OSDI'21 | P3: Distributed Deep Graph Learning at Scale
最近GNN真的一个炒得火热的topic,无论是算法还是系统。OSDI 21更是一口气接收了四篇GNN和GE相关的论文。正好自己最近也在做这个方向,挑两篇出来精读一下,跟大家交流一下。

https://www.usenix.org/system/files/osdi21-gandhi.pdf
微软做的一篇关于分布式GNN training的work。重点也是关注在大规模分布式的GNN训练下,如何将最重的第一层的计算分摊在所有机器上,从而隐藏掉大量的机器由于feature网络通信带来的性能下降。因为GPU的利用率下降的主要原因也在于mini-batch下网络通信成为瓶颈,后续训练数据不能及时的到GPU进行计算,所以这种方式也可以自然的提升GPU的使用率。
Background: GNN训练不同于传统DNN网络的的一个关键点是: DNN训练数据之间都是独立的,而图结构则是呈现一定的关联性。而且,对于图上的顶点和/或边,一般也都会带有一些高维的feature。一个K层的GNN网络,对于每个节点,都需要1-hop到k-hop的邻居构成该节点的computation graph。所以一般会使用neighborhood sampling来进一步降低整个computation graph的大小,来使其能够fit进GPU里。而且对于biliions node and edge级别的图,分布式训练就不可避免了。https://pic1.zhimg.com/80/v2-31e4a8ee85b76b46ce95083460e4e540_1440w.jpg
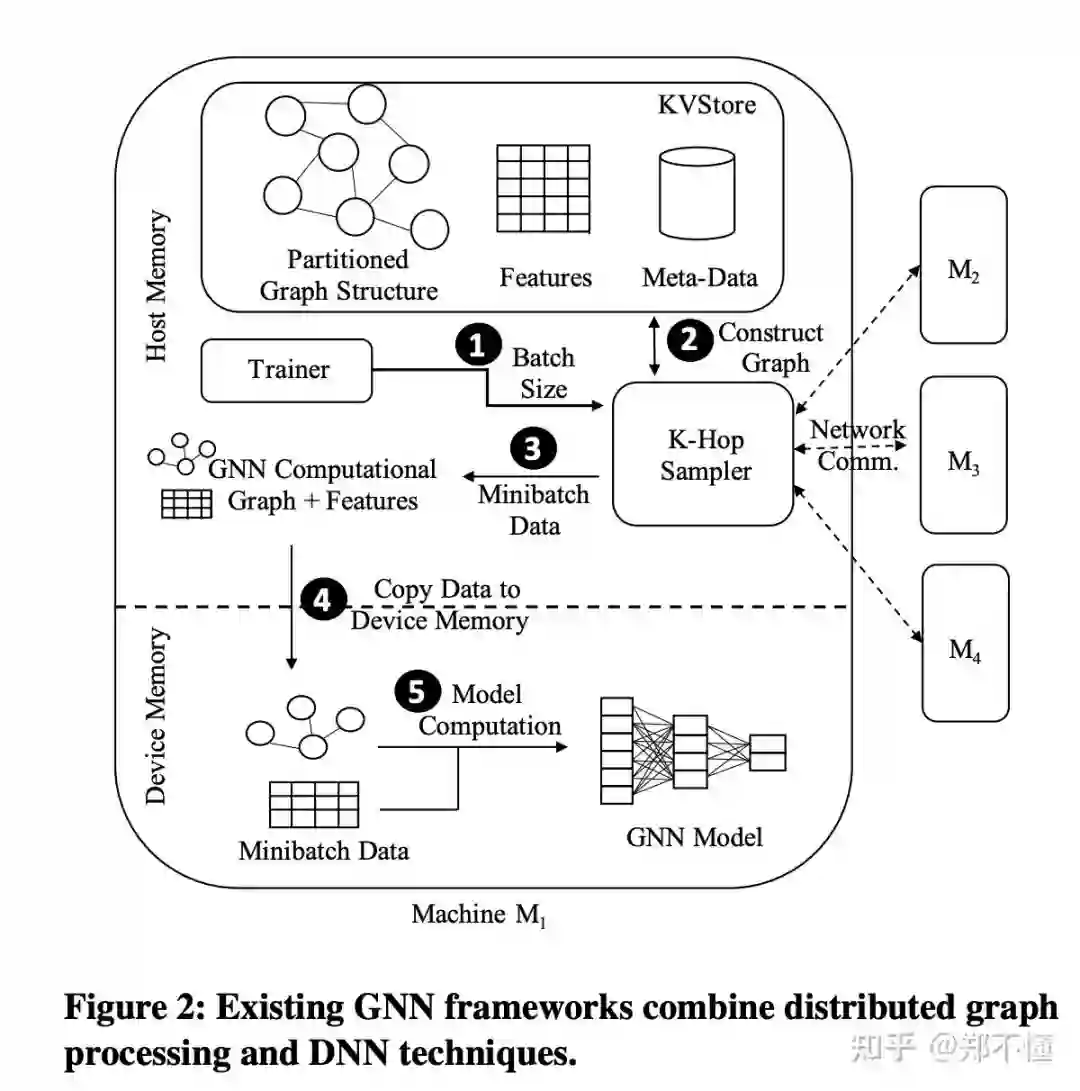
P3的设计主要基于以下三个观察:
-
由于data dependency, 在分布式情况下,生成训练computation graph的网络通信占据了整个训练时间的主要部分。
-
一些分布式图处理技术比如partition 对于GNN的训练并没有很大帮助。partition的overhead很大,而且一般都是在关注在相邻结构的信息,对于GNN这种需要关注多hops的workload可能并不适用。
-
在GNN训练中,GPU的利用率非常低,80%的时间都因为通信的的瓶颈而被堵塞,导致闲置。
P3系统设计Pipelined Push-Pull:
一. 将图的topology和feature分别存储,并且feature按列切分。
图的topology hash partition没什么好说的,把每个点hash 映射到某台机器,同时存储以该点为起始点的edge。但是这个feature的切分相当于对于每个worker,都有完整所有点的feature的某些维(对于一个F维的feature,假设存在N台worker,那么每台机器存储F/N维feature),不需要关心任何图分布的问题。
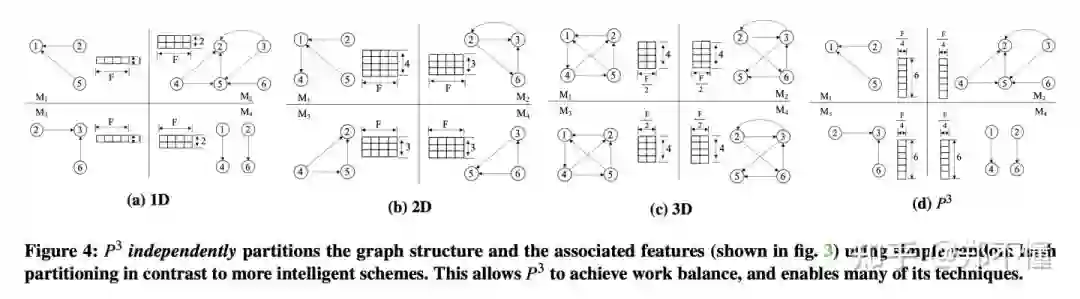
二. P3的Push-Pull 机制
1. 对于Computation Graph的生成。
采用正常的pull base的机制。从起始seed node开始,每次向外拉取之间相连的邻居的node,重复K次,构建整体K-hop neighborhood信息,不过,这里只需要拿到对应的图结构信息,并不需要拉取对应的feature,所以整体的网络消耗会非常低。
