ACL 2021 | 今年NLP的这些论文,你不能错过!

(本文阅读时间:15 分钟)

论文链接:
https://arxiv.org/abs/2106.02300v1
命名实体识别(Named Entity Recognition, NER)是指:对文本中带有特定语义信息的实体进行识别,其广泛应用于知识图谱、推荐系统等领域中。目前,基于深度神经网络的 NER 模型已经在拥有大规模高质量标注语料的前提下取得了不错的效果。但是在实际应用中,标注数据尤其是高质量的标注数据,往往因其高代价而仅集中在少数几种语言中。因此,跨语言命名实体识别(Cross-Lingual Named Entity Recognition)就成为了 NER 领域近几年的研究热点。人们希望通过跨语言迁移学习,将知识从具有大量标注语料的源语言,迁移到没有标注语料的目标语言,从而解决目标语言上的 NER 问题。
与现有的 Feature-based 方法和 Pseudo-labeling 方法不同,微软亚洲研究院的研究员提出的 AdvPicker 通过对抗学习构造判别器获取目标语言无标注数据中更具有语言无关性的子集,从而可高效利用目标语言语料进行跨语言命名实体识别。
如图1所示,AdvPicker 主要由三部分构成:
(1)Token-level 对抗学习:基于多任务学习(NER & 语种分类)框架实现。首先在 NER 任务中,利用源语言标注语料对编码器和 NER 分类器进行训练。然后,在语种分类任务中,混合有标注的源语言文本和无标注的目标语言文本,编码器不断调整参数,使其能够在正确判断源语言实体任务的同时,产生让判别器无法进行正确语种分类的词向量;判别器则基于编码器的输出,判断当前输入文本的语种类别。
(2)数据选择:将目标语言无标注语料作为输入,利用训练得到的语种判别器对编码器输出的特征向量进行分类,并依据概率排序,从中选出 Language-independent 的文本子集(判别器输出概率接近0.5)。
(3)知识蒸馏:利用(2)中选出的目标语言文本子集,基于(1)中所得的源语言 NER 模型,以知识蒸馏的方式训练学生模型(目标语言 NER 模型)。
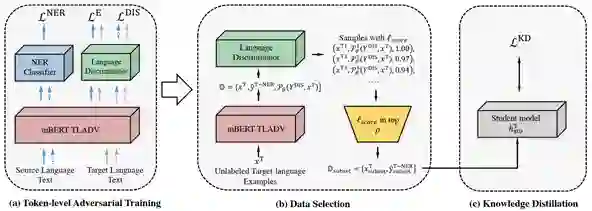
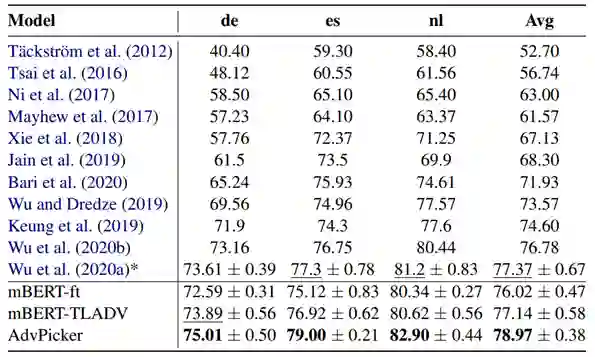
表1:模型性能比较(Zero-shot Cross-lingual NER)
*表示没有利用额外数据的结果
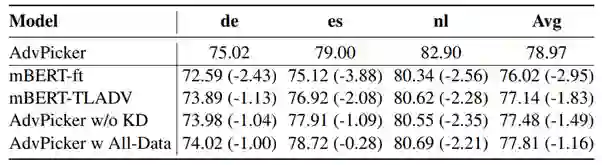
表2:消融实验

论文链接:
https://arxiv.org/abs/2105.13239
代码搜索(Code Search)旨在给一个自然语言查询(Query)找到一段合适的代码,并且通过使用这种技术,能够有效地提高程序员们的生产力。但是训练一个有较好效果的代码-查询的匹配模型,需要大量的监督数据。因此,微软亚洲研究院的研究员们提出了 CoSQA 数据集(Code Search and Question Answering),其中含有20,604个真实网页查询和代码的配对数据,每一对都有一个0/1标签来判断代码是否可以回答查询的问题,图2中包含了 CoSQA 的两个例子。

