ACL 2022论文盘点出炉!NLP好文一口气读完


机器翻译
1.1 CSANMT

论文标题:
Learning to Generalize to More: Continuous Semantic Augmentation for Neural Machine Translation
https://arxiv.org/abs/2204.06812
https://github.com/pemywei/csanmt
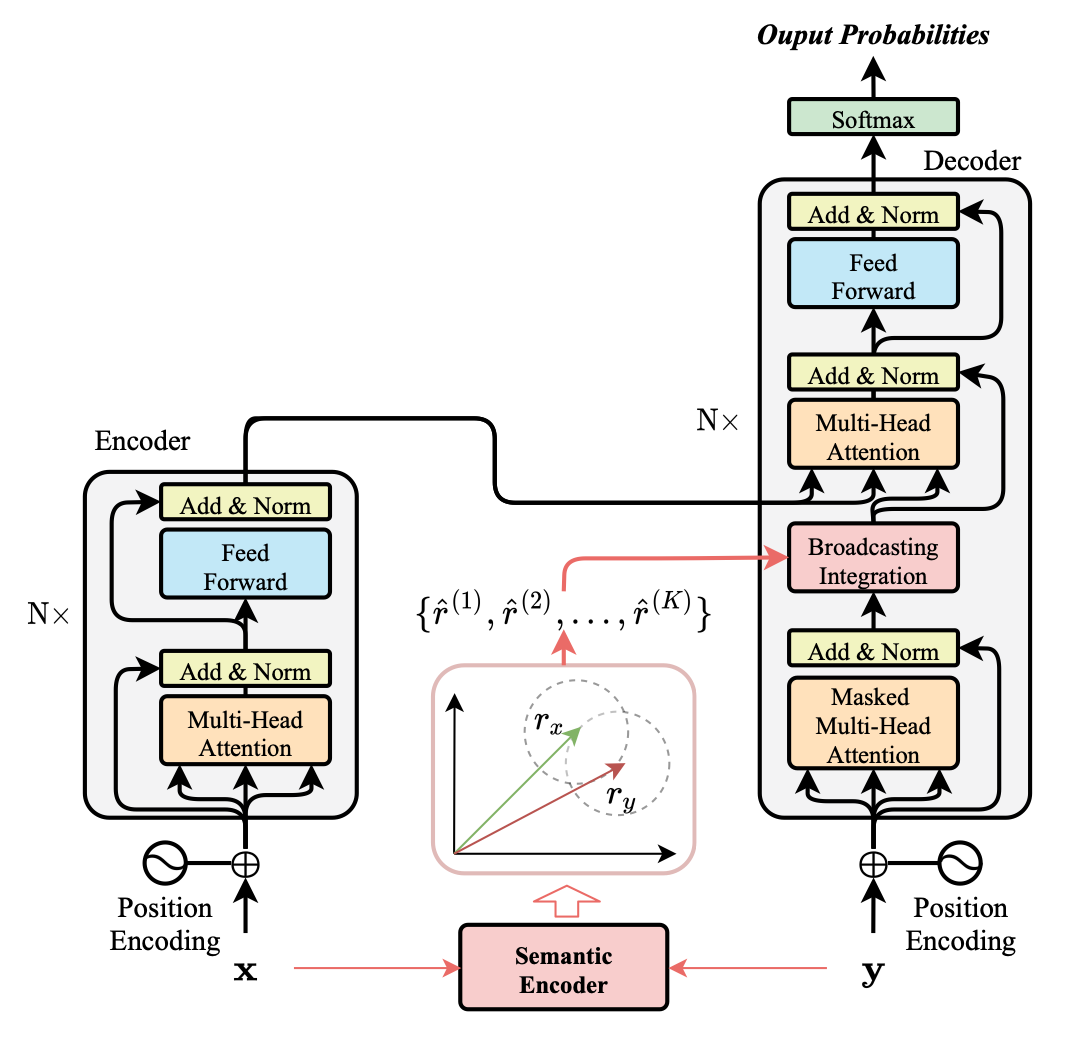
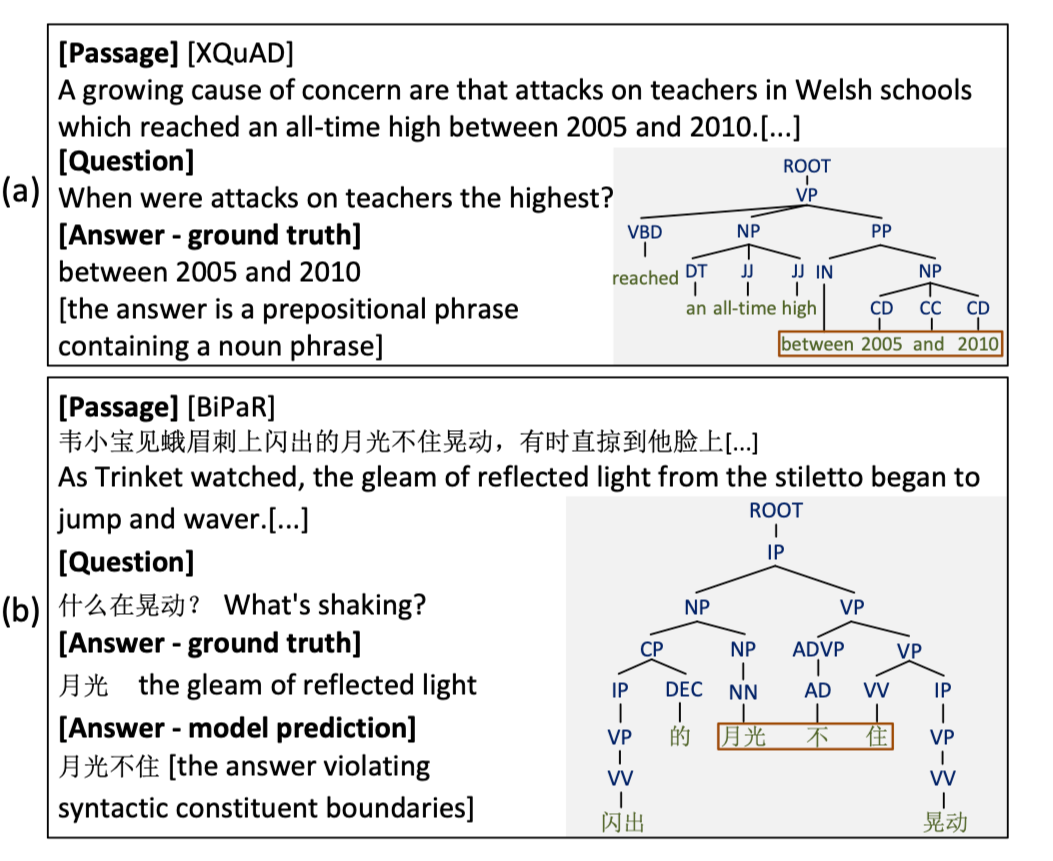
上图是 CSANMT 的框架。
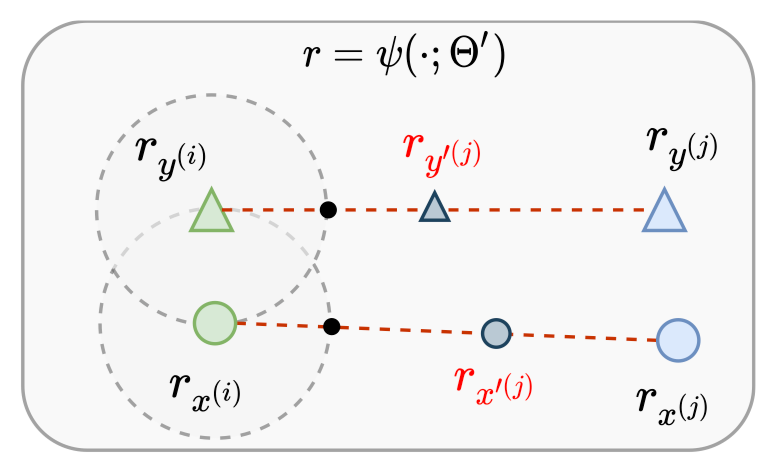

