淘宝首页搜索背后的GNN
下拉推荐属于搜索场景的导购产品,见图 1.1 所示,其意义在于对用户想搜的Query进行补全,以提高用户的搜索效率。近几年下拉推荐排序模型升级到了深度模型,并进行了多次迭代优化,其中一个关键技术是用户行为序列建模。用户行为序列建模是搜索推荐场景刻画用户兴趣偏好变化的常用技术。从行为周期上,可以将行为序列划分为中短期和长期,分别使用不同的时间跨度描述不同粒度的兴趣。在下拉推荐场景,模型使用两个中短期序列,近半个月行为过的Query序列和Item序列,分别与待排序的Query做Target Attention抽取与当前用户意图相关的偏好。与不使用序列的模型相比,离线AUC有多个pt的提升,由此可见序列建模的重要性。最初下拉模型只使用了长度为10的Item序列,后来扩展到长度为50的Query和Item序列,直观上看,将序列加长可以包含更丰富的用户历史行为,但是也存在着以下几点问题:
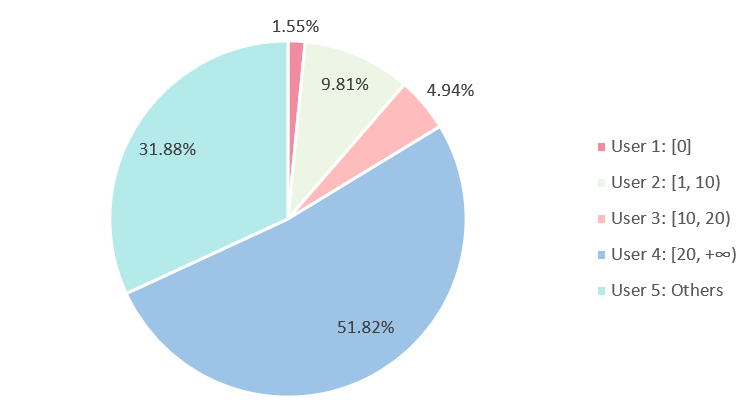
图1.2 用户活跃度分布(20210711)
▐ 问题1:加长序列无法作用于历史行为稀疏的不活跃用户
目前下拉模型使用用户近半个月的Query和Item序列,根据序列长度我们可以对用户的活跃度进行划分,详情见图 1.2所示,表示两个序列的长度都落在某个范围内。可以看到,只有一半的用户近半个月行为过的Query和Item都超过20个,大约有16%左右的用户行为过的Query和Item都不满20个。对于这些不活跃的用户,我们无法加长他们的行为序列,预期模型也不能做出较好地预测。图 1.3是Base模型在不同活跃度用户上的AUC,后缀表示训练样本中行为序列的最大长度,可以看到,base_20和base_50在行为序列长度小于20的用户上效果几乎持平。对于那些可以加长行为序列的用户,base_50则表现得比base_20好得多,符合预期。
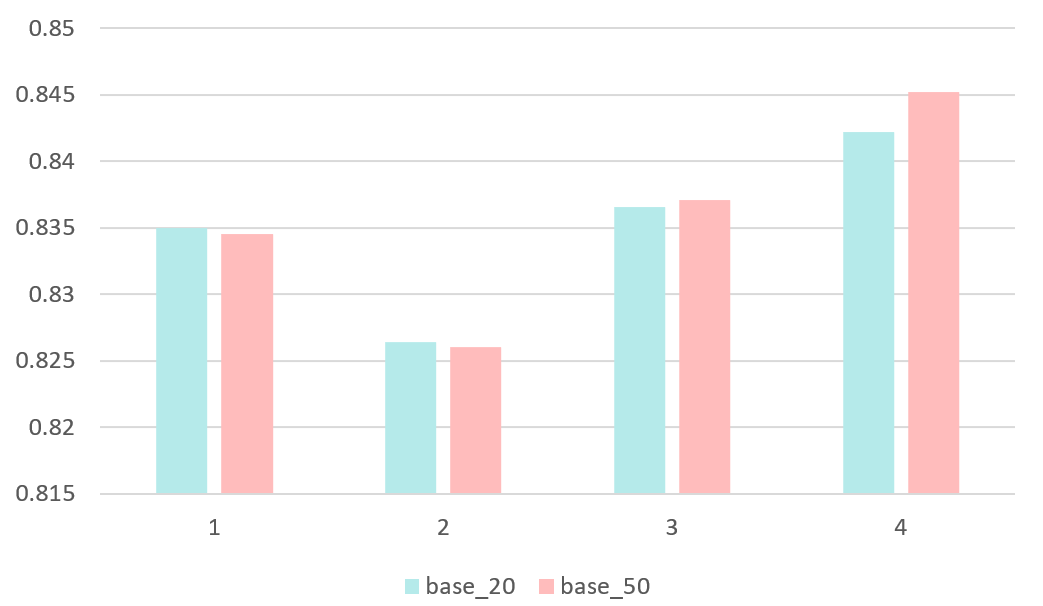
图 1.3 Base模型在不同活跃度用户上的AUC(20210711)
▐ 问题2:加长序列对曝光次数较少的长尾Query的效果较弱
在下拉场景马太现象非常明显,一小部分Query占据了绝大多数PV。长尾Query不仅训练样本比较少,在Query序列里占比也比较低。加长序列可以包含更多的Query,使得Query Embedding被更充分地学习,但是对长尾Query效果相对有限。图 1.4是Base模型在不同PV的Query上AUC,1-10表示PV从高到低,可以看到,相比较base_20,base_50在长尾Query上的提升远不如高频Query。
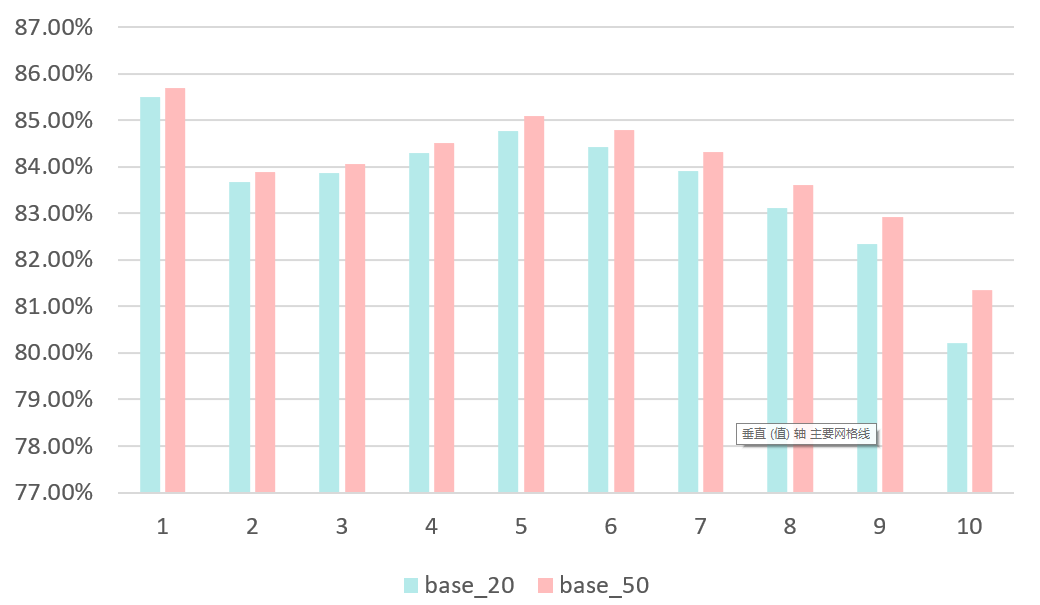
图1.4 Base模型在不同PV的Query上的AUC(20210711)
▐ 问题3:加长序列带来的收益与巨大的存储消耗之比不高
一方面,加长序列所带来的收益具有边际效应,通过可视化Attention值也能发现,序列中的有效成分主要集中在前20,如图 1.5所示(颜色越浅Attention值越大)。另一方面,行为序列内是大量重复的Query、Item等,在当前的数据组织方式下有冗余存储的问题,是训练数据和样本中的存储大头。事实上,存储资源紧张也是目前部门内的一个较为突出的问题。

图 1.5Query序列Attention值热力图
既然加长序列存在着以上一些问题,是否存在更有效的拓展序列的方式?排序模型通过行为序列抽取用户偏好,相当于在Item-User-Query异构图中分别聚合1阶Item和Query邻居来表征用户User,我们自然想到可以通过构建更加复杂的图结构来为序列提效。例如,构建一张Query和Item之间的异构图,通过GNN在图中聚合邻居结点,学习Query或Item的Graph Context信息,用于表征用户的宽泛的潜在的偏好。图 1.6是一个例子,用户搜过“西餐餐具”,在输入“牛”前缀时,由于“西餐餐具”的Graph Context信息中包含了“牛排”的信息(两者在图中是邻居),模型就更可能把“牛排”排到“牛仔裤”的前面。可以看到,无论对于不活跃用户还是长尾Query,都可以在图中获取到一些额外的信息,并且通过邻居间的交互促进对Embedding的学习。
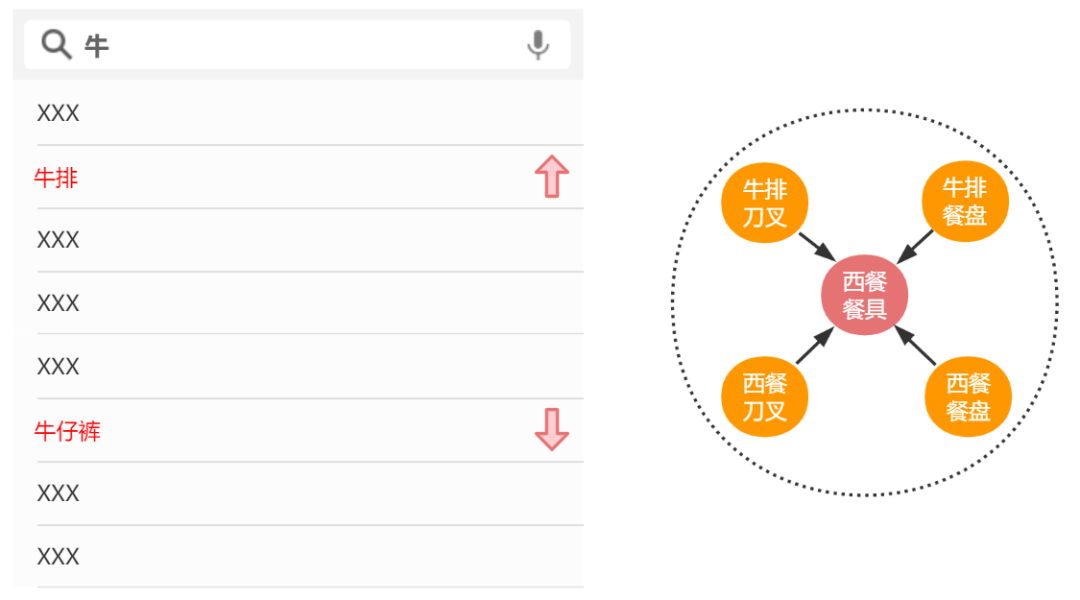
图 1.6 邻居信息
总的来说,针对上述三个问题,我们引入邻居信息,用图神经网络建模,期望在更小的存储消耗下更有效地拓展序列,并对不活跃用户和长尾Query有较好的效果。同时结合实验分析归纳出一些GNN在下拉场景的一般性的结论。全文按照实习工作的推进顺序组织。
下拉场景的数据具有两个特点,一是数据规模庞大:每天有亿级的用户规模和亿级的样本规模;下拉底池Query的数量级为千万级。二是数据类型复杂:用户行为有点击、加购、成交等;行为对象有Query(查询)、Item(商品)等。针对这两个特点,在图神经网络方面着重调研了大规模和异构性两个方向,在搜推的应用方面着重调研了工业界的一些工作。
