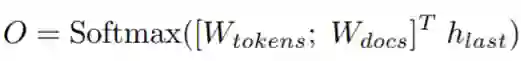选自arXiv
作者:Yi Tay等
机器之心编译
编辑:陈萍
谷歌提出基于 Transformer 的可微文本检索索引,明显优于双编码器模型等强大基线,并且还具有强大的泛化能力,在零样本设置中优于 BM25 基线。
信息检索 (Information Retrieval, IR) 从互联网诞生之日起,便有着不可撼动的地位。如何从海量数据中找到用户需要的信息是当前研究的热点。目前比较流行的 IR 方法是先检索后排序(retrieve-then-rank)策略。在检索算法中,比较常用的是基于反向索引或最近邻搜索,其中基于对比学习的双编码器 (dual encoders,DE) 是目前性能最优的模型。
近日,谷歌研究院在论文《Transformer Memory as a Differentiable Search Index》中提出了一种替代架构,研究者采用序列到序列 (seq2seq) 学习系统。
该研究证明使用单个 Transformer 即可完成信息检索
,其中有关语料库的所有信息都编码在模型的参数中。
该研究引入了可微搜索索引(Differentiable Search Index,DSI),这是一种学习文本到文本新范式。DSI 模型将字符串查询直接映射到相关文档;换句话说,DSI 模型只使用自身参数直接回答查询,极大地简化了整个检索过程。
此外,本文还研究了如何表示文档及其标识符的变化、训练过程的变化以及模型和语料库大小之间的相互作用。实验表明,
在适当的设计选择下,DSI 明显优于双编码器模型等强大基线,并且 DSI 还具有强大的泛化能力,在零样本设置中优于 BM25 基线
。
![]()
论文链接:https://arxiv.org/pdf/2202.06991.pdf
![]()
论文一作、谷歌高级研究员 Yi Tay 表示:在这个新范式中,检索的所有内容都映射到易于理解的 ML 任务上。索引是模型训练的一种特殊情况,不再依赖外部不可微的 MIPS 操作进行检索。这使得统一模型更容易。
