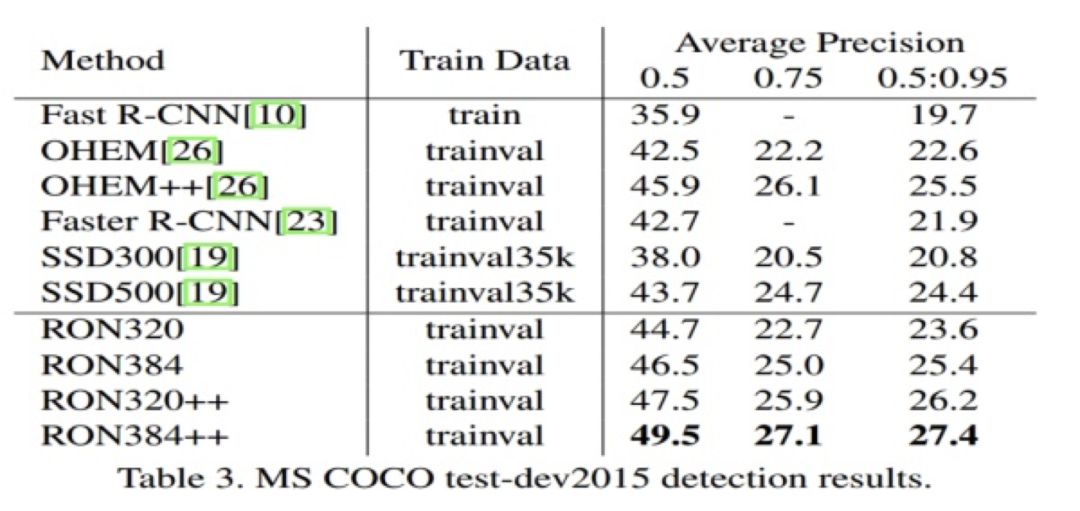
图 24
#被遮挡物体检测
Soft-NMS -- Improving Object Detection With One Line of Code
论文链接:arxiv.org/abs/1704.04503
开源代码:github.com/bharatsingh430/soft-nms
录用信息:ICCV2017
论文目标

图 25
传统 NMS 的处理方法是对检测框按检测得分排序,留下得分最高的,其他的如果 IoU 大于一定阈值就直接将其得分赋值为 0(等于去掉)。这样的话,如果遇到上面这种情况就会有问题:红框是最好的物体检测框,但是绿框和红框的 IoU 过大,所以按照 NMS 策略,绿框就直接去除,检测不到了。作者设计了一种新的 NMS 方法解决这个问题。
核心思想
计算 NMS 时,不是简单的去除值不是最高的物体,而是给 IoU 较大的框设置较小的得分。伪代码如下,修改的这行代码就是把传统的 NMS 改进为 soft-NMS。

图 26
作者使用两种方法将传统 NMS 改进为 soft-NMS:
线性方法
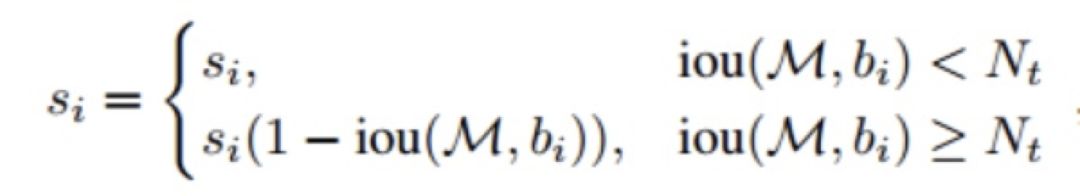
高斯加权
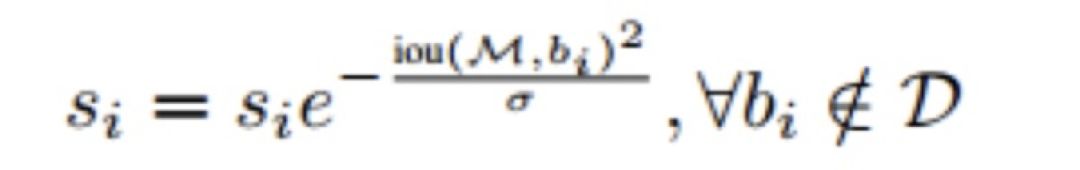
算法效果
由于 soft-NMS 主要关注的是互相遮挡的物体,从下图中的结果提升来看,像鸟、船这种容易被遮挡的物体的提升比较明显。

图 27
RRC: Accurate Single Stage Detector Using Recurrent Rolling Convolution
论文链接:arxiv.org/abs/1711.06897
开源代码:github.com/xiaohaoChen/rrc_detection
录用信息:CVPR2017
论文目标
提升被遮挡物体或小物体的检测效果。
核心思想
SSD 虽然在时间消耗和准确度上取得了不错的平衡,但是它对小物体、被遮挡的物体、同类重叠物体、照片过曝光或者欠曝光的物体检测效果不好。其原因主要是这些物体的预测位置与 ground truth 的 IoU(Intersection over Union)有时会低于 0.5。从下图的效果图(左侧图)来看虽然分类正确,位置也给出来了,但是与 ground truth 的偏差会很大,如果通过在训练过程中针对多尺度预测时,把输入的每一个特征图提高对应的 anchor boxes 的 IoU 阈值的话,SSD 的预测的准确度会大幅度下降。针对于这种情况,本文提出了 Recurrent Rolling Convolution 这种结构,在生成 anchor 大于 0.5 的时候(本文设置为 0.7)基于 SSD 的 one stage 模型针对于上所说的小物体、被遮挡物体等所预测的物体的位置会有较高的 IoU。

图 28
网络设计结构
总体设计
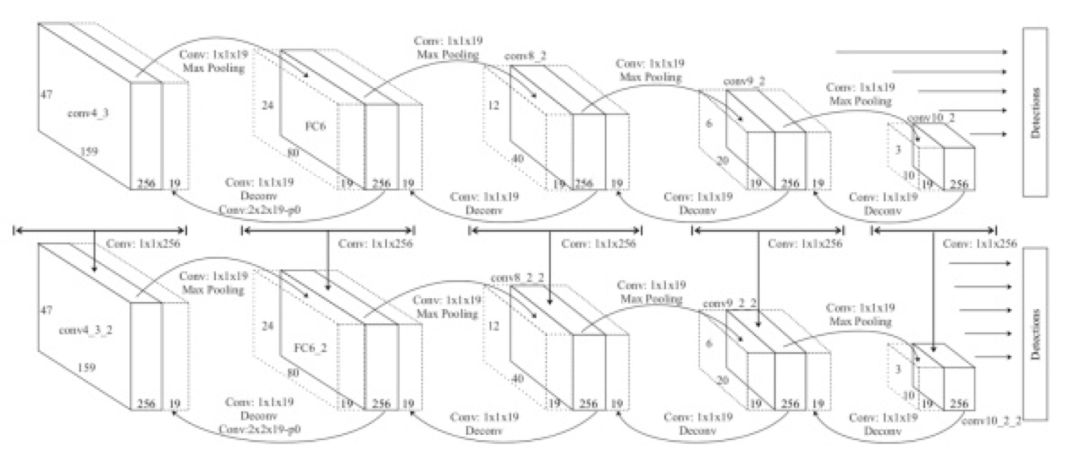
图 29
上图为连续两次 RRC 迭代的流程图。以 VGG16 的网络结构为例,RRC 在第一次迭代的计算需要输入的特征图包括 conv4_3、 FC6、conv8_2、conv9_2、conv10_2。在每一次迭代的每一个 bottom up 和 Top-Down 的阶段(图中上半部分为第一次迭代和下半部分为第二次迭代中)从左往右箭头使得网络历经
loss函数
下图中的 
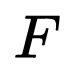