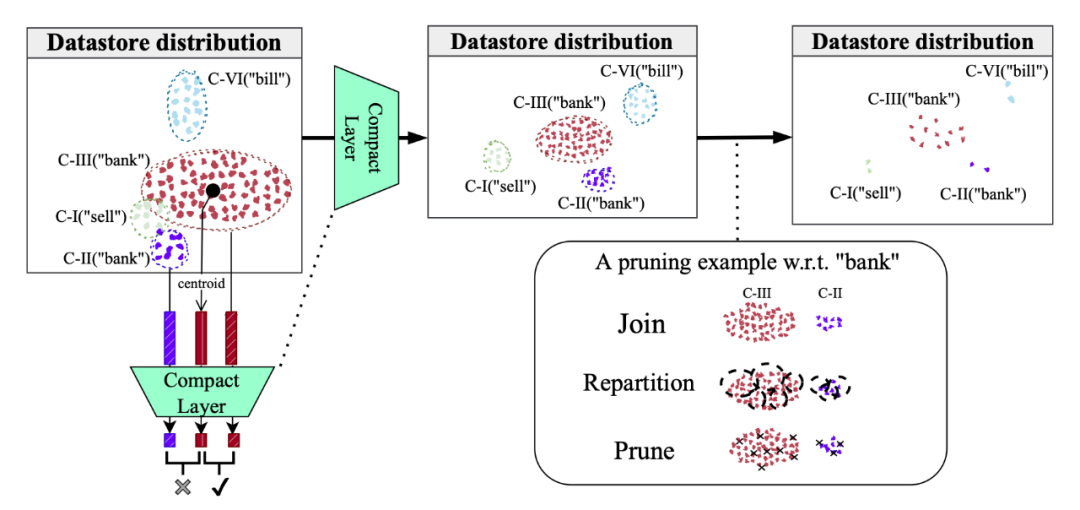
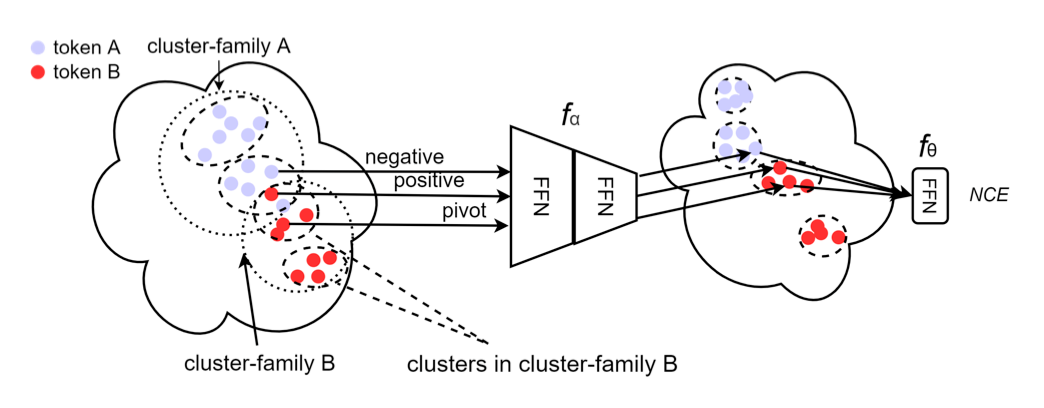
1.2 PCKMT

论文标题:
Efficient Cluster-Based k-Nearest-Neighbor Machine Translation
https://arxiv.org/abs/2204.06175
https://github.com/tjunlp-lab/PCKMT
最近提出的 k- 最近邻机器翻译(k-Nearest-Neighbor Machine Translation,kNN-MT)作为神经机器翻译(NMT)中域适应的非参数解决方案。它旨在通过与由域内数据构建的附加 token 级基于特征的检索模块协调来缓解高级 MT 系统在翻译域外句子时的性能下降。先前的研究证明,非参数 NMT 甚至优于对域外数据进行微调的模型,但 kNN 检索是以高延迟为代价的,特别是对于大型数据存储。

