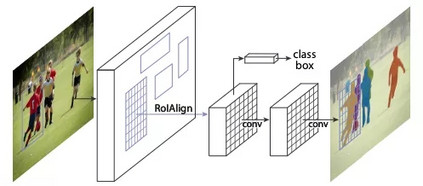
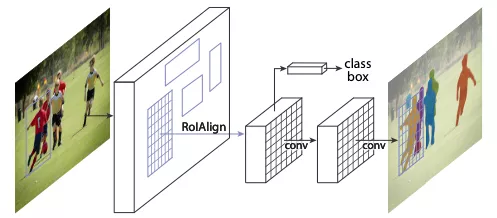
-TOP10- Mask R-CNN 被引频次:1839 作者:Kaiming He,Georgia Gkioxari,Piotr Dollar,Ross Girshick. 发布信息: 2017,16th IEEE International Conference on Computer Vision (ICCV) 论文:https://arxiv.org/abs/1703.06870 代码:https://github.com/facebookresearch/Detectron Mask R-CNN作为非常经典的实例分割(Instance segmentation)算法,在图像分割领域可谓“家喻户晓”。Mask R-CNN不仅在实例分割任务中表现优异,还是一个非常灵活的框架,可以通过增加不同的分支完成目标分类、目标检测、语义分割、实例分割、人体姿势识别等多种不同的任务。
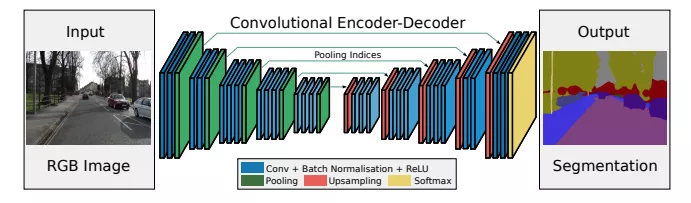
-TOP9- SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation 被引频次:1937 作者: Vijay Badrinarayanan,Alex Kendall,Roberto Cipolla 发布信息:2015,IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 论文:https://arxiv.org/pdf/1511.00561.pdf 代码:https://github.com/aizawan/segnet SegNet是用于进行像素级别图像分割的全卷积网络。SegNet与FCN的思路较为相似,区别则在于Encoder中Pooling和Decoder的Upsampling使用的技术。Decoder进行上采样的方式是Segnet的亮点之一,SegNet主要用于场景理解应用,需要在进行inference时考虑内存的占用及分割的准确率。同时,Segnet的训练参数较少,可以用SGD进行end-to-end训练。
-TOP8- DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs 被引频次:2160 作者: Chen Liang-Chieh,Papandreou George,Kokkinos Iasonas等. 发布信息:2018,IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE DeepLabv1:https://arxiv.org/pdf/1412.7062v3.pdf DeepLabv2:https://arxiv.org/pdf/1606.00915.pdf DeepLabv3:https://arxiv.org/pdf/1706.05587.pdf DeepLabv3+:https://arxiv.org/pdf/1802.02611.pdf 代码:https://github.com/tensorflow/models/tree/master/research/deeplab DeepLab系列采用了Dilated/Atrous Convolution的方式扩展感受野,获取更多的上下文信息,避免了DCNN中重复最大池化和下采样带来的分辨率下降问题。2018年,Chen等人发布Deeplabv3+,使用编码器-解码器架构。DeepLabv3+在2012年pascal VOC挑战赛中获得89.0%的mIoU分数。
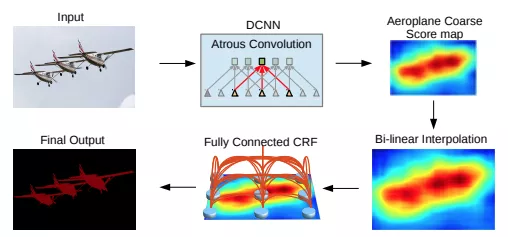
DeepLabv3+
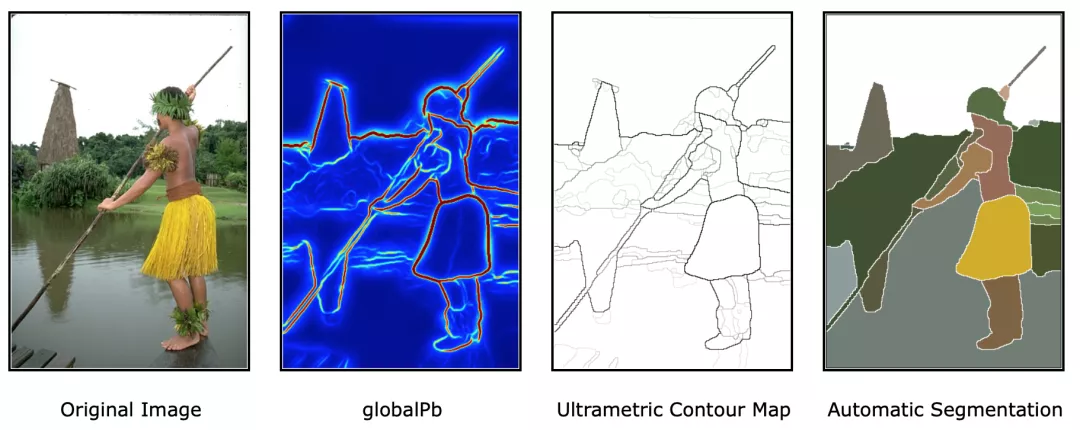
-TOP7- Contour Detection and Hierarchical Image Segmentation 被引频次:2231 作者: Arbelaez Pablo,Maire Michael,Fowlkes Charless等. 发布信息:2011,IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 论文和代码:https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/resources.html Contour Detection and Hierarchical Image Segmentation通过检测轮廓来进行分割,以解决不加交互的图像分割问题,是分割领域中非常重要的一篇文章,后续很多边缘检测算法都利用了该模型。
-TOP6- Efficient graph-based image segmentation 被引频次:3302 作者:Felzenszwalb PF,Huttenlocher DP 发布信息:2004,INTERNATIONAL JOURNAL OF COMPUTER VISION 论文和代码:http://cs.brown.edu/people/pfelzens/segment/ Graph-Based Segmentation 是经典的图像分割算法,作者Felzenszwalb也是提出DPM算法的大牛。该算法是基于图的贪心聚类算法,实现简单。目前虽然直接用其做分割的较少,但许多算法都用它作为基石。