图 30
实现的一些细节
对于网络的体系结构, RRC 迭代 5 次,使用 5 层的卷积图来预测框回归和分类任务。实验通过验证 RRC 的
算法效果
需要注意的是由于本文主要解决的是遮挡物体检测的问题,作者使用了 KITTI 数据集(汽车)进行测试。KITTI 数据的物体互相遮挡比较常见,可以更好的反映出算法的优化效果。
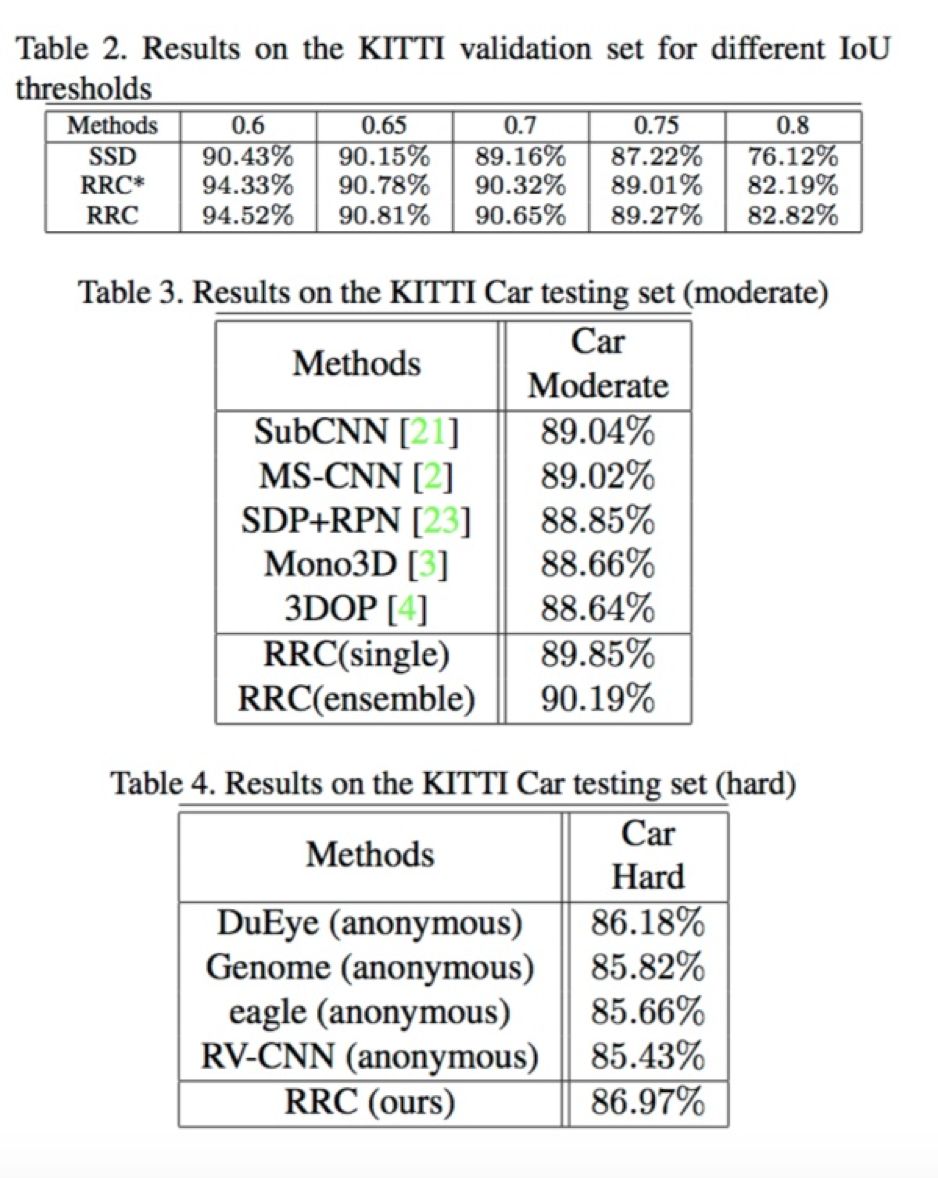
图 31
#解决检测mini-batch过小的问题
MegDet: A Large Mini-Batch Object Detector
论文链接:arxiv.org/abs/1711.07240
开源代码:/
录用信息:CVPR2018
论文目标
解决大规模 Batch Size 的训练问题;缩短训练时间,提高准确率。
核心思想
对于图片分类任务,网络只需识别其中主要的物体,由于其占图片的比例较大,导致所需图片的尺寸相对较小,因此相应的 Batch Size 很大。而对于检测任务,需要检测一些精细的物体,经深度神经网络训练之后,图片的尺寸以 2 的倍数减小。因此,为了保证最后一张特征图上小尺寸物体依然占有一定比例,需要输入一张较大尺寸的图片,然而这将导致图像检测所需的显存同比例增长,使得已有的深度学习框架无法训练大规模Batch Size 的图像检测模型。
小 batch-size 有如下缺点:a.训练时间久;b.不能为 BN 提供准确的数据;c.正负样本比例不均衡;d.梯度不稳定的缺点。然而增加 Batch Size 需要较大的 learning rate,但是如果只是简单地增加 learning rate,可能导致网络不收敛,如果用小的 learning rate 确保网络收敛,效果又不好。具体改进如下:
1.Variance Equivalence,即使用梯度方差等价代替梯度等价。在之前的工作中经常使用 Linear Scaling Rule,即当 Batch Size 变为原来的 k 倍时,learning rate 也应该变为原来的 k 倍。但是在分类里,损失只有 Cross-Entropy,然而在检测里,图像之间有不同的 Ground-Truth 分布。结合两个任务的不同,分类任务的 learning rate 规律并不适合检测任务。基于此,论文提出了方差等价来代替梯度等价。
2.Warmup Strategy,即刚开始训练的时候,learning rate 设置的小,随着每次迭代,逐渐增加 learning rate。例如,16-batch 的 FPN 学习率为 0.02,在训 256 的 MegDet时,如果设置 lr=0.02*16,会导致模型发散,因此需要逐渐增加 lr,让模型适应。随后随着训练逐渐减少 lr,确保网络精度提高。
3.Cross-GPU Batch Normalization,在分类里,图片大小通常为 224 或 299,所以一块 TitanX 可以容纳 32 张图,或者更多。然而对于检测来说,检测器需要接受各种尺寸的图片,因此会限制一个设备容纳的图片数。所以,需要跨 GPU 从多个样本提取不同的数据完成 BN。如下图所示:
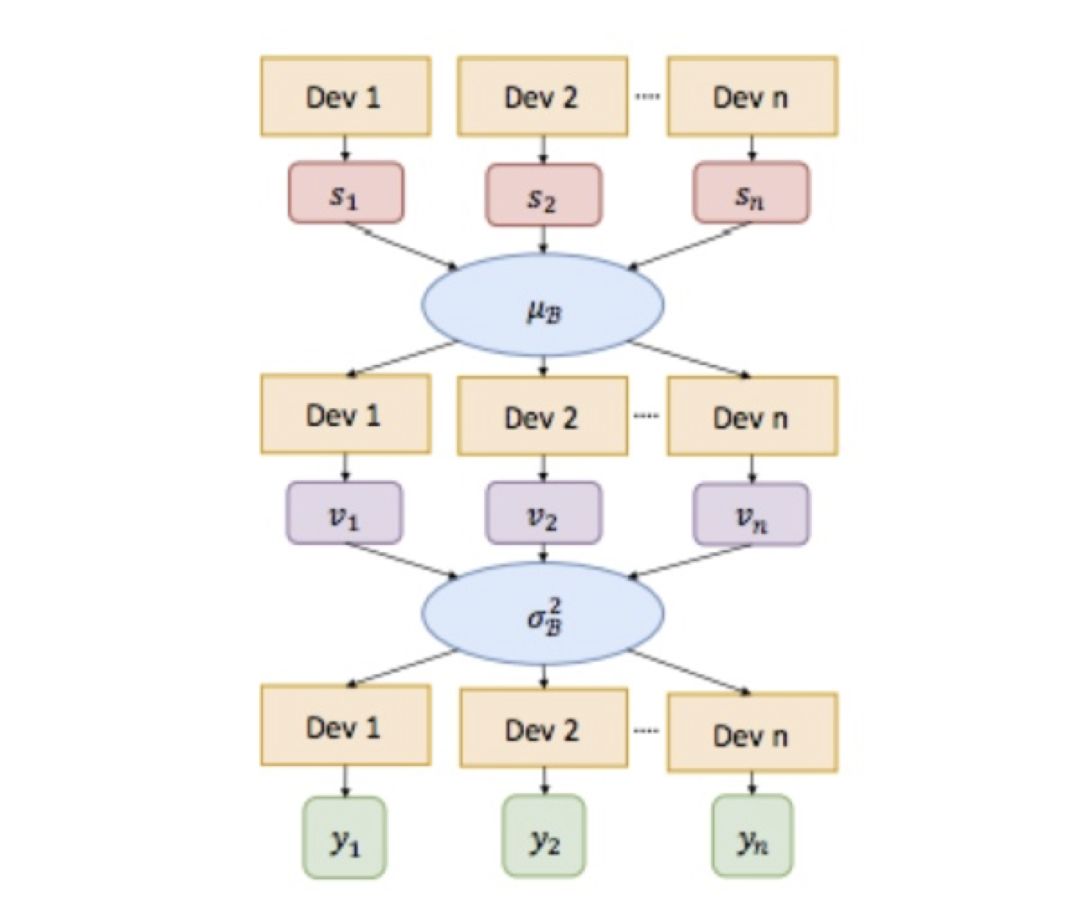
图 32
BN 操作需要对每个 batch 计算均值和方差来进行标准化。其中对于多卡的具体做法是,首先聚合算均值,然后将其下发到每个卡,随后再计算 minibatch 的方差,最后将方差下发到每个卡,结合之前下发的均值进行标准化。
算法效果