▐ 图神经网络的研究方面
GC-MC将RGCN作为编码器,双线性点积作为解码器,结点关系作为监督信号,将推荐任务建模为链接预测;NGCF在GCN的传播公式中加入亲和项,同时通过堆叠多层学习高阶信息;KGAT借鉴TransR建模不同类型的实体和关系,并与注意力机制相结合。以上工作都是在小数据上的尝试,并没有在大规模真实场景中落地。PinSage是Pinterest在图片推荐场景的尝试,首次将GCN应用到工业级推荐,基于Random Walk进行邻居采样,并使用了Hard Negative Sampling、Curriculum Training等技巧;MEIRec是阿里在底纹推荐场景的工作,通过meta-path随机采样邻居,对于不同类型的邻居分别采用Mean、LSTM和CNN聚合,并通过Term Embedding共享降低参数量和提高泛化性;DHGAT是阿里在商店搜索场景的工作,基于共现频数随机采样邻居,类似于HAN同时考虑邻居结点和邻域类型的重要性,并对不同类型结点Embedding空间的差异建模。
如何将图神经网络与下拉排序模型结合是一个问题,有两种可行的方式:
图神经网络部分单独预训练
得到的Query和Item Embedding以初始化或Concat的方式作为补充信息辅助排序模型的训练。但是经过咨询了解到,之前预训练的方式几乎没有效果,下拉模型使用的Embedding也都是端到端训练得到的。一个可能的原因是,端到端训练得到的Embedding与目标任务更加相关。
将GNN嵌入排序模型端到端训练。
GNN作为大模型中的一个前置模块,为序列中的Query和Item学习Graph Context信息作为补充,在CTR预估目标下进行端到端的训练。最终决定采用这种方式。
▐ 图的构建
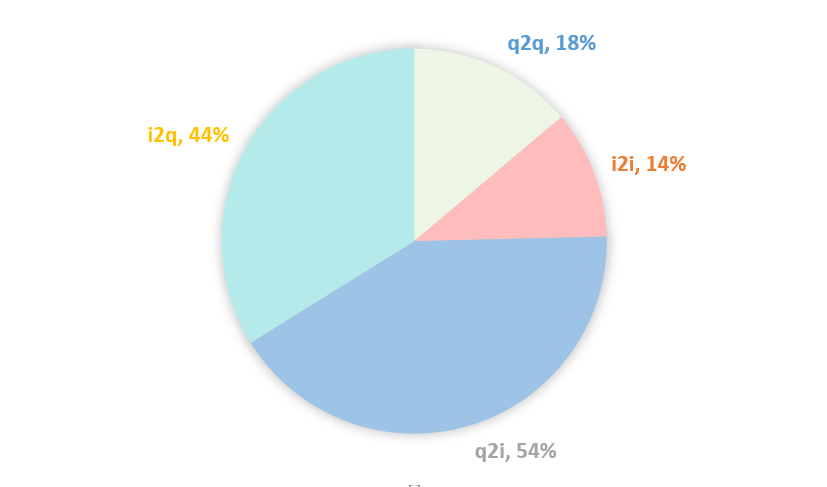
排序模型通过行为序列抽取用户偏好,相当于在Item-User-Query异构图中分别聚合1阶Item和Query邻居来表征用户User。我们可以在Item和Query之间构建更多关系引入更丰富的信息。一方面可以通过用户行为构建共现关系,例如在Query A下Item B共被购买过N次,则在Query A和Item B之间生成一条边,权重为共现频数N;另一方面可以通过Query或Item属性构建属性关系,例如Query A和Query B具有共同属性Attribute C,则在Query A和Query B之间生成一条边,权重可设置为1。本次实验只构建了共现关系。具体而言,根据内部已有的几张表,构建了Query和Item的异构高阶图,包含了q2i、i2q、q2q、i2i几种关系。
由于是通过用户行为来构建图,就需要考虑图的实时性变化。此外,图的结点和边都是上亿级别的,还需要考虑对图进行采样。图 3.1是Item“635266613678”在20210606和20210607的i2q邻居权重分布图,其top10的邻居的从高到低都是“刀叉”、“西餐餐具刀叉”、“牛排刀叉”、“刀叉餐具”、“刀叉牛排”、“西餐刀叉勺”、“西餐刀叉”、“牛排刀”、“牛排餐具刀叉”、“牛排刀叉两件套”。q2i、q2q、i2i也有类似的分布。我们可以观察到两个特点:
邻居及其权重分布在天级的时间尺度上变化不大。因此我们可以在第T天使用第T-1天的数据构建邻居。
邻居的权重集中在前几个呈现出长尾分布的趋势。如果根据权重分布进行采样,大概率会集中在前几个邻居,考虑到采样带来的额外开销,我们可以用TopN的邻居进行近似。当然这样也会存在潜在的问题,Top N估计是有偏的,也可能不利于模型的泛化性。
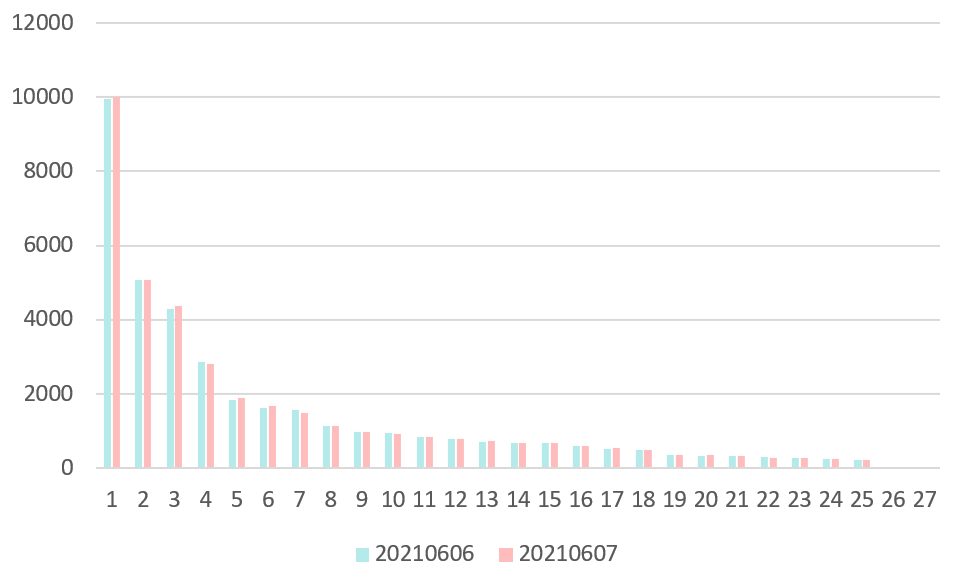
图 3.1 Item 635266613678 在20210606-20210607的邻居权重分布
▐ 特征利用
在生成训练数据时,Query和Item邻居的特征与当前排序模型基本一致。在实验时通过mc.json文件配置真正用到的特征,在不同阶段的实验中用到的特征有所变化。
▐ 模型结构
GNN作为排序模型序列建模部分的一个前置模块,为序列中的Query和Item学习Graph Context Embedding,然后通过以下两种方式进行结合,最终采用哪种方式通过实验确定。

图 3.3 模型结构(Graph Context Feature)
Graph Context Feature
将学习到的Graph Context Embedding拼接到原来序列中的Query或Item的特征上,见图 3.3中的模块2所示。

图 3.4 模型结构(Graph Context Sequence)
Graph Context Sequence
将学习到的Graph Context Embedding作为单独的序列与待排序的Query做Target Attention,抽取与用户当前意图相关的宽泛的潜在的偏好,见图 3.4中的模块2所示。
▐ 代码实现
集团内部已有AliGraph、GraphML、Euler等图框架,但是考虑到我们是在大模型上做改动,要求这些框架与AOP等平台较好地兼容,经过调查发现这些图框架均不满足,因此决定将邻居也组织成序列的格式,在模型代码中通过索引去定位各自的邻居。例如,有一个Batch的长为20的Query序列,对序列中每个Query采样5个1阶邻居,将其按照顺序组织为长为100的序列,在模型代码中Query序列的Shape为(B, 20, d)经过Reshape为(B, 20, 1, d),邻居序列的Shape为(B, 100, d)经过Reshape后为(B, 20, 5, d),邻居结点和中心结点的位置就一一对应上了,后续的GNN操作也可通过矩阵操作进行。
初期不涉及对模型本身的详细设计,主要目标是快速验证方案的可行性,同时获取一些发现以指导后续实验的调整与模型的改进。在这一阶段仅使用5个1阶邻居,20210607-20210613共计7天的数据用于训练,20210614的数据用于验证。下文中“GCN”表示以mean的方式聚合邻居,“No Aggregator”表示不经过聚合操作,直接将所有邻居用于特征拼接(Graph Context Feature)或者单独序列(Graph Context Sequence),这主要是考虑到“GCN”过于简单可能无法发挥邻居信息的作用,而“No Aggregator”作为一种无损的方式也许可以有所保证(当然前提是模型能有效抽取信息)。“Base”表示当前的下拉排序模型,“Base_20”和“Base_50”分别表示训练样本中的序列长度为50和20。需要注意的是,GNN使用的都是长为20的序列。所有模型都使用同一套超参数,例如学习率、衰减率、Batch Size等等。详细的实验设置见表 4.1。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表 4.1 实验设置
▐ Graph Context Feature
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表 4.2 Total AUC
Base_50相对Base_20有略微正向的提升,说明加长序列是有收益的但是不明显(万分之6)
对于GCN
-
加入各种邻居均有略微正向的提升,说明邻居信息是有效的但是在当前设置下效果不明显。(最高千分之1.5) -
同构邻居q2q & i2i相比异构邻居q2i & i2q效果更明显。 可能的原因是q2i & i2q数据比较稀疏,经过统计发现其存在50%左右的结点邻居个数不足5个,而q2q & i2i只有15%左右的这样的结点,更多的数据则意味着更多的信息,详情见图 4.1。
图 4.1 邻居个数不足5个的结点的占比
-
同构邻居和异构邻居均有一些收益,但是同时加入它们却没有进一步的提升。 可能的原因有:一是两种类型的邻居包含的信息有重叠,二是Graph Context Feature的方式不利于信息的抽取。
对于No Aggregator
可以看到,除了同构邻居q2q & i2i,加入其它邻居收益均为负。可能的原因仍然与上述的数据稀疏有关,q2i和i2q有大量邻居不足5个,为了保持维度上的对齐,在代码里这部分被置为了0,导致经过特征拼接后,Query和Item的Embedding中包含了大量0值(始终为0),而这非常不利于深度模型的训练。
▐ Graph Context Sequence
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表 4.3 Total AUC
采用Graph Context Sequence这种将邻居信息作为单独的序列与待排序的Query做Target Attention的方式,总体AUC见表 4.3。我们可以有如下几个发现:
对于GCN
相比Graph Context Feature的方式,有两个方面的提升:
总体AUC均有所上涨。相比Base_20的最高提升由之前的千分之1.5到现在的千分之2.5。
同时加入同构邻居和异构邻居能够带来进一步的提升。可能的原因是将邻居信息作为单独的序列,相比特征拼接的方式,在用Target Query做兴趣抽取时,能够最大限度地保留Graph Context的信息。至于特征交叉可以交给末层的MLP来做。
同构邻居q2q & i2i相比异构邻居q2i & i2q效果明显一点。原因同上。
对于No Aggregator:当加入4个邻居序列后,模型的AUC有很明显的下降。可能的原因是序列太长(100)加上参数变多(4组参数),模型可能难以收敛了。表 4.4是A组结果中GCN和No Aggregator下i2i邻居序列前4个位置的Attention曲线对比(其他位置情况类似),可以看到,No Aggregator确实没有收敛。
GCN |
No Aggregator |
