大咖 | 香侬科技对话FB AI研究院首席科学家Devi Parikh:视觉问答数据集VQA的前世今生

本文系香侬科技系列专访栏目,本期采访嘉宾是Facebook人工智能研究院(FAIR)首席科学家Devi Parikh。
Facebook人工智能研究院(FAIR)首席科学家Devi Parikh 是2017年 IJCAI 计算机和思想奖获得者(IJCAI两个最重要的奖项之一,被誉为国际人工智能领域的“菲尔兹奖”),并位列福布斯2017年“20位引领AI研究的女性”榜单。她主要从事计算机视觉和模式识别研究,具体研究领域包括计算机视觉、语言与视觉、通识推理、人工智能、人机合作、语境推理以及模式识别。
2008 年到现在,Devi Parikh 先后在计算机视觉三大顶级会议(ICCV、CVPR、ECCV)发表多篇论文。她所主持开发的视觉问题回答数据集(Visual Question Anwering)受到了广泛的关注,并在CVPR 2016上组织了VQA挑战赛和VQA研讨会,极大地推动了机器智能理解图片这一问题的解决,并因此获得了2016年美国国家科学基金会的“杰出青年教授奖(NSF CAREER Award)。她最近的研究集中在视觉、自然语言处理和推理的交叉领域,希望通过人和机器的互动来构造一个更加智能的系统。
香侬科技:您和您的团队开发的视觉问答数据集(VQA, Visual Question Answering Dataset, Antol et al. ICCV2015; Agrawal et al. IJCV 2017)极大地推动了该领域的发展。这一数据集囊括了包括计算机视觉,自然语言处理,常识推理等多个领域。您如何评估VQA数据集到目前产生的影响?是否实现了您开发此数据集的初衷?您期望未来几年VQA数据集(及其进阶版)对该领域产生何种影响?
Devi and Aishwarya:VQA数据集影响:我们在VQA上的工作发布后短期内受到了广泛的关注 – 被超过800篇论文所引用((Antol et al. ICCV 2015; Agrawal et al. IJCV 2017),还在15年ICCV上“对话中的物体认知”研讨会中获得最佳海报奖(Best Poster Award)。
为了评估VQA的进展,我们用VQA第一版为数据集,在2016年IEEE国际计算机视觉与模式识别会议(CVPR-16,IEEE Conference on Computer Vision and Pattern Recognition 2016)上组织了第一次VQA挑战赛和第一次VQA研讨会(Antol etal. ICCV 2015; Agrawal et al. IJCV 2017)。 挑战和研讨会都很受欢迎:来自学术界和工业界的8个国家的大约30个团队参与了这一挑战。在此次挑战中,VQA的准确率从58.5%提高到67%,提升了8.5%。

图1. VQA数据集中的问答样例。
VQA v1数据集和VQA挑战赛不仅促进了原有解决方案的改进,更催生了一批新的模型和数据集。例如,使用空间注意力来聚焦与问题相关的图像区域的模型(Stacked Attention Networks, Yang et al., CVPR16);以分层的方式共同推理图像和问题应该注意何处的注意力神经网络(Hierarchical Question Image Co-attention, Lu et al., NIPS16);可以动态组合模块的模型,其中每个模块专门用于颜色分类等子任务(Neural Module Networks, Andreas et al., CVPR16);使用双线性池化等运算融合视觉和语言特征,从而提取更丰富的表征的模型(Multimodal Compact Bilinear Pooling,Fukui et al.,EMNLP16)。
此外,VQA也催生了许多新的数据集,包括侧重于视觉推理和语言组合性的模型及相关数据集(CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning, Johnson et al., CVPR17);对于VQA第一版数据集的重新切分,使其可以用来研究语言的组合性问题C-VQA(A Compositional Split of the VQA v1.0 Dataset, Agrawal et al., ArXiv17);还有需要模型克服先验言语知识的影响,必须要观察图像才能回答问题的VQA数据集(Agrawal et al., CVPR18)。