论文提出了 warmup learning rate 和跨 GPU BN 机制,使训练时间缩短(从 33 到 4 小时),而且准确率更高。使用同样在 COCO 数据集上训练的 FPN 框架,使用 256 的 batch-size 比使用 16 的 batch-size,验证集精度更高,且训练时间更少(如下图所示)。使用 MegDet 做 backbone 的检测网络获得了 COCO2017 冠军。
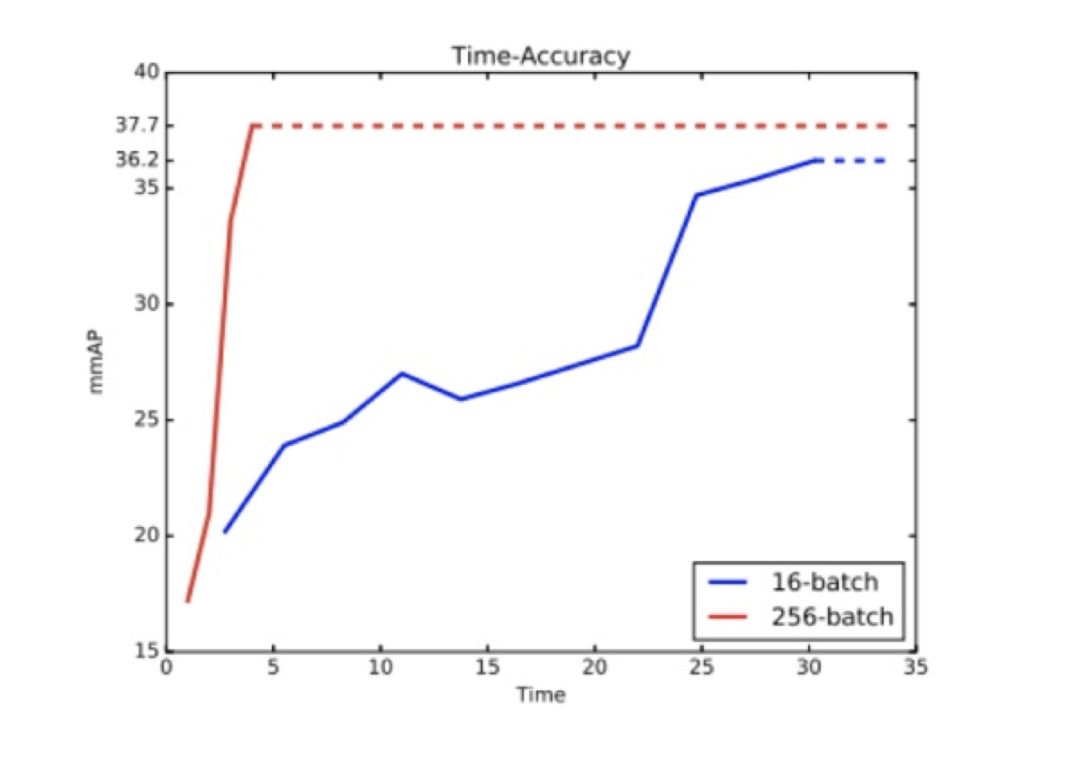
图 33
#关注物体之间的关联性
Relation Networks for Object Detection
论文链接:arxiv.org/abs/1711.11575
开源代码:github.com/msracver/Relation-Networks-for-Object-Detection
录用信息:CVPR2018
论文目标
绝大多数的检测类论文对目标物体都是独立检测,忽略了目标物体彼此之间的关联性信息。本文作者受 NLP 领域注意力方法启发,提出了一种有效度量物体关联性信息的新方法。作者将该方法用于物体识别、重复框消除等阶段,均取得了显著的效果,实现了一种完全的端到端物体检测。在实际应用中,relation module 可以用来替换 NMS。
核心思想
本文主要创新点有两方面。一方面是提出了物体关联性信息有效度量的新方法:relation module;另一方面是该方法在物体识别和重复框消除中的应用。在物体识别中,relation module 可以将关联性信息融入提取后的特征中,并能保持特征维数不变。因此该方法可以方便地嵌入到各种检测框架中,用于提升性能。在重复框消除中,使用 relation module 替换 NMS,使得重复框消除这一环节能够更有效的融入整个学习过程,下面具体介绍下 relation module 以及它在物体识别和重复框消除中的应用。
Relation module
示意图如下:
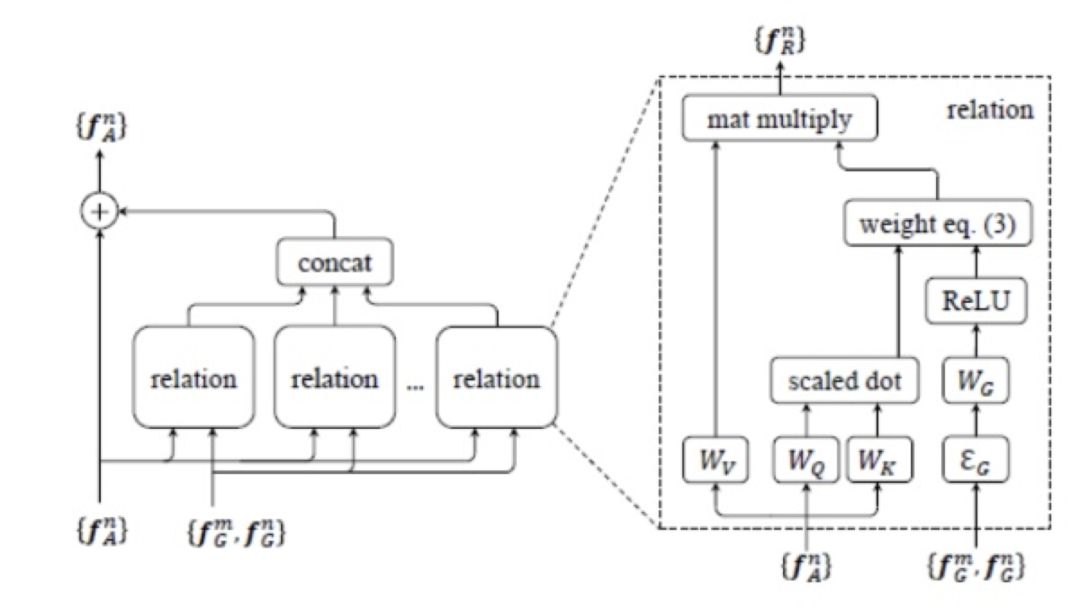
图 34
其中

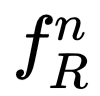
对于上图右边的每一项,作者都给出了具体的解释和计算公式,读者可以阅读原文了解细节。需要指出的是,通过一系列的变换和限制,在 concat 所有的 relation,并与原来的特征叠加后,特征的维数并没有发生改变。
物体识别应用
现在绝大多数的检测算法均采用如下处理步骤:
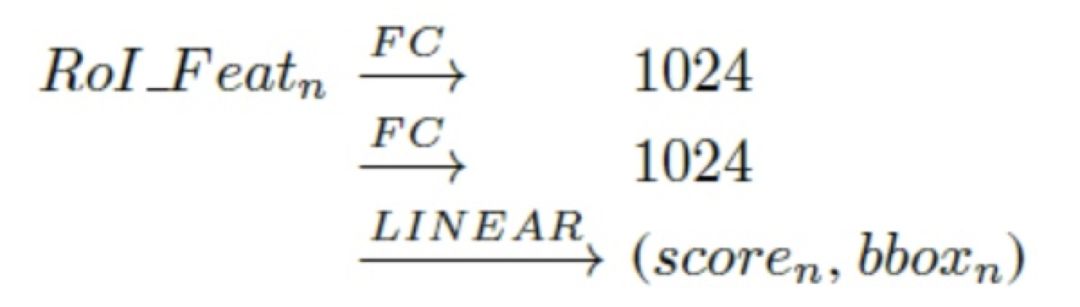
如前所述,relation module 并不改变特征的维数,所以可以非常方便的添加到 fc 层之后,形成 2fc+RM(relation module)的结构,实现如下结果:
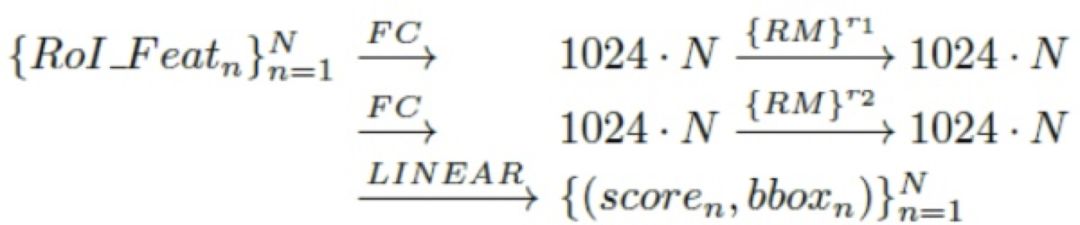
其中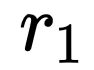
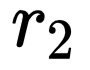
重复框消除应用
作者将重复框消除当做了一个二分类问题。对于每个 ground truth,只有一个 detected object 被归为 correct 类,而其余的都被认为是 duplicate 类。
对于每个 detected object,首先按照物体识别阶段的输出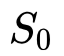
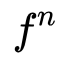
