【泡泡图灵智库】用于大规模定位的高效描述子学习(ICRA)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Efficient Descriptor Learning for Large Scale Localization
作者:Antonio Loquercio1, Marcin Dymczyk1, Bernhard Zeisl2, Simon Lynen2, Igor Gilitschenski1, Roland Siegwart1
来源:ICRA 2017
编译:张国强
审核:汤文俊
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——用于大规模定位的高效描述子学习,该文章发表于ICRA 2017。
许多使用稀疏基于关键点的可视化地图的机器人和增强现实(AR)系统在大型且高度重复的环境中运行,其中姿态跟踪和定位是具有挑战性的任务。 此外,这些系统通常面临进一步的挑战,例如有限的计算能力,或者用于存储整个环境的大地图的内存不足。因此,开发紧凑的地图表示和改进检索对于实现大规模视觉位置识别和闭环的必要性非常大。
在本文中,我们基于神经网络的最新进展,提出了一种压缩描述符的新方法,同时提高了它们的可辨性和可匹配性。 同时,我们在设计选择中针对资源受限的机器人应用。 这项工作的主要贡献是双重的。 首先,我们提出了一种从描述符空间到低维欧氏空间的线性投影,它基于一种采用三重态损失的新型监督学习策略。 其次,我们展示了将上下文外观信息包含在视觉特征中的重要性,以便在强视点,光照和场景变化下改善匹配。通过对三个具有挑战性的数据集的详细实验,我们证明了相对于最先进方法,性能有显着提高。
主要贡献
1、我们使用一种新颖的监督学习策略来训练描述符的有效线性投影。
2、我们表明,在投影函数中包含上下文信息可以不断提高检索性能,甚至优于完全学习的描述符。
3 、我们通过广泛的实验评估证明了我们方法的有效性,并将性能增益与基线方法进行了对比。
算法流程

图1 检索匹配
这里提出的描述符投影和增强方法在强烈的外观变化下实现了困难的描述符匹配。 然后,在不使用我们的投影技术的情况下仍然可以进行一些匹配(绿色),依赖于直接在二进制描述符空间中搜索。 然而,所提出的线性投影能够实现额外的,更具挑战性的匹配(黄色),可以通过包括更广泛的上下文信息(红色)来进一步改进。

图2 描述符三元组(X1,X2,X3)
三联体的前两个组成部分X1和X2是匹配的,这意味着他们观察到相同的特征。 另一方面,X3不匹配,因为它描述了不同的兴趣点。
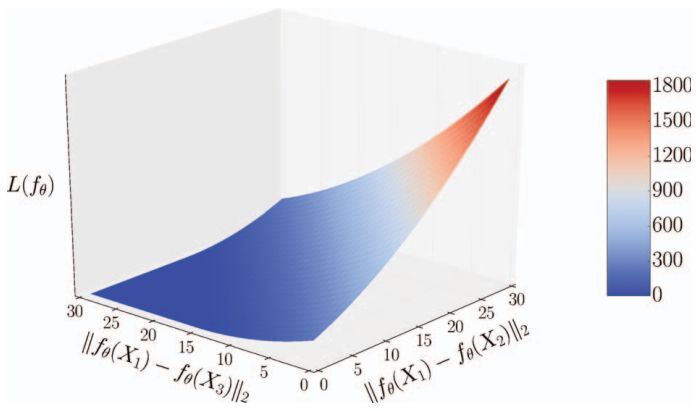
图3 边缘损失函数
在该图中,等式3被绘制为匹配和非匹配样本之间的L2距离的函数。 即使在后面的参数中凸起,L(fθ)在投影函数参数θ中也不是凸的。
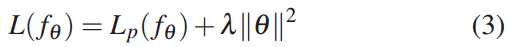
图4 提出的学习方法的训练周期
要初始化训练,应提供一些初始样本三元组。 在这些反向传播后,我们预测了一批训练样本,并用它们来制作新的硬三胞胎。 这些将用于继续训练模型。
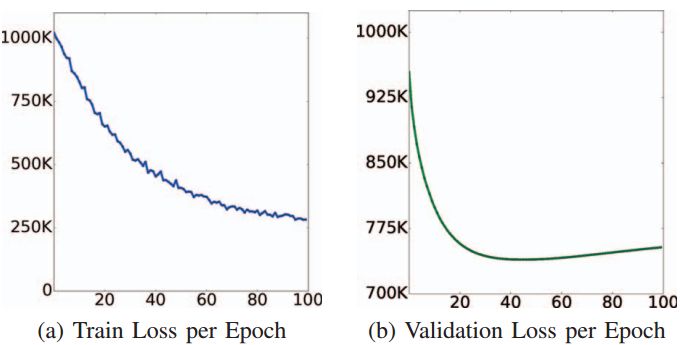
图5 在线交叉验证
根据训练期间未见的验证集定期评估学习参数。将检测具有较低验证损失的参数以进行测试。 此过程与L2标准化一起减少了训练集上的过度拟合。
表 1 乘数交叉验证