简而言之,我们在VQA上的工作已经在人工智能中创建了一个新的多学科子领域。事实上,在这个数据集发布不久,在一些重要的AI会议上,当你提交论文并选择相关的子主题时,VQA已成为一个新增选项。
是否实现了VQA开发的初衷:
尽管VQA社区在提高VQA模型的性能方面取得了巨大进步(VQA v2数据集上的预测准确率在3年内从54%提高到72%),但我们距离完全解决VQA任务还有很长的路要走。现有的VQA模型仍然缺乏很多必要的能力,比如:视觉落地 (visual grounding),组合性(compositionality),常识推理等,而这些能力是解决VQA的核心。
当我们开发数据集时,我们认为模型的泛化应该是一个很大挑战,因为你很难期望模型在训练集上训练,就能很好地推广到测试集。因为在测试时,模型可能会遇到关于图像的任何开放式问题,而很有可能在训练期间没有遇到过类似的问题。我们期望研究人员能尝试利用外部知识来处理此类问题,但是在这方面的工作现阶段还很少。不过我们已经看到了一些在该方面的初步进展(e.g., Narasimhan et al. ECCV 2018, Wang et al. PAMI 2017),希望将来会看到更多。
期望VQA数据集未来的影响:
我们希望VQA数据集对该领域能产生直接和间接的影响。直接的影响是指,我们期望在未来几年内能涌现更多新颖的模型或技术,以进一步改进VQA第一版和VQA第二版数据集上的预测准确率。而间接的影响是指,我们希望更多全新的数据集和新任务能被开发出来,如CLEVR(Johnson等人, CVPR17),Compositional VQA(Agrawal等人,ArXiv17),需要克服先验语言知识的VQA (Agrawal et al.,CVPR18),基于图像的对话(Das et al.,CVPR17),需要具身认知的问答(Embodied Question Answering, Das et al.,CVPR18)。它们或直接构建在VQA数据集之上,或是为解决现有VQA系统的局限性所构造。因此,我们期待VQA数据集(及其变体)能进一步将现有AI系统的能力提升,构造可以理解语言图像,能够生成自然语言,执行动作并进行推理的系统。
香侬科技:最近,您的团队发布了VQA第二版(Goyal et al. CVPR 2017),其中包含对应同一问题有着不同答案的相似图像对。这样的数据集更具挑战性。通常,创建更具挑战性的数据集会迫使模型编码更多有用的信息。但是,构建这样的数据集会耗费大量人力。是否可以用自动的方式来生成干扰性或对抗性的示例,从而将模型的预测能力提升到一个新的水平呢?

Devi, Yash, and Jiasen:构建大规模数据集确实是劳动密集型的工作。目前有一些基于现有标注自动生成新的问答对的工作。例如,Mahendru等人EMNLP 2017使用基于模板的方法,根据VQA训练集的问题前提,生成关于日常生活中的基本概念的新问答对。这一研究发现,将这些简单的新问答对添加到VQA训练数据可以提高模型的性能,尤其是在处理语言组合性(compositionality)的问题上。
在数据增强这一问题上,生成与图像相关的问题也是一个很重要的课题。与上述基于模板生成问题的方法不同,这种方法生成的问题更自然。但是,这些模型还远不成熟,且无法对生成问题进行回答。因此,为图像自动生成准确的问答对目前还是非常困难的。要解决这一问题,半监督学习和对抗性例子生成可能会提供一些比较好的思路。
值得注意的是,关于图像问题的早期数据集之一是Mengye Ren等人在2015年开发的Toronto COCO-QA数据集。他们使用自然语言处理工具自动将关于图像的标注转换为问答对。虽然这样的问答对通常会留下奇怪的人为痕迹,但是将一个任务的标注(在本例中为字幕)转换为另一个相关任务的标注(在这种情况下是问答)是一个极好的方法。
香侬科技:除VQA任务外,您还开发了基于图像的对话数据集--Visual Dialog Dataset(Das et al., CVPR 2017, Spotlight)。在收集数据时,您在亚马逊劳务众包平台(一个被广泛使用的众包式数据标注平台)上配对了两个参与者,给其中一个人展示一张图片和图的标题,另一个人只能看到图的标题,任务要求只能看到标题的参与者向另一个能看到图片的参与者提出有关图片的问题,以更好地想象这个图像的场景。
这个数据集为我们清晰地揭示了图像中哪些信息人们认为更值得获取。您是否认为对模型进行预训练来猜测人们可能会问什么问题,可以让模型具备更像人类的注意力机制,从而提高其问答能力?