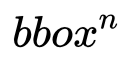
将 relation module 的输出经过一个线性分类器和 Sigmoid 函数后,得到分数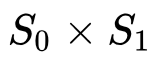
IoU超过阈值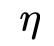
示意图如下:
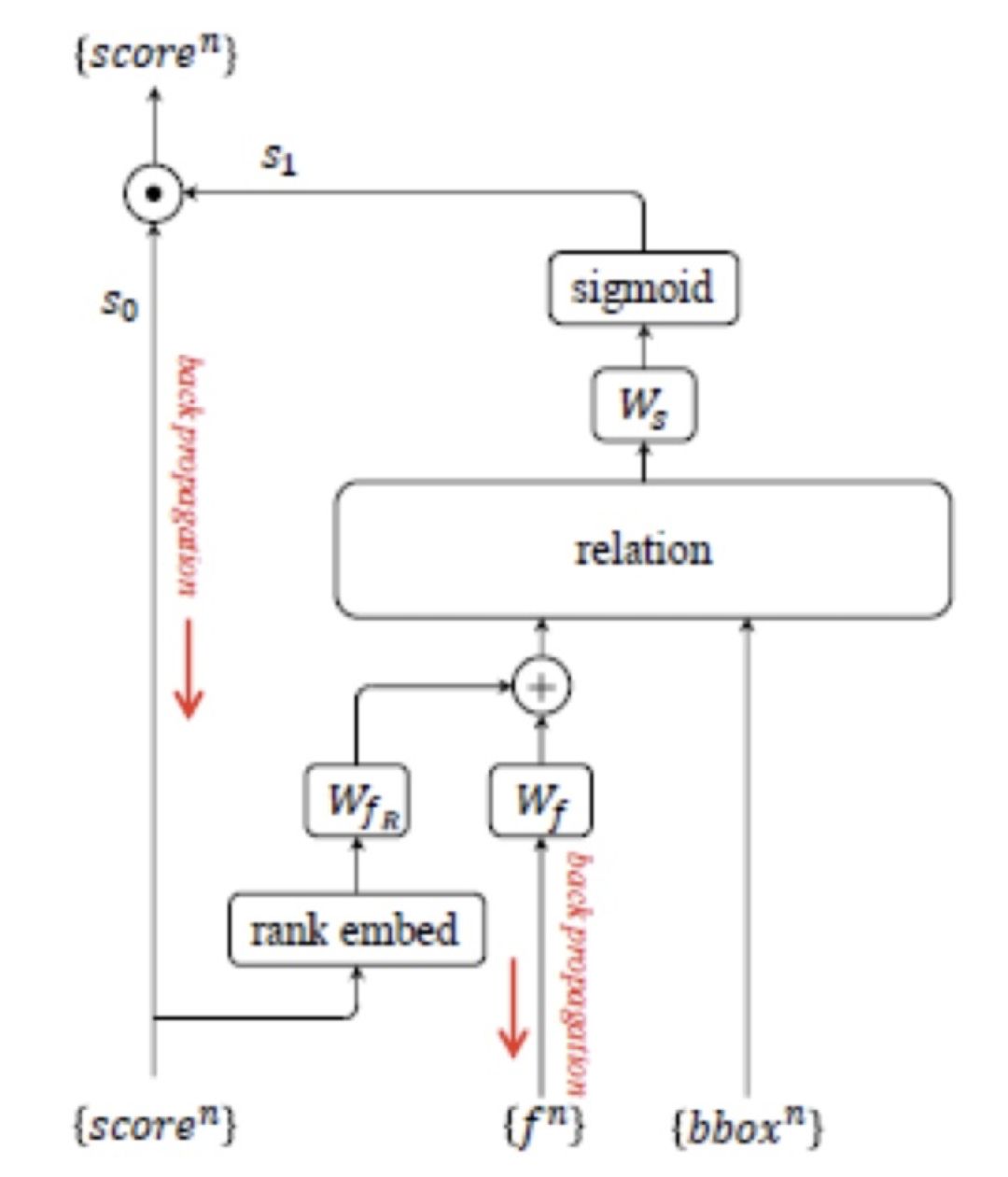
图 35
在训练和推理中,作者都给出了详细的策略,读者可以阅读原文了解细节。需要指出的是,不管是 NMS 或 SoftNMS,在学习过程中,重复框消除只是一种孤立的处理手段,并不参与模型参数的更新,而采用 relation module 方法,重复框消除既可以单独训练,也可以融入到整个模型参数的更新中,从而实现完全的 end to end 训练。
算法效果
作者在 COCO 数据集上进行了实验,采用了 ResNet-50 和 ResNet-101 作为基础网络。关于物体识别效果,作者实验了 geometric 特征的作用、relation 的个数、relation module 的个数,结果如下所示:

图 36
关于重复框消除效果,作者对比实验了 NMS、SoftNMS 以及本文方法,结果如下:
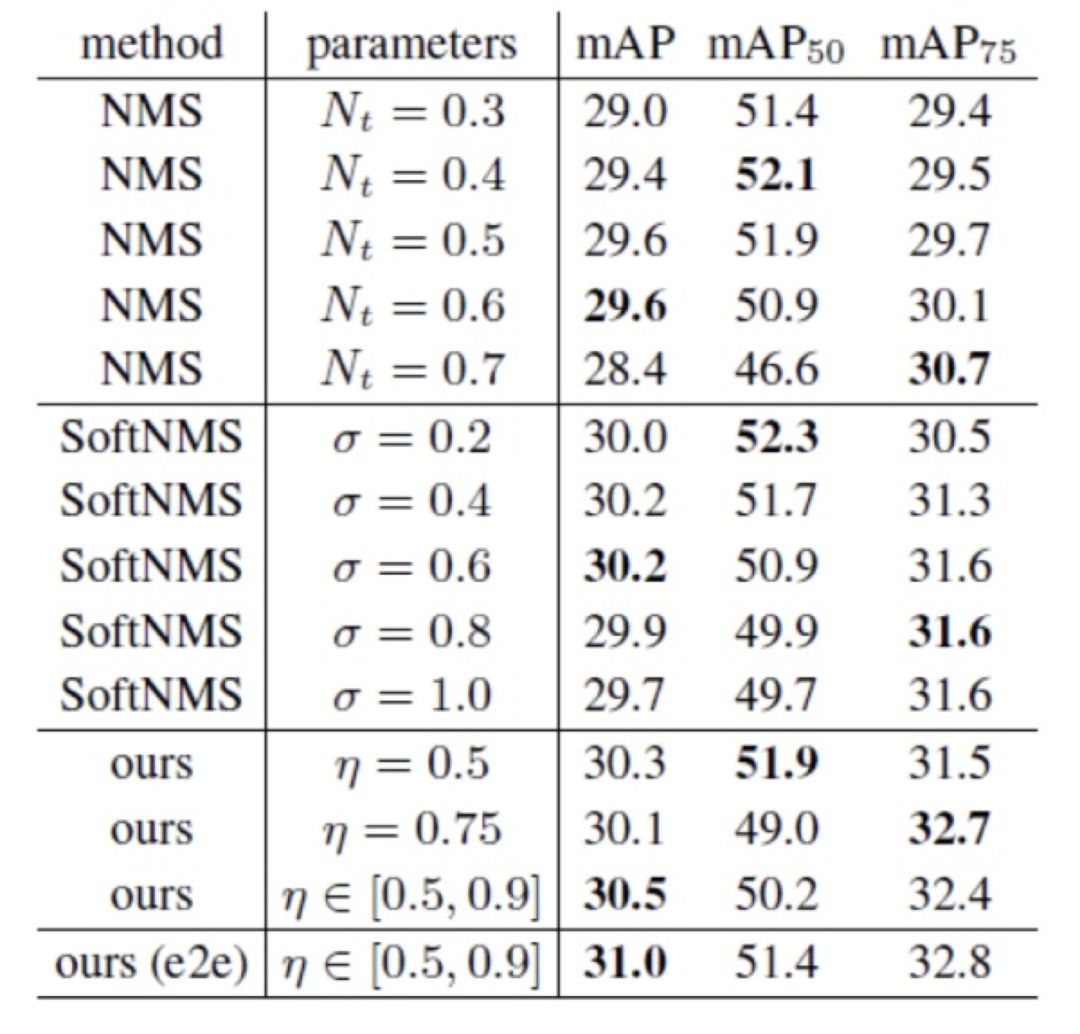
图 37
关于端到端训练效果,作者对比了 Faster R-CNN、FPN、DCN 三种检测框架。针对每一种框架,分别使用了 2fc +SoftNMS -> 2fc+RM +SoftNMS -> 2fc+RM +e2e(end-to-end)三种网络结构,实验结果如下:

图 38
#改进网络结构以提升效果
DetNet: A Backbone network for Object Detection
论文链接:arxiv.org/abs/1804.06215
开源代码:/
录用信息:ECCV2018
论文目标
讨论分类模型和检测模型各自特点,重新设计了一个适合检测任务的网络模型。
核心思想
该论文提出一种专门用于目标检测的主干网络结构 DetNet,主要的贡献在于探讨了当前主流的 CNN 网络对于目标检测任务上的弊端。当前常用的 CNN 网络结构都是基于分类任务所设计的,其特点是存在大量的 pooling 层,最后的特征图会被压缩的非常小。Pooling 层会造成特征的部分位移实际上对位置信息很重要的检测任务来讲比较不友好。而分类任务被分类的部分往往在图像中占主体,最后特征层比较小其实并无影响,而且这样感受野变大使得单位特征可以包含更丰富的信息。但是对于检测任务来讲,目标在图中所占比例是不固定的,有可能非常小。低分辨率高感受野的特征会丢失太多细节信息导致小物体的检测困难。所以适合检测的网络应当有着较高的分辨率,但是这样会带来计算量增长和感受野降低的弊端。DetNet 通过精细的设计平衡了这两个问题。
在论文中作者以 ResNet50 为例,将 ResNet50 通过改进变成适合检测任务的网络。文中提到味了保证公平性,ResNet50 网络的前 4 个 stage 未作改变,而在第 4 个 stage 之后引入的空洞卷积的操作。
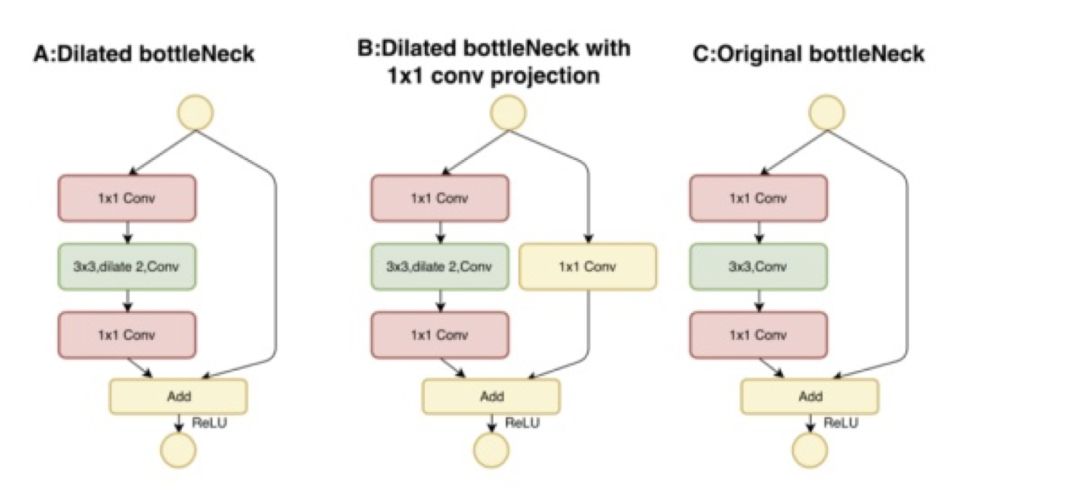
图 39
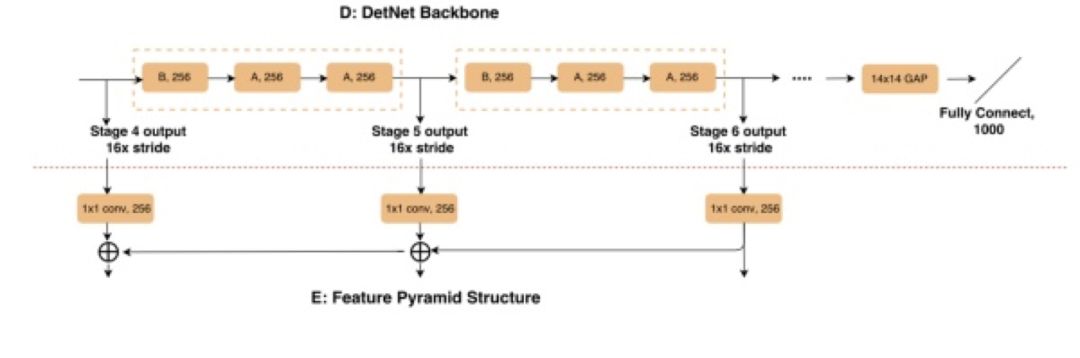
图 40
