开往视觉对话研究的列车——2018年第一届视觉对话挑战赛
整理 | 姗姗
出品 | 人工智能头条(公众号ID:AI_Thinker)
【人工智能头条导读】在过去的研究中,计算机视觉和自然语言处理两个领域都取得了飞速的发展与成功。虽然他们都有自己的研究方法,技术也已经满足了很多的应用需求,但更多时候是分开发展的,并且从感知觉深入到认知层面的研究还是存在着很多的问题与未知。随着问题的突出、不断涌现的需求与计算能力的飞速发展,理解能力已经成为越来越多的研究和应用中最为关注的问题。
视觉对话,是计算机视觉与自然语言处理两个领域结合的新研究方向,视觉与语言的综合应用。如果”看“和”语言“只是单独作用而不能彼此相辅相成,那么我们描绘的人工智能、人机交互只能是空中楼阁、梦幻泡影而已。
然而,从近两年的研究中可以发现,对于将计算机视觉与自然语言处理两个领域结合的工作已经多了起来,并且努力开拓研究范围和优化方法与结果。不涉及对话系统的 VQA( visual question answering)、video/movie 的描述、还有涉及对话模型的视觉对话领域。近三年发表的论文也在不断累积,从一开始最早的小规模数据集,李飞飞老师提出的Visual 7W 数据集、到现在最大的数据集mscocoQA ;从初期 VQA 采用的方法,到引用外部知识库,Attention机制等方法上的改进,可以看出大家都在致力于将图像、场景等视觉信息的理解与推理、语言这些高级认知能力相融合,继续推动人工智能的发展。
近日关于视觉对话方向的第一场竞赛在 6 月正式开始举行。无论是在计算机视觉领域还是自然语言处理方向的有志者都可以参与进来,推动人工智能系统的发展。
▌前言
EvalAI是一个开源的网络平台,用于组织和参与人工智能挑战。EvalAI = evaluating the state of the art in AI。在今年的6月4日,EvalAI 宣布即将举办第一届视频内容对话竞赛。在前几日,EvalAI 公布了竞赛的数据集与评估服务器,并将于8月中旬截止提交作品。
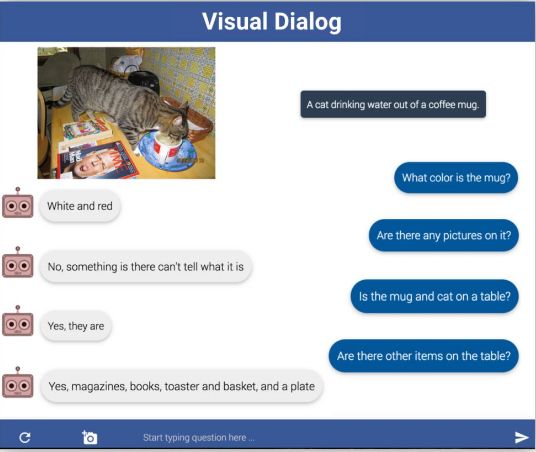
视觉对话是一项新颖的任务,它要求人工智能代理可以与人类进行有意义的对话,并用自然的、对话的语言讲述视频中内容。具体地说,给定一个图像、对话历史(由图像标题和先前的问题和答案组成),代理必须在对话框中回答后续问题。想要在这个任务中有和良好的表现,代理不仅需要在可视内容中进行查询而且也要在对话框历史中进行查询。
相信下一代智能系统需要具备这种能力,为各种应用程序举办关于视觉内容的对话竞赛,我们鼓励团队参与,并帮助推动这个令人激动的领域的最新进展!
▌数据集
在6月30日,EvalAI公开发布了 VisDial 数据集,挑战赛将在 v1.0上进行,该数据集基于 COCO 图像。
训练集:1,23,287张图片 * 10轮对话
验证集:2,064张图片 * 10轮对话
测试集:8,000张图片 * 1 轮对话
格式

▌竞赛指南
1.团队必须在EvalAI上注册并创建一个挑战团队
快速入门:
https://evalai.readthedocs.io/en/latest/participate.html
竞赛页面:
https://evalai.cloudcv.org/web/challenges/challenge-page/103/overview
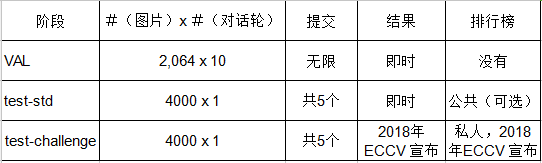
竞赛阶段
▌入门代码
从 Visual Dialog 论文中提供了 Lua Torch实现 的模型。这包括 VisDial v1.0的dataloaders,预训练模型,以挑战提交格式保存结果的脚本,以及训练自己模型的代码。另外,在 PyTorch中 提供 入门代码。代码非常适合用作Visual Dialog挑战训练模型的样板。
更多竞赛信息与资源可以参考链接:
https://visualdialog.org/
▌干货分享
虽然这个领域还有更多的研究在等着大家去做,但是近几年的研究论文还是值得大家关注和阅读的,特此人工智能头条为大家整理了几篇论文让大家可以进行参阅与学习。
Are You Talking to Me? Reasoned Visual Dialog Generation through Adversarial Learning(CVPR 2018)
Learning Cooperative Visual Dialog Agents with Deep Reinforcement Learning(ICCV 2017)
Image Question Answering using ConvolutionalNeural Network with Dynamic Parameter Prediction. (CVPR 2016)
Ask Me Anything: Free-form Visual QuestionAnswering Based on Knowledge from External Sources(CVPR 2016)
Visual7W: Grounded Question Answering inImages (CVPR 2016)
Dynamic Memory Networks for Visual andTextual Question Answering
Ask Your Neurons: A Neural-based Approach toAnswering Questions about Images. (ICCV 2015)
Learning Cooperative Visual Dialog Agents with Deep Reinforcement Learning
Learning to Reason: End-to-End Module Networks for Visual Question Answering
Visual Question Answering: A Survey ofMethods and Datasets
Visual Question Answering: Datasets,Algorithms, and Future Challenges
——【完】——
在线公开课NLP专场
◆
精彩继续
◆
时间:7月12日 20:00-21:00
扫描海报二维码,免费报名
添加微信csdnai,备注:公开课,加入课程交流群

点击 | 阅读原文 | 免费报名