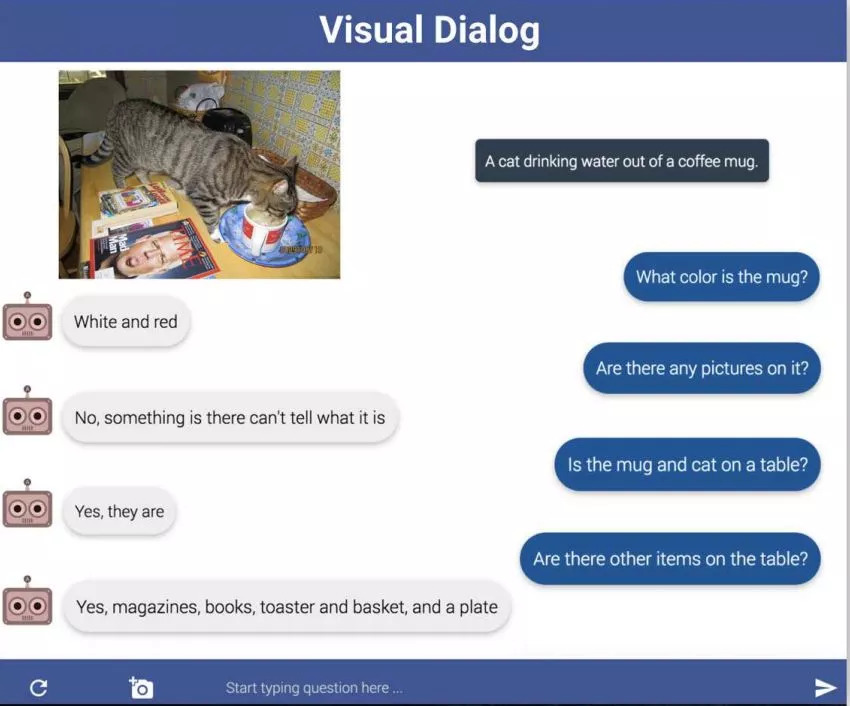
Devi and Abhishek:在这些对话中,问题的提出存在一些规律:对话总是开始于谈论最醒目的对象及其属性(如人,动物,大型物体等),结束在关于环境的问题上(比如,“图像中还有什么?”,“天气怎么样?”等)。如果我们可以使模型学习以区分相似图像为目的来提出问题并提供答案,从而使提问者可以猜出图像,就可以生成更好的视觉对话模型。Das & Kottur et al., ICCV 2017展示了一些相关的工作。
香侬科技:组合性是自然语言处理领域的一个经典问题。您和您的同事曾研究评估和改进VQA系统的组合性(Agrawal et al. 2017)。一个很有希望的方向是结合符号方法和深度学习方法(例, Lu et al. CVPR 2018, Spotlight)。您能谈谈为什么神经网络普遍不能系统性地泛化,以及我们能如何解决这个问题吗?

图4. 组合性VQA数据集(C-VQA)的示例。测试集中词语的组合是模型在训练集中没有学习过的,虽然这些组合中的每一单个词在训练集中都出现过。图片来源于Agrawal et al. 2017。
Devi and Jiasen: 我们认为产生这样结果的一个原因是这些模型缺乏常识,如世界是如何运作的,什么是可以预期的,什么是不可预期的。这类知识是人类如何从例子中学习,或者说面对突发事件时依然可以做出合理决策的关键。
当下的神经网络更接近模式匹配算法,它们擅长从训练数据集中提取出输入与输出之间复杂的相关性,但在某种程度上说,这也是它们可以做的全部了。将外部知识纳入神经网络的方法现在仍然非常匮乏。
香侬科技:您的工作已经超越了视觉和语言的结合,扩展到了多模式整合。在您最近发表的“Embodied Question Answering”论文中(Das et al. CVPR, 2018),您介绍了一项包括主动感知,语言理解,目标驱动导航,常识推理以及语言落地为行动的任务。
这是一个非常有吸引力的方向,它更加现实,并且与机器人关系更加紧密。在这种背景下的一个挑战是快速适应新环境。您认为在3D房间环境中训练的模型(如您的那篇论文中的模型)会很快适应其他场景,如户外环境吗?我们是否必须在模型中专门建立元学习(meta-learning)能力才能实现快速适应?
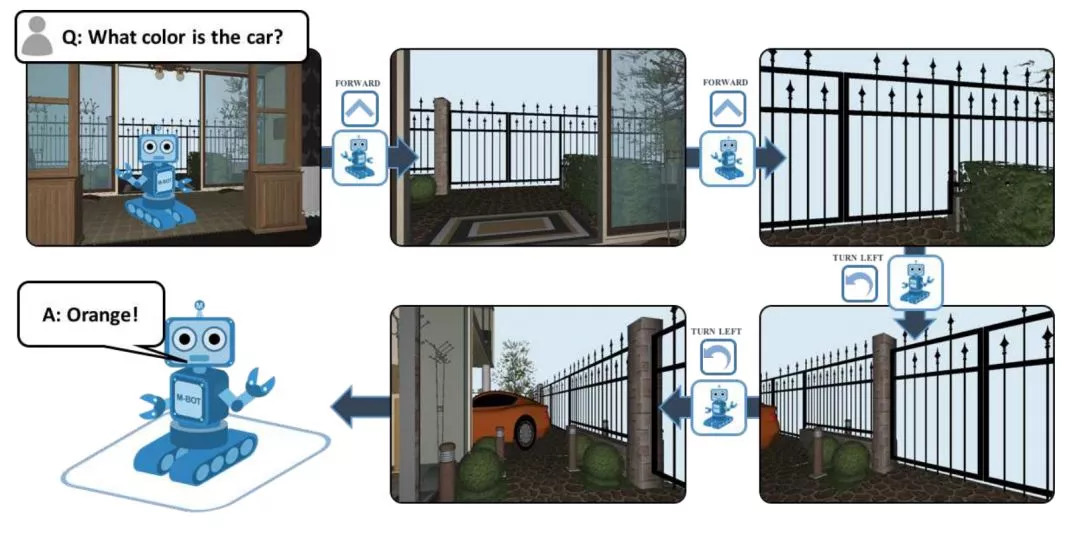
图5. 在具身问答(Embodied QA)任务中,机器人通过探索周围的3D环境来回答问题。为完成这项任务 ,机器人必须结合自然语言处理、视觉推理和目标导航的能力。图片来自于Das et al. CVPR 2018
Devi and Abhishek:在目前的实例中,他们还不能推广到户外环境。这些系统学习到的东西与他们接受训练时的图像和环境的特定分布密切相关。因此,虽然对新的室内环境的一些泛化是可能的,但对于户外环境,他们在训练期间还没有看到过足够多的户外环境示例。