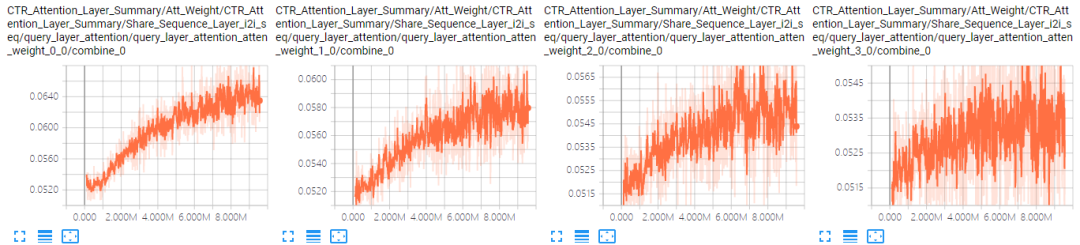
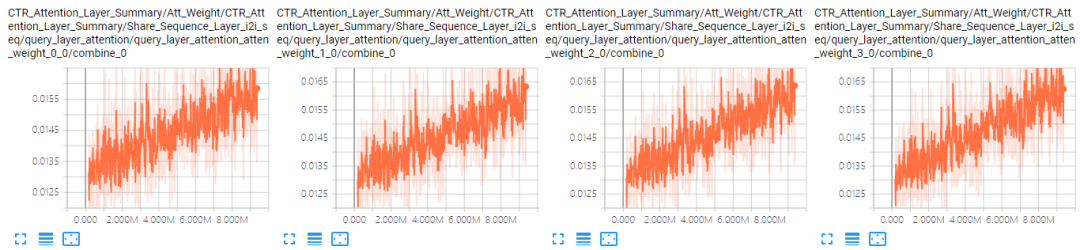
表 4.4 i2i邻居序列Attention曲线对比
|
|
|
||
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表 4.5 Total AUC
纵向对比,总体上AUC相比GCN大降,不符合预期,至少应该不比GCN差。可能的原因是模型变复杂以后,仅用7天的数据训练已经难以收敛了。表 4.6是A组结果中GCN和+neig & seq attenall最好的结果下i2i邻居序列前4个位置的Attention曲线对比,可以看到,同样存在着没有收敛的问题。
横向对比,Sequence Attention有非常微小的收益,并且当序列数量越多时越明显,符合预期。
对比GCN或者+neig & seq attenall与Base模型的Attention值还能发现,尽管整体上邻居序列也是前几个位置Attention值比较大,后几个位置的Attention值比较小,但是它们之间的Gap(0.017)相对Base模型(0.12)并不明显。可能的原因是邻居序列中没有使用时间特征。
GCN |
Attention |
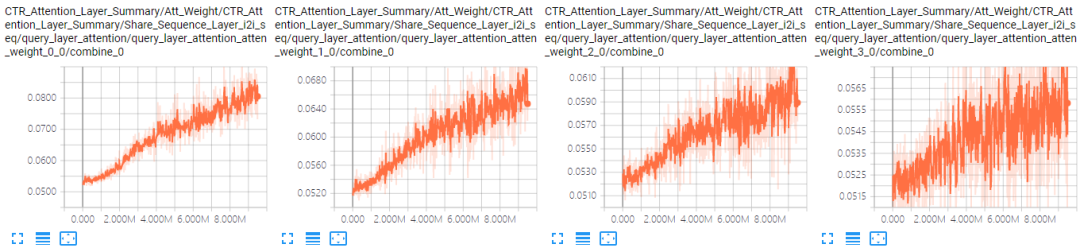
表 4.6 i2i邻居序列Attention曲线对比
为了验证Neighbor Attention和Sequence Attention的有效性,我们可以进一步观察模型学习到的Attention的值。Neighbor Attention如表 4.7所示,Sequence Attention如表 4.8所示。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表 4.7 Neighbor Attention
在组织邻居结点时,位置1-N按照共现频数从高到低排列。从表 4.7可以看到,整体上邻居的注意力分布确实符合这一趋势。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表 4.8 Sequence Attention
一方面,Query和Item Sequence作为原始序列,所能提供的信息最多,相对邻居序列更重要。另一方面,从之前的结果可以看到,不同的邻居序列的重要性也有差异。表 4.8的结果与预期基本一致。
问题A
线上排序模型使用的是14+天的训练数据。在之前的实验中当模型变得复杂以后,仅用7天的训练数据模型已经难以收敛了。因此在之后的实验中将训练数据补到了10天(20210701-20210710)。
问题B
模型对邻居序列学习到的Attention值之间差异不大,因此在样本中为邻居结点加上了中心结点的时间特征,相当于引入了时间越近越重要的先验知识引导模型学习。
▐ 模型侧
问题A:在邻居聚合(Attention)时使用了多套不同的参数,参数量随邻居序列的数量的增加而增长,之前的实验中模型已经难以收敛了,后续加入更多高阶邻居后问题会更加突出。为此通过Node-Type-Specific Transformation和Edge-Type-Specific Attention建模图的异构性并共享相关参数降低参数量。
问题B:之前的实验中,对于每种邻居序列都与Target Query做Attention,计算量随邻居序列的数量的增加而增长,尽管这一步是并行的其计算量开销仍然不可忽略。为此加入了融合不同类型邻居信息的操作,以及融合邻居和自身信息的操作(除中心结点),最后分别为Query和Item序列得到一个融合了异构高阶信息的Graph Context序列。

图 5.1 模型结构
模型的整体结构如图 5.1所示。GNN部分作为排序模型的一个模块,为Query和Item Sequence分别学习一个Graph Context Sequence作为补充信息。其中比较关键的是:Node-Type-Specific Transformation和Transformer-Like Attention(In-Neighborhood Attention,Inter-Neighborhood Attention,Inter-Sequence Attention)。下面以Query类型的结点为例具体介绍这几种操作。
5.2.1 Node-Type-Specific Transformation
不同类型的结点的特征维度和特征空间都存在差异,通过特定于结点类型的特征变换操作,一方面可以将特征维度对齐,另一方面尽可能拉近特征空间,便于后续不同类型的结点之间的特征融合(尤其是加法融合)。详情见公式(1),其中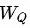
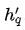