1.3 Human Evaluation for Machine Translation

论文标题:
Toward More Effective Human Evaluation for Machine Translation
https://arxiv.org/abs/2204.05307
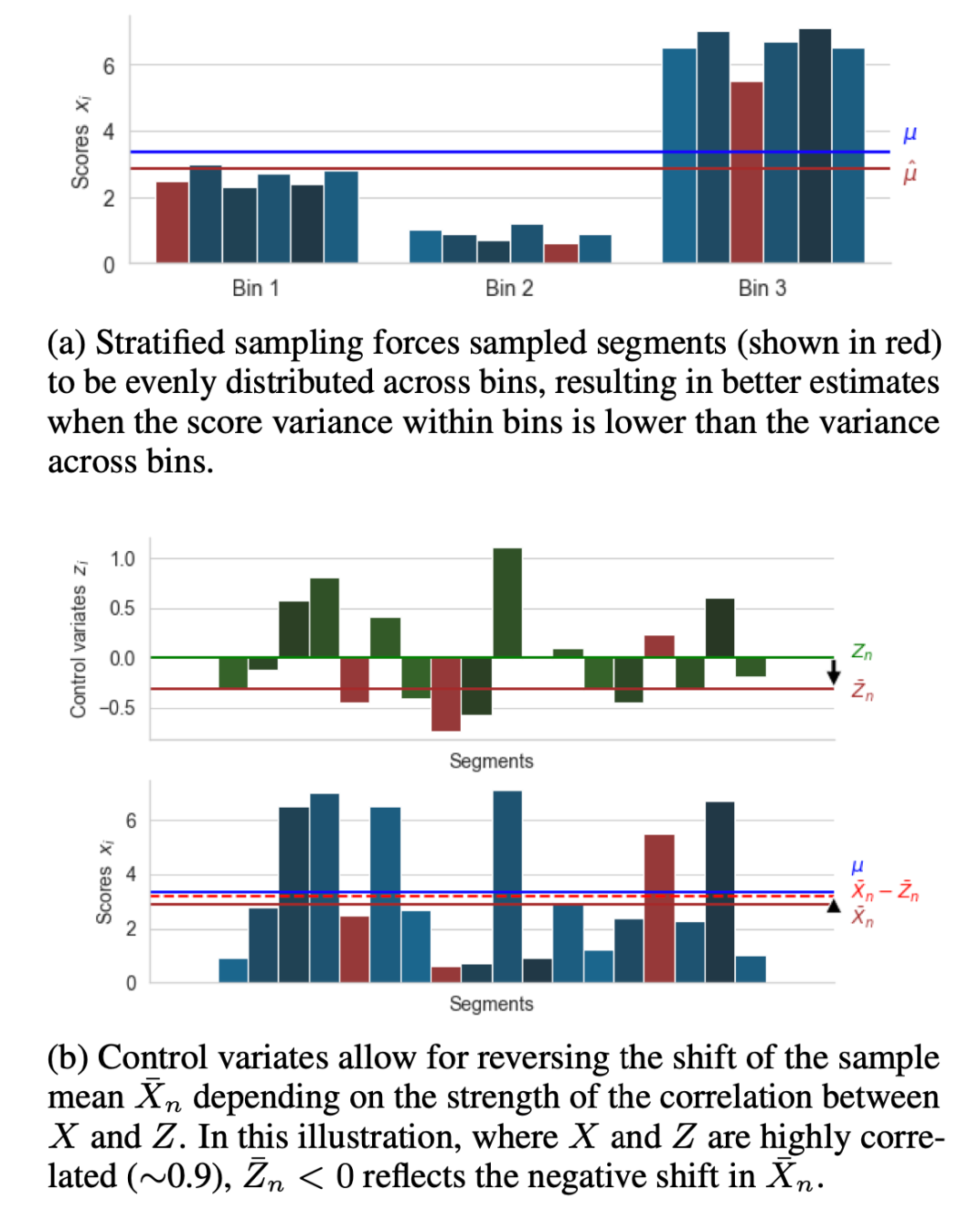
基于实验观察,作者提出以下建议:
-
使用文档成员等先验信息将项目划分为箱,然后使用等式分层抽样选择项目,并按比例分配。 使用与人类分数相关的自动度量或其他特征作为控制变量。此步骤在采样完成后执行,与所使用的采样方法无关。如果有多个指标可用,则通过平均或应用在样本上学习的平滑回归器将它们组合成一个变量。

对话系统
2.1 DSGFNet

论文标题:
Dynamic Schema Graph Fusion Network for Multi-Domain Dialogue State Tracking
https://arxiv.org/abs/2204.06677
对话状态跟踪(Dialogue State Tracking,DST)旨在跟踪用户在对话过程中的意图。在 DST 中,对域和槽之间的关系进行建模通常在以下方面存在不足:(1) 明确融合先前的槽域成员关系和对话感知动态槽关系,以及(2)推广到未见的域。
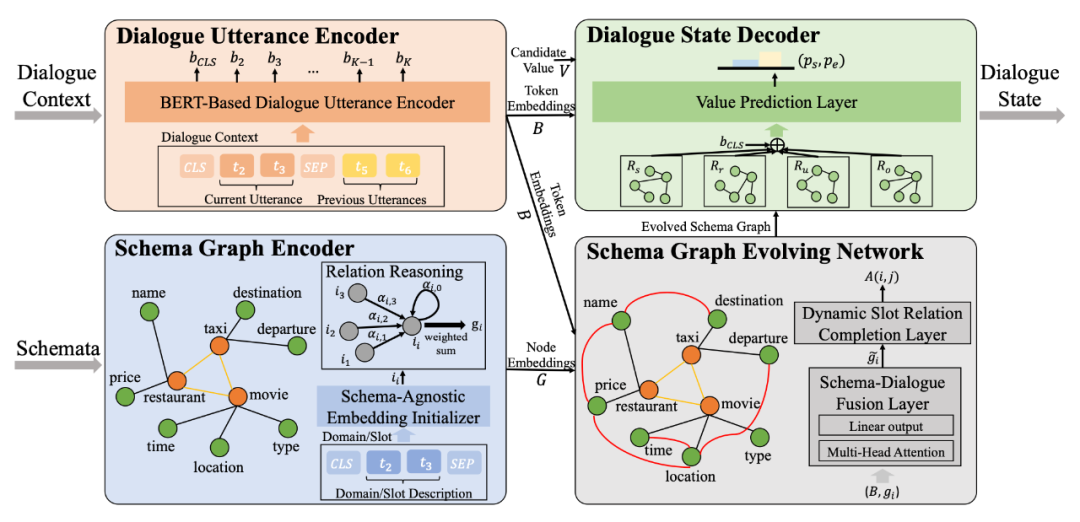


