论文笔记:WSDM 2021 GraphSMOTE
前言
现有的 GNN 默认节点 samples 的类别满足 balance 的条件,但是在现实世界中可能存在 class imbalance 的情况。如果直接训练 GNN model 可能存在依赖偏好导致模型性能欠佳,基于此本文提出了 GraphSMOTE ,GraphSMOTE 构造了一个嵌入空间来编码节点之间的相似性,基于此生成 new samples。此外,同时训练一个edge generator 来对关系信息进行建模提供给 new samples,该框架具备良好的可扩展性。
如果大家对大图数据上高效可扩展的 GNN 和基于图的隐私计算感兴趣,欢迎关注我的 Github,之后会不断更新相关的论文和代码的学习笔记。
链接:https://github.com/XunKaiLi/Awesome-GNN-Research
1.Motivation
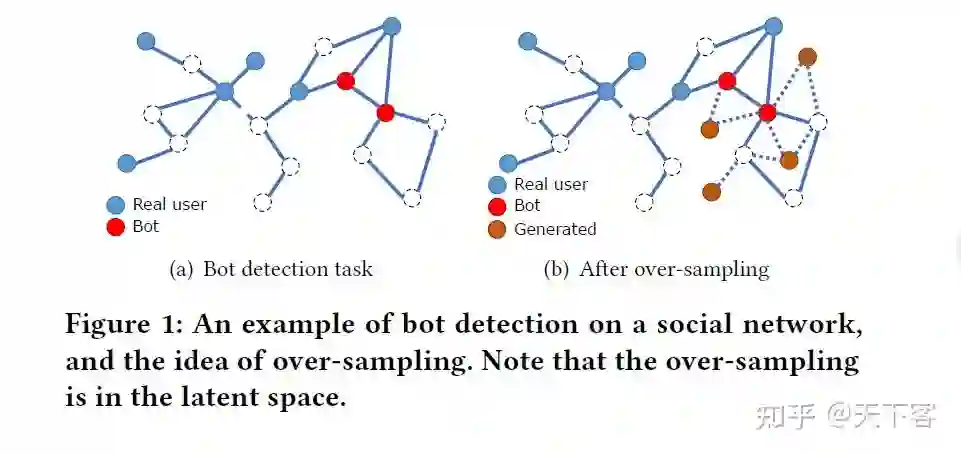
现在世界中的 class imbalance 问题的一些例子:虚假账户检测,社交网络上的正常用户和机器人账号。同样,网站页面的主题分类,一些主题类别可能因为受众度等原因缺乏标签。
在机器学习领域,class imbalance 问题的解决办法分类如下:
-
Data-level;
-
Algorithm-level;
-
Hybrid-level。
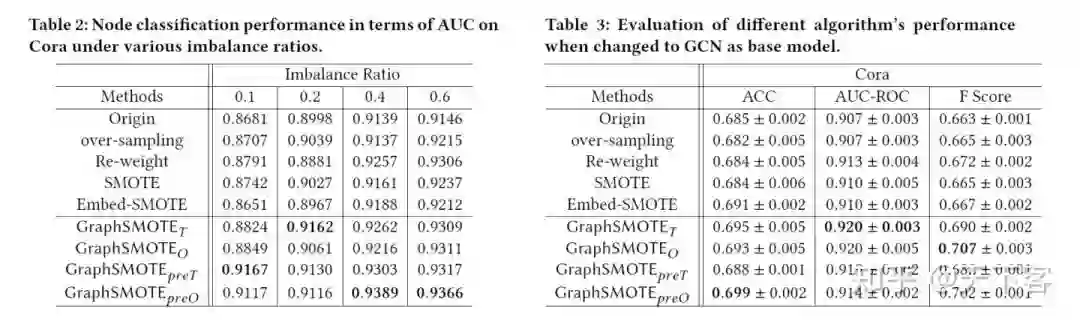
Data-level 方法希望类分布更加平衡,使用 over-sampling 或 down-sampling 方法来实现;algorithm-level 方法为不同的类引入不同的误分类惩罚或先验概率;hybrid-level 方法结合上述两类方法的特点。然而由于图结构的特殊性,上述方法直接应用于图数据上的效果不佳,因为在训练过程需要充分考虑节点之间的关系,class imbalance 不仅会影响其嵌入质量,而且会影响相邻节点之间的特征信息传播过程。
原有的 class imbalance 问题的解决方法不能很好适用于图数据的原因如下:
很难为合成的 new samples 生成关系信息。over-sampling 方法使用目标样本与其最近邻之间的插值来生成新的 training samples。然而插值可能破坏拓扑结构;合成的 new samples 质量可能较低,直接原因在于高维的节点属性,直接对其进行插值不利于 GNN model 的训练。synthetic minority oversampling techniques(SMOTE)是解决 class imbalance 最有效的方法。在图数据集上应用 SMOTE 的难点如下:1. 原始特征空间上的合成节点生成未充分考虑图数据自带的复杂信息;2. 新生成的节点无法与现有图建立关系(edges),对于 GNN model 来说难以利用。基于上述问题,本文提出 GraphSMOTE。
2. GraphSMOTE
在训练过程中图中只有部分节点 带有标签信息 ,总共有 类 , 代表第 类的数量,基于此使用 imbalance ratio 来衡量 class imbalance。如果存在 class imbalance 问题则相应的系数较小。模型目标是希望在 class imbalance 的前提下学习得到一个分类器 能够在 majority 和 minority classes 上都表现良 好:
其中 代表节点属性的特征矩阵。
GraphSMOTE 的主要思想是在基于 GNN 的 feature extractor 通过插值生成少数类 new samples,并利用 edge generator 补全关系信息,形成一个增广的平衡图。
GraphSMOTE 由四部分组成:
-
GNN-based feature extractor (encoder),用于学习节点表示,保留节点属性和图拓扑结构信息来生成 new samples; -
Synthetic node generator,用于在嵌入空间中生成少数类 new samples; -
Edge generator,用于补全 new samples 的关系信息; -
GNN-based classifier ,基于在增广平衡图上执行节点分类。