如上图所示,该网络在第四个 stage 之后便不在进行下采样,特征的分辨率不会进一步降低。此时特征的 stride step= 16。而引入空洞卷积的操作便是为了克服感受野小的问题,但是值得注意的一点是,随着网络的变深,空洞卷积的尺度并没有相应的变大。作者是因为变大效果不好所以没有变大还是无意而为之也没有进行讨论,这个其实是个挺值得大家去做的一个实验,没有这个实验我们没法得出到底多大的感受野范围是最适合目标检测任务的。与此同时,为了进一步减小计算量,自 stage4,网络 channel 的数量便不再增多,而是保持一样。这样的网络结构使得该网络也同样适合用和检测中常见的 Top-Down 结构同时使用,由于预测层分辨率没有变化,所以使得高层特征和底层特征融合更加的容易,免去了上采样的步骤。
我认为论文与其说提出了一个全新的检测适用的网络倒不如说改进了分类网络的不足,或是说提出了一个重新设计检测网络的思考方向。目标检测算法发展到现在,各个流程趋于稳定与同质化。在底层特征的研究可以作为一个新的方向,CNN 在卷积的过程中如何更好的体现位置坐标信息,如何对于不同尺寸的物体都保持较好的响应,都是优化检测任务的重点。本论文的网络设计虽然看似简单,但思考的出发点实际上是非常深刻且能解决实际问题的。而且其中一些操作,如预测层的 channel 没有继续变多,是否也能体现出检测网络的一个特性?其背后的原因又是什么?希望未来可以看到更多基于特定任务的特性而单独设计的网络结构。
算法效果
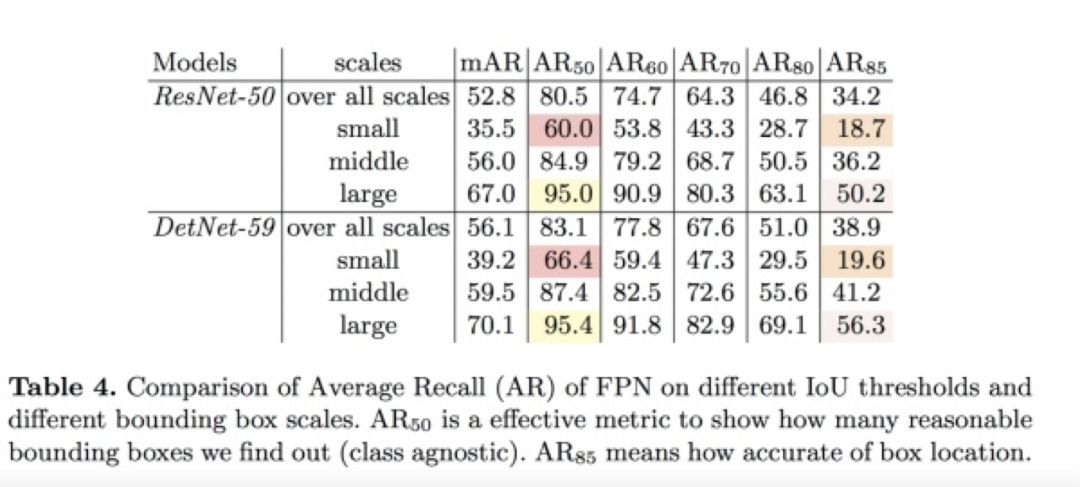
图 41
RefineDet:Single-Shot Refinement Neural Network for Object Detection
论文链接:arxiv.org/abs/1711.06897
开源代码:github.com/sfzhang15/RefineDet
录用信息:CVPR2018
论文目标
通过实现对 ssd default box 的二次精修提升检测效果。
核心思想
one stage 的网络结构,位置框和物体的类是在同一个特征提取层来做回归和分类预测的,这种的网络运算速度虽然快但是准确度不够高,准确度不够高的一个重要原因是因为框的正负样本数目比例失衡严重,two stage 的网络由于引入了 Region Proposal Networks 使得框的回归任务精度变高,该网络筛出了大量的负样本框(正负样本比例控制在 1:3)解决了正负样本不平衡的问题。RefineDet 是基于 SSD 的改进算法,该算法主要是 bottom up(网络结构图上半部分)的网络结构来回归粗略位置参数来调整anchor的位置以及框的二分类(是否是物体的位置)任务,用 Top-Down(网络结构图下半部分)的网络结构相对于调整的anchor的参数来回归精细物体位置和框内物体的分类任务。可以看出 bottom up 的运算就是来解决正负样本框数目不平衡问题的。
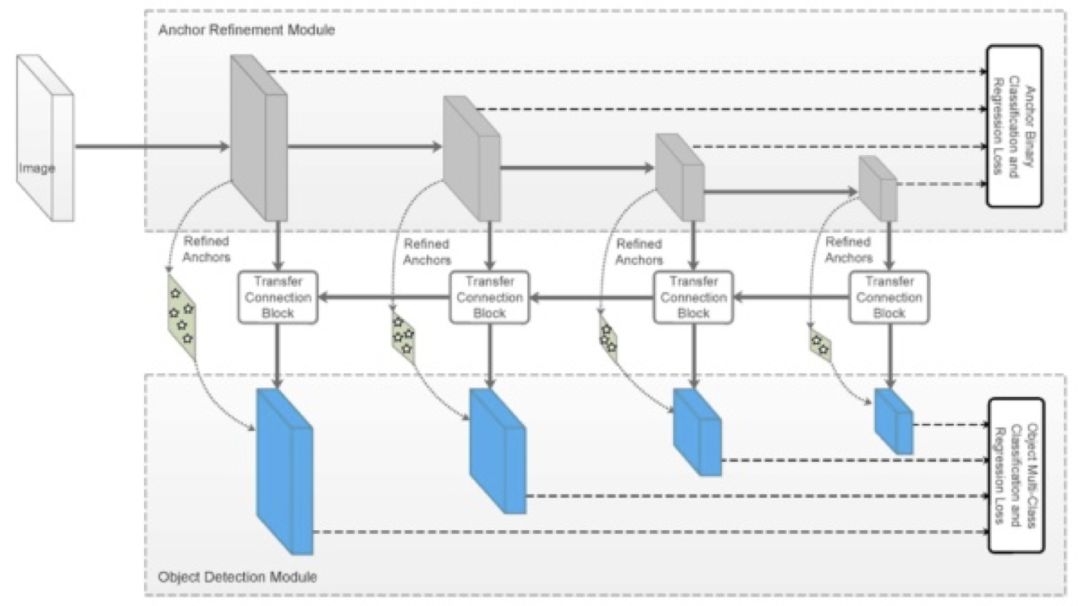
图 42
网络总体来说就是把 SSD 这个 one stage 模型,通过加入 Top-Down 的方法变成 two stage 模型。bottom up 阶段(论文称之为 arm,anchor refinement module)为常规 SSD 多尺度预测阶段,做预测所提取的特征图分别为:conv4_3,conv5_3,fc7,conv6_2。每一个特征图都会有两个子网络分支,为别为预测 anchor 位置的子网络mbox_loc(3 组 w, h, x, y,子网络卷积层的 channel 为 12)和预测是否为 anchor 类别的子网络 mbox_conf(3 组 0,1,子网络卷积层的 channel 为 6),筛选出的负例样本置信度高于 0.99 的就不会传入到 Top-Down 阶段(论文称之为 ODM,object detection module)以此来控制正负样本的比例不均衡问题。