例如,在室内环境中,墙壁结构和深度给出了关于可行路径和不可行路径的线索。而在室外环境中,路表面的情况(例如,是道路还是草坪)可能与系统能否在该路径上通行更相关,而深度却没那么相关了。
即使在室内的范围内,从3D房间到更逼真的环境的泛化也是一个未完全解决的问题。元学习方法肯定有助于更好地推广到新的任务和环境。我们还在考虑构建模块化的系统,将感知与导航功能分离,因此在新环境中只需要重新学习感知模块,然后将新的环境(例如更真实的环境)的视觉输入映射到规划模块更为熟悉的特征空间。
香侬科技:您有一系列论文研究VQA任务中问题的前提(Ray et al. EMNLP 2016, Mahendru et al. 2017),并且您的研究发现,迫使VQA模型在训练期间对问题前提是否成立进行判断,可以提升模型在组合性(compositionality)问题上的泛化能力。目前NLP领域似乎有一个普遍的趋势,就是用辅助任务来提高模型在主要任务上的性能。但并非每项辅助任务都一定会有帮助,您能说说我们要如何找到有用的辅助任务吗?

图6. VQA问题中常常包含一些隐藏前提,会提示一部分图像信息。因此Mahendru et al. 构造了“问题相关性预测与解释”数据集(Question Relevance Prediction and Explanation, QRPE)。图中例子展示了Mahendru et al. EMNLP 2017一文中“错误前提侦测”模型侦测到的一些前提不成立的问题。
Devi and Viraj:在我们实验室Mahendru等人2017年发表的论文中,作者的目标是通过推理问题的前提是否成立,来使VQA模型能够更智能地回答不相关或以前从未遇到的问题。
我们当时有一个想法,认为用这样的方式来扩充数据集可能帮助模型将物体及其属性分离开,这正是组合性问题的实质,而后来经过实验发现确实如此。更广义地来说,我们现在已经看到了很多这种跨任务迁移学习的例子。
例如,围绕问题回答,机器翻译,目标导向的对话等多任务展开的decaNLP挑战。或者,将用于RGB三维重建,语义分割和深度估计(depth estimation)的模型一起训练,构建一个强大的视觉系统,用于完成需要具身认知的任务(Embodied Agents, Das et al. 2018)。
当然也包括那些首先在ImageNet上预训练,然后在特定任务上微调这样的被广泛使用的方法。所有这些都表明,即使对于多个跨度很大的任务,多任务下学习的表征也可以非常有效地迁移。但不得不承认,发现有意义的辅助任务更像是一门艺术,而不是科学。
香侬科技:近年来,深度学习模型的可解释性受到了很多关注。您也有几篇关于解释视觉问答模型的论文,比如理解模型在回答问题时会关注输入的哪个部分,或是将模型注意力与人类注意力进行比较(Das et al. EMNLP 2016, Goyal et al. ICML 2016 Workshop on Visualization for Deep Learning, Best Student Paper)。您认为增强深度神经网络的可解释性可以帮助我们开发更好的深度学习模型吗?如果是这样,是以什么方式呢?