为了选择特征尺度的常数乘数,我们使用曲线下的精确回收面积(PR AUC)对其值进行交叉验证。 关于这一分数的更多细节将在第IV-A节中给出。 正如定性分析所预期的那样(图6),C = 50给出了最好的结果。

图6 定位景况举例
为了实现尺度不变性,我们通过常数乘数将景况与特征尺度耦合。在图中,乘数分别为20,50,100,300。注意,从乘数100开始,边界效应开始显着,而对于20,背景仅捕获少数其他感兴趣点。 表I中的结果报告乘数50在性能方面是最好的,正如我们对定性分析所期望的那样。
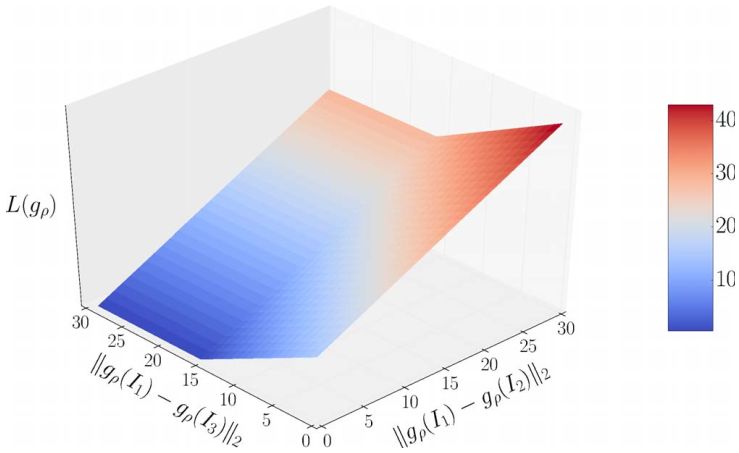
图7 景况描述子误差函数
在该图中相对于匹配和非匹配图像块描述符之间的L2距离绘制了等式6。 与图3中的损失不同,我们在此更加强调匹配图像补丁之间的距离,要求尽可能小。即使有利于学习图像补丁功能,强制执行此约束也会导致性能下降(如果使用) 用于训练线性投影。
主要结果
表2 曲线下的PR区域(AUC)