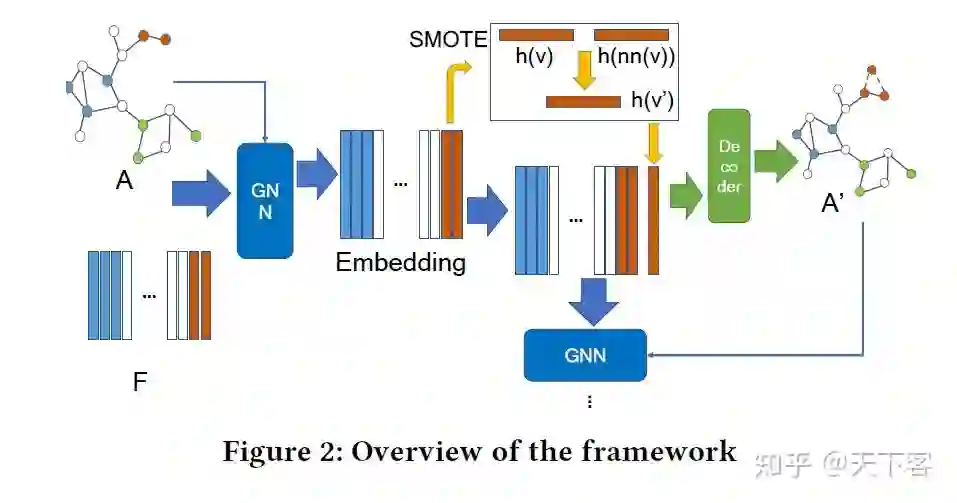
2.1 Feature Extractor
使用 Feature extractor 的出发点有二:低维嵌入空间中,samples 的空间分布更加接近;经过 GNN 编码可以提取到一定的图拓扑结构信息。并且遵循一个假设:当前节点与最近邻节点的插值特征以更高的概率表示为当前节点的标签信息。在图中,节点的相似性需要考虑节点属性、节点标签以及局部图结构。本文基于 GNN 在 edge prediction 和 node classification 两个下游任务上对其进行训练。
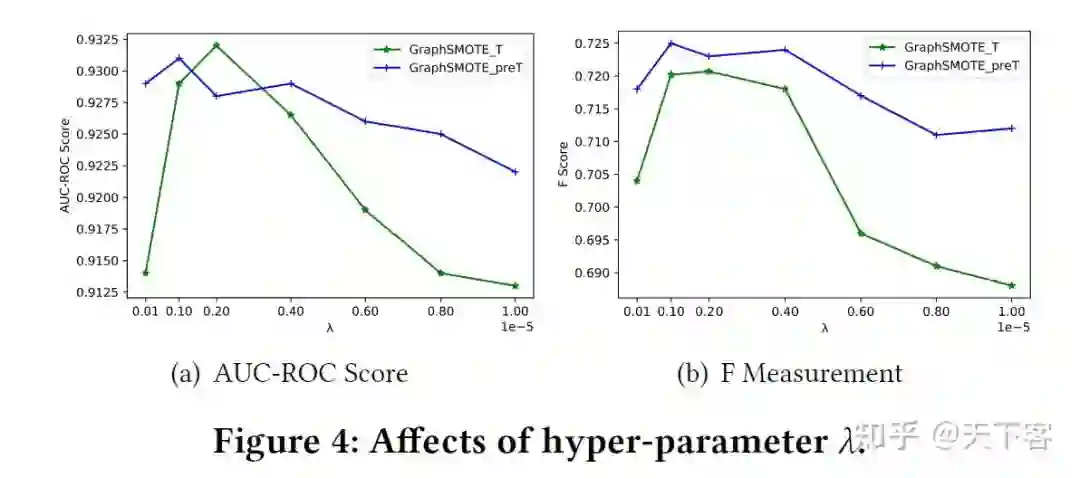
考虑到 over-smoothing 和 over-fitting 问题,feature extractor 使用一层的 GraphSAGE 实现:
2.2 Synthetic Node Generation
该模块为少数类生成 new samples, SMOTE 的基本思想是将来自目标少数类的样本与它们在嵌 入空间中最近的邻域进行揷值,这些样本应属于同一类 (假没条件)。设 为少数节点,标记 为 。第一步是找到与 相同类别的最近标记节点:
指来自同一类的 的最近邻居,使用嵌入空间中的欧氏距离来衡量该指标。生成少数类 new samples:
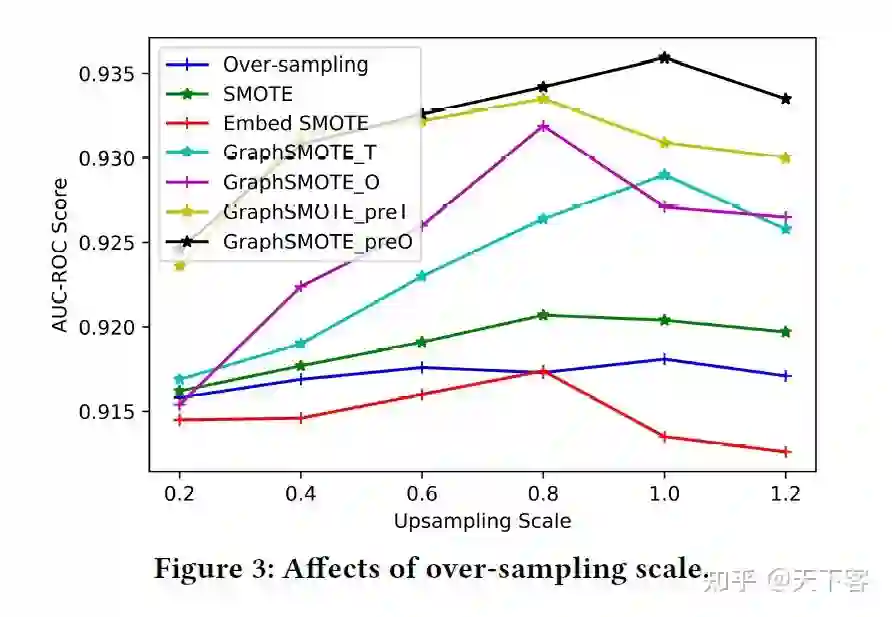
对于每一个少数类,可以应用 SMOTE 来生成完整的节点。使用超参数、over-sampling 比例来控制为每一类生成的样本量。通过这个生成过程,可以使类的大小分布更加均衡。
2.3 Edge Generator
其中 代表捕捉节点对之间交互信息的参数矩阵, edge generator 的损失函数为:
其中 指的是 中的节点之间的预测连接(预测原本存在的连接关系来使 学习到如何捕获 节点对的信息交互过程) 。基于此认为生成的 new samples 所预测的连接关系也是准确的。之后本文尝试了两种增广图数据的构建方法分别为 :
2.4 GNN Classifier