图7. 通过寻找模型在回答问题时关注了输入问题中哪部分字段(高亮部分显示了问题中的词汇重要性的热图)来解释模型预测的机制。比如上面问题中“whole”是对模型给出回答“no”最关键的词语。图片来源于论文Goyal et al. ICML 2016 Workshop on Visualization for Deep Learning。
Devi and Abhishek:我们的Grad-CAM论文(Selvarajuet et al., ICCV 2017)中的一段话对这个问题给出了答案:
“从广义上讲,透明度/可解释性在人工智能(AI)演化的三个不同阶段都是有用的。首先,当AI明显弱于人类并且尚不能可靠地大规模应用时(例如视觉问题回答),透明度和可解释性的目的是识别出模型为什么失败,从而帮助研究人员将精力集中在最有前景的研究方向上; 其次,当人工智能与人类相当并且可以大规模使用时(例如,在足够数据上训练过的对特定类别进行图像分类的模型),研究可解释性的目的是在用户群体中建立对模型的信心。第三,当人工智能显著强于人类(例如国际象棋或围棋)时,使模型可解释的目的是机器教学,即让机器来教人如何做出更好的决策。
可解释性确实可以帮助我们改进深度神经网络模型。对此我们发现的一些初步证据如下:如果VQA模型被限制在人们认为与问题相关的图像区域内寻找答案,模型在测试时可以更好的落地并且更好地推广到有不同“答案先验概率分布”的情况中(即VQA-CP数据集这样的情况)。
可解释性也常常可以揭示模型所学到的偏见。这样做可以使系统设计人员使用更好的训练数据或采取必要的措施来纠正这种偏见。我们的Grad-CAM论文(Selvaraju et al.,ICCV 2017)的第6.3节就报告了这样一个实验。这表明,可解释性可以帮助检测和消除数据集中的偏见,这不仅对于泛化很重要,而且随着越来越多的算法被应用在实际社会问题上,可解释性对于产生公平和符合道德规范的结果也很重要。
香侬科技:在过去,您做了很多有影响力的工作,并发表了许多被广泛引用的论文。您可以和刚刚进入NLP领域的学生分享一些建议,告诉大家该如何培养关于研究课题的良好品味吗?
Devi:我会引用我从Jitendra Malik(加州大学伯克利分校电子工程与计算机科学教授)那里听到的建议。我们可以从两个维度去考虑研究课题:重要性和可解决性。
有些问题是可以解决的,但并不重要;有些问题很重要,但基于整个领域目前所处的位置,几乎不可能取得任何进展。努力找出那些重要、而且你可以(部分)解决的问题。当然,说起来容易做起来难,除了这两个因素之外也还有其他方面需要考虑。例如,我总是被好奇心驱使,研究自己觉得有趣的问题。但这可能是对于前面两个因素很有用的一个一阶近似。
本文选自《香侬说》,这是香侬科技打造的一款以机器学习与自然语言处理为专题的访谈专栏。
该专栏由斯坦福大学,麻省理工学院, 卡耐基梅隆大学,剑桥大学等知名大学计算机系博士生组成的“香侬智囊”撰写问题,采访顶尖科研机构(斯坦福大学,麻省理工学院,卡耐基梅隆大学,谷歌,DeepMind,微软研究院,OpenAI等)中人工智能与自然语言处理领域的学术大牛, 以及在博士期间就做出开创性工作而直接进入顶级名校任教职的学术新星,分享他们广为人知的工作背后的灵感以及对相关领域大方向的把控。
参考文献
Antol S, Agrawal A, Lu J, et al. VQA: Visual question answering[C]. Proceedings of the IEEE International Conference on Computer Vision. 2015: 2425-2433.
Yang Z, He X, Gao J, et al. Stacked attention networks for image question answering[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 21-29.
Lu J,Yang J, Batra D, et al. Hierarchical question-image co-attention for visual question answering[C]. Proceedings of the Advances In Neural Information Processing Systems. 2016: 289-297.
Andreas J, Rohrbach M, Darrell T, et al. Neural module networks[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 39-48.
Fukui A, Park D H, Yang D, et al. Multimodal compact bilinear pooling for visual question answering and visual grounding[J]. arXiv preprint arXiv:1606.01847,2016.
Johnson J, Hariharan B, van der Maaten L, et al. CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning[C]. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017: 1988-1997.
Vo M, Yumer E, Sunkavalli K, et al. Automatic Adaptation of Person Association for Multiview Tracking in Group Activities[J]. arXiv preprint arXiv:1805.08717, 2018.
Agrawal A, Kembhavi A, Batra D, et al. C-vqa: A compositional split of the visual question answering (vqa) v1.0 dataset. arXiv preprint arXiv: 1704.08243, 2017.
Agrawal A, Batra D, Parikh D, et al. Don’t just assume; look and answer: Overcoming priors for visual question answering[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 4971-4980.
Das A, Kottur S, Gupta K, et al. Visual dialog[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 1080--1089.
Das A, Datta S, Gkioxari G, et al. Embodied question answering[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018.
Goyal Y, Khot T, Summers-Stay D, et al. Making the V in VQA matter: Elevating the role of image understanding in Visual Question Answering[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017, 1(2):3.
Mahendru A, Prabhu V, Mohapatra A, et al. The Promise of Premise: Harnessing Question Premises in Visual Question Answering[C]. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017: 926-935.