而为了避免正常的拉取全部feature所带来的巨大的网络消耗,这里采用了hybrid parallelism approach(model parallelism + data parallelism), P3将其命名为 push-pull parallelism。
2. 对于Computation Graph的执行。
这里将整个执行流程拆成8步:
-
将每台机器生产layer 1的computation graph推到所有worker上去。
-
因为将feature均匀分布在不同机器上,这里每台机器拿到layer 1的computation graph以后就可以开始进行前向传播,拿到一个partial activations结果。这里就可以类比于model parallel, 因为每台机器只有F/N维的feature,所以相当于只用到了第一层网络的( F/N * Hidden size )个参数。这里因为没有什么网络消耗,所以GPU的使用率(非空闲时间/总时间)也大大提高。
-
然后将所有在其他机器的partial activations结果aggregate起来,做一个reduce操作,就得到了对应的第一层输出。
-
当然可能也存在一些不可聚合的函数,例如ReLU函数。所以这里后面还需要接一个Layer 1D,进一步的转化结果。后面就可以进行正常的data parallelism。
-
最后经过后面K-1层网络,得到最终的embeding,计算出loss,完成前向传播。
-
然后到layer 1D之前,完成正常的data parallelism,更新对应的网络参数。
-
之后push对应的error gradient到所有机器,又切换回model parallelism。
-
然后进行本地对应的模型参数更新。(本地的部分feature对应的部分模型参数。)
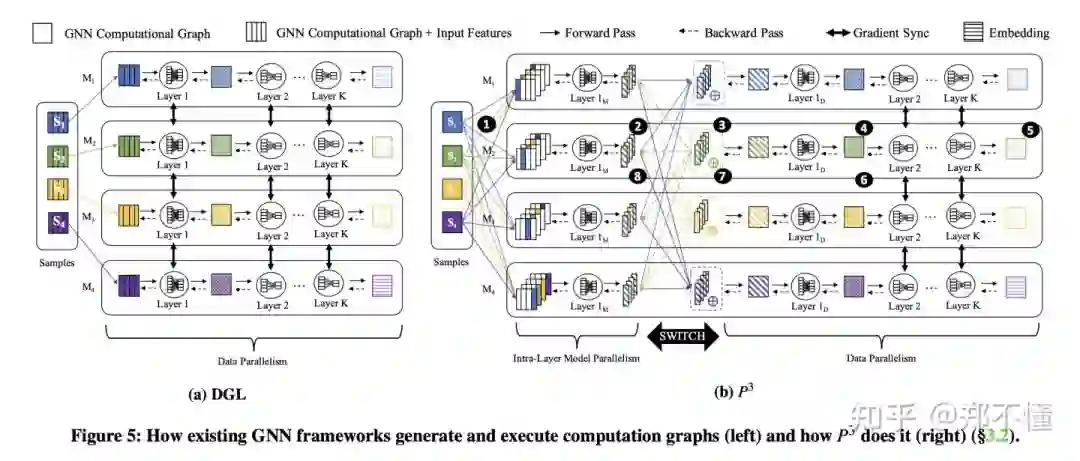