-TOP5- SLIC Superpixels Compared to State-of-the-Art Superpixel Methods 被引频次:4168 作者: Radhakrishna Achanta,Appu Shaji,Kevin Smith,Aurelien Lucchi,Pascal Fua,Sabine Susstrunk. 发布信息:2012,IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 论文和代码:https://ivrlwww.epfl.ch/supplementary_material/RK_SLICSuperpixels/index.html SLIC 算法将K-means 算法用于超像素聚类,是一种思想简单、实现方便的算法,SLIC算法能生成紧凑、近似均匀的超像素,在运算速度,物体轮廓保持、超像素形状方面具有较高的综合评价,比较符合人们期望的分割效果。
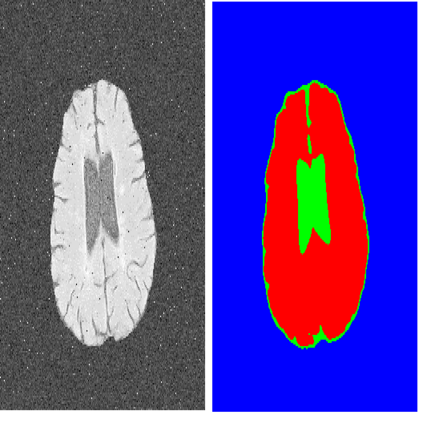
-TOP4- U-Net: Convolutional Networks for Biomedical Image Segmentation 被引频次:6920 作者: Ronneberger Olaf,Fischer Philipp,Brox Thomas 发布信息:2015,18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) 代码:https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/ U-Net是一种基于深度学习的图像语义分割方法,在医学图像分割领域表现尤为优异。它基于FCNs做出改进,相较于FCN多尺度信息更加丰富,同时适合超大图像分割。作者采用数据增强(data augmentation),通过使用在粗糙的3*3点阵上的随机取代向量来生成平缓的变形,解决了可获得的训练数据很少的问题。并使用加权损失(weighted loss)以解决对于同一类的连接的目标分割。 图片
-TOP3- Mean shift: A robust approach toward feature space analysis 被引频次:6996 作者: Comaniciu D,Meer P 发布信息:2002,IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE Meanshift是基于像素聚类的代表方法之一,是一种特征空间分析方法。密度估计(Density Estimation) 和mode 搜索是Meanshift的两个核心点。对于图像数据,其分布无固定模式可循,所以密度估计必须用非参数估计,选用的是具有平滑效果的核密度估计(Kernel density estimation,KDE)。Meanshift 算法的稳定性、鲁棒性较好,有着广泛的应用。但是分割时所包含的语义信息较少,分割效果不够理想,无法有效地控制超像素的数量,且运行速度较慢,不适用于实时处理任务。
-TOP2- Normalized cuts and image segmentation 被引频次:8056 作者:Shi JB,Malik J 发布信息:2000,IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 论文:https://ieeexplore.ieee.org/abstract/document/1000236 NormalizedCut是基于图论的分割方法代表之一,与以往利用聚类的方法相比,更加专注于全局解的情况,并且根据图像的亮度,颜色,纹理进行划分。 图片
-Top1- Fully Convolutional Networks for Semantic Segmentation 被引频次:8170 作者: Long Jonathan,Shelhamer Evan,Darrell Trevor 发布信息:2015,IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 代码:https://github.com/shelhamer/fcn.berkeleyvision.org FCN是图像分割领域里程碑式论文。作为语义分割的开山之作,FCN是当之无愧的TOP1。它提出了全卷积网络(FCN)的概念,针对语义分割训练了一个端到端,点对点的网络,它包含了三个CNN核心思想: (1)不含全连接层(fc)的全卷积(fully conv)网络。可适应任意尺寸输入。 (2)增大数据尺寸的反卷积(deconv)层。能够输出精细的结果。 (3)结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。
参考 [1]FCN的学习及理解(Fully Convolutional Networks for Semantic Segmentation),CSDN [2]mean shift 图像分割 (一),CSDN [3]https://zhuanlan.zhihu.com/p/49512872 [4]图像分割—基于图的图像分割(Graph-Based Image Segmentation),CSDN [5]https://www.cnblogs.com/fourmi/p/9785377.html