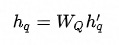
公式 (1)
Hierarchical Heterogeneous Transformer-Like Attention
下拉排序模型中序列与Target Query之间用的是Transformer中点积的方式计算Attention。GAT(图注意力神经网络)中用的是一个带LReLU的隐层计算Attention,在计算复杂度上比点积高一些。此外,考虑到计算方式的一致性,在GNN部分使用了Transformer的方式,并根据图的异构性做了一些修改。共计有4个层次的Attention。
In-Neighborhood Attention
邻域内同种类型的邻居的重要性有差异,这从邻居共现频数分布也能看出(本次实验采用的是Top N采样,差异可能不如随机采样明显)。为此在聚合同种类型的邻居时使用Attention机制。中心结点是Q,邻居结点是K和V,由于已经经过了Node-Type-Specific Transformation,这里不再对Q,K和V做特征变换。此外,考虑到边的类型对相似性的影响,这里的点积是特定于边的类型的双线性点积。详情见公式(2)-(5),其中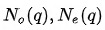
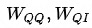
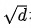
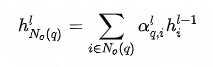
公式 (2)
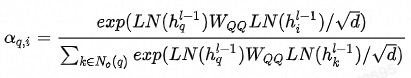
公式 (3)
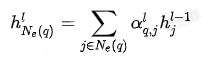
公式 (4)
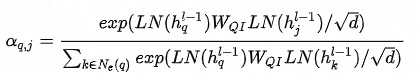
公式(5)
Inter-neighborhood Attention
除了邻域内同种类型的邻居的重要性有差异,邻域间不同类型的邻居的重要性也有差异,这从之前的加入不同类型邻居序列的实验结果也能看出。为此在融合不同类型的邻居时也使用Attention机制。此外,考虑到当存在异构邻居时,Attention的值更容易被中心结点自身所主导,在进行特征融合时邻居信息就容易被稀释掉,所以这里中心结点不作为K、V参与Attention的计算。详情见公式(6)-(7)。
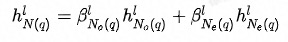
公式(6)
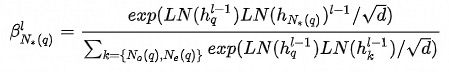
公式(7)
最终的Embedding见公式(8),其中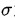
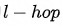
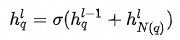
公式(8)
对于GCN,以上公式中的重要性系数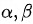
In-Sequence Attention:这一部分与下拉模型保持一致,使用Transformer抽取序列中与Target Query相关的用户偏好。
Inter-sequence attention:这里延续了快速尝试部分的Sequence Attention模块,在新的训练样本上进一步通过实验探究其有效性。
Sequence Attention相比直接concat的一个缺点是,不能经过MLP层与Prefix、User Profile等特征进行充分的特征交叉。
在快速尝试的实验的基础上,扩大了样本规模,新增了样本特征,并针对性地改进了模型。在这一部分,首先会验证GCN下是否还有类似的结论,接着验证改进后模型的总体效果如何,然后验证加宽邻居是否会带来收益,最后验证加深邻居是否会带来收益。总体上,之前的改进是有效的,在数据规模变大后,相比之前千分之2.5的提升,AUC不仅没有下降反而进一步提升至千分之4.1。
▐ GCN下是否还有类似结论
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表 6.1 Total AUC
HGCN与GCN唯一的区别是以Mean的方式融合了不同类型的邻居,总体AUC见表 6.1。可以发现,以下几个结论仍然保持不变:
加长序列仍然是有效的,并且效果变得更加明显(千分之2.5)。
加入各种邻居序列都能带来收益,并且同构邻居收益最大(千分之3.8)。
不过我们也能发现,当同时加入所有邻居,模型的效果却下降了。这可能是由于Mean的融合方式引起的,实际上不同的邻居重要性是有差异的。
▐ 改进后模型总体效果如何
首先,为邻居结点加上时间特征后,前后位置的Attention值的Gap由之前的0.017扩大到了0.11,说明时间特征可以更好地引导Attention的学习。
HGCN |
Attention |
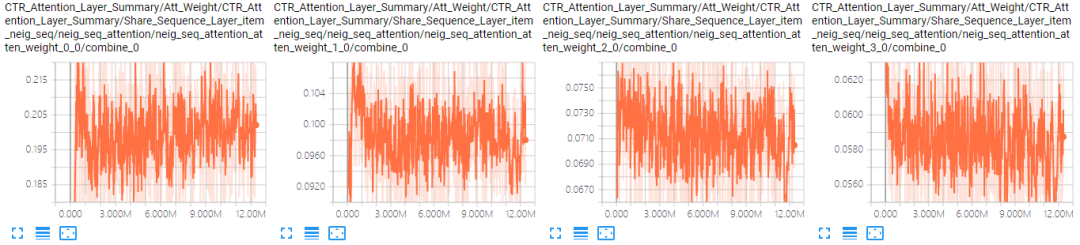

表 4.6 Item neighbor Sequence Attention曲线对比
|
|
|
||
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表 6.2 Total AUC
那么,相比之前加入Attention后效果大降,改进后Attention模型的效果如何呢?总体AUC见表 6.2所示。我们可以有以下几个发现:
纵向对比,相比之前加入Attention后效果大降,现在总体上相比HGCN均有微小提升,这说明之前的改进是有效的。
加入In-neighd attention后有微小提升,说明Top N邻居的重要性差异并不明显。
加入 Inter-neighd attention有进一步提升,并改善了HGCN加入所有邻居后效果下降的问题,说明不同类型的邻居的重要性确实有差异。
加入Inter-seq attention后效果仍然持平,说明对Sequence Embedding的融合必要性不大。
▐ 加宽邻居是否会带来收益
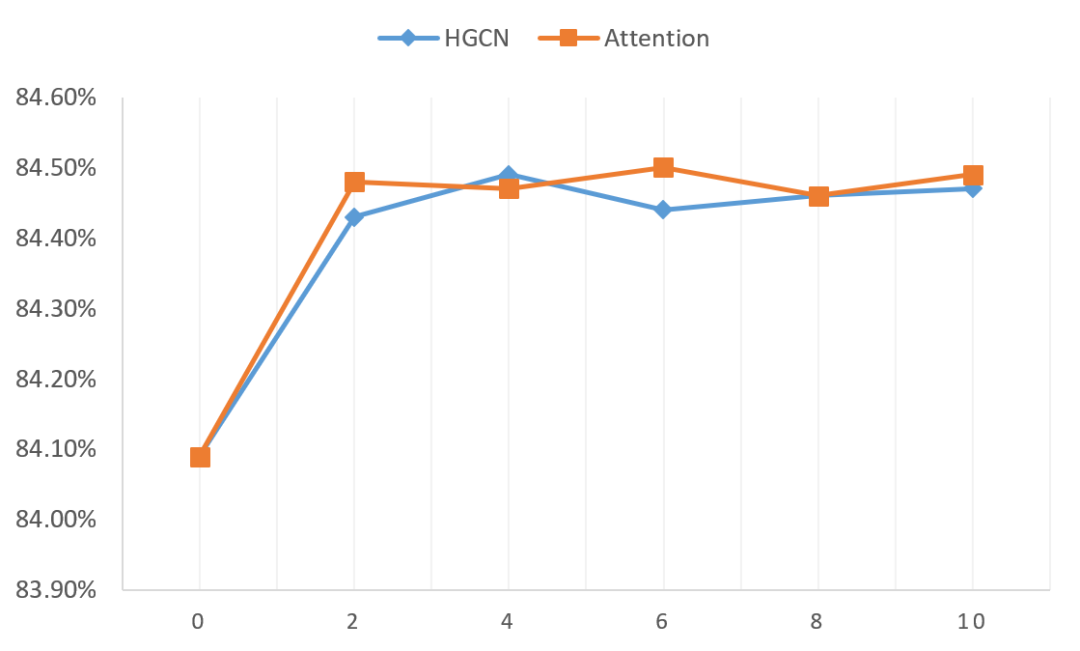
图 6.1 AUC随邻居宽度的变化趋势
加宽邻居是一种常见的操作,更多的邻居意味着更多信息(也可能引入更多噪声),这里通过实验来验证加宽邻居的有效性,AUC随邻居宽度的变化趋势如图 6.1所示。这里对HGCN和Attention都+q2q & i2i & q2i & i2q,其中Attention为+In-neighd attention & Inter-neighd attention。我们可以有如下几个发现:
2-6个邻居基本已经足够了。
Attention整体上优于HGCN,但是优势并不突出。
以上两点可能都是由Top N的采样方式引起的,前Top N个邻居的重要性差异不大,并且所提供的的信息可能也是重叠的。
▐ 加深邻居是否会带来收益
Base_50 |
84.36 |
|
Base_20 |
84.09 |
|
Model |
2 hop size=0 |
2 hop size=3 |
HGCN |
84.39 |
84.45 |
Attention |
84.40 |
84.47 |
表 6.3 Total AUC
加深邻居也是一种常见的操作,更深的邻居可能蕴含高阶的信息。这里考虑到实现方式的限制,只验证了2阶邻居相对1阶邻居是否存在收益,其中1 hop size=6,2 hop size=3。事实上,在GNN的相关研究中,2-3阶的邻居基本已经足够了,引入太高阶的邻居反而有副作用(源于图的直径一般都不大),总体AUC见表 6.3所示。此外,这里只使用了邻居结点的ID特征和时间特征。我们可以有以下几个发现:
2 hop邻居确实能够提供更多信息,其AUC有较明显的提升。
即使只使用1阶邻居,只使用ID特征,只使用HGCN,也能够达到比Base_50略好的效果。也就是说我们可以使用更少的数据,而且不引入额外的模型参数,就能够达到Base_50的效果。
Attention的效果和HGCN相比仍然相差不大。
至此,基于以上的实验结果可以回答开篇提到的三个问题,分析引入邻居信息并用GNN建模是否起到了作用。
▐ 问题1:加长序列无法作用于历史行为稀疏的不活跃用户
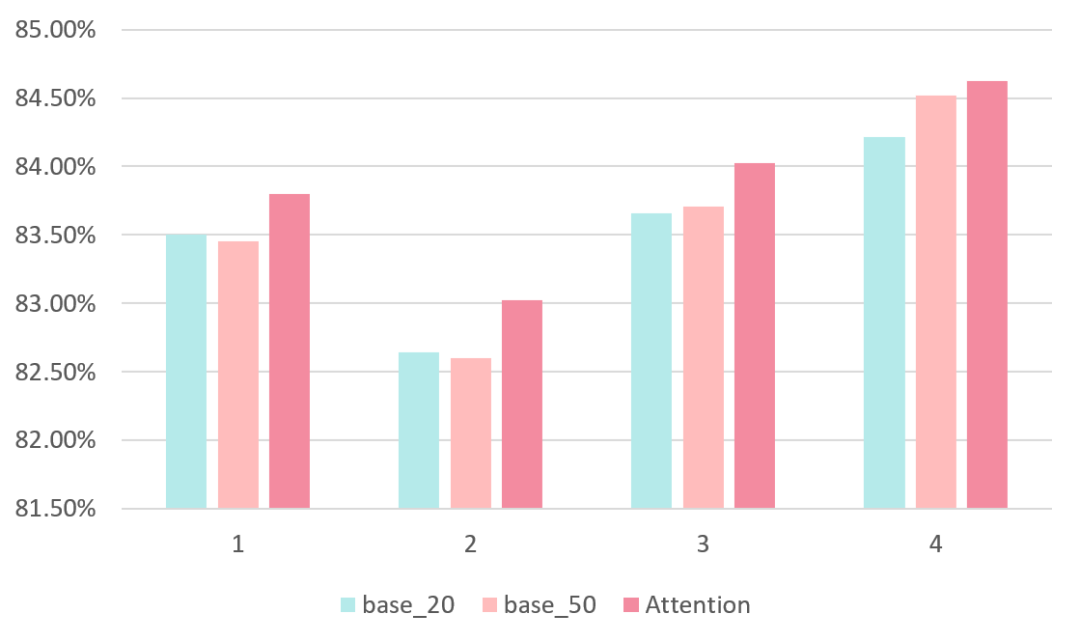
图 7.1 在不同活跃度用户上的AUC(20210711)
GNN对不活跃用户有明显效果。模型在不同活跃度用户上的AUC对比见图 7.1所示,可以有以下几点发现:
base_50在低活用户上效果与base_20几乎持平,但是GNN在低活用户上效果却有显著提升。
即使在base_50表现优异的高活用户上,GNN在只使用长20的序列的基础上,效果也比base_50略好。
▐ 问题2:加长序列对曝光次数较少的长尾Query的效果较弱
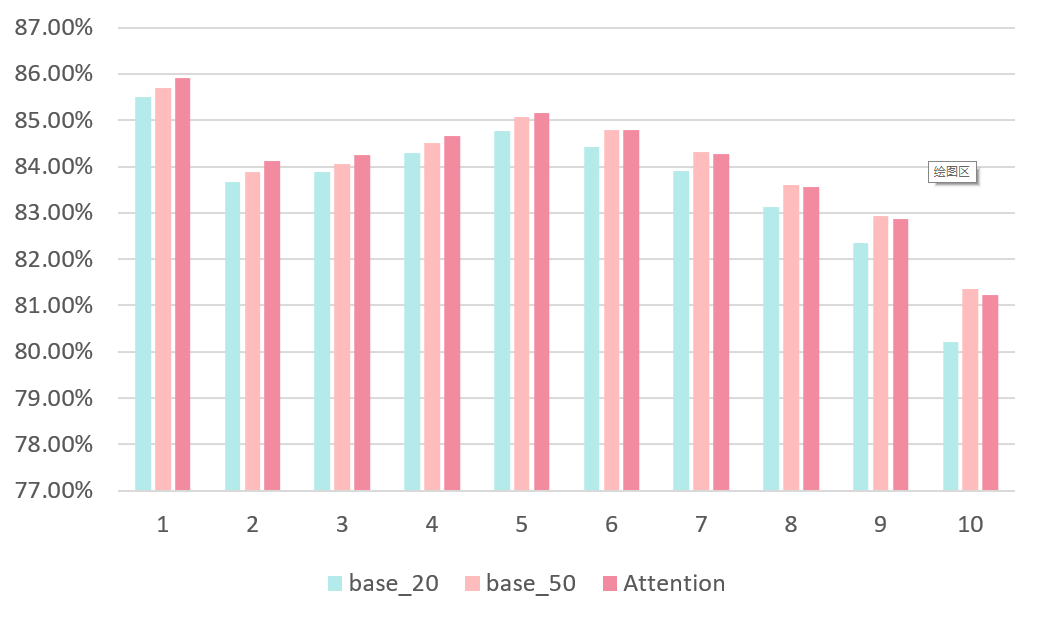
图 7.2 在不同PV的Query上的AUC(20210711)
GNN对长尾Query也有明显效果。模型在不同PV的Query上的AUC见图 7.2所示,可以发现在长尾Query上GNN相对Base_20和Base_50均有所提升,在Base_50表现优异的高频Query上GNN也能够保持持平。
▐ 问题3:加长序列带来的收益与巨大的存储消耗之比不高
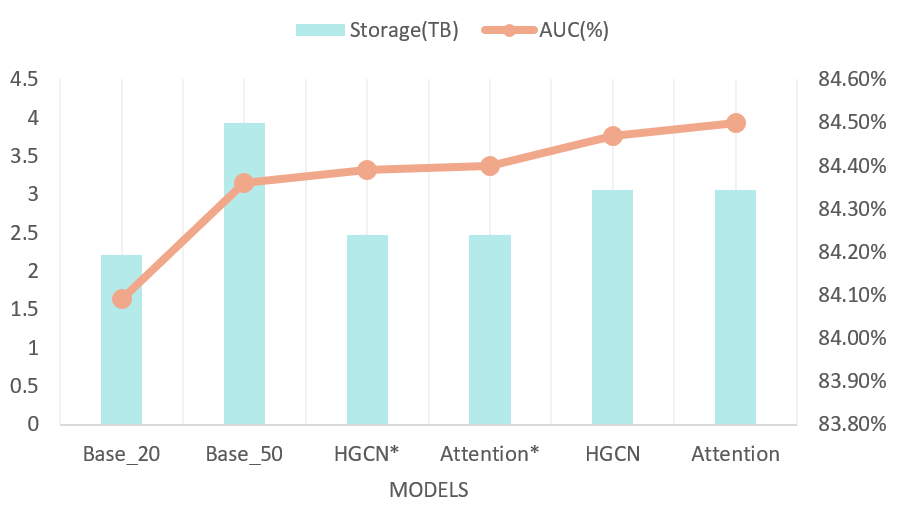
图 7.3 存储消耗与AUC对比
本次实习工作针对下拉排序模型存在的三个问题,引入邻居信息并用GNN建模取得了一定的效果,也为如何在序列上进一步提效提供了另一个角度。相比加长序列,GNN可以显著提升模型在不活跃用户和长尾Query上的效果,并且可以用更少的存储量取得更高的总体收益。同时也能看到仍然存在着一些也许可以改进的地方:
Top N采样方式是否合理。考虑到采样带来的消耗,基于数据的长尾分布,本次实验中采用了Top N的采样方法进行简化近似。但是Top N采样可能会导致采样到的N个邻居区分度不大,包含的信息重合,这可能是Attention无法发挥优势的原因,以及加宽邻居存在严重的边际效应的原因。同时,如果未来部署到线上,面对线上的数据分布,Top N采样可能会限制模型的泛化能力。
给Target Query加上邻居信息。本次实验中只引入了序列中Query和Item的邻居信息,由于Query之间共享Embedding可以间接地作用于Target Query。后续也可以给Target Query也加上邻居信息,以更直接的方式促进对长尾Query的学习。
用Prefix Attention代替Neighbor Attention。对于邻居信息我们需要的同样只是与Target Query相关的部分。本次实验没有用Target Attention是考虑到计算量的问题,而Prefix Attention则不存在这个问题,并且Prefix在大多数情况下足以表明用户当前的意图。后续可以实验对比下序列建模中Target Attention和Prefix Attention的效果,然后再决定邻居聚合中是否使用Prefix Attention。
本次暑期实习收获很多,经历了一个完整的发现问题分析问题到解决问题的过程。相比之前在学校搞科研接触到的工作,不再是使用现成的玩具数据集,而是自己处理百亿级的数据集;不再是魔改模型后对着结果讲故事,而是针对真实的问题使用合适的技术;模型效果的提升不是意义不大的数字,而是有可能在线上产出实际的商业价值。同时学习了DataWork,AOP,语雀的使用,感受到了先进工具对生产力的提升。未来的计划方面,主要有以下几点:
将现在的工作上线一个简单的版本,看一下是否能够在线上也取得效果。
将现在的工作继续完善,包括更好的采样方法,更优质的邻居数据,Target Query侧加上邻居信息,Prefix Attention代替Neighbor Attention。在这之后将工作整理成论文投一个会议。
系统深入广泛地学习一下推广搜方面的资料。
在实际业务中解决更多问题获得更多成长。
最后,非常感谢谷仁老师,筠荻老师和开锋老师的支持与帮助。
[1] Wu Z, Pan S, Chen F, et al. A comprehensive survey on graph neural networks[J]. IEEE transactions on neural networks and learning systems, 2020.
[2] Wu S, Sun F, Zhang W, et al. Graph neural networks in recommender systems: a survey[J]. arXiv preprint arXiv:2011.02260, 2020.
[3] Wang S, Hu L, Wang Y, et al. Graph learning approaches to recommender systems: A review[J]. arXiv preprint arXiv:2004.11718, 2020.
[4] Kipf T N, Welling M. Semi-supervised classification with graph convolutional networks[J]. arXiv preprint arXiv:1609.02907, 2016.
[5] Veličković P, Cucurull G, Casanova A, et al. Graph attention networks[J]. arXiv preprint arXiv:1710.10903, 2017.
[6] Hamilton W L, Ying R, Leskovec J. Inductive representation learning on large graphs[J]. arXiv preprint arXiv:1706.02216, 2017.
[7] Chen J, Ma T, Xiao C. Fastgcn: fast learning with graph convolutional networks via importance sampling[J]. arXiv preprint arXiv:1801.10247, 2018.
[8] Chiang W L, Liu X, Si S, et al. Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks[J]. arXiv preprint arXiv:1905.07953, 2019.
[9] Schlichtkrull M, Kipf T N, Bloem P, et al. Modeling Relational Data with Graph Convolutional Networks[J]. arXiv preprint arXiv:1703.06103, 2017.
[10] Wang X, Ji H, Shi C, et al. Heterogeneous graph attention network[C]//The World Wide Web Conference. 2019: 2022-2032.
[11] Berg R, Kipf T N, Welling M. Graph convolutional matrix completion[J]. arXiv preprint arXiv:1706.02263, 2017.
[12] Wang X, He X, Wang M, et al. Neural Graph Collaborative Filtering[J]. arXiv e-prints, 2019: arXiv: 1905.08108.
[13] Wang X, He X, Cao Y, et al. KGAT: Knowledge Graph Attention Network for Recommendation[J]. arXiv e-prints, 2019: arXiv: 1905.07854.
[14] Zhang C, Song D, Huang C, et al. Heterogeneous graph neural network[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019: 793-803.
[15] Hu Z, Dong Y, Wang K, et al. Heterogeneous Graph Transformer[J]. arXiv preprint arXiv:2003.01332, 2020.
[16] Lv Q, Ding M, Liu Q, et al. Are we really making much progress? Revisiting, benchmarking, and refining heterogeneous graph neural networks[J]. 2021.
[17] Ying R, He R, Chen K, et al. Graph Convolutional Neural Networks for Web-Scale Recommender Systems[J]. arXiv e-prints, 2018: arXiv: 1806.01973.
[18] Fan S, Zhu J, Han X, et al. Metapath-guided Heterogeneous Graph Neural Network for Intent Recommendation[J]. 2019.
[19] Niu X, Li B, Li C, et al. A Dual Heterogeneous Graph Attention Network to Improve Long-Tail Performance for Shop Search in E-Commerce[J].
[20] Chen C, Ma W, Zhang M, et al. Graph Heterogeneous Multi-Relational Recommendation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(5): 3958-3966.
[21] Vaswani A, Shazeer N, Parmar N, et al. Attention Is All You Need[J]. arXiv preprint arXiv:1706.03762, 2017.
我们来自淘宝搜索算法团队,负责淘宝App搜索用户增长和搜索导购、商品排序,负责业务包括底纹、下拉、相关搜索等亿级别Query推荐场景,技术包括召回、海选、精排、重排序等,团队优势有:
业务空间大、基础设施完善:场景海量反馈,在工程团队的支持下,算法工程师可以轻松上线百G模型,分钟级更新,更加注重算法本身。
队氛围好、研究与落地深度结合:实习期间会考虑同学成长,避免接触复杂的业务问题,由资深师兄根据同学优势与兴趣定义好业务问题,辅导研究,最终实习工作以论文呈现,给每位同学都有充分的成长空间;团队在SIGIR、KDD、AAAI等会议有稳定产出。
人才需求:有机器学习、深度学习有一定理解,有LTR或NLP相关业务经验,如果不确定自己能力能否匹配或有任何问题,可以先非正式的找我聊下,如果合适再进入正式面试流程。联系微信: xiaofei0885 或发邮件到我邮箱guren.xf#alibaba-inc.com(发送邮件时,请把#替换成@)