Ren M, Kiros R, Zemel R. Image question answering: A visual semantic embedding model and a new dataset[J]. Proceedings of the Advances in Neural Information Processing Systems, 2015,1(2): 5.
Fang H S, Lu G, Fang X, et al. Weakly and Semi Supervised Human Body Part Parsing via Pose-Guided Knowledge Transfer[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 70-78.
Ray A, Christie G, Bansal M, et al. Question relevance in VQA: identifying non-visual and false-premise questions[J]. arXiv preprint arXiv: 1606.06622,2016.
Das A, Agrawal H, Zitnick L, et al. Human attention in visual question answering: Do humans and deep networks look at the same regions?[J]. Computer Vision and Image Understanding, 2017, 163: 90-100.
Goyal Y, Mohapatra A, Parikh D, et al. Towards transparent AI systems: Interpreting visual question answering models[J]. arXiv preprint arXiv:1608.08974, 2016.
Selvaraju R R, Cogswell M, Das A, et al. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization[C]. Proceedings of the International Conference on Computer Vision (ICCV). 2017: 618-626.
可以上下滑动哟~
附英文原文采访稿:
ShannonAI: The Visual Question Answering Dataset (Antol et al. ICCV 2015; Agrawal et al. IJCV 2017) you and your colleagues introduced has greatly pushed the field forward. It integrates various domains including computer vision, natural language processing, common sense reasoning, etc. How would you evaluate the impact of the VQA dataset so far? Have the original goals of introducing this dataset been realized? What further impact do you anticipate the VQA dataset (and its variants) to have on the field in the next few years?
Devi and Aishwarya: (1)Our work on VQA has witnessed tremendous interest in a short period of time (3 years) - over 800 citations of the papers (Antol et al.ICCV 2015; Agrawal et al. IJCV 2017), ~1000 downloads of the dataset, best poster award at the Workshop on Object Understanding for Interaction (ICCV15).
To benchmark progress in VQA, we organized the first VQA Challenge and the first VQA workshop at CVPR16 on the VQA v1 dataset (Antolet al. ICCV 2015; Agrawal et al. IJCV 2017). Both the challenge and the workshop were very well received. Approximately 30 teams from 8 countries across academia and industry participated in the challenge. During this challenge, the state-of-the-art in VQA improved by 8.5% from 58.5% to 67%.
In addition to the improvement in the state-of-the-art, the VQA v1 dataset and the first VQA Challenge led to the development of a variety of models and follow-updatasets proposed for this task. For example, we saw models using spatial attention to focus on image regions relevant to question (Stacked Attention Networks, Yang et al., CVPR16), we saw models that jointly reason about image and question attention, in a hierarchical fashion (Hierarchical Question Image Co-attention, Lu et al., NIPS16), models which dynamically compose modules, where each module is specialized for a subtask such as color classification (Neural Module Networks, Andreas et al., CVPR16), models that study how to fuse thevision and language features using operators such as bilinear pooling to extract rich representations(Multimodal Compact Bilinear Pooling, Fukui et al., EMNLP16), and we have seen datasets as well as models that focus on visual reasoning and compositionalityin language (CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning, Johnson et al., CVPR17), C-VQA: A Compositional Split of the Visual Question Answering (VQA) v1.0 Dataset (Agrawal et al., ArXiv17), Don't Just Assume; Look and Answer: Overcoming Priors for Visual Question Answering (Agrawal et al., CVPR18).
In short, our work on VQA has resulted in creation of a new multidisciplinary sub-fieldin AI! In fact, at one of the major conferences (I think it was NIPS) -- when you submit a paper and have to pick the relevant sub-topic -- VQA is one of the options :)
(2)Although the VQA community has made tremendous progress towards improving the state-of-the-art (SOTA) performance on the VQA dataset (the SOTA on VQA v2 dataset improved from 54% to 72% in 3 years), we are still far from completely solving the VQA dataset and the VQA task in general. Existing VQA models still lack a lot of skills that are core to solving VQA -- visual grounding, compositionality, common sense reasoning etc.
When we introduced the dataset, we believed that it would be very difficult for models to just train on the training set and generalize well enough to the test set. After all, at test time, the model might encounter any open-ended question about the image. It is quite plausible that it won’t have seen a similar question during training. We expected researchers to explore the use of external knowledge to deal with such cases. However, we have seen less work in that direction than we had anticipated and even hoped for. We have seen some good initial progress in this space (e.g., Narasimhan et al. ECCV 2018, Wang et al. PAMI 2017) and hopefully we’ll see more in the future.