CoSQA 中的自然语言查询来源于必应(Bing)搜索引擎的查询日志,代码选用了 CodeSearchNet 中的 Python 函数(如表3所示),并且研究员对函数中自带的自然语言注释也进行了保留,以促进查询和代码间更好的匹配。
事实上,标注这种需要专业知识的数据集比较困难,为了提高标注质量,研究员们制定了标注流程并让每条数据至少经三人进行标注。表4展示了 CoSQA 数据集的一些统计信息。

表4:CoSQA 数据集统计数据
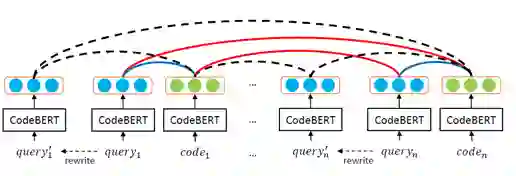
除数据外,本文还提出了基于对比学习的查询-代码匹配模型(CoCLR,Code Contrastive LeaRning),如图3所示。通过对查询进行重写和使用同批数据的不同代码,来获得更多的训练数据,以增强模型的匹配能力。


论文链接:
https://arxiv.org/abs/2107.01875
Rap 是一种带有押韵和节奏的特殊音乐形式。Rap 的自动生成面临着许多挑战:一方面,由于没有现存的含有节奏信息的数据集,之前的 Rap 生成系统只能生成纯歌词;另一方面,之前的 Rap 生成系统对于押韵的建模也有所欠缺,很难自动生成多押、连押和连环押等高质量 Rap 的必要成分。因此,微软亚洲研究院的研究员们提出了 DeepRapper,利用一个基于 Transformer 的 Rap 生成模型,来生成押韵且有节奏信息的 Rap 歌词。
针对数据缺乏的问题,研究员们首先设计了一个收集数据的 Pipeline(如图4),收集了大量歌曲数据,并且对歌曲进行了一系列处理。

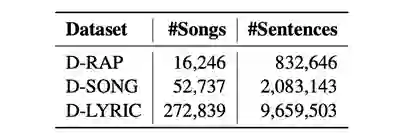
表6:用于 Rap 生成的数据集详情
DeepRapper 采用了基于 Transformer 的自回归语言生成模型。为了更好地对“押韵“建模,该模型首先采用了反向生成的方式,从右到左生成一句话里的歌词。因为押韵词语通常位于句子末尾,这样的反向处理有利于生成多押(N-gram rhyme)的 Rap。然后,研究员们又引入了韵母 Embedding 和相对位置 Embedding,以更好捕捉押韵词语与句子中位置的关系,这同样利于生成多押的 Rap。最后在生成时引入韵脚约束,以灵活调整下一个词的概率,在不影响自动生成 Rap 的同时,给押韵的词语分配更多的概率,这不仅有利于生成多押,还有利于连押。而且对于可以获得的极少的连环押数据,DeepRapper 也在连环押句子中的每个韵脚后嵌入了一个特殊Token,从而赋予了 DeepRapper 生成连环押 Rap 句子的能力(后文有少量连环押的示例)。
对于节奏的建模,DeepRapper 在歌词中插入了一个特殊的 [BEAT] Token,显式地将节奏信息和歌词信息融合,将节奏预测简化成语言模型里特殊 Token 的预测。图5是 DeepRapper 模型的输入输出示意图。

图5:DeepRapper 模型的输入输出示意图
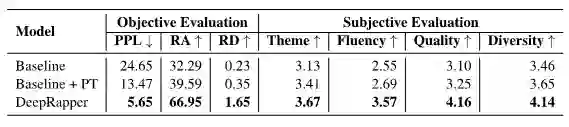
表7展示了 DeepRapper 客观和主观的评估结果,并与两个基线模型进行了比较。Baseline 与 DeepRapper 结构相同,但是没有韵律模型;Baseline+PT 则是采用了预训练的 Baseline。结果显示,DeepRapper 在客观指标 Perplexity (PPL)、Rhyme Accuracy (RA)、 Rhyme Density (RD),和主观指标 Theme (主题是否鲜明)、Fluency (语言是否流畅)、Quality (韵脚质量)、 Diversity (韵脚多样化)上都远远超出了各个 Baseline。
此外,研究员们还对 DeepRapper 中的每一个设计做了对照试验,详细结果见表8。通过分析可以得出以下结论:没有韵律建模,DeepRapper 在押韵相关的指标上下降比较明显;去除任何一个韵律建模中的小模块,都会影响 DeepRapper 的押韵能力;没有节奏建模,不会生成有节奏信息的 Rap;没有预训练也会影响 DeepRapper 的表现。
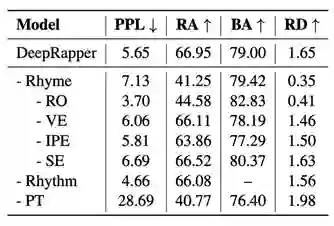
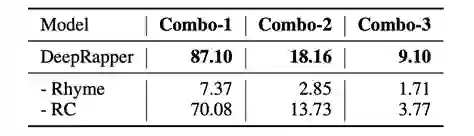