将 arm 阶段预测出来的结果调整 anchor 参数(conf:0/1,w,h,x,y 图中标记为 refined anchors),将特征图 conv4_3,conv5_3,fc7,conv6_2 输入给 TCB 单元(transfer connection block)得到 P3, P4, P5, P6 传入给 ODM 阶段。TCB 单元实质上就是 Top-Down 结构,作用就是使得多尺度特征图的信道融合以此来丰富特征。最后生成的特征图为:P3, P4, P5, P6(其中 P3, P4, P5, P6 的生成分别对应 arm 中的 conv4_3,conv5_3,fc7,conv6_2 相对应,特征图的尺寸分别是
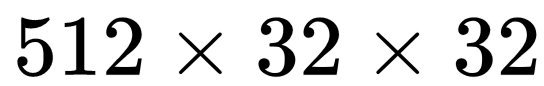
、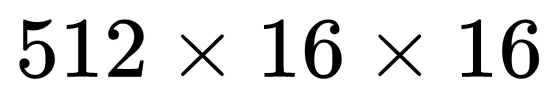
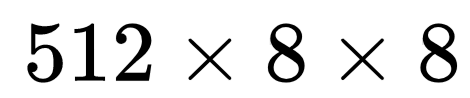
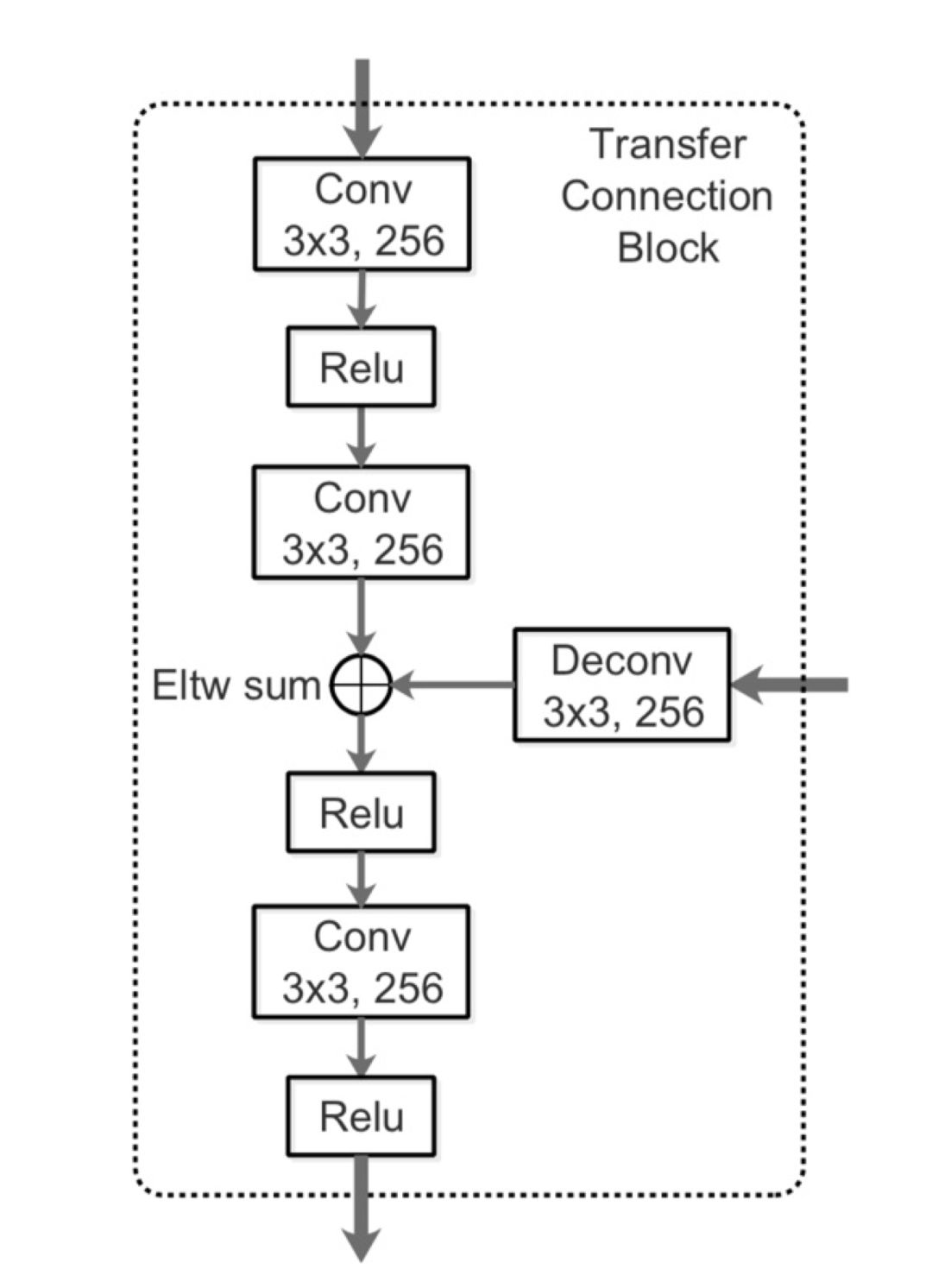
图 43
在 Top-Down 阶段做框精细调整的回归和物体分类任务。每一个特征图都会有两个子网络分支,为别为精细调整anchor位置的子网络 mbox_loc(3 组 w, h, x, y,子网络卷积层的 channel 为 12)和预测是否为物体类别的子网络 mbox_conf(3 组 81 类样本,因为是分类 coco 数据集,子网络卷积层的 channel 为 243)。
网络训练过程是端到端的训练方法,loss 函数也是常规的分类 Softmax 和目标检测的框回归 smoothL1。损失函数公式如下所示:
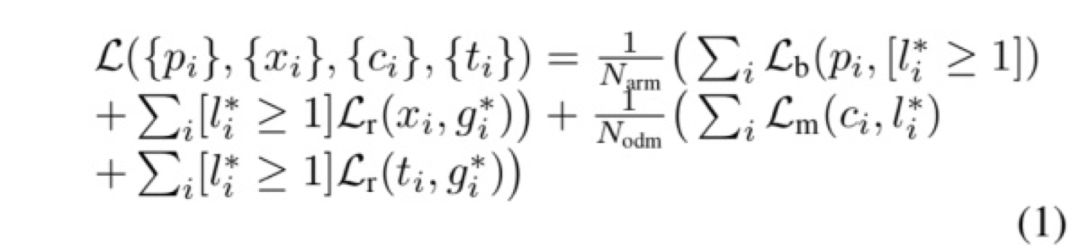
其中,i 为一个 batch 里面预测 anchor 的序列,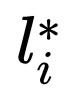
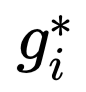
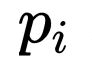
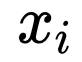
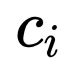
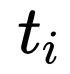
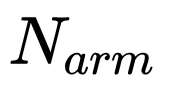
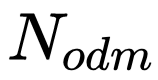
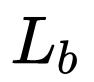
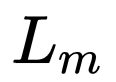
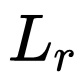
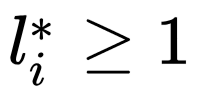
在 coco 的数据集上,选用 vgg16 的网络结构,全部的图片 resize 到
算法效果
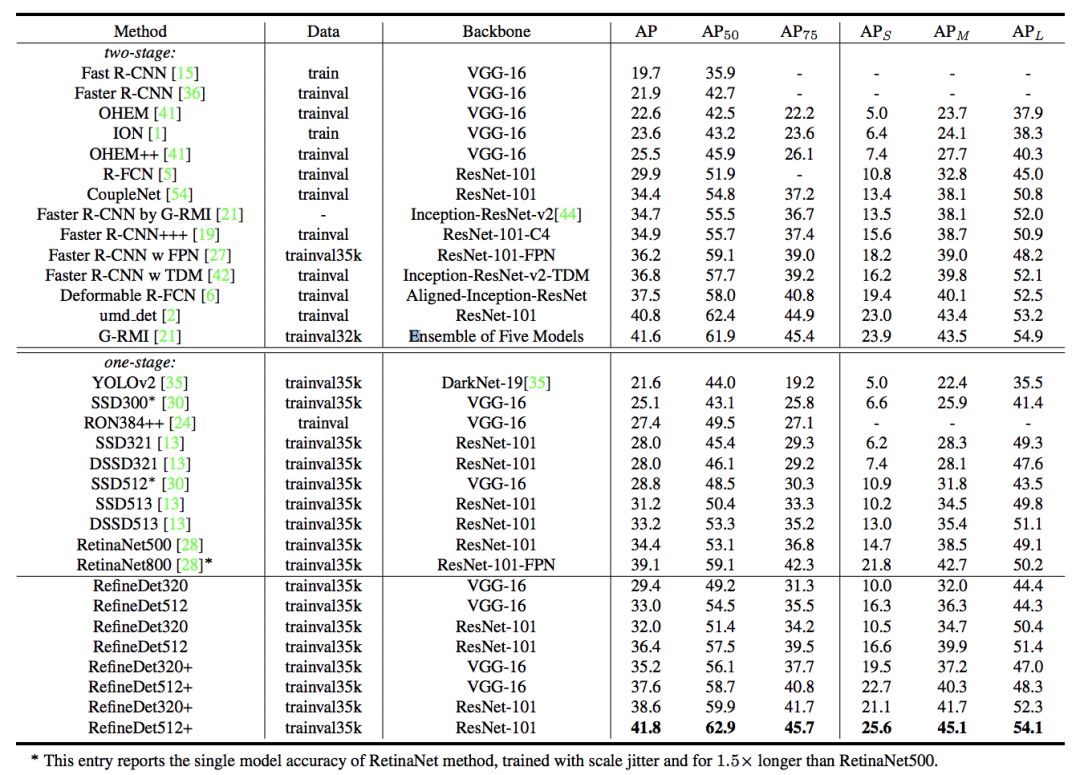
图 44
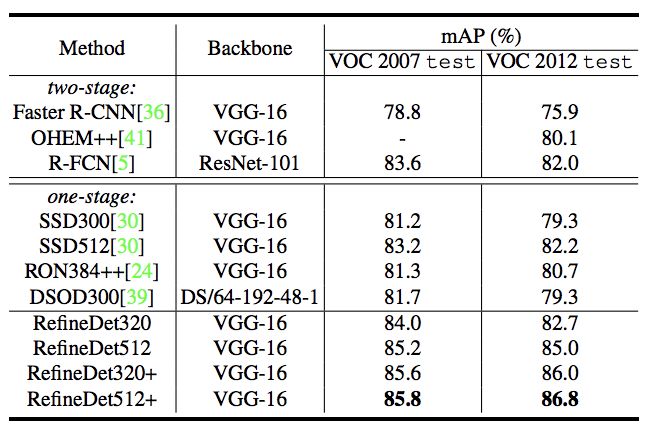
图 45
以上效果为在 VOC 和 COCO 数据集上的 mAP 对比。
Pelee: A Real-Time Object Detection System on Mobile Devices
论文链接:arxiv.org/abs/1804.06882
开源代码:github.com/Robert-JunWang/Pelee
录用信息:CVPR2018
论文目标
在网络结构设计上更加精致,可以在移动端进行实时物体检测。
核心思想
Two-Way Dense Layer
Pelee 使用两路卷积层来得到不同尺寸的感受野。
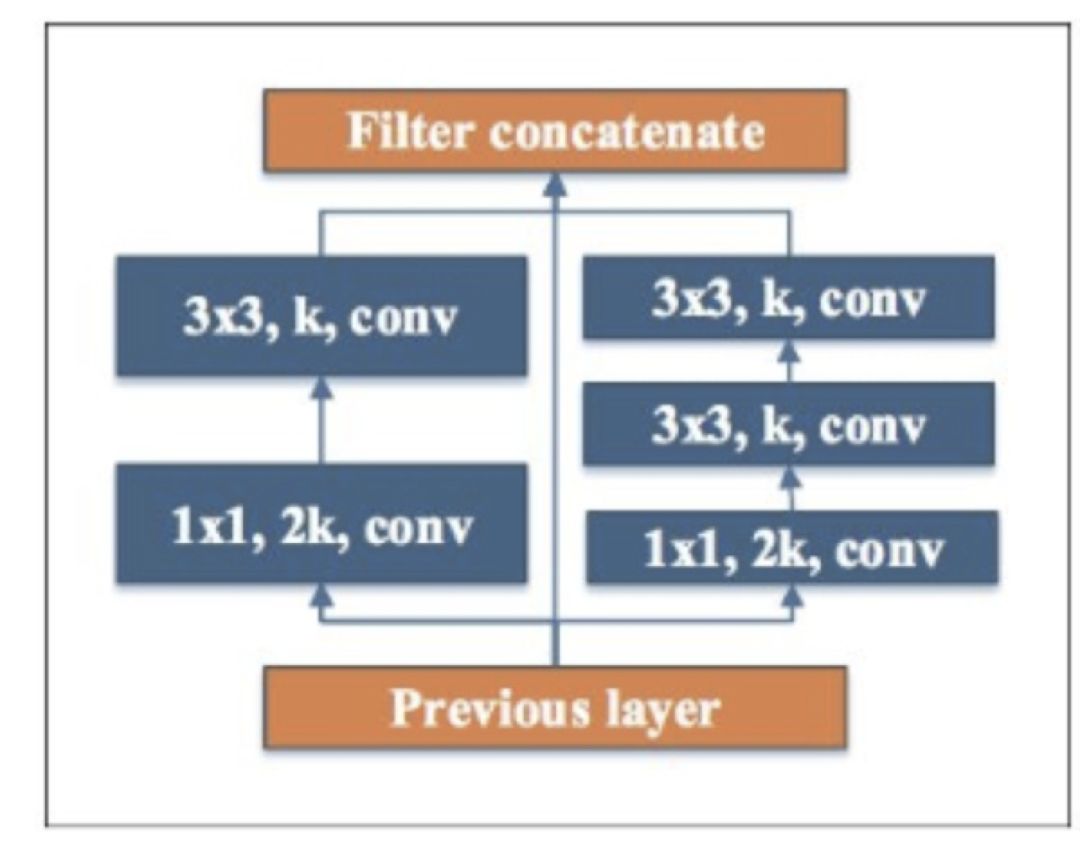
图 46
左边先通过 1 x 1 卷积,后面接 3 x3 卷积,使其对小物体有更好表现。右边先通过 1 x 1 卷积,两个 3 x 3 卷积代替 5 x 5 卷积,有更小的计算量和参数个数,且对大物体有更好表现。
Stem Block
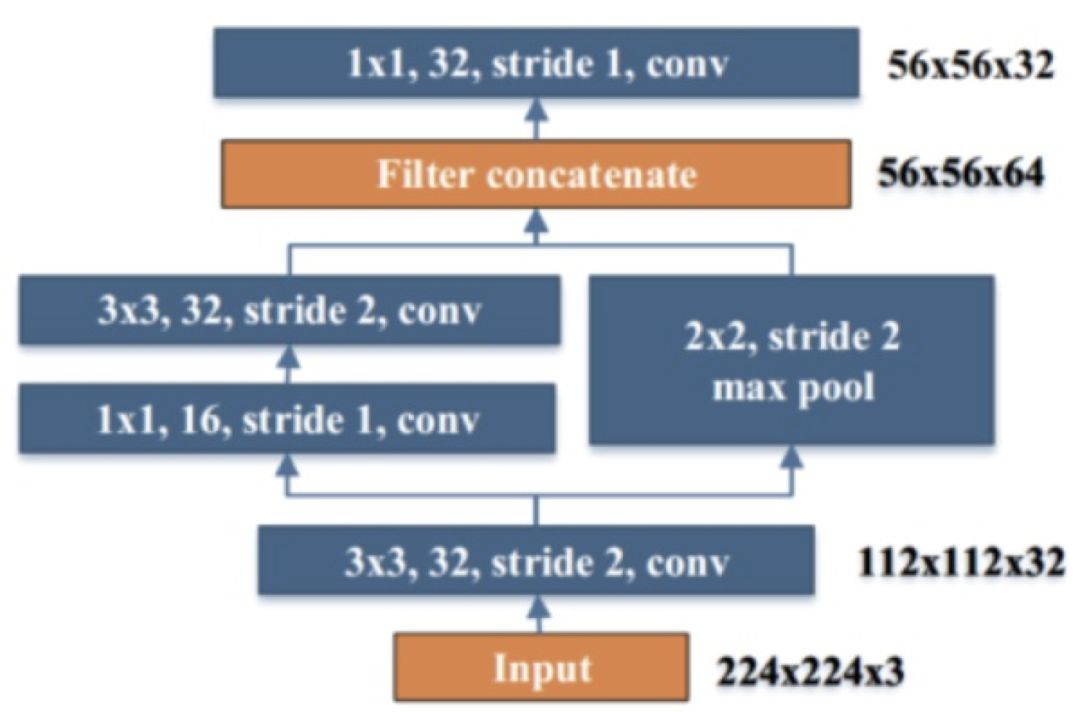
图 47
网络前几层对于特征的表达十分重要,Pelee 采用了类似于 DSOD 算法的 stem block 结构,经实验可知该结构可以在不增加过多计算量情况下提高特征表达能力。
动态调整 bottleneck layer 通道数
bottleneck layer 通道数目随着输入维度的变化而变化,以保证输出通道的数目不会超过输出通道。与原始的 DenseNet 结构相比,实验表明这种方法在节省 28.5% 的计算资源的同时仅会对准确率有很小的影响。
过渡层不压缩
实验表明,DenseNet 提出的压缩因子会损坏特征表达,Pelee 在转换层中也维持了与输入通道相同的输出通道数目。
Bn 层与卷积融合,起到加速的作用
舍弃了以前的 bn-relu-conv 采用了 conv-bn-relu 形式。Bn 层与卷积层融合加快推理速度(融合部分计算),同时后面接了 1 x 1 卷积提高表达能力。
作者将 SSD 与 Pelee 相结合,得到了优于 YOLOV2 的网络结构。使用 Pelee 作为基础网络对 SSD 改进:
1. 舍弃 SSD 的 38 x 38 的 feature map。
2. 采用了 Residual Prediction Block 结构,连接了不同的层。
3. 用 1 x 1 卷积代替 SSD 里的 3 x 3 卷积做最终物体的分类与回归。减少了 21.5%的计算量。
具体网络结构:
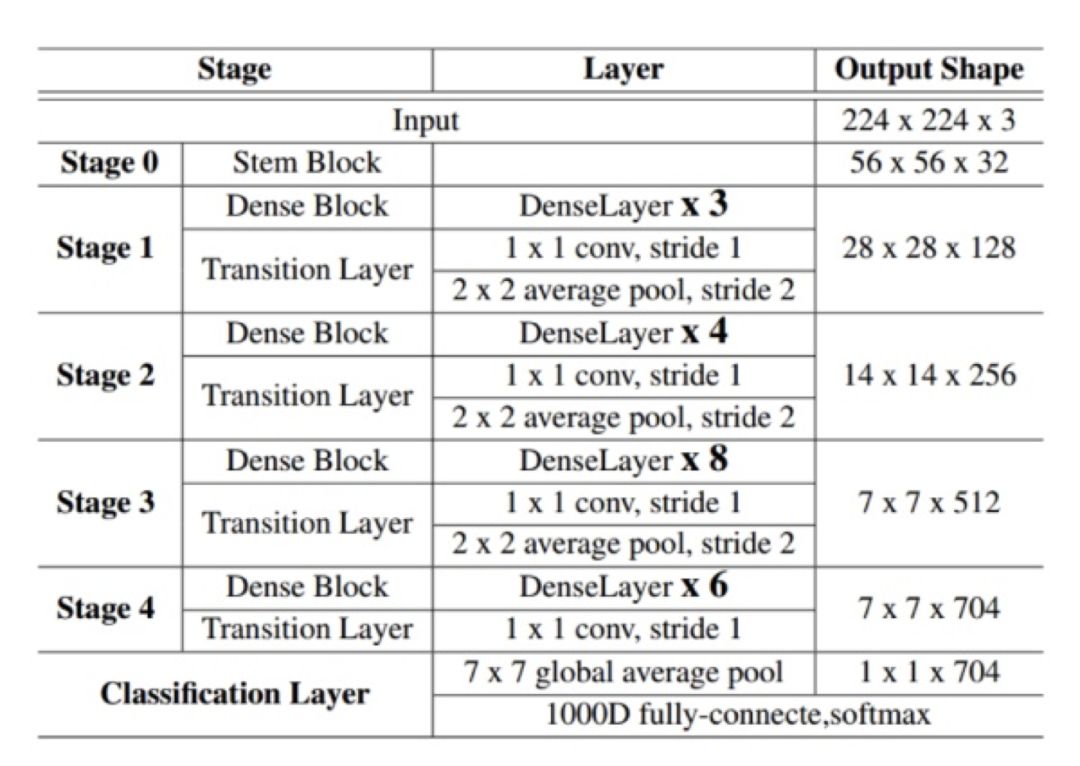
图 48:分类网络结构图
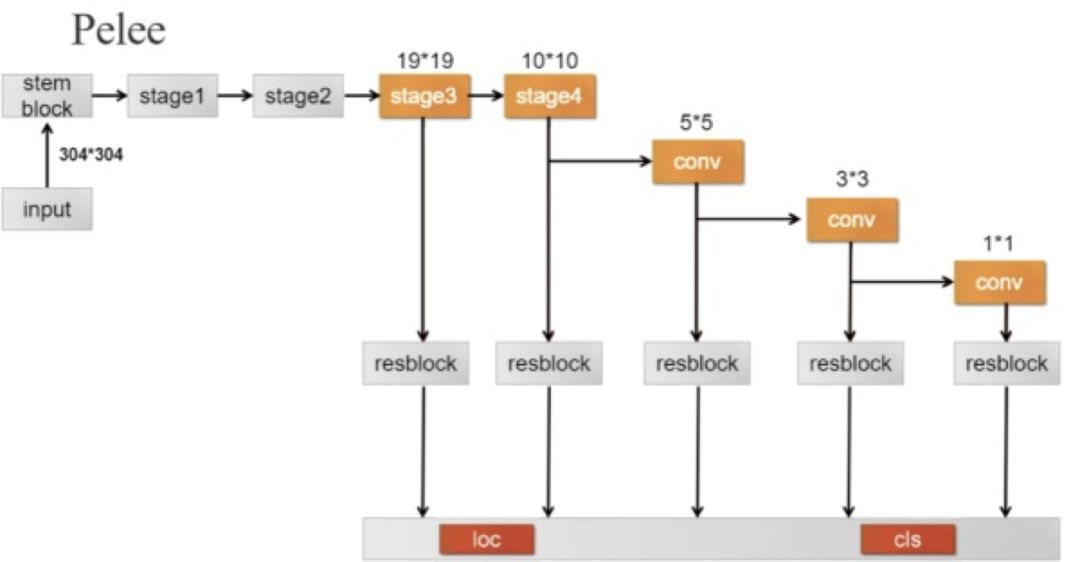
图 49
首先图片输入后经过 Stem Block 结构,再通过 stage1、 stage2、stage3、stage4 及后续卷积操作得到相应 feature map,接 resblock 结构后进行分类及位置回归。
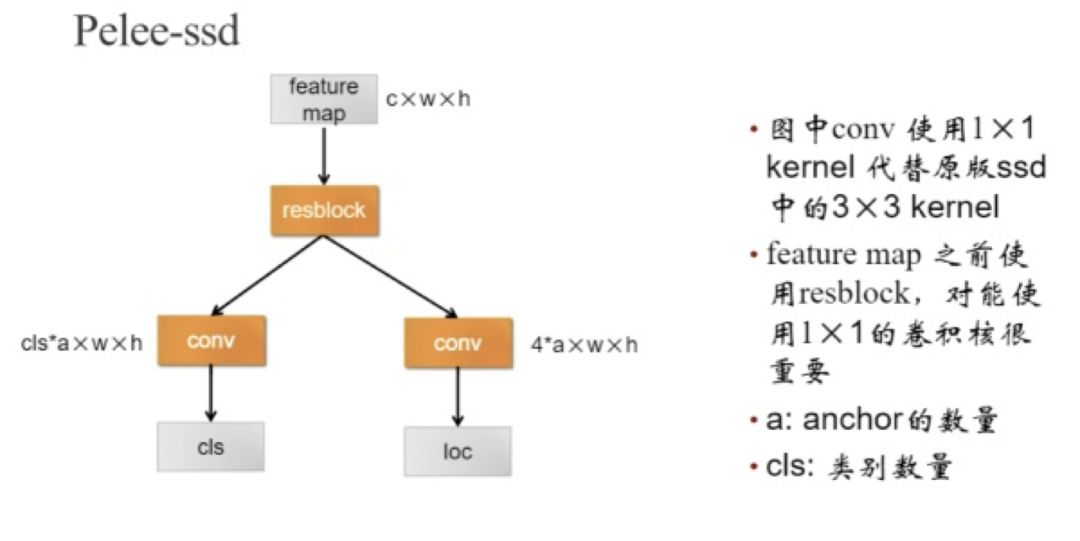
图 50
算法效果
结合 SSD,在 VOC2007 数据集上达到了 76.4%的 mAP,在 COCO 数据集上达到了 22.4%的 mAP。在 iPhone 6s 上的运行速度是 17.1 FPS,在 iPhone 8 上的运行速度是 23.6 FPS。
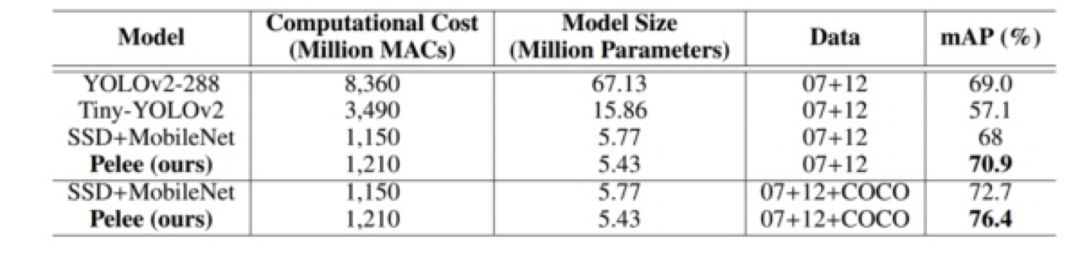
图 51

图 52
Receptive Field Block Net for Accurate and Fast Object Detection