(3)We expect the VQA dataset to have both direct and indirect impact on the field. Directly, we expect more novel models/ techniques to bed eveloped in next few years in order to further improve the SOTA on the VQA v1 and VQA v2 datasets. Indirectly, we expect that more novel datasets and novel tasks such as CLEVR (Johnson et al., CVPR17), Compositional VQA (C-VQA)(Agrawal et al., ArXIv17), VQA under Changing Priors (VQA-CP) (Agrawal et al.,CVPR18), Visual Dialog (Das et al., CVPR17), Embodied Question Answering (Das et al., CVPR18) will be developed either by directly building on top of the VQA dataset or by being motivated by what skills existing VQA systems are lacking and developing datasets/ tasks that evaluate those skills. Thus, we expect the VQA dataset (and its variants) to further push the capabilities of the existing AI systems towards agents that can see, talk, act, and reason.
ShannonAI: Recently your team released VQA2.0 (Goyal et al. CVPR 2017), a balanced dataset that contains pairs of similar images that result in different answers to the same question. In general, creating more challenging datasets seems to force the models to encode more information that are useful. However, constructing such datasets can be pretty labor-intensive. Is there any automatic way to generate distractors/adversarial examples that may help push the models to their limits?
Devi, Yash, and Jiasen: Constructing a large-scale dataset is indeed labor-intensive. There are a few works which focus on automatically generating new question-answer pairs based on existing annotations. For example, Mahendruet al., EMNLP 2017 uses a template-based method to generate new question-answer pairs about elementary concepts from premises of questions in the VQA trainingset. They show that adding these simple question-answer pairs to VQA training data can improve performance on tasks requiring compositional reasoning.
Visual question generation which aims to generate questions related to the image is another topic connected to data augmentation.Different from the template-based method described above, the generated question is more natural. However, these models are far from perfect and answers to these questions still need to be crowdsourced. Hence, automatically generating accurate question-answer pairs for images is currently quite difficult and noisy. Semi-supervised learning and adversarial examples generation are certainly promising directions.
Note that one of the earlier datasets on questions about images was the Toronto COCO-QA Dataset dataset by Ren et al. in 2015.They automatically converted captions about images into question-answer pairs using NLP tools. While the question-answer pairs often have strange artifacts,it is a great way to convert annotations from one task (in this case captioning) into annotations for another related task (in this case question-answering).
ShannonAI: In addition to the VQA task, you also introduced the Visual Dialog Dataset (Das et al., CVPR 2017 Spotlight). When collecting the data, you paired two participants on Amazon Mechanical Turk and asked one of them to ask questions about an image to the other. This dataset offers us great insight into what naturally attracts human's attention in an image and what information humans find worth requesting. Do you think pre-training the model to guess what questions people might ask could equip the model with more human-like attention mechanism, which would in turn enhance its question answering ability?
Devi and Abhishek: There is a somewhat regular pattern to the line of questioning in these dialogs — the conversation starts with humans talking about the most salient objects and their attributes (people, animals, large objects, etc.), and ends with questions about the surroundings("what else is in the image?", "how's the weather?", etc.).
And so if we were to equip models with this sort of acapability where they learn to ask questions and provide answers in an image-discriminative manner so that the questioner can guess the image, that could lead to better visual dialog models. Some work towards this is available in Das & Kotturet al., ICCV 2017.
ShannonAI: Compositionality has been a long-standing topic in NLP. You and your colleagues have focused on evaluating and improving the compositionality of the VQA systems (Agrawal et al. 2017). One promising direction is to combine symbolic approaches and deep learning approaches (e.g., Lu et al. CVPR 2018 Spotlight). Could you comment on why neural networks are generally bad at performing systematic generalization and how we could possibly tackle that?
Devi and Jiasen: We think one reason for this is that these models lack common sense -- knowledge of how the world works, what is expected vs.unexpected, etc. Knowledge of this sort is key to how humans learn from a few examples, or are robust -- i.e., can make reasonable decisions -- even when faced with novel “out of distribution” instances. Neural networks, in their current incarnation, are closer to pattern matching algorithms that are very good at squeezing complex correlations out from the training dataset, but to some degree, that is all they can do well. Mechanisms to incorporate external knowledge into neural networks is still significantly lacking.
ShannonAI: Your work has gone beyond integrating vision and language, and has extended to multi-modal integration. In your recent "The Embodied VQA" paper, you introduced a task that incorporates active perception, language understanding, goal-driven navigation, common sense reasoning, and grounding of language into actions. This is a very attractive direction since it is more realistic and tightly connects to robotics. One challenge under this context is fast adaptation to new environments. Do you think models trained in the House3D environment (as in the paper) would quickly adapt to other scenarios, like outdoor environment? Do we have to explicitly build meta-learning ability in the models in order to achieve fast adaptation?