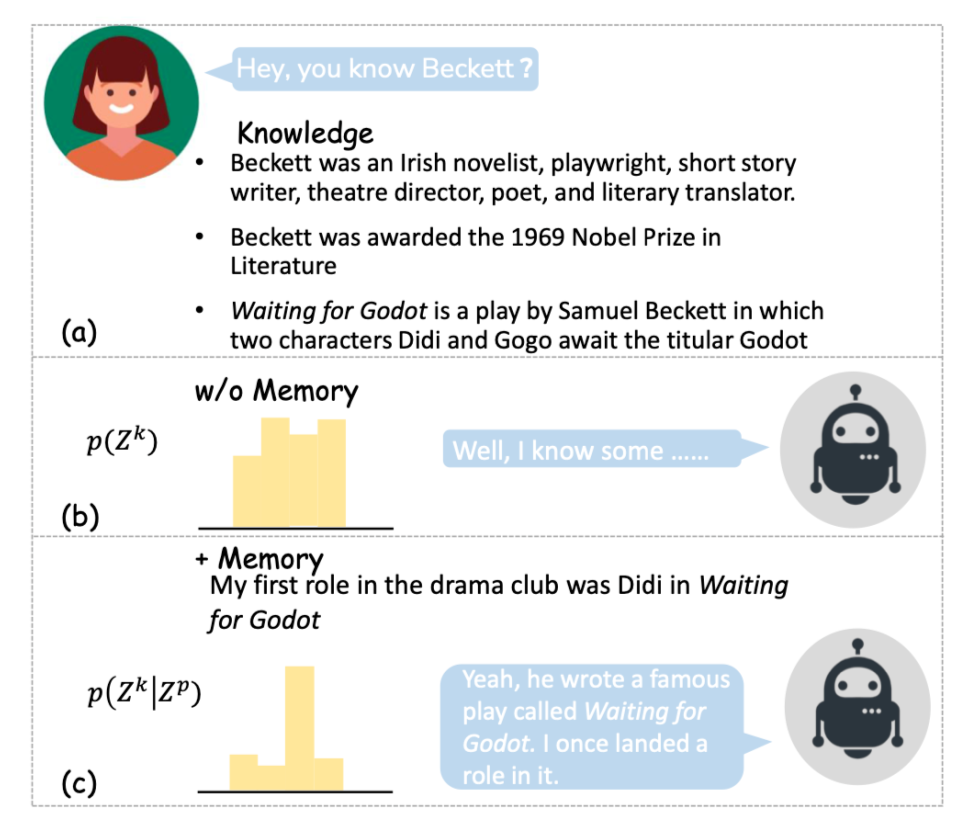
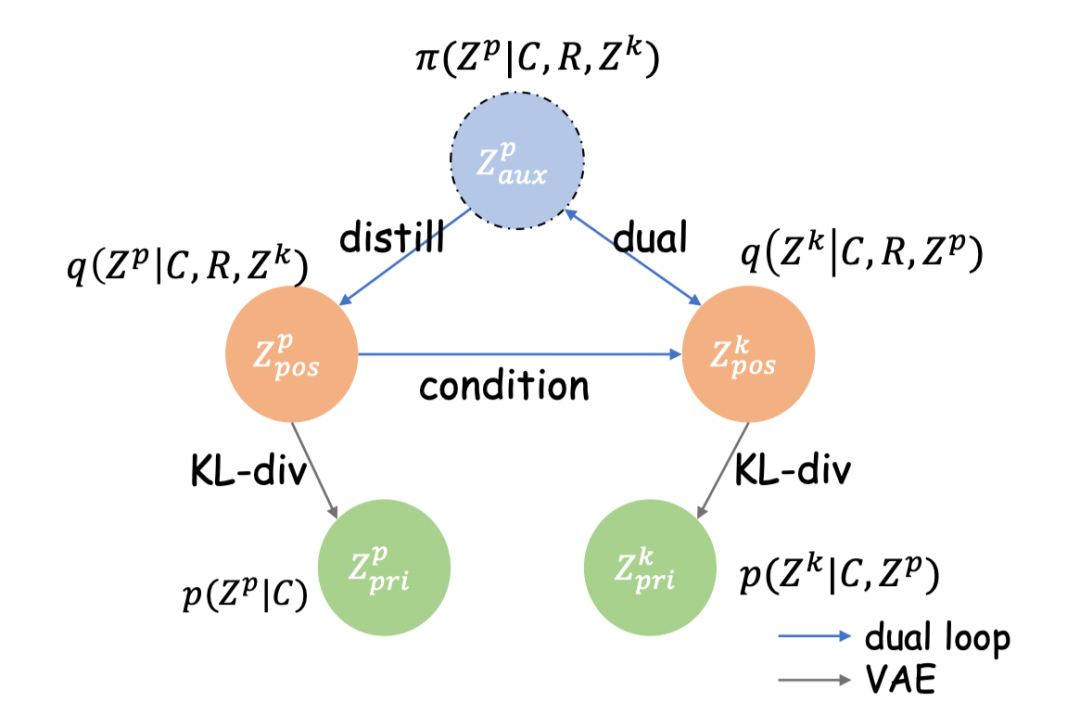
论文标题:
There Are a Thousand Hamlets in a Thousand People's Eyes: Enhancing Knowledge-grounded Dialogue with Personal Memory
https://arxiv.org/abs/2204.02624
基于知识的对话(Knowledge-grounded conversation,KGC)在构建有趣且知识渊博的的聊天机器人方面显示出巨大潜力,而知识选择是其中的关键因素。然而,以往的知识选择方法只关注知识与对话上下文之间的相关性,而忽略了对话者的年龄、爱好、教育和生活经历对其个人偏好相对于外部知识有更大影响这一事实。如果不考虑个性化问题,就很难选择合适的知识并产生与角色一致的响应。


论文标题:
Inferring Rewards from Language in Context
https://arxiv.org/abs/2204.02515
https://github.com/jlin816/rewards-from-language
在经典指令遵循中,诸如“我想要 JetBlue 航班”之类的语句会映射到操作(例如,选择该航班)。然而,语言也传达了有关用户潜在奖励功能的信息(例如,对 JetBlue 的一般偏好),这可以允许模型在新的上下文中执行所需的操作。
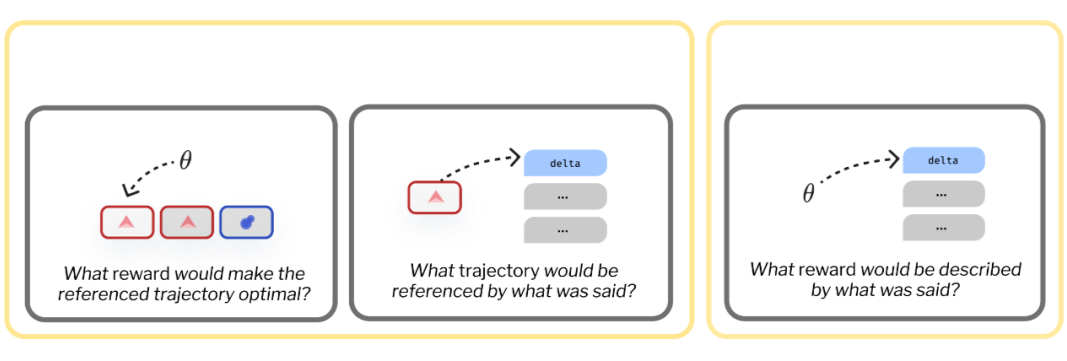