论文链接:arxiv.org/abs/1711.07767
开源代码:github.com/ruinmessi/RFBNet
录用信息:/
论文目标
一些检测论文会依赖很深的 CNN 网络来提升效果,但此类网络会牺牲运行速度。在 RFB 论文中,作者由视觉感受野(Receptive Fields)出发提出了感受野 RFB 模块(Receptive Fields Block)。通过膨胀卷积和增加 Inception 结构等方法使得网络结构的感受野变大,这样可以在不增加网络深度的前提下保持较高的检测效果和较快的运行速度。
核心思想
通过改进 SSD 特征提取网络,使卷积核的感受野可以覆盖更多范围,提升检测效果。算法主要是对网络中卷积的结构进行改进,相当于把 SSD 的基础网络替换为一个类似于 Inception 的网络,并将普通卷积改为了膨胀卷积,使得每个卷积的感受野变得更大。RBF 网络通过模仿人类感受野使基础网络可以学到更多尺度的信息,从而在不增加参数的前提下提升准确率。
RFBNet 主要创新可以参考以下两张图:
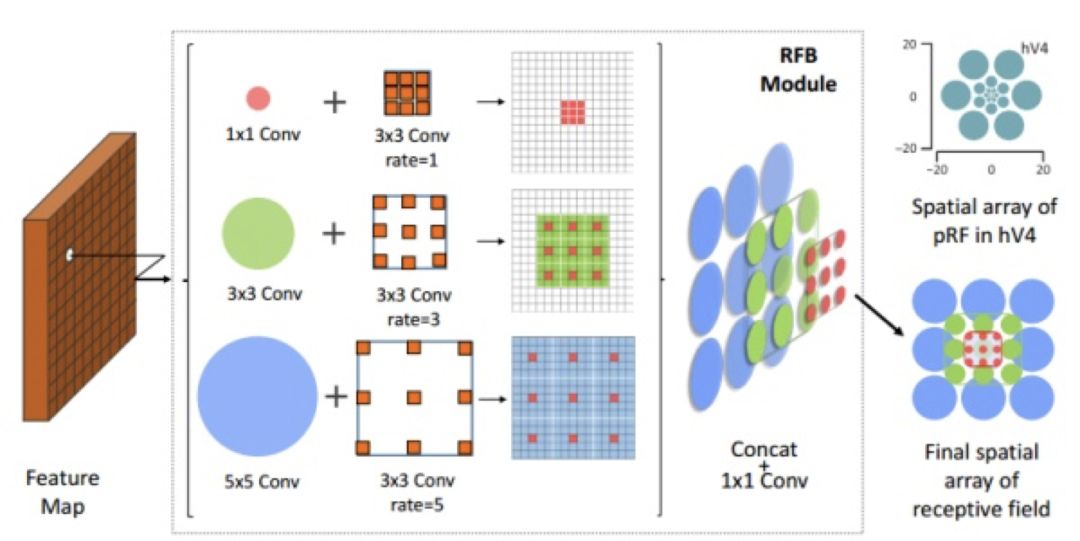
图 53
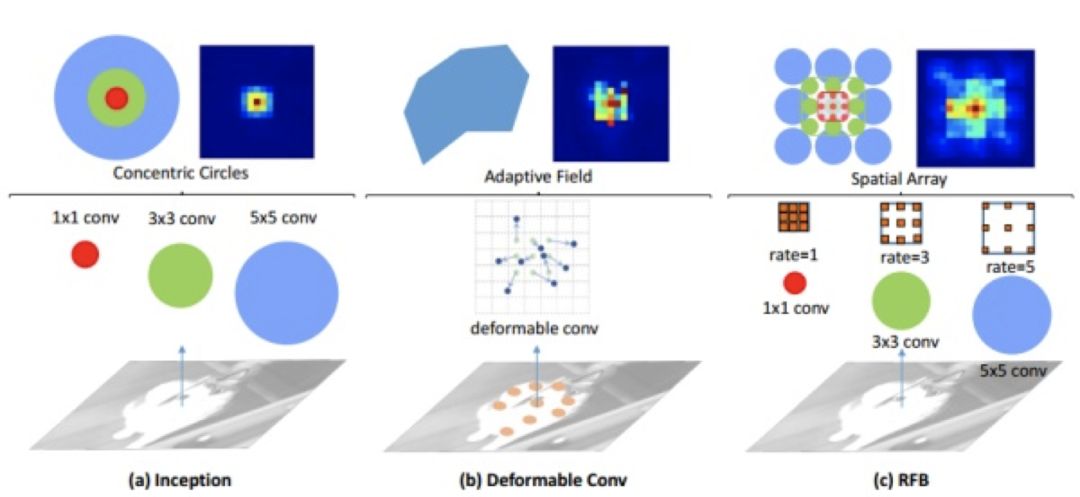
图 54
作者参考 Inception 结构,将 SSD 的基础网络改进为多Branch结构。每个 RFB(感受野模块)由不同大小的普通卷积+Dilation Conv 构成。如 1*1 卷积接 3*3 卷积,3*3 卷积接 3*3 膨胀卷(感受野为 9*9),5*5 卷积接 3*3 膨胀卷积(感受野为 15*15)。然后将这三个结构 concat 在一起共同作用。膨胀卷积如图所示,虽然 3*3 的卷积的参数个数和普通卷积一样,但其覆盖范围更大。
其实每个卷积核不覆盖很小的范围在 deformable conv 论文中也早有提及。作者在对比中提到,deformable 的每个像素的作用是相同的,但 RFB 结构可以通过对不同尺度的卷积设定不同权重使不同尺度的信息的作用不同。
在实现过程中,作者使用了两种不同类型的 RFB:
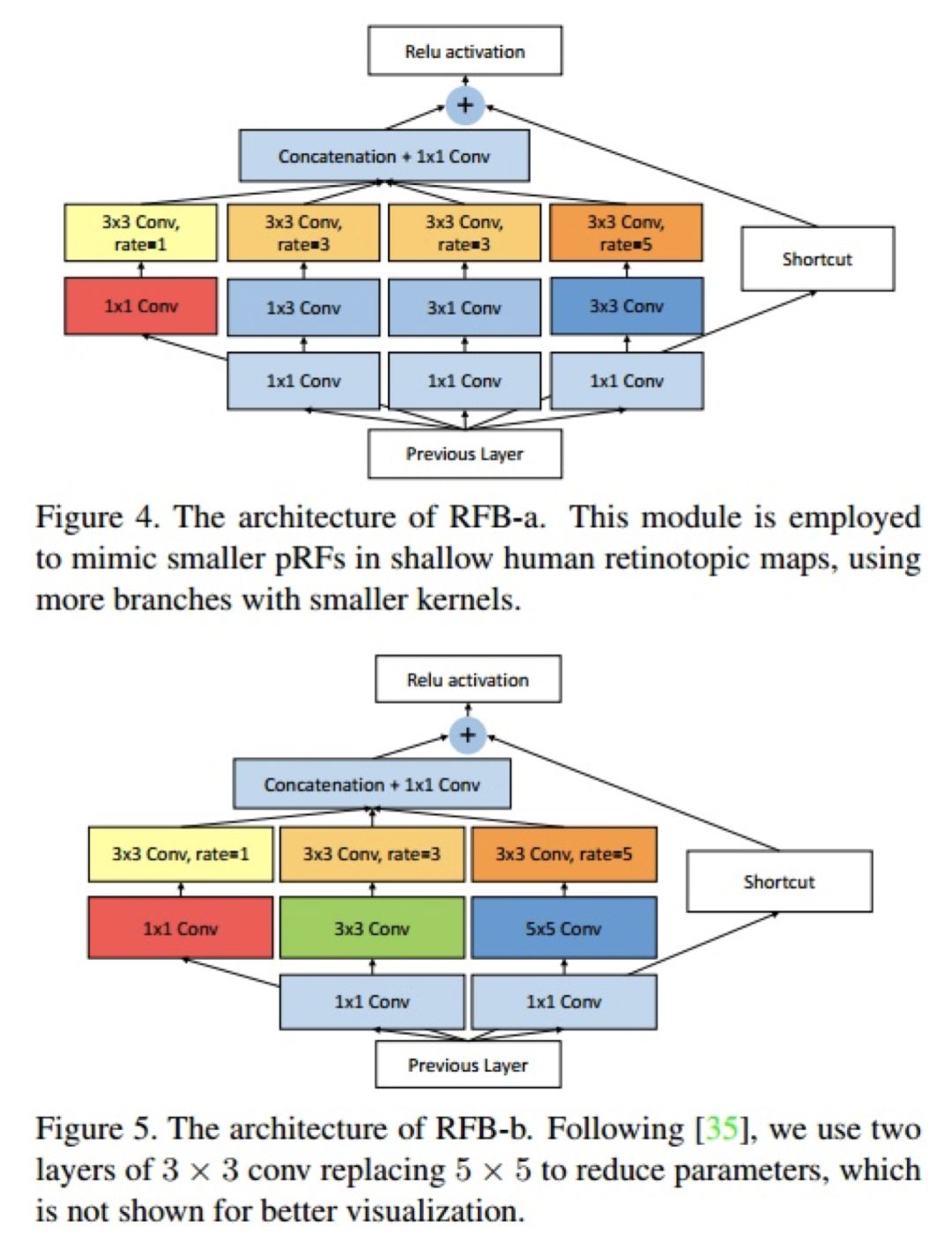
图 55
A 结构分支更多,卷积核更小,且没有 5*5 卷积核(作者在使用中使用两个 3*3 卷积代替 5*5 卷积)这两种构造在最后的 SSD 物体检测网络中的位置是不同的。根据作者的说法,在更靠前的网络,为了模仿人类更小的感受野,所以使用了更多分枝,且卷积核更小。事实上在使用过程中,只有第一层用了 A 结构。
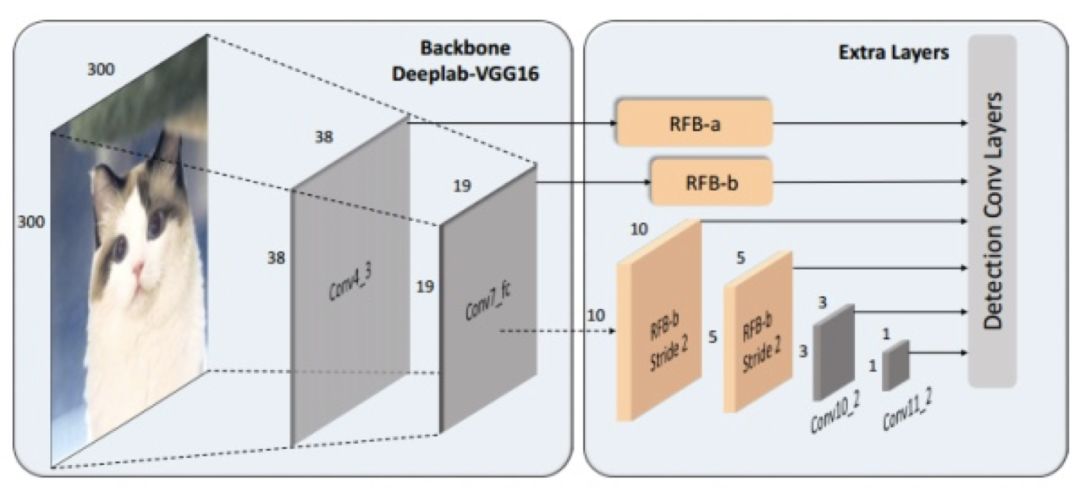
图 56
我们看一下整体的网络结构,可以看到 RFB a 结构只在提取 VGG43 的特征时使用,其他的 RFB 都是 B 结构。另一个有趣的现象是最后几层依然使用了原始的卷积操作。因为在这些层 feature map 的尺寸已经很小了。较大的卷积核(5*5)不能运行在上面。
算法效果
VOC 数据集的 mAP 可以达到 80.5%。作者在其他基础网络上也测试了准确率,发现也有提升。证明 RFB 结构的效果提升具有普遍性。此外,作者尝试了使用 RFB 网络从零开始训练。最终的 mAP 为 77.6 (DSOD 为 77.7),整体表现差不多。
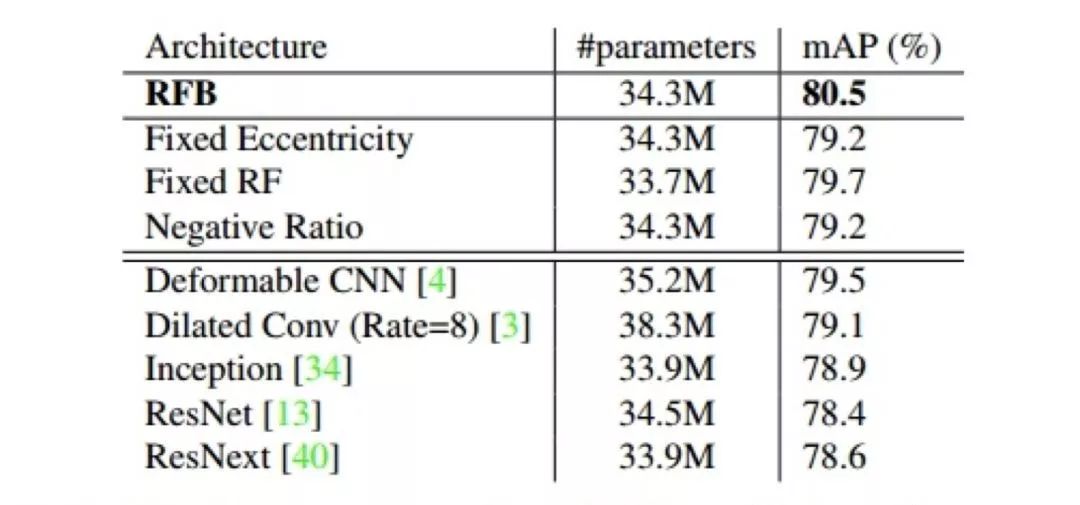
图 57
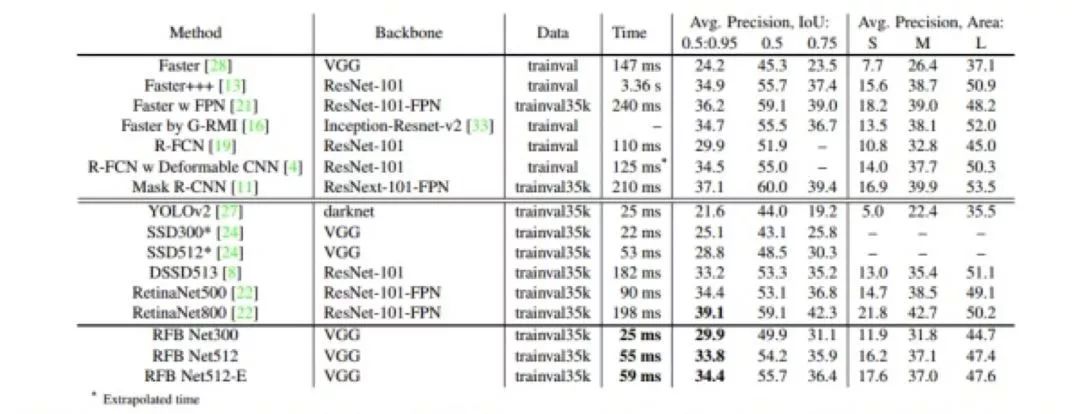
图 58
(未完待续)



