最全推荐系统Embedding召回算法总结
最近特别忙,工作日几乎没什么时间学习。平时攒了一堆推荐相关的文章,趁周末整体学习了一下。主要是参考了网上的一篇技术文章(迄今为止我看到的比较好的推荐Embedding总结)以及我自己的一些理解。
首先一些概念性的内容要科普下。推荐系统分召回和排序,召回为将每个用户找出他可能喜欢的物品的候选集,排序是对候选集按照用户的喜爱程度进行排序,最终得出给用户推荐的结果。
在推荐系统的召回阶段,需要对每个用户和每个被推荐物品做数学层面的表示,目前比较主流的方法是通过向量,也就是Embedding表示。举个例子,假设傲海和两个物品的Embedding表示法如下:
傲海=[1,32,53,657,863]
物品1=[32,53,46,75,68]
物品2=[2,32,53,657,863]
相比于物品1,傲海的向量距离显然与物品2更小,在推荐系统中就会优先为傲海推荐物品1而不是物品2。这种表示方法就将推荐召回模块抽象成是否可以准确的表示每个人和物品的Embedding,越准确则推荐效果越佳。
那向量召回有哪些模式呢?其实最核心的是I2I和U2I,当然还有一些衍生的比如U2U2I,这里不再赘述。
U2I主要是通过计算人(USER)和物品(ITEM)的距离做召回,就跟我上文提到的傲海和两个物品的向量距离计算一样。U2I对算法的要求是,需要把人和物品的特征同时加入算法进行计算,这样人和物品的向量维度和意义才一致,做人和物品的向量距离计算才有意义。
I2I是不考虑人的因素的,I2I一般应用到以下场景:
“比如一个人喜欢买各种X类型的手机,把所有物品的Embedding,然后找跟X类型手机距离近的物品推荐给这个人即可”。所以I2I算法更多地是考虑如何求物品间的相关性,并表示成Embedding。
我把I2I和U2I的比较流行的算法做了个汇总,如下图:
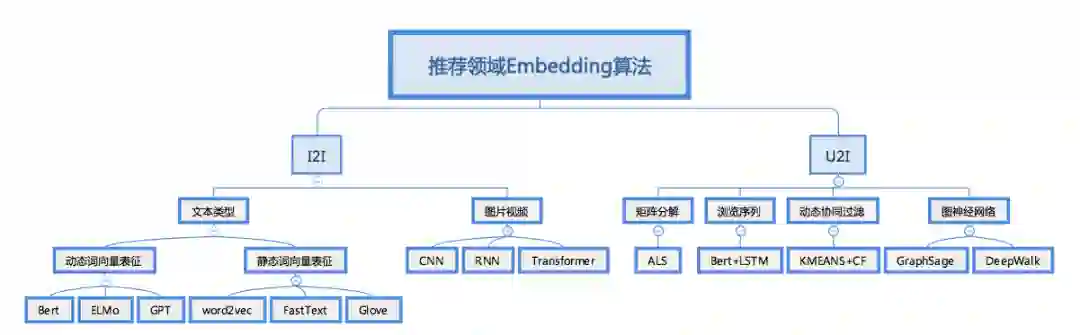
先来讲I2I算法,为什么分文字和图片两个类目呢?因为平时我们看到的新闻大致是这样的:

商品大致是这样的:

待推荐物品都会包含图片和说明文字,需要同时考虑这两部分的Embedding。
图片类型比较简单,一般都是ResNet这些算法的中间向量结果导出作为这个图片的Embedding表示:
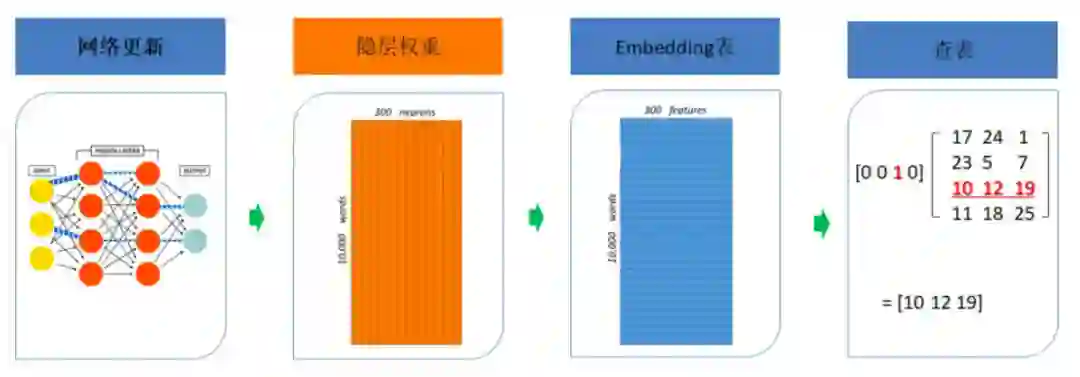
文本类的Embedding可以分为两种,一种是比较传统的word2vector、fasttext、glove这些算法的方案,叫做词向量固定表征类算法,这些算法主要是通过分析词的出现频率来进行Embedding生成,不考虑文本上下文。
而另一种文本Embedding方法,也是目前最流行的方案是动态词表征算法,比如Bert、ELMo、GPT,这类算法会考虑文本上下文。
动态词表征和固定词表征算法的区别可以举个例子说明,比如下面这句话:“小明爱吃苹果,也爱使用苹果手机”。需要对“苹果”这个词做Embedding,固定词表征算法很难区分出吃的苹果和手机苹果品牌,而动态的表征方法是可以的。
ALS
U2I算法可以分为4类,最经典的就是MF矩阵分解算法ALS,
比如在ALS算法输入的是下图这样的人对歌的打分数据,