表10:DeepRapper 的节奏评估

图6:DeepRapper 生成的中文歌词示例

论文链接:
https://arxiv.org/abs/2106.01040
Transformer 是 NLP 领域非常重要的基础模型。由于其内部的自注意力机制,Transformer 的计算复杂度和输入序列长度的平方成正比,如图7所示。
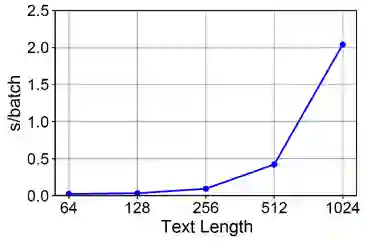
图7:Transformer 的计算时间和输入文本长度的关系示例
文档则是 NLP 领域常见的文本类型,其长度通常较长,如果用 Transformer 去建模长文档,计算开销会很大。所以,通常的做法是对长文档进行截断,但是这样会造成文档输入信息不全,影响最终的文档建模效果。
对此,微软亚洲研究院的研究员们注意到,长文档通常由多个句子组成,不同句子的语义既相对完整自洽。基于这两点,研究员们提出了一种层次化 (Hierarchical) 和交互式 (Interactive) 的Transformer 结构:Hi-Transformer,来实现高效和准确的长文档建模,如图8所示。
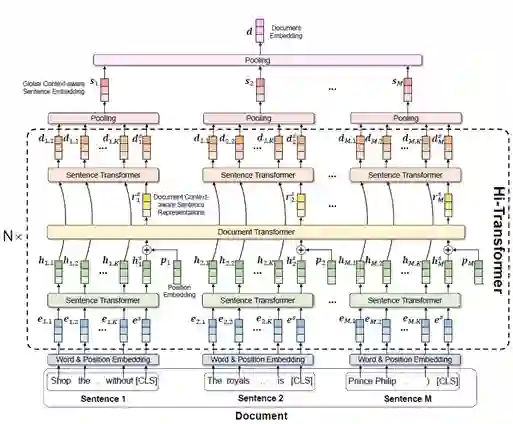
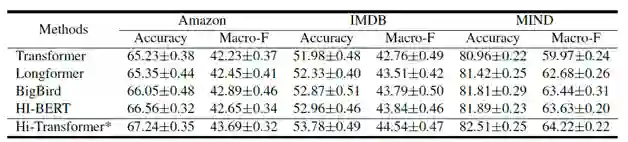
表11:不同 Transformer 在长文档建模上的性能比较

表12:不同 Transformer 方法的计算复杂度对比
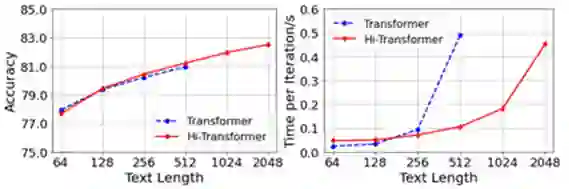
图9进一步比较了 Transformer 和 Hi-Transformer 在不同文档长度下的性能和速度。可以看到,当输入同样长度文档时,二者的性能非常接近。当文档长度较长时,Hi-Transformer 的速度显著优于 Transformer。因此,Hi-Transformer 能够处理 Transformer 由于速度和显存限制而无法处理的较长文档,并且能够取得和 Transformer 接近的效果。