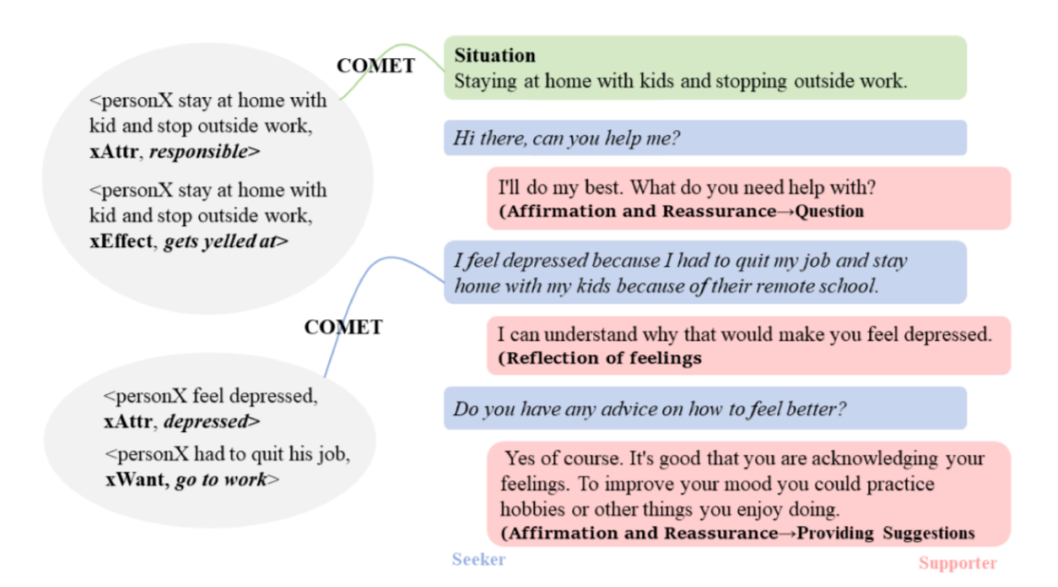
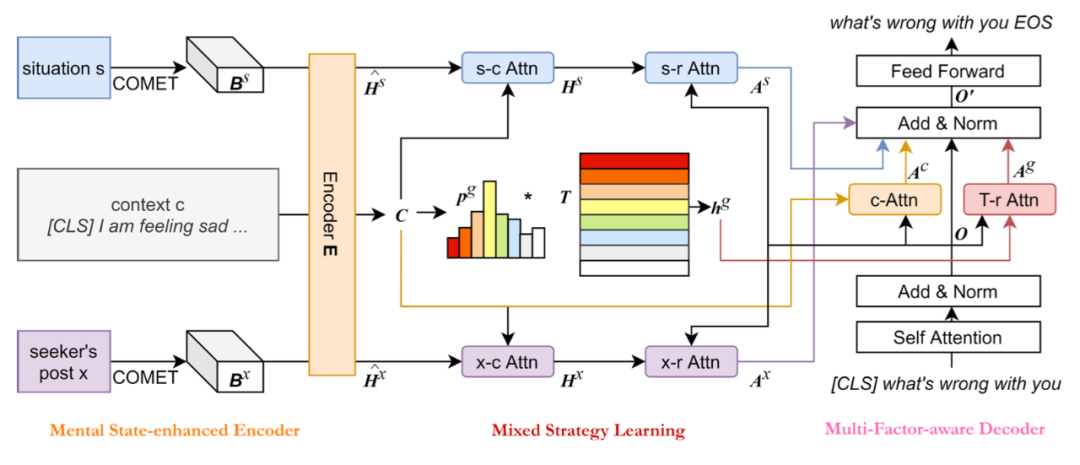
论文标题:
MISC: A MIxed Strategy-Aware Model Integrating COMET for Emotional Support Conversation
https://arxiv.org/abs/2203.13560
https://github.com/morecry/MISC
将现有方法应用于情感支持对话(为有需要的人提供有价值的帮助)有两个主要限制:(a)现有方法通常使用对话级别的情感标签,该标签过于粗略,无法捕捉用户的即时心理状态;(b)现有方法大多专注于在回应中表达同理心,而不是逐渐减少用户的痛苦。


预训练模型
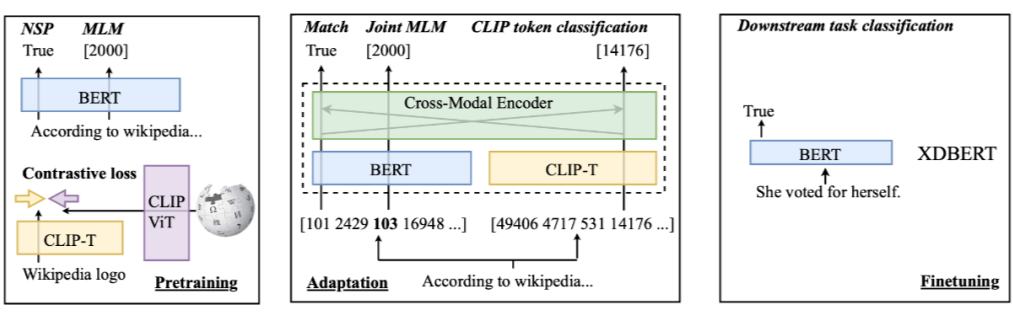
3.1 XDBERT

论文标题:
XDBERT: Distilling Visual Information to BERT from Cross-Modal Systems to Improve Language Understanding
https://arxiv.org/abs/2204.07316