图2 线性初始化和非线性细化给出的校准结果
3个评估数据集的泛化结果。 所有投影方法都是通过博物馆数据集的火车分割来学习的。 相应的PR曲线如图8所示。
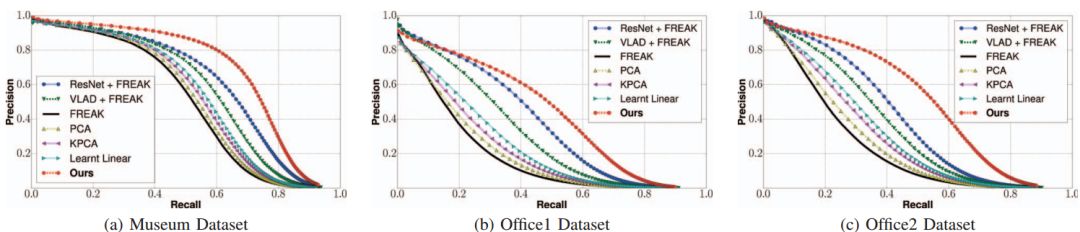
图8 PR 曲线
尽管在博物馆数据集的火车拆分中学到了,但我们的方法很好地概括了Office数据集的视觉上不同的数据。 实际上,可以观察到我们的线性和上下文增强投影始终优于所有基线方法。 有趣的是,使用FREAK描述符进行搜索的效果非常差。 我们认为这是由于我们的数据集中出现的外观发生了很大变化。 相应的PR AUC列于表II中。 除原始FREAK外,所有预测描述符都是16维浮点数。
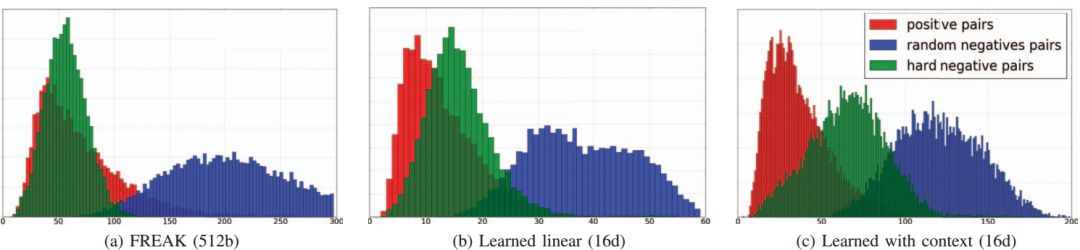
图9 成对距离分布
在大型和重复环境中,难以区分匹配(红色)和非匹配对(绿色和蓝色)。实际上,对于每个描述符,将存在许多非对应的最近邻居(绿色距离)。我们的线性和上下文投影缓解了这个问题,提高了描述符的可辨性。
表3 训练和评估数据集
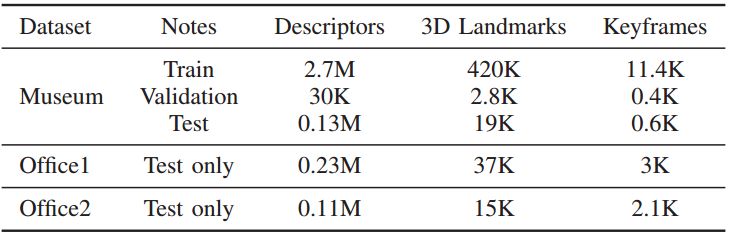
只有博物馆数据集用于训练我们的模型。为了测试在训练期间看不见的不同数据的概括,我们评估了另外两个具有挑战性的室内数据集。
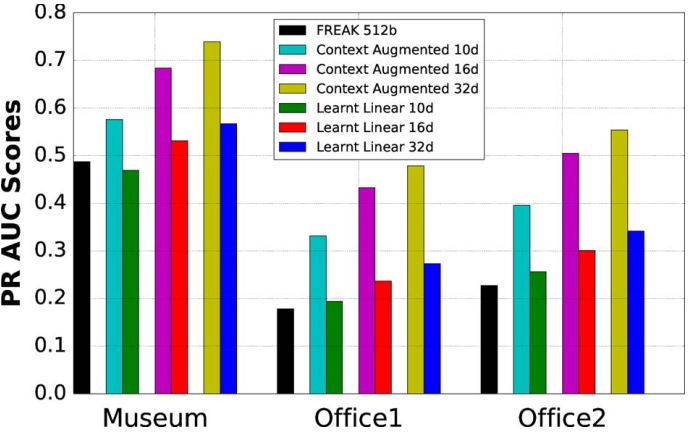
图10 描述符维数的影响
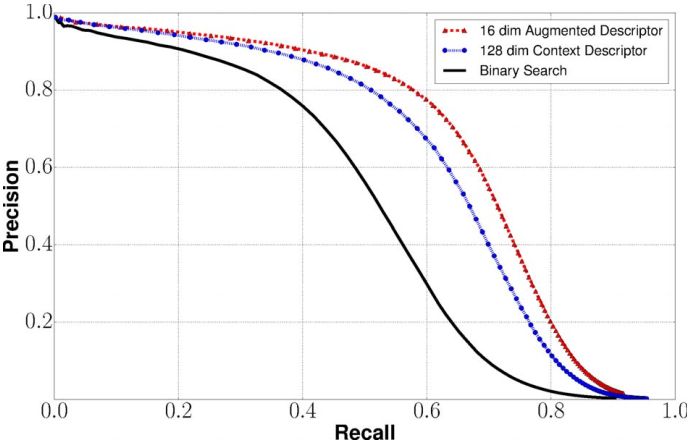
图11 耦合学习
尽管尺寸较小,但是景况和视觉特征之间的结合优于单独考虑的两个部分的性能。 这证明了建议的方法比仅使用单个(手工或学习的)图像补丁描述符产生更好的结果。
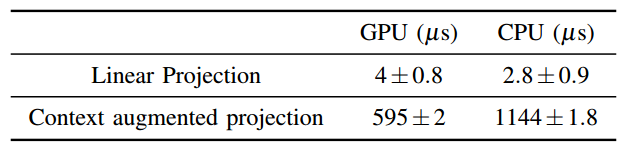
表4 一个描述符的计算成本

Abstract
Many robotics and Augmented Reality (AR) systems that use sparse keypoint-based visual maps operate in large and highly repetitive environments, where pose tracking and localization are challenging tasks. Additionally, these systems usually face further challenges, such as limited computational power, or insufficient memory for storing large maps of the entire environment. Thus, developing compact map representations and improving retrieval is of considerable interest for enabling large-scale visual place recognition and loop-closure.
In this paper, we propose a novel approach to compress descriptors while increasing their discriminability and matchability, based on recent advances in neural networks. At the same time, we target resource-constrained robotics applications
in our design choices. The main contributions of this work are twofold. First, we propose a linear projection from descriptor space to a lower-dimensional. Euclidean space, based on a novel supervised learning strategy employing a triplet loss. Second, we show the importance of including contextual appearance information to the visual feature in order to improve matching under strong viewpoint, illumination and scene changes.Through detailed experiments on three challenging datasets, we demonstrate significant gains in performance over state-ofthe-art methods.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com