基于上述的增广图数据策略得到 ,其中带有标签节点集为 ,并且此时的 class imbalance 问题得到了改善,GNN Classifier 形式如下 (最后接一个线性层完成节点分 类):
其中 代表第二个 GraphSAGE 模块,该模块使用交叉嫡损失函数:
预测结果:
2.5 Training Algorithm

全局目标函数为:
其中 分别代表 feature extractor, edge generator 和 node classifier 模块的可训练参 数。
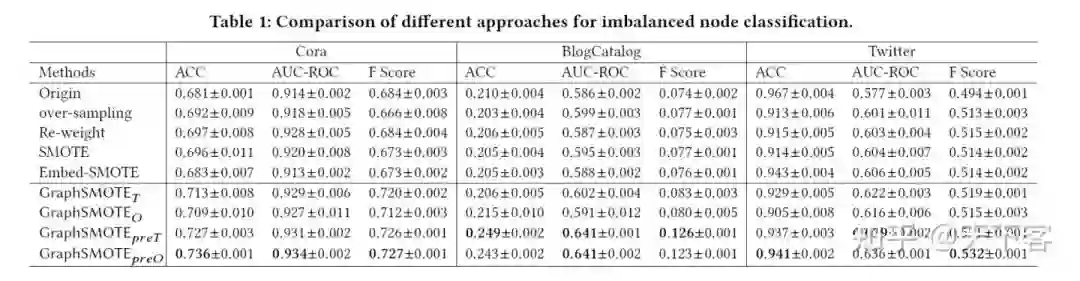
3. Experiments
baselines
-
Over-sampling: 一种解决不平衡学习问题的经典方法,通过重复采样来自少数类的样本。在 原始输入空间中沿其 edges 采样 个少数类节点。在每次训练中包含 个节点, ; -
Re-weight: 一种成本敏感的方法,赋予少数样本较高的损失,以缓解多数类支配损失函数的问 题; -
SMOTE:经典的 SMOTE 方法,对于 new samples,将其边设置为与目标节点相同的边; -
Embed-SMOTE: SMOTE 的一种扩展,用于深度学习场景,在中间嵌入层而不是输入执行 over-sampling。将其设置为最后一层 GNN 的输出,这样就不需要生成 edges; -
GraphSMOTE :使用仅来自 edges prediction 任务的损失来训练 edge generator。用阈 值将预测的 edges 设置为二进制值; -
GraphSMOTE : 预测的 edges 被设置为连续的,梯度可以从基于 GNN 的分类器中计算和 传播。用来自 edges generation 任务和 nodes classification 任务的训练损失一起训练 edges generator; -
GraphSMOTE preT : GraphSMOTE 的扩展,在参与整体训练之前,对 edges generator 进行预训练; -
GraphSMOTE preO : GraphSMOTE 的扩展,在参与整体训练之前,对 edges generator 进行预训练;