为什么说这样做可以节省网络开销呢?
-
相当于减少了一个hop的feature通信。
-
只有第一层会这样partially computed and aggregated.
具体的例子:

(我算了一下,它这里的71MB = 188339 * 100 / 1024 / 1024 * 4 相当于把所有点的feature都走网络拉取)。
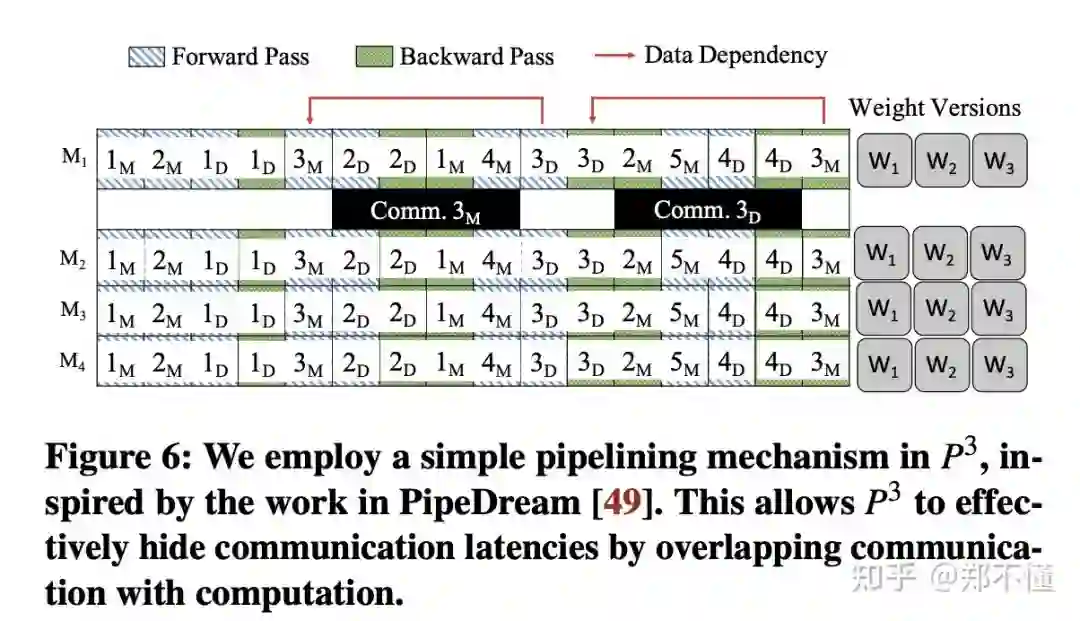
3. Pipelining
之前的一些设计都是为了减少网络消耗的时间,为了更好的overlap 通信和计算过程,P3采用了类似于PipeDream的pipeline机制。
首先,根据之前的设计,可以将一个mini-batch的计算转化为4个阶段,
-
Model Parallelism in Forward -
Data Parallelism in Forward -
Data parallelism in Backward -
Model parallelism in Backward
然后,根据4个阶段,同时3个minibatch进行计算(没看过pipedream,不知道知道3是怎么算出来的)。可以让两个forward阶段和两个backward阶段同时进行。然后论文也证明了一下这样同时三个minibatch进行计算不会影响收敛和内存消耗并不大。
4. Cache

感觉这里就不是每台机器F/N的feature了。而且尽可能的放,然后再 replicate。看描述都是针对于host memory的,没有什么GPU cache的操作。(sad
实验:
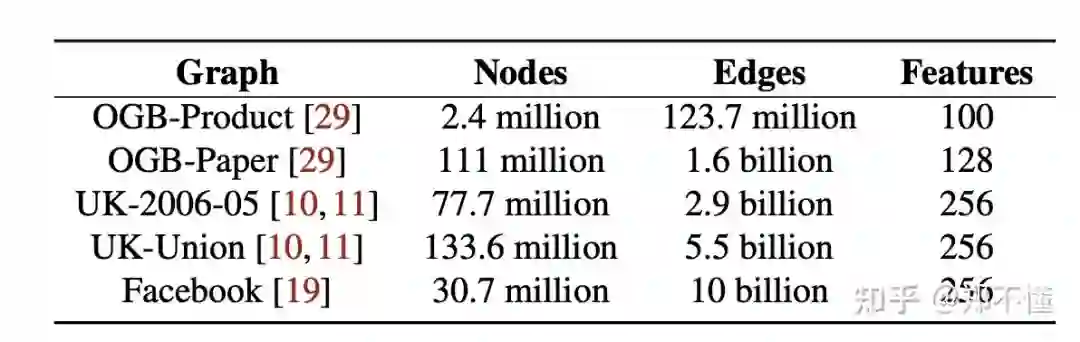
(大家现在都是在疯狂的搞大图,但是一般都是随机产生feature。)
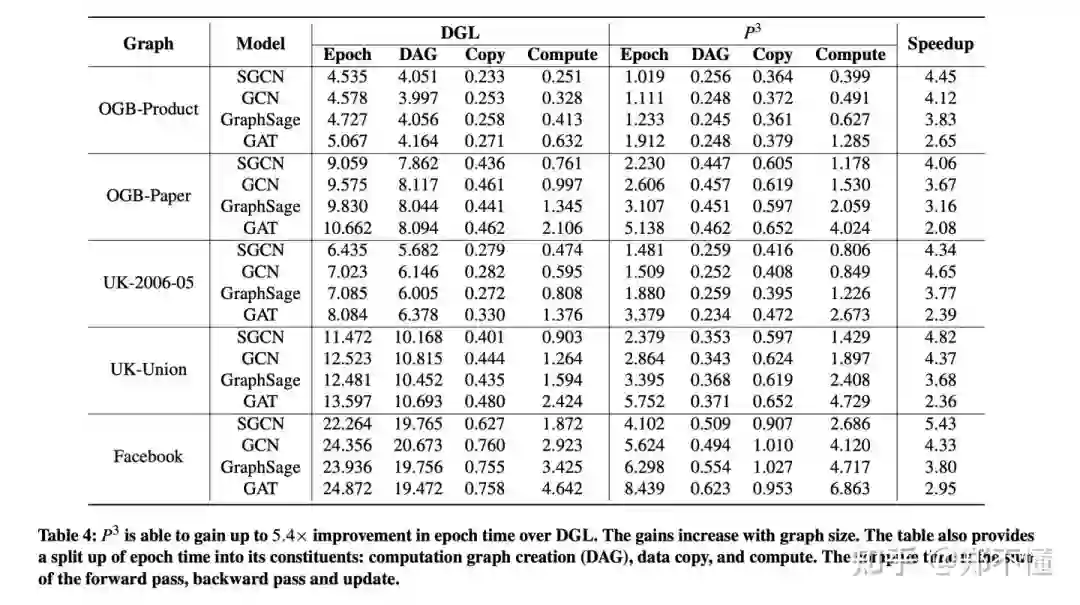
因为没有拉feature,只有图结构,所以 computation graph非常快,然后因为其他额外的push-pull操作,导致data copy和compute的时间稍稍有些增加。
讨论和思考 :
1.整体理解下来,设计还是比较清晰的。核心思路就是通过将第一层的计算分散在所有机器,减少网络开销。对于网络消耗,我又仔细想一想,整理了一个公式。n为集群的规模。(理想情况,应该是忽略了一些细节。)
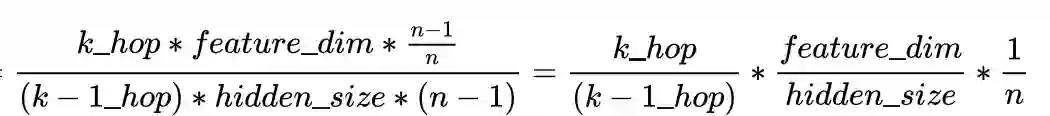
首先第一项就是看 ,第k层邻居数量和第k-1层邻居的数量,所以图的density和fanout的参数设置也可能对于性能的提升也有一定的影响,如果图比较稀疏或者对于深层的节点fanout比较小,那可能性能提升的会变少。第二项 就是5.10讨论的hidden size的问题了。但是根据RoC的观点,实际上layer和hidden_size的增加应该是会让模型性能进一步提升的。所以,这个缺点感觉还挺值得好好思考一下。第三项就是集群的规模。因为P3其实不论每台机器分到多少feature,由于model parallelism,所以要传输的数据大小是不变的,这样就导致,如果集群数量提升,那么增加的网络消耗是线性的,但是论文实验并没有显示出来(甚至throughput还是线性增长),不过论文中还是谈及了,良心。(还是 n 从2 到 4 变化不太够)
2.整体GPU使用率提升了,但是利用率看起来还是不太够。这个方向可能还是有很大的提升空间。
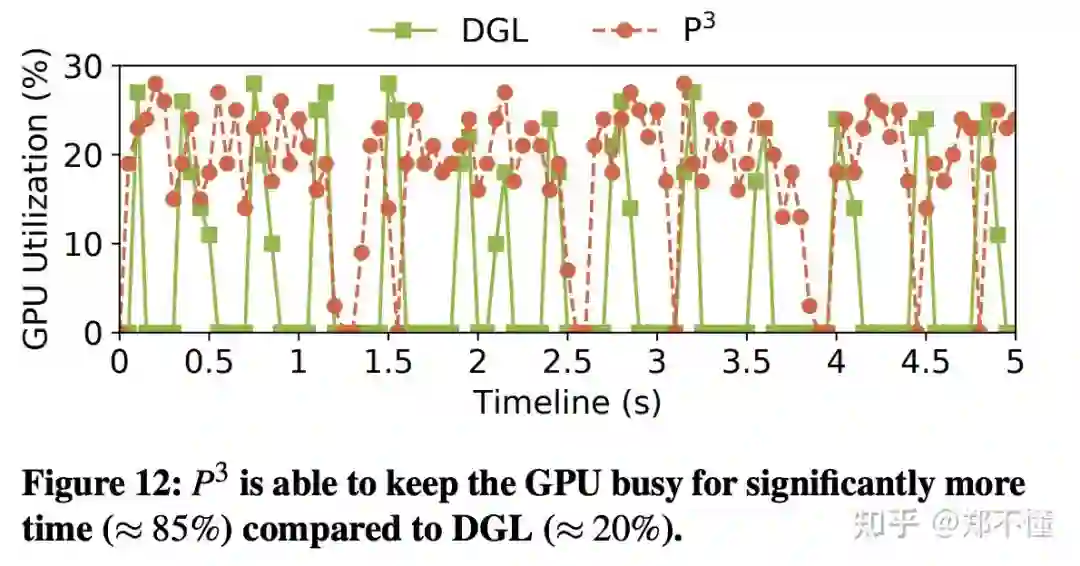
-
以及我还是对它觉得graph partition不行这种观点不太赞同。




