【泡泡图灵智库】基于深层特征重构的单目深度估计及视觉里程计无监督学习
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Unsupervised Learning of Monocular Depth Estimation and Visual Odometry with Deep Feature Reconstruction
作者:Yinda Zhang, Ravi Garg, and Chamara Saroj Weerasekera
来源:arXiv cs:CV
播音员:四姑娘
编译:李建华
审核:陈建华
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——基于深层特征重构的单目深度估计及视觉里程计无监督学习,该文章发表于arXiv cs:CV 2018。
基于学习的方法在单目深度估计和视觉里程计任务中展现了光明的前途,但他们多半是基于监督的方法。最近的单目深度估计方法探索了在没有完全监督的情况下进行学习的可能性,该方法通过最小化光度误差来实现。在本文中,我们探讨了使用立体图像序列来学习深度估计和视觉里程计。使用立体序列可以同时利用空间(左右)和时间(向后)的光度扭曲误差,并将场景深度和相机运动限制在真实的尺度内。在测试时,我们的框架能够从单目序列中估计单目深度和两视角的里程计。我们还展示了在标准光度测量的扭曲损失基础上,通过考虑深层特征的扭曲来提升性能。深入的实验表明:(1)通过联合训练单目深度估计和视觉里程计,在深度上增加约束,可改进深度估计的精度。同时,视觉里程计的学习结果也很有竞争力。(2)基于深层特征的扭曲损失相对于单纯的光度歪曲损失,对单目深度估计和视觉里程计性能提升都有贡献。在KITTI驾驶数据集上,我们的方法在两项任务中均优于现有的学习方法。本文源码见https://github.com/Huangying-Zhan/ Depth-VO-Feat。
介绍
深度估计和视觉里程计是机器人视觉中的基本问题,在自动驾驶方面有重要的应用。除了基于几何的解决方案外,现有基于学习的方案多数是基于监督学习模式,需要大量的标注数据,成本较高。而最近的无监督方案存在尺度不确定性问题。
本文工作的目标是解决无监督学习的尺度不确定问题,采用双目数据联合训练深度估计和视觉里程计网络,应用时只需单目图像输入即可。
主要贡献有:
1.提出了联合学习深度估计和视觉里程计的无监督框架,且不存在尺度不确定性问题。
2.利用了图像对在时空上的约束,在现有技术基础上,改进了单目深度估计的性能。
3.设计了最先进的、基于帧到帧的视觉里程计,性能显著优于同类无监督学习方法,且与基于几何的方法相当。
4.在图像重构的颜色及强度损失之外,使用了新的重构特征损失,显著提高了深度估计和视觉里程计的精度。
算法流程
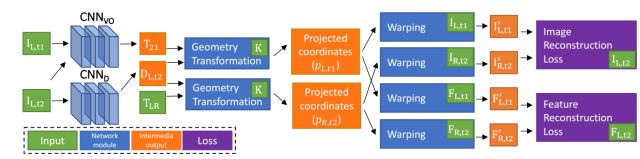
图1 训练流程图
训练时,采用双目图像序列I为输入,下标L代表左,R代表右,CNNvo对应视觉里程计训练网络,CNND对应深度估计网络。VO网络根据单目的前后序列图像,输出两个时刻间的变换矩阵T21的估计值,深度估计网络根据单目图像,输出深度的估计值。该值再结合左右视图的变换矩阵TLR,以及相机的内参K,可以从左图重构出右图,还可以把左图的特征映射到右图。重构图和特征与真值的差异构成了损失函数,利用反向传播算法可以不断优化网络。
训练完成后,只利用单目数据做输入,即可得到深度估计值和单目相机的转移矩阵(可实现视觉里程计的功能)。
主要结果
在KITTI数据集上进行了测试。
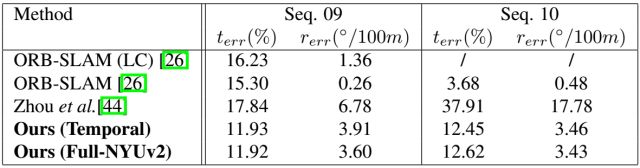
图2 视觉里程计的测试结果,terr为平均位置漂移误差,rerr为平均旋转漂移误差
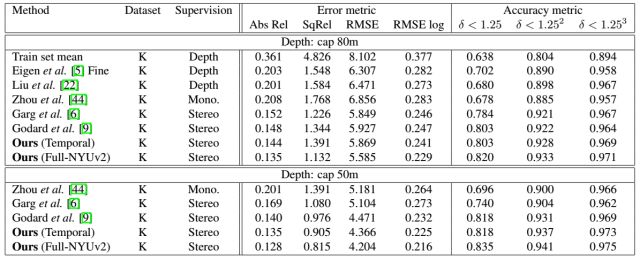
图3 深度估计误差结果,K代表KITTI数据集。Depth代表使用真实的深度数据进行训练;Mono代表使用单目图像;Stereo表示使用立体视角图进行训练,相机间的姿态关系已知。
测试表明,本文的无监督学习方法在深度估计以及视觉里程计学习方面比现有的无监督方案要好。
本文的方法要求场景无遮挡且为刚体。未来,在真实情景应用中,还需要对动态场景及遮挡进行建模。

Abstract
Despite learning based methods showing promising results in single view depth estimation and visual odometry, most existing approaches treat the tasks in a supervised manner. Recent approaches to single view depth estimation explore the possibility of learning without full supervision via minimizing photometric error. In this paper, we explore the use of stereo sequences for learning depth and visual odometry. The use of stereo sequences enables the use of both spatial (between left-right pairs) and temporal (forward backward) photometric warp error, and constrains the scene depth and camera motion to be in a common, real world scale. At test time our framework is able to estimate single view depth and two-view odometry from a monocular sequence. We also show how we can improve on a standard photometric warp loss by considering a warp of deep features. We show through extensive experiments that: (i) jointly training for single view depth and visual odometry improves depth prediction because of the additional constraint imposed on depths and achieves competitive results for visual odometry; (ii) deep feature-based warping loss improves upon simple photometric warp loss for both single view depth estimation and visual odometry. Our method outperforms existing learning based methods on the KITTI driving dataset in both tasks. The source code is available at https://github.com/Huangying-Zhan/ Depth-VO-Feat.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com