论文标题:
Explanation Graph Generation via Pre-trained Language Models: An Empirical Study with Contrastive Learning
https://arxiv.org/abs/2204.04813
https://github.com/swarnaHub/ExplagraphGen
预训练的 Seq2Seq 模型在许多 NLU 任务中取得了广泛的成功,然而分析它们生成结构化输出(如图形)的能力方面的工作相对较少。这篇文章的作者研究了以端到端方式生成解释图的预训练语言模型,并分析了它们学习此类图的结构约束和语义的能力。
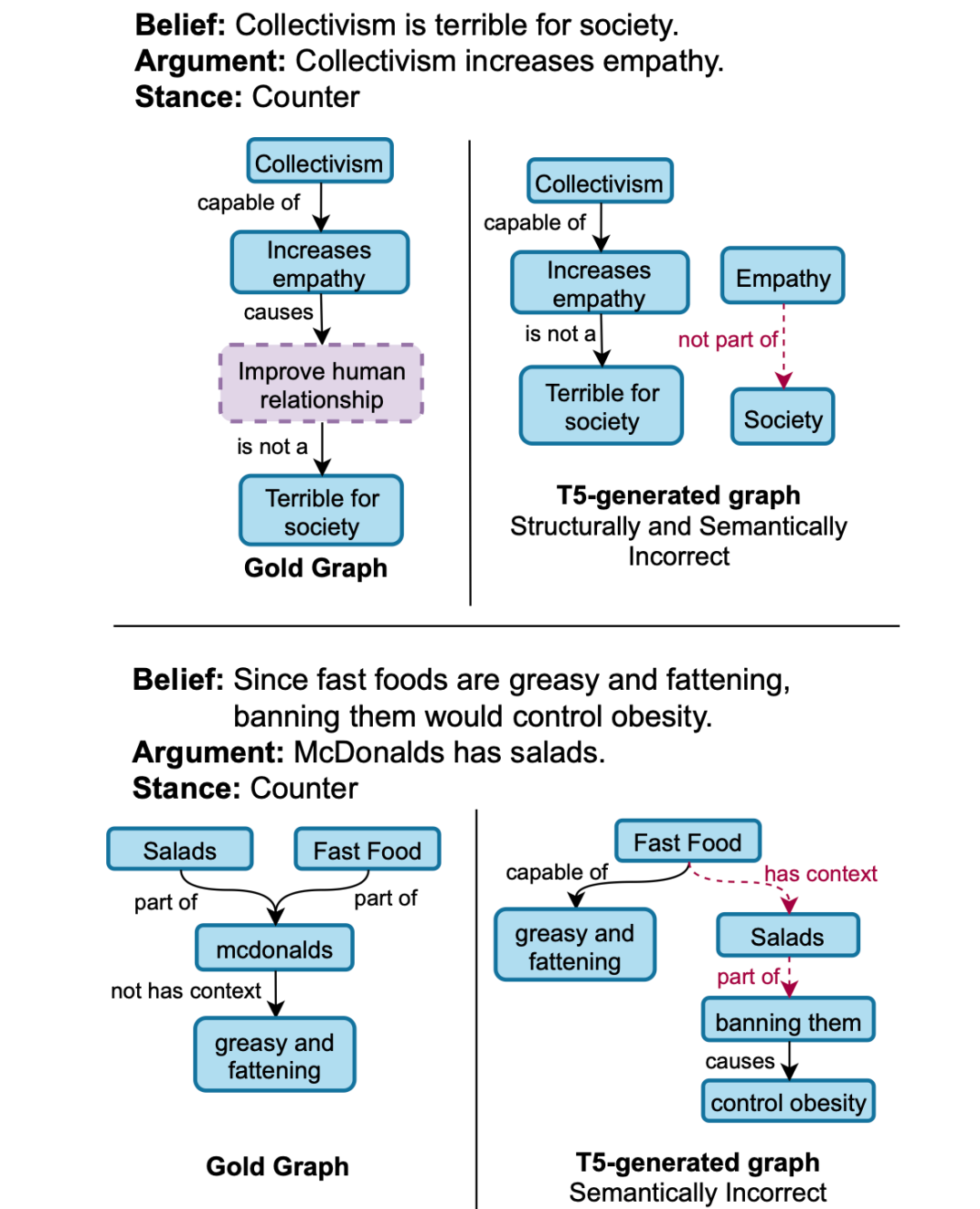
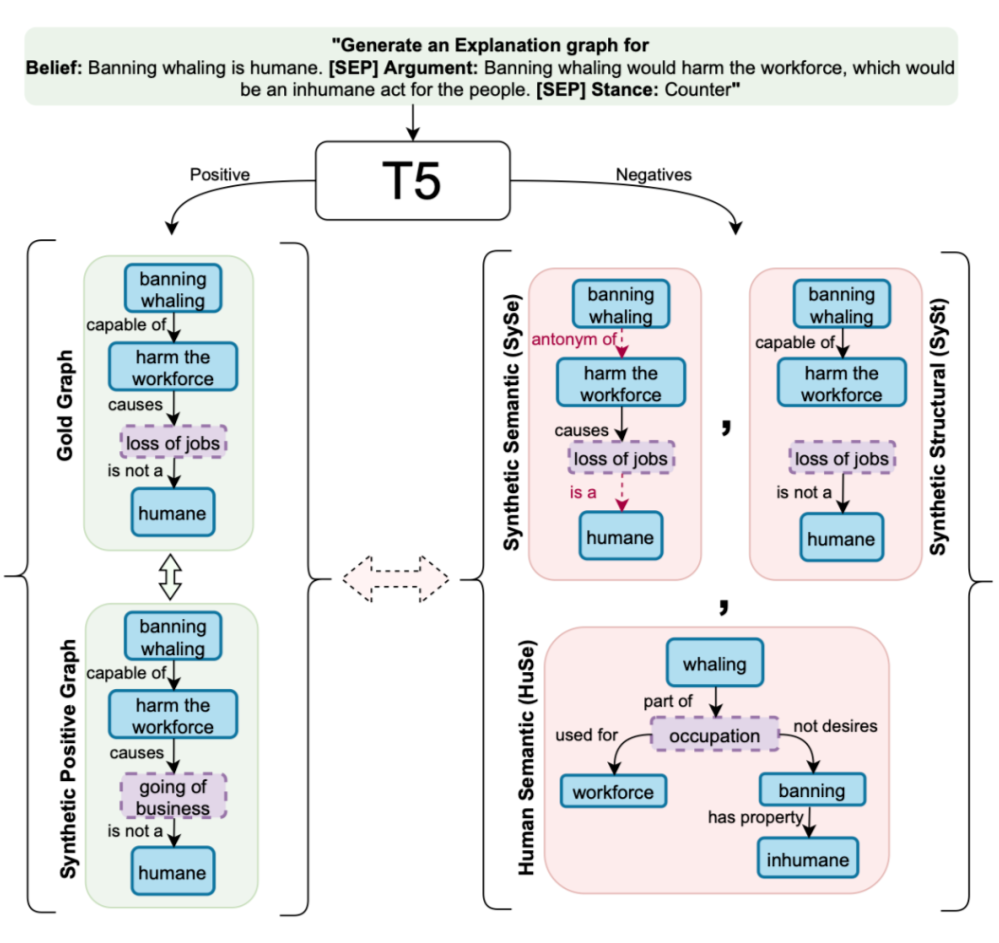
上图是本文提出的基于 T5 的对比学习框架,用于使用正扰动图和三种负扰动图生成图。
3.3 PERFECT