Devi and Abhishek: In their current instantiation, they probably would not generalize to outdoor environments. These agents are tightly tied to the specific distribution of images and environments they're trained in. So while some generalization to novel indoor environments is expected, they haven't seen sufficient examples of outdoor environments during training. In indoor environments for instance, wall structures and depth give strong cues about navigable vs. unnavigable paths. In an outdoor environment, the semantics of the surfaces (as opposed to depth) are likely more relevant to whether an agent should navigate on a path or not (e.g., road vs. grass).
Even within the scope of indoor navigation,generalizing from House3D to more realistic environments is not a solved problem. And yes, meta-learning approaches would surely be useful for better generalization to new tasks and environments. We are also thinking about building modular agents where perception is decoupled from task-specific planning + navigation, so we just need to re-learn the perception module to map from visual input from the new distribution (say more photo realistic environments) to a feature space the planning module is familiar with.
ShannonAI: You have a series of papers looking at premises of questions in VQA tasks (Ray et al. EMNLP 2016, Mahendru et al. 2017) and you showed that forcing standard VQA models to reason about premises during training can lead to improvements on tasks requiring compositional reasoning. There seems to be a general trend in NLP to include auxiliary tasks to improve model performance on primary tasks. However, not every auxiliary task is guaranteed beneficial. Can you comment on how we could find good auxiliary tasks?
Devi and Viraj: In the context of Mahendru et al 2017, the authors’ goal was to equip VQA models with the ability to respond more intelligently to an irrelevant or previously unseen question, by reasoning about its underlying premises. We had some intuition that explicitly augmenting the dataset with such premises could aid the model in disentangling objects and attributes, which is essentially the building block of compositionality, and found that to be the case. More generally though, we have now seen successful examples of such transfer across tasks. For example, the decaNLP challenge that is organized around building multitask models for question answering, machine translation, goal-oriented dialog, etc. Or, the manner in which models trained for RGB reconstruction, semantic segmentation, and depth estimation, are combined to build an effective vision system for training Embodied Agents (Das et al 2018). And of course, the now popular approach of finetuning classification models pretrained on ImageNet to a wide range of tasks. All of these seem to suggest that such learned representations can transfer quite effectively even across reasonably diverse tasks. But agreed, identifying meaningful auxiliary tasks is a bit more of an art than a science.
ShannonAI: In recent years, interpretability of deep learning models has received a lot of attention. You also have several papers dedicated to interpreting visual question answering models, e.g., to understand which part of the input the models focus on while answering questions, or compare model attention with human attention (Das et al. EMNLP 2016, Goyal et al. ICML2016 Workshop on Visualization for Deep Learning, Best Student Paper). Do you think enhancing the interpretability of deep neural network could help us develop better deep learning models? If so, in what ways?
Devi and Abhishek: A snippet from our Grad-CAM paper (Selvaraju et al.,ICCV 2017) has a crisp answer to this question:
"Broadly speaking, transparency is useful at three different stages of Artificial Intelligence (AI) evolution. First, when AI is significantly weaker than humans and not yet reliably ‘deployable’ (e.g.visual question answering), the goal of transparency and explanations is to identify the failure modes, thereby helping researchers focus their efforts on the most fruitful research directions. Second, when AI is on par with humansa nd reliably ‘deployable’ (e.g., image classification on a set of categories trained on sufficient data), the goal is to establish appropriate trust and confidence in users. Third, when AI is significantly stronger than humans (e.g. chess or Go), the goal of explanations is in machine teaching – i.e., a machine teaching a human about how to make better decisions."
So yes, interpretability can help us improve deep neural network models. Some initial evidence we have of this is the following: if VQA models are forced to base their answer on regions of the image that people found to be relevant to the question, the models become better grounded and generalize better to changing distributions of answer priors at test time(i.e., on the VQA-CP dataset).
Interpretability also often reveals biases the model shave learnt. Revealing these biases can allow the system designer to use better training data or take other actions necessary to rectify this bias. Section 6.3 in our Grad-CAM paper (Selvaraju et al., ICCV 2017) paper reports such an experiment. This demonstrates that interpretability can help detect and removebiases in datasets, which is important not just for generalization, but also for fair and ethical outcomes as more algorithmic decisions are made in society.
ShannonAI: In the past you have done a lot of influential work and have published many widely cited papers. Could you share with students just entering the field of NLP some advice on how to develop good taste for research problems?
Devi: I’ll re-iterate advice I’ve heard from Jitendra Malik. One can think of research problems as falling somewhere along two axes:importance and solvability. There are problems that are solvable but not important to solve. There are problems that are important but are nearly impossible to make progress on given where the field as a whole currently stands. Try to identify problems that are important, and where you can make adent. Of course, this is easier said than done and there may be other factors to consider beyond these two (for instance, I tend to be heavily driven by what I find interesting and am just curious about). But this might be a useful first approximation to go with.
可以上下滑动哟~
【今日机器学习概念】
Have a Great Definition