论文链接:
https://arxiv.org/pdf/2106.06381.pdf
预训练跨语言语言模型(Pretrained Cross-Lingual Language Model)在自然语言推断、问答、序列标注等诸多任务上展现了强大的跨语言迁移能力。例如,仅用英语的问答训练数据来微调预训练跨语言语言模型,得到的模型就可以直接在多个语言上实现问答任务。以往的跨语言预训练任务更关注句子级别的对齐,隐式地鼓励跨语言对齐,而忽略了显示的词级别的细粒度的对齐。
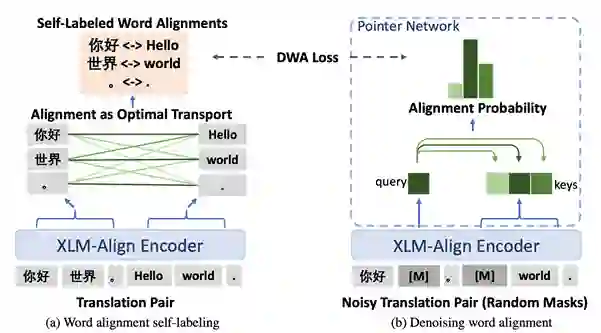
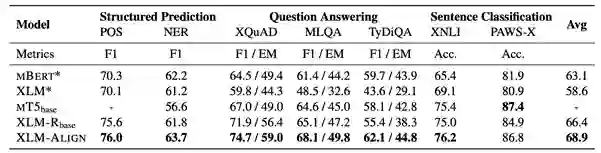
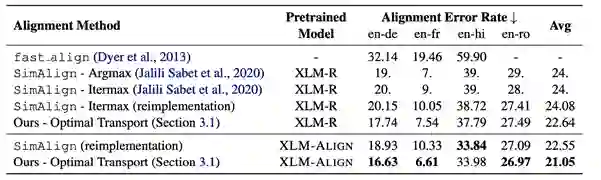
表14:在4个语言对上的词对齐实验结果

论文链接:
https://aclanthology.org/2021.acl-long.348.pdf
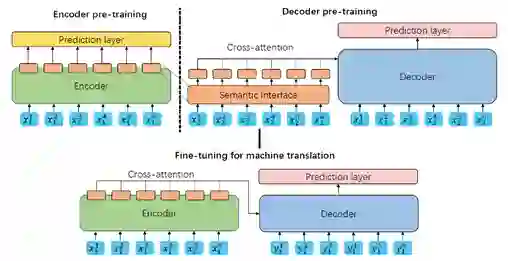
近年来,预训练技术在 NLP 领域取得了巨大成功,如何针对机器翻译任务进行预训练也成为了当前的一个热点问题。为了能够有效地训练编码器和解码器之间的交叉注意力(Cross-attention)模块,并显示引入目标语言和源语言的跨语言映射信息,微软亚洲研究院的研究员们提出了基于语义交互界面的机器翻译编码器和解码器预训练方法。
该方法通过一个与语言无关的语义交互界面 SemFace,将编码器和解码器的预训练过程进行交互。在预训练过程中,编码器的目标是将源语言的输入通过特征提取映射到 SemFace 定义的语义空间中;解码器的目标则是利用该语义空间的信息生成目标语言的句子。通过定义 SemFace,编码器和解码器的预训练过程可以分别完成,源语言和目标语言的跨语言信息可以在 SemFace 定义的与语言无关的空间中进行表示。同时在解码器的预训练过程中,交叉注意力模块的参数也可以得到训练。预训练完成后,编码器和解码器可以进行自然地拼接,直接进行后续机器翻译的微调。
如图11所示,本文提出的方法可分为两步。第一步如图中的上半部分所示,利用单语数据,通过预定义的语义交互界面,分别预训练编码器和解码器。在预训练的过程中,编码器的目标是将输入映射到该交互界面定义的空间中,解码器的目标是通过交叉注意力模块利用该空间中的信息完成解码。
以上,是为大家精选的6篇微软亚洲研究院的研究员们在 2021 ACL 会议上发表的论文,研究员们的成果对于 NLP 研究的发展有着十分重要的作用和影响!为了更好的向大家展示微软亚洲研究院的 “黑科技” ,我们邀请您参与下方的投票:请选出你更感兴趣的话题或文章,如有你还有想了解的其他黑科技话题,欢迎给我们留言!(以下按照论文首字母排序)
论文1:AdvPicker:基于对抗判别器高效利用无标注语料的跨语言命名实体识别模型
论文2:CoSQA:基于网页查询和代码配对数据的大规模数据集
论文3:DeepRapper:用神经网络生成有韵律和节奏的Rap
论文4:Hi-Transformer:一种具有层次化和交互式特点的长文档建模结构
论文5:利用自标注的词对齐提升预训练跨语言语言模型
论文6:SemFace:用语义交互界面预训练机器翻译的编码器和解码器
你也许还想看:







