「工业实践」在内容推荐场,阿里是如何用GNN做召回的?

本系列文章包含每平每屋过去一年在召回、排序和冷启动等模块中的一些探索和实践经验,本文为该专题的第二篇。
第一篇指路:冷启动系统优化与内容潜力预估实践
前言
每平每屋是阿里巴巴旗下家居家装平台,涵盖淘宝每平每屋家居频道、每平每屋设计家、每平每屋App、每平每屋制造业等家居全链路服务,为消费者提供了2D图文、3D样板间、3D虚拟直播、3D短视频、VR全屋漫游等丰富多元的家居内容,逐渐成为年轻一代生活灵感与家居装修的向导之一。
C端业务在淘内主要以每平每屋家居频道进行承接,提供场景化的导购服务。频道内每件单品都不再孤立呈现,而是以场景化内容搭配推荐为主。消费者只需在淘宝搜索“每平每屋”或点击首页猜你喜欢的“每平每屋”内容卡片即可进入频道,通过点击详情页挂载的商品可进行收藏、加购、购买等行为,获得沉浸式购物体验。

目前每平每屋频道内容推荐个性化召回主要分为U-I-I和深度U-I两大类。
U-I-I召回:根据用户属性特征、引流内容或点击的内容,基于内容ID、内容所属的风格与空间、内容挂载的商品和类目,通过i2i、c2i等方式召回相关的内容,具有较高的精度。
深度U-I:根据用户的点击行为,将用户、内容转化为向量,通过向量检索技术召回topk,变“精确匹配”为“模糊查找”,具有较好的多样性和发散性。
因为淘宝首页猜你喜欢引流结构的特点,部分用户对所见即所得以外模块浏览心智较低。每日访问每平每屋频道的用户中,由淘宝首页频道卡片引流进入的零少行为用户占比较高,这使得我们在对用户兴趣建模时面临着严重的用户行为稀疏的问题。而用户的交互行为往往存在一定的流行度偏差,例如,用户点击某个内容受到收藏数、运营活动、展示位置靠前等诸多因素影响,而非个人兴趣偏好驱动,这就造成少数流行内容包含了大多数交互的马太效应,这一点在零少行为用户群体中更为明显。对这样分布特点的数据进行建模时,模型会“偷懒”地倾向于推荐流行内容去拟合,进而弱化了对用户真实意图的挖掘。因此,在优化频道内内容召回时,我们主要考虑了如下问问题,详细的实践介绍将在后面的章节展开。
深度挖掘side info:在用户与内容缺乏交互行为的情况下,基于GNN模型建模高阶关系,并融合side info,如用户点击的内容所挂载的商品、类目、风格、空间等,以建立起更多的关联。
对用户交互行为中的流行度偏差去偏:基于GNN解耦模型挖掘用户泛群体的真实兴趣意图进行召回,以缓解零少行为用户推荐马太效应。
挖掘side info
通过分析线上召回链路发现,深度U-I模型召回的曝光pv、uv占比较低,而占比较高的则为i2i召回。值得注意的是,现有的i2i召回候选集在构建时仅仅考虑了用户点击行为,且主要是在做准。由于没有综合考虑内容侧丰富的side info,在召回结果的发散性上仍有较多的优化空间。频道内每条内容挂载了多个商品锚点,点击商品锚点跳转到商品的详情页。此外,从内容详情页不难发现,除了挂载的多个商品外,内容还包含空间、风格和设计师等信息。概言之,内容关联了商品、内容、设计师等丰富且多维的side info,对于理解内容、优化召回链路提供了帮助。
▐ 基于single-view的图表征学习
 。用户在某个session中对内容
。用户在某个session中对内容
 和内容
和内容
 都产生了点击行为,那么内容
都产生了点击行为,那么内容
 与内容
与内容
 就产生一条边
就产生一条边
 ,权重
,权重
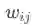 的计算方式为:
的计算方式为:

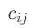 为内容与对在所有session中共现次数。
为内容与对在所有session中共现次数。
模型结构

Graph Sampling
借鉴GraphSAGE[5]思想,针对每个节点,根据权重矩阵采样与之相连的topk节点作为邻域得到子图。用采样得到的子图代替原图作为正样本进行训练,并随机采样指定数量的非邻域节点作为负样本。
Encoder
考虑到节点相关的特征均为ID类属性特征,我们首先将每个属性特征映射为一个向量,接着将各节点对应的属性特征concat起来,通过一层FC,得到节点的初始向量表征。最后,采用两层邻域聚合得到节点向量表征。在邻域聚合阶段,我们考虑了三种聚合方式:均值(Mean)、求和(Sum)和多头注意力机制(GAT)。综合考虑离线实验效果和模型训练效率,最终采用均值聚合方式。
Decoder
以Encoder输出的节点向量表征作为输入,重构每个节点对之间的相关性。
Loss
采用binary cross-entropy的分类损失函数进行模型训练,使得重构的正样本对
高,负样本对
低。
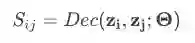
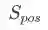

线上召回
线上服务主要根据用户实时和历史点击内容,进行i2i召回。我们发现直接进行向量召回在轻应用频道业务中会存在如下两个问题:
当线上i2i trigger数量较多时,通过内容ID->拿到embedding->再去召回,会带来rt的大幅上涨。若将embedding聚合成单个向量以降低RT,则会丢失信息;
为避免用户历史点击的热门内容主导用户后续的i2i召回,频道内根据用户交互时间进行trigger selection,即行为越近的点击,重要性越高,对应召回的内容越多。而对向量召回进行trigger selection则较为困难。
因此,我们将向量检索的过程搬到离线环节,预先计算好每条内容相关的topk条候选内容,构建i2i侯选池。
在线效果A/B Test
在推荐效率指标上,pctr+0.80%,ipv_pctr+1.50%,pctrcvr+2.31%。此外,我们观察了推荐在风格和空间两个属性上的多样性指标。单次请求中,曝光不同空间内容数-0.62%,曝光不同风格内容数-0.04%,点击不同空间内容数+0.08%,点击不同风格内容数+0.23%。从单次曝光上看,空间和风格多样性的性的指标上并没有取得预期的效果,猜测为内容侧包含丰富的side info且这些信息往往具有不同的分布,以ID特征的方式融合进节点表征,一方面会丢失信息,另一方面会存在归纳偏置,即容易被某个领域信息主导节点表征的学习。
▐ 基于multi-view的图表征学习
在第二阶段,我们尝试了基于多任务多视图的图表征学习——M2GRL[1]。该模型将大规模异构网络表征学习拆解为Intra-view task和inter-view task两类任务,前者用于学习同构图内节点的表征,后者则用于学习不同域节点之间的关系。并以多任务学习缓解不同域信息归纳偏置的问题。
和第一阶段一致,我们采用相同的方式根据用户近15天在每平每屋频道内行为数据构建多个intra-view task的同构网络。inter-view task的网络则根据内容与side info之间的关联关系构建。
模型结构

首先,除了content-content同构图之外,针对每个view单独构建一个同构网络,如category-category、item-item等。每一个同构网络对应一个Intra-view task,采用同构图表征学习方法得到节点向量表征。接着,每一个域信息融合到内容向量表征对应一个inter-view task,采用空间对齐的思想完成信息融合。最终,使用同方差不确定性来动态调整多任务学习在训练时候的权重。
线上召回
同样的,这一环节我们离线计算好每条内容相关的topk条候选内容,构建i2i候选池。
在线效果A/B Test
对比2.1技术方案,在推荐效率指标上pctr+0.49%,ipv_pctr+0.22%,pctcvr+0.72%。在多样性指标上,单次请求中,曝光不同空间内容数-0.06%,曝光不同风格内容数+0.14%,点击不同空间内容数+0.83%,点击不同风格内容数+1.24%。此外,单链路曝光和点击的内容篇数分别提升+44.4%和+51.41%。说明M2GRL一定程度上可以缓解归纳偏置,避免部分view的特征主导节点表征的学习。
流行度去偏
通过深度挖掘side info构建更多的关联后,我们发现线上召回的内容依然较为集中。这是因为样本分布不均匀,热门样本数量多,导致训练模型偏向于推荐流行内容,进一步加剧线上的马太效应。因此,我们期望从流行度去偏的角度,挖掘用户真实意图,提高零少行为用户召回结果的准确性和多样性。
现有的解决流行度去偏问题方法包括:
根据商品的流行度给样本设计权重
利用一小部分无偏数据辅助学习
然而,这两种方法并未将兴趣和流行度这两种因素解耦,且忽视了用户受流行度影响的差异性以及内容流行度随时间变化的迁移性,在鲁棒性和可解释性上均存在一定的局限性。借鉴文章[3]的DICE(Disentangling Interest and Conformity with Causal Embedding)解耦框架,我们将驱动用户行为的兴趣和流行度这两类因素解耦成两套向量表征,学习用户真正的兴趣向量进行内容召回。
▐ DICE框架简介
DICE是2021年发表在WWW Disentangling Interest and Conformity with Causal Embedding 一文中提出的应用于推荐业务中的基于因果推断逻辑的向量解耦框架。其特点是不同影响因素用各自特定的数据集训练,从而从结构上将用户行为背后的兴趣和流行度驱动因素表征学习解耦,且任意表征学习模型都可以集成。
首先,解耦单一的user和item向量表征为interest和conformity两段向量。其中,interest部分为仅与兴趣因素相关的向量,conformity部分为仅与流行度因素相关的向量。相比较于仅从item角度增加一项标量的方法,这样能够体现用户的特异性。形式化为:

其中,
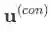
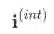




其次,利用因果推断产生的碰撞效将点击行为建模的等式扩展为不等式从而获得特定原因的数据,并以此作为监督信号来引导两部分向量表征的解耦。具体地,根据正负样本的流行度拆分数据集为
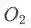
:负样本的流行程度低于正样本,那么猜测用户群体更多地是受流行度因素驱动产生的点击行为。
:负样本的流行程度高于正样本,那么猜测用户群体更多地是受兴趣因素驱动产生的点击行为。
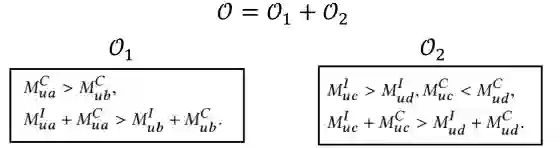
其中,
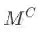
接着,采用多任务学习以综合和平衡兴趣和流行度两个点击行为驱动因素。如下图所示,拆解解耦表征学习为Conformity Modeling、Interest Modeling、Estimating Clicks和Discrepancy Task四个任务。

假设函数

Conformity Modeling:基于
和
数据集建模流行度因素驱动分。
Interest Modeling:基于
数据集建模兴趣因素驱动分。
Estimating Clicks:基于
和
数据集建模点击行为。
Discrepancy Task:利用一阶范数约束interest和conformity两部分向量要尽可能不相关。




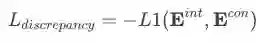
最后,通过不同的参数将四种task结合起来。

▐ 基于DICE解耦框架的图表征学习
针对零少行为用户,我们根据用户人口属性特征和进入频道的引流信息将用户分为不同的群体
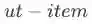


其中,


最终,以近15天用户点击日志,计算权重矩阵。为了减少用户群体行为中噪声点击的影响,我们以设定相关性阈值仅保留高于该阈值的权重值其它置为0的方式,构建出一张带权的
此外,与之前工作类似,我们也将内容挂载的商品、类目、风格、空间等side info作为节点的属性特征,融合进图的节点表征过程中,并引入item-item相似度网络,进一步丰富网络数据。
模型结构
如下图所示,我们基于两个二部图的GNN模型分别学习user和item的interest和conformity两部分向量,并集成到DICE框架中,将用户交互行为产生的驱动因素解耦为兴趣和流行度两个部分。
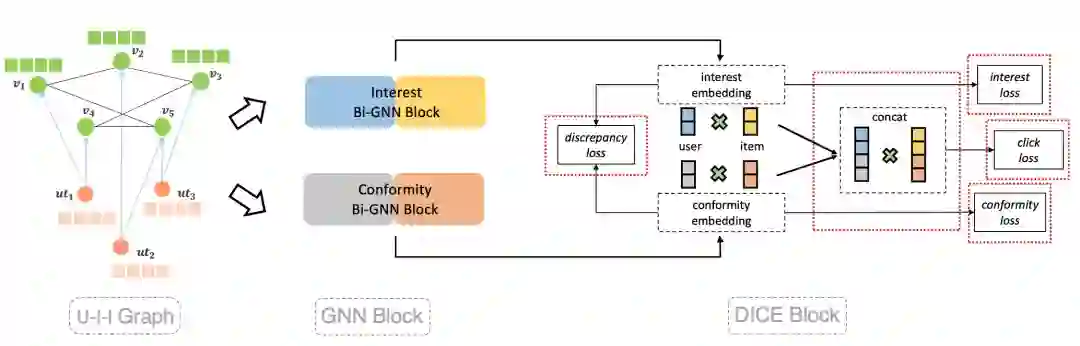
与原文的排序模型不同,仅仅使用曝光未点击作为召回模型的负样本是不够的,有时甚至会导致负向的效果。这是因为召回模型面对的整个内容侯选池,那么若以线上推荐链路筛选出的用户“最喜欢”内容中的负样本训练召回模型,是无法很好地对全量内容池做出判别的。随机负采样可以让负样本尽量符合线上召回环节的样本真实分布。然而随机采样得到的样本,很多情况下和正样本差异较大,这就导致模型无法学到有用的细粒度信息。因此,我们还挖掘了hard negative增强样本。
可视化示例
随机挑选线上3000条内容可视化对应的interest和conformity向量表征。按曝光pv由低到高,将内容分为4个等级,并用不同的颜色标记出。其中interest向量对应popular 1~4等级,conformity向量对应popular 6~9等级, 结果如下图所示:

从图中可以发现,两种解耦表征之间存在一条界限,并且左边conformity向量表征按曝光pv的不同,也有一定的分层聚类效果。
线上召回
线上服务主要根据用户属性特征和引流信息,查询的得到interest向量进行u2i召回。
在线效果A/B Test
在推荐效率指标上pctr+0.75%,ipv_pctr+0.48%,pctcvr+1.24%。在多样性指标上,单次请求中,曝光不同空间内容数+0.04%,曝光不同风格内容数+0.15%,点击不同空间内容数+0.68%,点击不同风格内容数+0.72%。从中可以发现通过向量解耦解决流行度偏差问题,挖掘用户真实意图,对于效率指标和多样性指标的提升均有一定的帮助。
总结与展望
大部分淘内轻应用频道新用户占比高,用户行为稀疏且内容分发头部曝光现象严重。保证召回结果准确性的同时提高发散性是推荐系统优化的重点之一,本文主要介绍了基于GNN模型在每平每屋轻应用频道内容召回上的实践。
基于链接的传递性建模高阶关系,同时融合multi-view side info以建立起更多的关联,缓解行为数据稀疏性问题。
基于DICE向量解耦框架,对用户交互行为中的流行度偏差去偏,挖掘用户泛群体的真实兴趣意图,以期缓解零少行为用户推荐马太效应。
未来在GNN模型的探索上,我们会考虑优化长尾问题,避免high-degree的节点主导了整个模型的训练,导致low-degree的节点得不到充分的学习,也会尝试将GNN与排序模型结合起来,进一步缓解数据稀疏性问题。此外,除了兴趣与流行度之外,用户交互行为可以是由更多的潜在因素共同驱动,例如风格、款式偏好等。近年来学术界和业内也有不少工作尝试将图像领域的解耦表征模型应用到推荐业务中,让模型能够构建更多的关联,从人的角度学习得到更为鲁棒、更具可解释性的推荐模式,因此细粒度的GNN解耦表征也是我们后续想要持续深挖的一个方向。
参考文献
[1] Wang, Menghan, et al. "M2GRL: A multi-task multi-view graph representation learning framework for web-scale recommender systems." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
[2] Grbovic, Mihajlo, and Haibin Cheng. "Real-time personalization using embeddings for search ranking at airbnb." Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.
[3] Zheng, Yu, et al. "Disentangling user interest and conformity for recommendation with causal embedding." Proceedings of the Web Conference 2021. 2021.
[4] Slides - Disentangling User Interest and Conformity for Recommendation with Causal Embedding
[5] Hamilton, Will, Zhitao Ying, and Jure Leskovec. "Inductive representation learning on large graphs." Advances in neural information processing systems 30 (2017).
团队介绍
淘系技术部-淘宝智能团队
淘宝智能团队是一支数据和算法一体的团队,服务于淘宝、天猫、聚划算、闲鱼和每平每屋等业务线的二十余个业务场景,提供线上零售、内容社区、3D智能设计和端上智能等数据和算法服务。我们通过机器学习、强化学习、数据挖掘、机器视觉、NLP、运筹学、3D算法、搜索和推荐算法,为千万商家寻找商机,为平台运营提供智能化方案,为用户提高使用体验,为设计师提供自动搭配和布局,从而促进平台和生态的供给繁荣和用户增长,不断拓展商业边界。
这是一支快速成长中的学习型团队。在创造业务价值的同时,我们不断输出学术成果,在KDD、ICCV、Management Science等国际会议和杂志上发表数篇学术论文。团队学习氛围浓厚,每年组织上百场技术分享交流,互相学习和启发。真诚邀请海内外相关方向的优秀人才加入我们,在这里成长并贡献才智。
如果您有兴趣可将简历发至leihui.clh@alibaba-inc.com,期待您的加入!