![]()
DSI 背后的核心思想是在单个神经模型中完全参数化传统的多阶段先检索后排序 pipeline
。为此,DSI 模型必须支持两种基本操作模式:
在这两个操作之后,DSI 模型可以用来索引文档语料库,并对可用的带标记数据集(查询和标记文档)进行微调,然后用于检索相关文档 —— 所有这些都在单个、统一的模型中完成。与先检索后排序方法相反,
DSI 模型允许简单的端到端训练,并且可以很容易地用作更大、更复杂的神经模型的可微组件
。
![]()
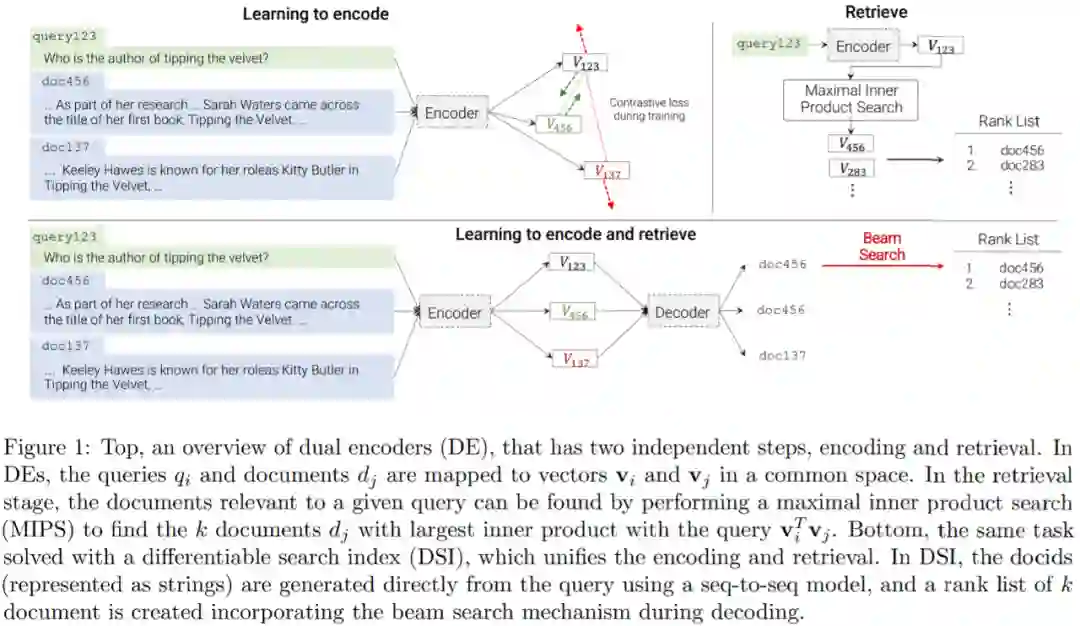
双编码器 (DE) 的概述,它有两个独立的步骤,编码和检索。
Inputs2Target
:研究者将其构建为 doc_tokens → docid 的 seq2seq 任务,此方式能够以直接输入到目标的方式将 docid 绑定到文档 token。
Targets2Inputs
:从标识符生成文档 token,即 docid → doc token。直观来讲,这相当于训练一个以 docid 为条件的自回归语言模型。
双向
:其在同一个联合训练设置中训练 Inputs2Targets 和 targets2input。附加一个 prefix token 以允许模型知道任务正在哪个方向执行。
基于 seq2seq 的 DSI 模型中的检索是通过解码给定输入查询 docid 来完成的。如何有效地解码很大程度上取决于模型中 docid 的表示方式。在本节中,研究者探讨了表示 docid 的多种可能方式以及如何处理解码。
非结构化原子标识符(Atomic Identifiers)
:表示文档最简单的方法是为每个文档分配一个任意的(并且可能是随机的)唯一整数标识符,该研究将这些标识符称为非结构化原子标识符。研究者要想使用这些标识符,一个明显的解码方式是学习标识符上的概率分布。在这种情况下,模型被训练为每个唯一的 docid (|Ndocuments|) 发出一个 logit。为了适应这种情况,该研究将标准语言模型的输出词汇表扩展如下:
![]()
简单的结构化字符串标识符
:该研究还考虑了另一种方法,将非结构化标识符 (即任意唯一整数) 视为可标记的(tokenizable)字符串,将其称为简单的结构化标识符。在此标识符下,检索是通过依次解码一个 docid 字符串来完成的。解码时,使用 beam search 来获得最佳 docid。但是,使用这种策略不容易获得 top-k 排名。不过,研究者可以彻底梳理整个 docid 空间,并获得给定查询的每个 docid 的可能性。
语义结构化标识符
:其目标是自动创建满足以下属性的标识符:(1) docid 应该捕获一些语义信息,(2) docid 的结构应该是在每一个解码 step 之后有效地减少搜索空间。给定一个需要索引的语料库,所有文档都聚集成 10 个簇。每个文档分配有一个标识符,其簇的编号从 0 到 9。下表为这个进程的伪代码:
![]()
所有 DSI 模型均使用标准预训练 T5 模型配置进行初始化
。配置名称和对应的模型参数数量为:Base (0.2B)、Large (0.8B)、XL (3B) 和 XXL (11B)。该研究用实验验证了上述各种策略的效果。
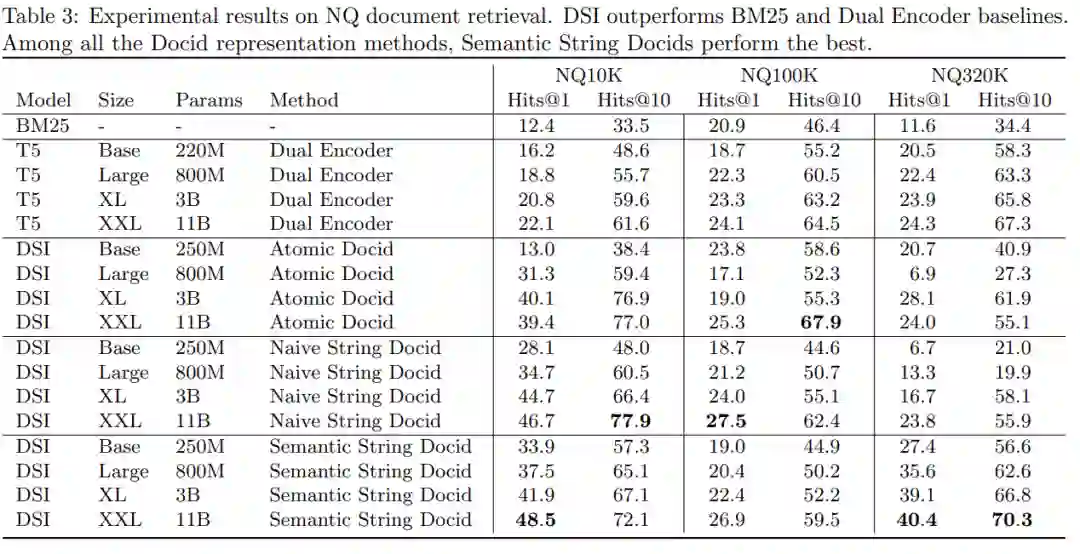
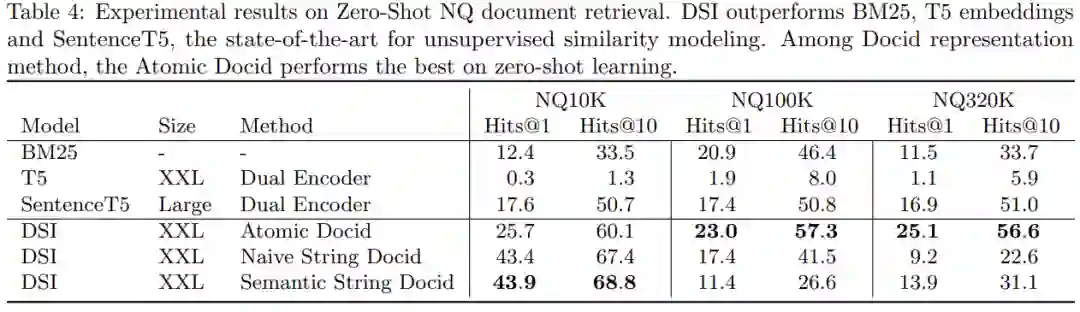
下表 3 给出了经过微调的 NQ10K、NQ100K 和 NQ320K 的检索结果,表 4 给出了零样本检索结果。对于零样本检索,模型仅针对索引任务而不是检索任务进行训练,因此模型看不到标记查询 → docid 数据点。
![]()
![]()
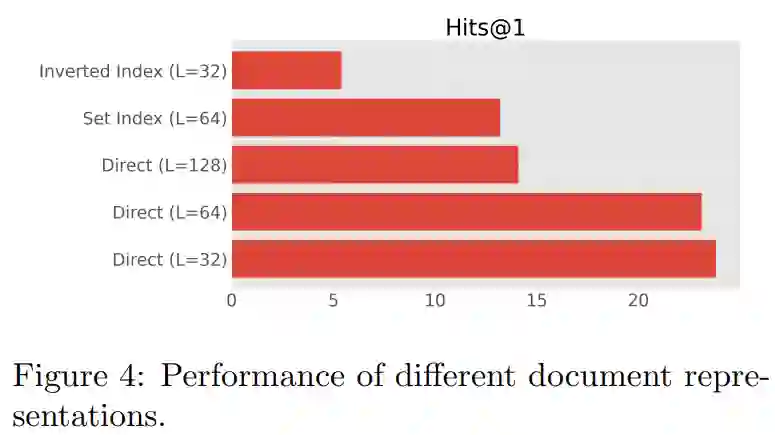
下图 4 给出了 NQ320K 上的结果。总的来说,研究者发现直接索引方法效果最好,并且由于 docid 反复暴露于不同的 token,因此很难训练倒排索引( inverted index)方法。他们还发现,较短的文档长度似乎在性能大幅下降超过 64 个 token 时效果很好,这表明当存在大量文档 token 时,可能更难优化或有效记忆。最后,研究者还发现对文档 token 应用集合处理或停用词预处理没有额外的优势。
![]()
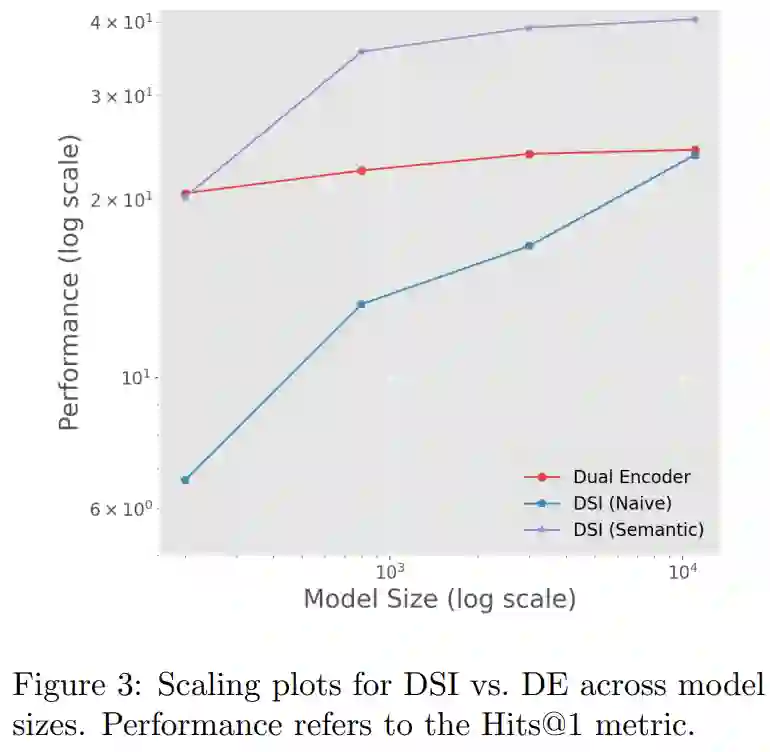
下图 3 绘制了三种方法的缩放表现(以对数尺度计),它们分别是 DE、具有 naive ID 的 DSI 和具有语义 ID 的 DSI。其中,DSI (naive) 可以从 base 到 XXL 的尺度变化中获益,并且似乎仍有改进的空间。同时,DSI (语义) 在开始时与 DE base 具有同等竞争力,但会随尺度增加表现得更好。DE 模型在较小的参数化时基本处于稳定状态。
![]()
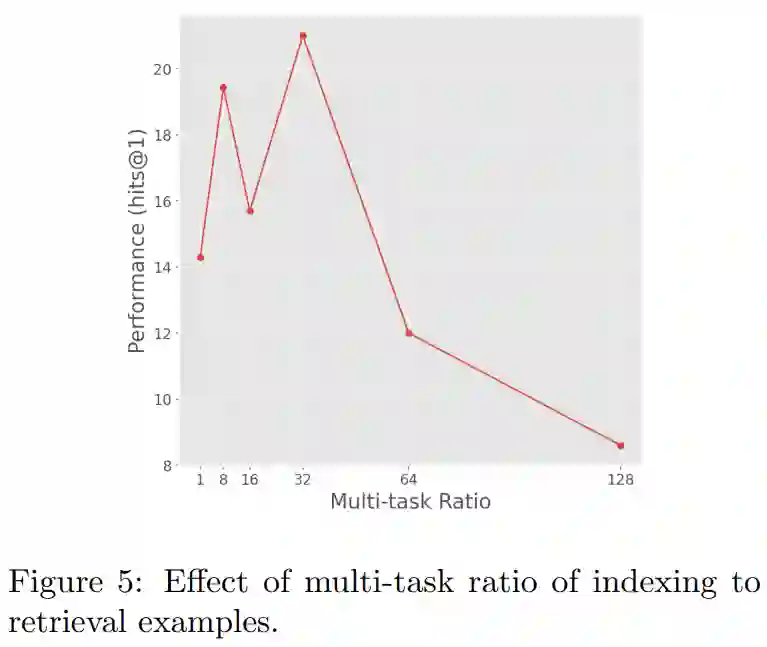
下图 5 展示了修改索引比例对检索样本的影响。研究者发现,索引和检索任务之间的相互作用会显著影响优化过程。r 值设置得过高或过低一般都会导致性能不佳。他们发现,索引比例为 32 时通常表现良好。
![]()
时在中春,阳和方起——机器之心AI科技年会
机器之
心AI科技年会将于3月23日在北
京举办,在分享交流对人工智能的判断与思考外,更重要的是与读者、合作伙伴和好友们真实的见一面。
这是一次注重交流与见面的聚会,所以叫「年会」,没叫「大会」。
在这场年会上,有三个方向我们希望和大家分享:人工智能、AI for Science和智能汽车。
人工智能论坛关注高性能计算、联邦学习、系统机器学习、强化学习、CV与NLP发展、RISC-V等。
AI x Science论坛关注AI与蛋白质、生物计算、数学、物理、化学、新材料和神经科学等领域的交叉研究进展。
首席智行官大会关注智能汽车、汽车机器人、无人驾驶商业化、车规级芯片和无人物流等。
当然,按以往的惯例,我们还将邀请行业内最具代表性与专业的权威嘉宾带来他们的思考与判断。
欢迎大家点击「阅读原文」报名活动,「中春」见。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com