ALS会根据这样的数据产出两个矩阵,这两个矩阵分别表示每个听众的Embedding和每首歌的Embedding。
基于浏览序列Embedding
另一种相对高级的人的Embedding方案是Bert+LSTM,这类方案叫浏览序列Embedding法。我们可以把每个用户历史的浏览记录作为这个人的属性的表示。
假设一个用户先后浏览过3篇文章,分别是:
“巴特尔掀翻奥尼尔”
“易建联怒砍3分,2篮板”
“孙悦率领湖人勇夺总冠军”
那就可以把这3篇新闻标题用Bert向量化,再将这些向量按照浏览序列输入LSTM,最终就生成这个用户的Embedding表示。
动态协同过滤
接着再介绍一种基于簇群的协同过滤召回方案,一般是KMEANS+CF。CF就是协同过滤法,原理不多说了。这种召回方案一般是先将每个用户按照他的标签做Tag Embedding,比如可以按照年龄、性别、身高做个Embedding。
小明=[29,1,180]
(29岁,1代表男性,身高180)
然后用KMEANS做所有用户的自动聚类,接着针对每个聚类簇内部的用户做相互之间的协同过滤,这样可以保证为相似口味的人推送互相都喜欢的物品。
图神经网络
图神经网络Embedding是目前比较热门的,效果也是相对比较好的一个方案。图神经网络把每个用户有过行为交互物品看作一个点,把具体的行为看作边。如下图所示:
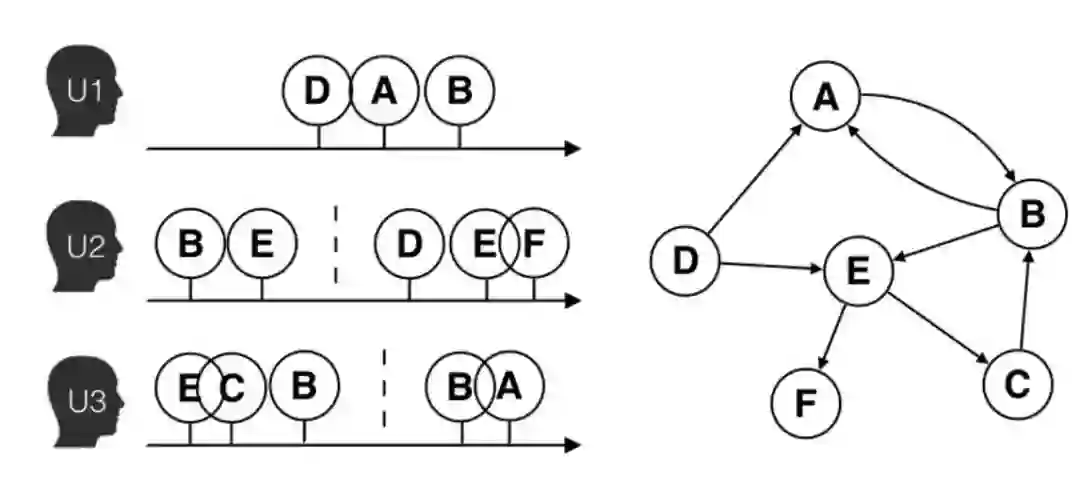
用户1看按照DAB的顺序跟物品交互,用户2按照BE DEF的顺序交互,依此类推,可以构建一个图关系。这个图关系隐藏着用户和物品的属性,可以生成人和物品的Embedding向量。常用的图神经网络算法有GraphSage和DeepWalk。
Embedding向量生成之后,可以用Faiss引擎去方便的计算向量间的距离,从而实现推荐召回。这个方案是目前主流的推荐引擎召回方案。相信后续会有越来越多的算法诞生,我也会持续关注。
参考:https://www.jiqizhixin.com/articles/2020-06-30-11