论文标题:
PERFECT: Prompt-free and Efficient Few-shot Learning with Language Models
https://arxiv.org/abs/2204.01172
https://github.com/rabeehk/perfect
当前对预训练掩码语言模型(PLMs)进行少量微调的方法需要为每个新任务设计 prompt 和 verbalizer,以将示例转换为 PLM 可以评分的完形填空格式。这篇文章的作者提出了 PERFECT,这是一种无需依赖任何手工设计的微调模型,只需 32 个数据点。
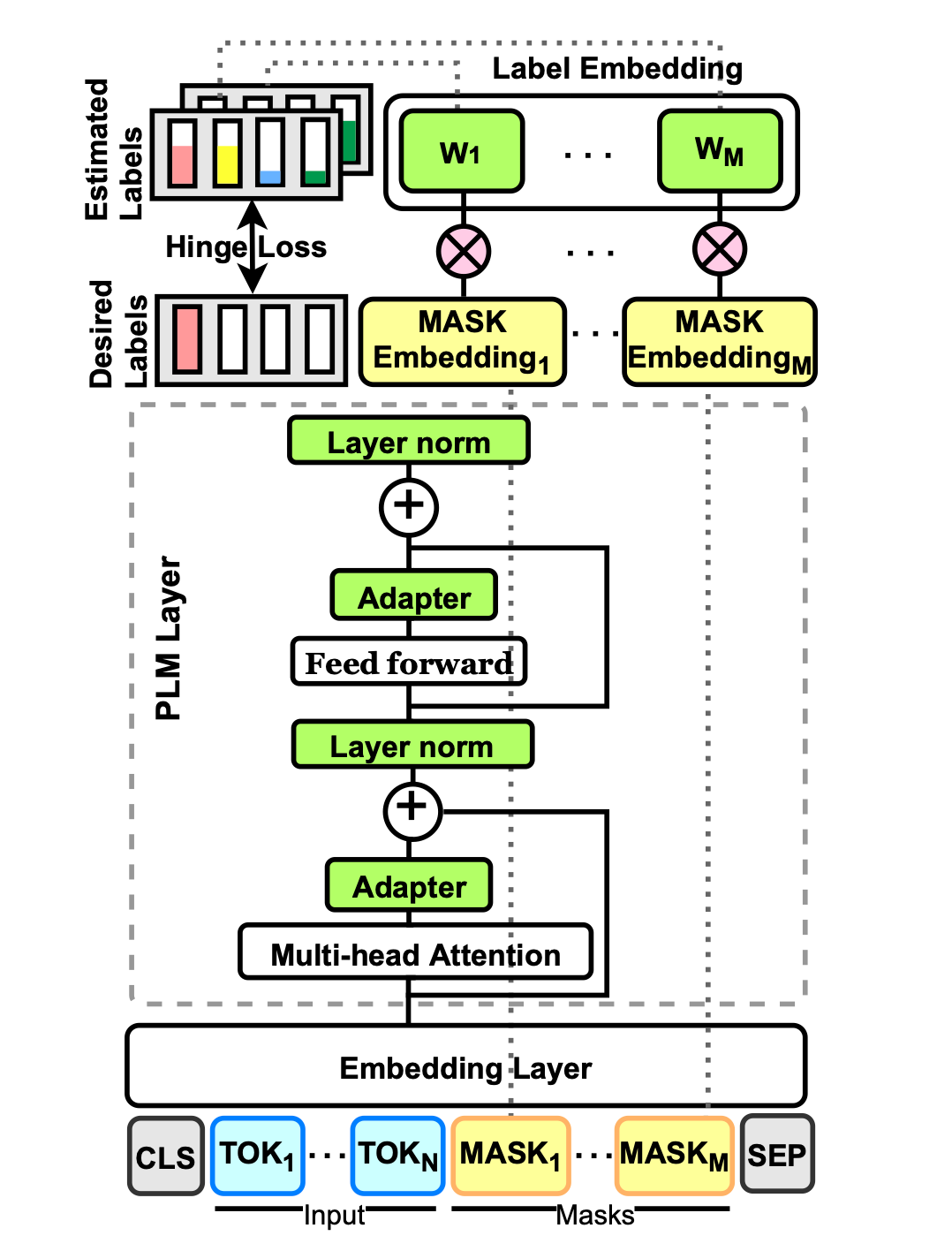
上图是 PERFECT 的图示。首先将每个输入转换为其掩码语言建模(MLM)输入,然后为每个 token 训练一个分类器并优化每个掩码位置上的平均多类 hinge loss。模型包含三个主要组件:a)无模式任务描述,使用特定于任务的 adapter告诉模型给定任务;b)多标记标签嵌入作为学习标签表示的有效机制;c)基于原型网络概念的有效推理策略,取代了先前的迭代自回归解码方法。
3.4 RL-Guided MTL

论文标题:
Reinforcement Guided Multi-Task Learning Framework for Low-Resource Stereotype Detection
https://arxiv.org/abs/2203.14349
随着以无监督方式对大量数据进行训练的大型预训练语言模型(PLM)变得越来越普遍,识别文本中的各种类型的偏差已成为焦点。现有的“刻板印象检测”数据集主要采用针对大型 PLM 的诊断方法。先前的研究表明现有基准数据集存在重大的可靠性问题。注释可靠的数据集需要准确理解刻板印象如何在文本中体现的细微差别。
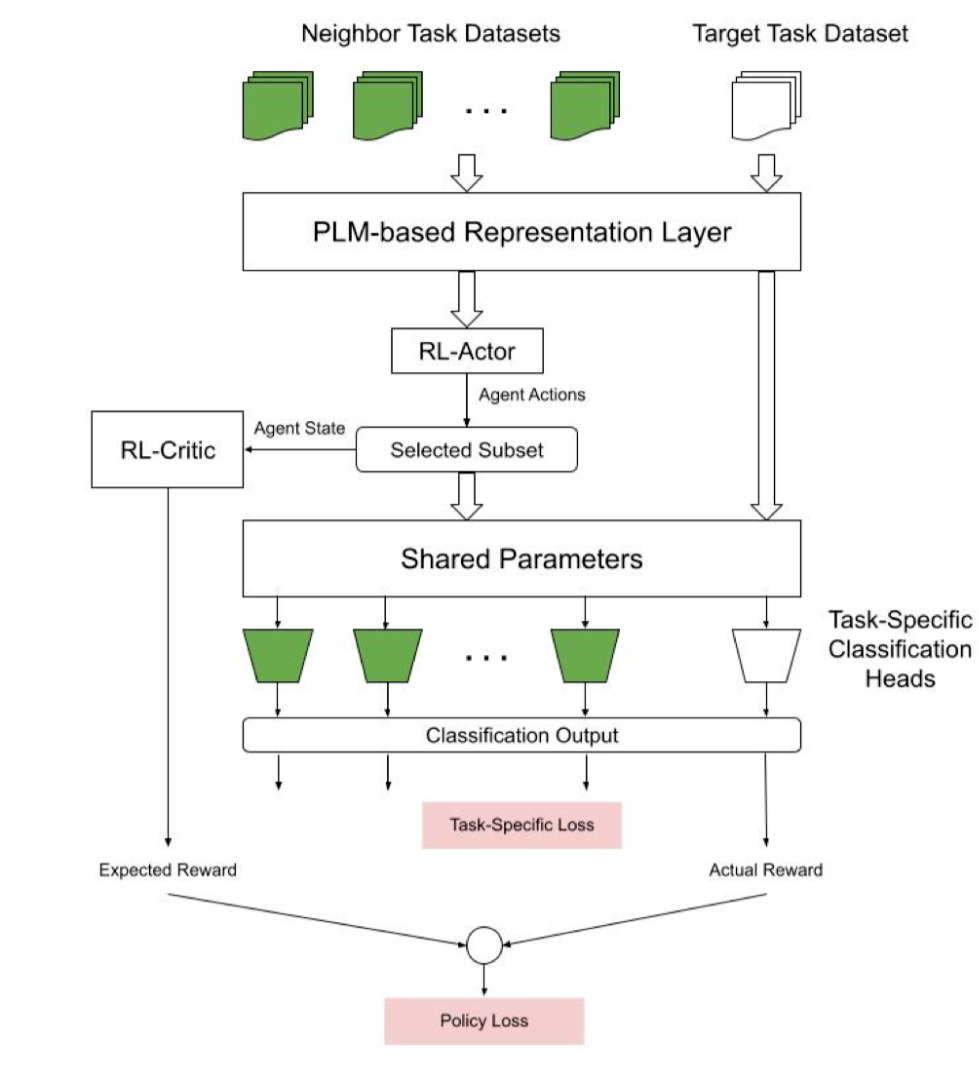


机器阅读理解
4.1 S2DM

论文标题:
Learning Disentangled Semantic Representations for Zero-Shot Cross-Lingual Transfer in Multilingual Machine Reading Comprehension
https://arxiv.org/abs/2204.00996
多语言预训练模型能够在机器阅读理解(MRC)中将知识从资源丰富的语言零样本迁移到低资源语言。然而,不同语言中固有的语言差异可能会使零样本迁移预测的答案跨度违反目标语言的句法约束。这篇文章的作者提出了一种全新的多语言 MRC 框架,该框架配备了连体语义分离模型(Siamese Semantic Disentanglement Model, S2DM),以在多语言预训练模型学习的表示中将语义与语法分离。
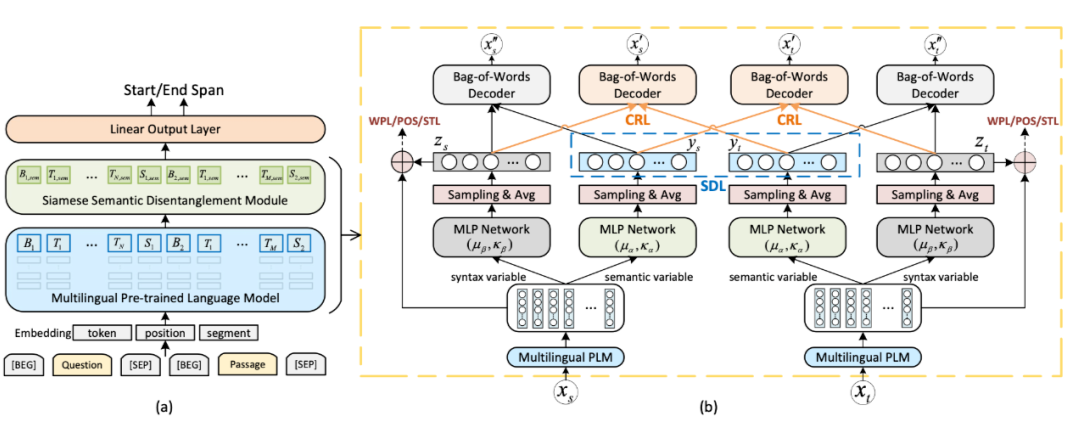
4.2 POI-Net

论文标题:
Lite Unified Modeling for Discriminative Reading Comprehension
https://arxiv.org/abs/2203.14103
https://github.com/Yilin1111/poi-net
作为机器阅读理解(MRC)的一个广泛和主要类别,判别式 MRC 的一般目标是根据给定材料预测答案。然而,各种区分性 MRC 任务的重点可能足够多样化:多选择 MRC 需要模型来突出和整合全局所有潜在的关键证据;而抽取式 MRC 则侧重于更高的局部边界精确度以进行答案抽取。在之前的工作中,缺乏针对整体判别性 MRC 任务的统一设计。
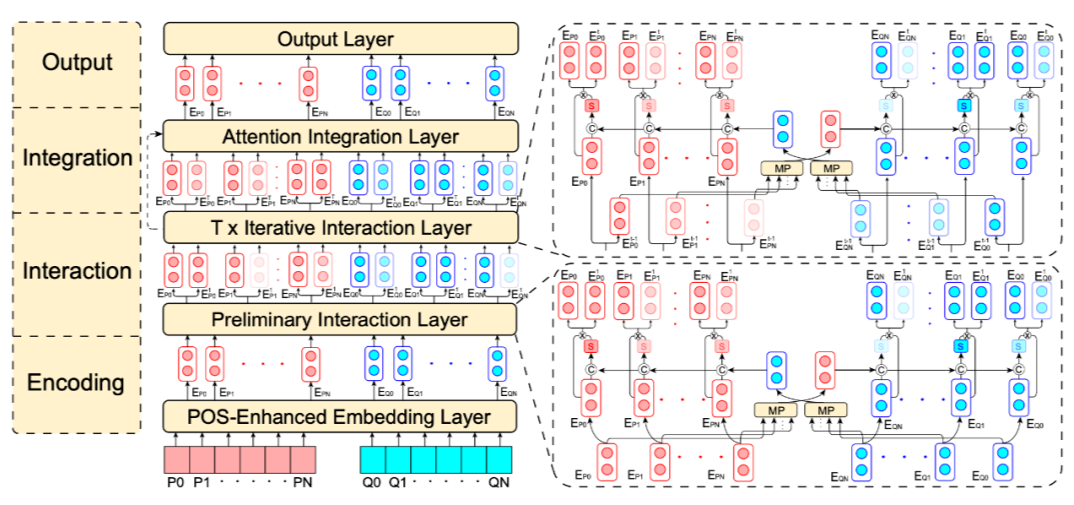
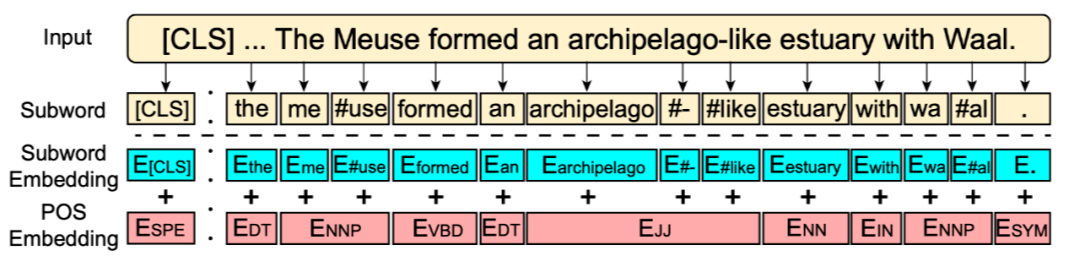
上图是 POI-Net 的输入表示流程。POS Embedding 的下标是输入的 POS 标签。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧



