
第29届国际计算机学会信息与知识管理大会(The 29th ACM International Conference on Information and Knowledge Management, CIKM 2020)将于2020年10月19日-10月23日在线上召开。CIKM是CCF推荐的B类国际学术会议,是信息检索和数据挖掘领域顶级学术会议之一。本届CIKM会议共收到投稿920篇,其中录用论文193篇,录取率约为21%。
论文题目:Diversifying Search Results using Self-Attention Network(长文)
作者者:秦绪博(人大博士生),窦志成,文继荣
论文概述:搜索结果多样化的目标是使得检索得到的结果能够尽量覆盖用户提出问题的所有子话题。已有的多样化排序方法通常基于贪心选择(Greedy Selection)过程,独立地将每一个候选文档与已选中的文档序列进行比较,选择每一个排序位置的最佳文档,生成最后的文档排序。而相关研究证明由于各候选文档的边际信息收益并非彼此独立,贪心选择得到的各个局部最优解将难以导向全局最佳排序。本文介绍了一种基于自注意力网络(Self-Attention Network)的方法,可以同步地衡量全体候选文档间的关系,以及候选文档对不同用户意图的覆盖程度,有效地克服原有方法受限于贪心选择过程的局限性,并在TRECWebTrack09-12数据集上获得更好的性能。

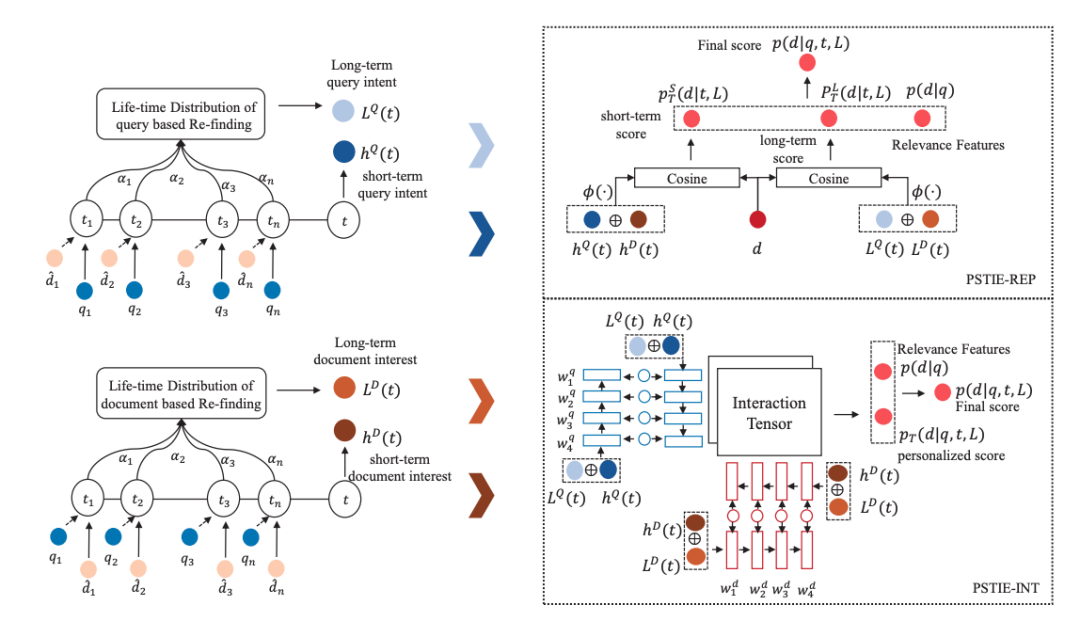
论文题目:PSTIE: Time Information Enhanced Personalized Search(长文)
作 者:马正一(人大硕士生),窦志成,边关月,文继荣
论文概述:基于深度学习的个性化搜索模型通过序列神经网络(例如RNN)对用户搜索历史进行序列建模,归纳出用户的兴趣表示,取得了当前最佳的效果。但是,这一类模型忽略了用户搜索行为之间细粒度的时间信息,而只关注了搜索行为之间的相对顺序。实际上,用户每次查询之间的时间间隔可以帮助模型更加准确地对用户查询意图与文档兴趣的演化进行建模。同时,用户历史查询与当前查询之间的时间间隔可以直接帮助模型计算用户的重查找(re-finding)行为概率。基于此,本文提出了一个时间信息增强的个性化搜索模型。我们设计了两种时间感知的LSTM结构在连续时间空间中对用户兴趣进行建模,同时直接将时间信息利用在计算用户重查找概率中,计算出了更加准确的用户长短期兴趣表示。我们提出了两种将用户兴趣表示用于个性化排序的策略,并在两个真实数据集上取得了更好的效果。
论文题目:Learning to Match Jobs with Resumes from Sparse Interaction Data using Multi-View Co-Teaching Network(长文)
作 者:卞书青(人大博士生),陈旭,赵鑫,周昆,侯宇蓬,宋洋,文继荣
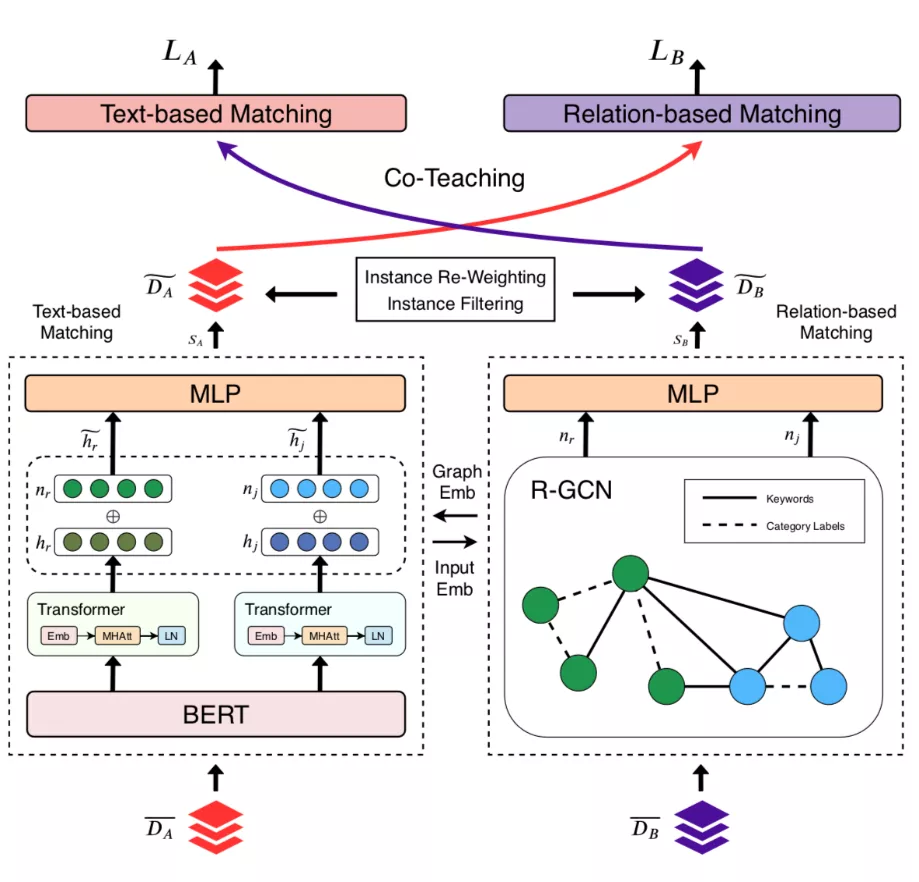
论文概述:随着在线招聘规模的不断增长,求职领域下的人岗匹配已经成为最重要的任务。人岗匹配任务通常可以看作文本匹配问题。当监督数据足够多时,模型的学习效果是有用的。但是在线招聘平台上,职位和简历的交互数据稀疏且带有噪声,这会影响求职简历匹配算法的性能。为了缓解这些问题,本文提出了一种多视图协同教学网络用来解决人岗匹配中的数据稀疏和噪声问题,匹配网络包含两个主要模块,即基于文本的匹配模型和基于关系的匹配模型。这两个部分在两个不同的视图中捕获了语义信息并且相互补充。为解决数据稀疏和噪声数据带来的挑战,我们设计了两种特定策略。首先,两个模块共享学习的参数和表示,以增强每个模块的初始的表示。更重要的,我们采用了一种协同教学的机制来减少噪声对训练数据的影响。核心思想是让这两个模块通过选择更可靠的训练实例来互相帮助。这两种策略分别关注于表示增强和数据增强。与基于纯文本的匹配模型相比,所提出的方法能够从有限的甚至稀疏的交互数据中学习更好的表示,对训练数据中的噪声具有一定的抵抗能力。实验结果表明,我们的模型均优于现有的方法。
论文题目:Knowledge-Enhanced Personalized Review Generation with Capsule Graph Neural Network(长文)
作 者:李军毅(人大博士生),李思晴,赵鑫,何高乐,魏志成,袁晶,文继荣
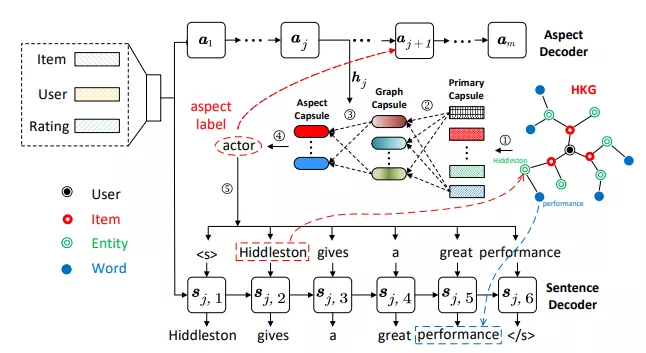
论文概述:个性化评论生成(PRG)任务旨在自动生成反映用户偏好的评论文本。以前的大多数研究都没有明确建模物品的事实描述,因此倾向于生成无信息的内容。而且,这些研究主要集中在单词层面的生成,无法准确反映出用户在多个主题上的抽象偏好。针对上述问题,我们提出了一种基于胶囊图神经网络(Caps-GNN)的知识增强个性化评论生成模型。我们首先构造一个异构知识图谱(HKG),充分利用丰富的物品属性。我们采用Caps-GNN学习到HKG图胶囊,用于编码HKG的隐含特征。我们的生成过程包含两个主要步骤,即主题序列生成和句子生成。首先,基于图胶囊,我们自适应地学习了主题胶囊,以推断主题序列。然后,根据推断的主题标签,我们设计了一种基于图的拷贝机制,通过引入HKG的相关实体或单词来生成句子。本文是第一个将知识图谱用于个性化评论生成任务,引入的KG信息能够增强用户在主题和单词层面上的偏好。实验表明,我们的模型对于个性化评论生成任务具有更好的效果。
论文题目:S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization(长文)
作 者:周昆(人大博士生),王辉(人大硕士生),赵鑫,朱余韬,王思睿,张富铮,王仲远,文继荣
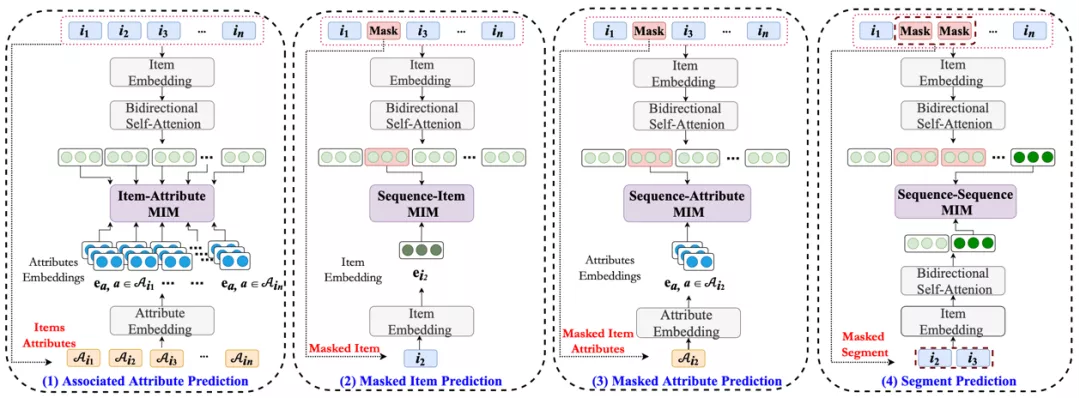
论文概述:近年来,深度学习在序列化推荐领域取得了巨大成功,已有的序列化推荐模型通常依赖于商品预测的损失函数进行参数训练。但是该损失函数会导致数据稀疏和过拟合问题,其忽视了上下文数据与序列数据之间的关联,使得数据的表示学习的并不充分。为解决该问题,本文提出了S3-Rec这一模型,该模型基于自注意力是模型框架,利用四个额外的自监督训练函数来学习属性、商品、序列之间的特殊关系。在这里,本文采用了互信息最大化技术来构造这些自监督函数,以此来统一这些关系。在六个数据集上的充分实验表明本文提出的模型能够取得State-of-the-art的效果,其在数据量受限和其他推荐模型上也能带来较大的提升。
**论文:Learning Better Representations for Neural Information Retrieval with Graph Information” **
(作者:李祥圣,Maarten de Rijke, 刘奕群,毛佳昕,马为之,张敏,马少平)
内容简介:目前的检索模型多数基于文本间的匹配。然而,对于一个搜索会话,用户的行为之间是具有联系的,这样的联系可以用图的方式表示出来。例如用户在会话搜索中修改查询的过程可以知道那些查询之间是相似的,用户点击文档后,可以知道查询与文档之间的关联性。利用这样的两个网络,我们可以构建一个由用户行为组成的图网络。在传统的文本匹配模式上,进一步地引入行为图信息帮助检索模型更好地理解用户搜索意图。检索模型可以利用图信息,对输入的查询进行相似节点查询。同理,对于候选文档也可以利用相似节点查询。通过引入邻接节点信息,丰富当前节点的语义表示。
现有的图模型的工作主要分为两种:网络嵌入式表示方法与图神经网络方法。基于这两种方法,我们提出了两种利用图信息改进检索模型的方法,两种方法的示意图如下所示:


