【泡泡图灵智库】一种基于多假设的视觉和惯导数据流相融合的深度神经网络(arXiv-21)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Multi-Hypothesis Visual-Inertial Flow
作者:E. Jared Shamwell, William D. Nothwang, Donald Perlis
来源:arXiv2018
播音员:堃堃
编译:杨小育(硕士,中国科学院大学深圳先进技术研究院,计算机技术专业,研究方向:无人驾驶的避障、轨迹规划)
审核:皮燕燕
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——一种基于多假设的视觉和惯导数据流相融合的深度神经网络,该文章发表于arXiv2018 。
图像序列间的像素的对应关系估计是视觉导航(如VO、VIO和VSLAM)的关键一步。我们设计了一个名为视觉惯性流(VFlow)的无监督深度神经网络,在接收到灰度图像和惯导元件的测量信息后,通过基于多假设的无监督神经网络方法对图像间的对应关系进行估计。VIFlow在学习异构传感器的信息流和来自未知的非参数化噪声分布的样本后,将源图像和目标图像像素间的对应关系生成若干(4或8个)可能的假设。我们把VFlow和几种仅基于视觉的图像稠密对应关系估计方法进行定量比较,实验结果表明VIFlow显著提高了运算效率、减少了运行时间。最后我们也做了定性比较,以展示VFlow如何检测异常独立运动.
主要贡献
1、 使用视觉以外的传感器信息来估计图像间的对应关系。
2、可以估计异常的独立运动。
3、不需要提前校准传感器,和现有仅使用视觉的方案相比,运行速度更快,效率更高。
算法流程
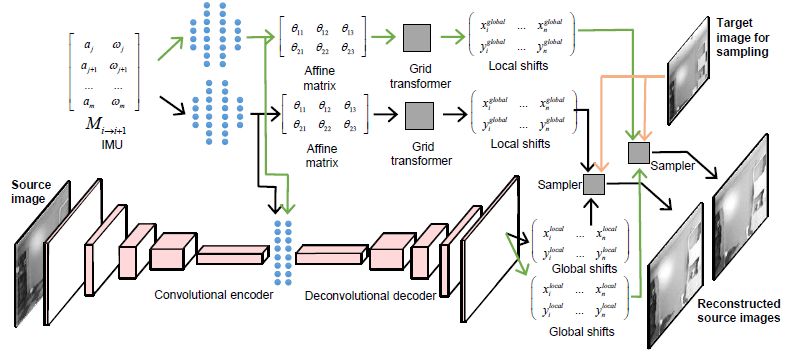
图1 VIFlow的结构图
1、Winner-Take-All (WTA)损失函数规则
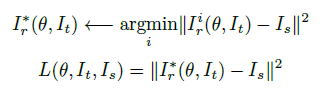
Ir*是最小误差假设,误差仅在这一路径进行反向传播,仅更新获胜的这一路的参数,另一路的参数保持不变。
2、路径一:全局转换机制
图1中的上半部分为该路径,在给定IMU的数据后,通过若干的全连接层,经过学习计算2D仿射变换矩阵的参数后,把3D变换近似成2D变换,最后使用该2D变换生成H×W×2形式的坐标变化量。
3、路径二:局部转换机制
图1中的下半部分为该路径,以原图像作为输入,使用自动编码解码网络产生H×W×2形式的像素位移,用来补偿全局路径中估计的像素位移。
4、空间变换
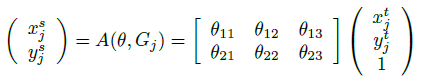
(Xti,Yti)是输出特征图中的目标坐标,(Xsi,Ysi)是输入特征图中的源坐标,θ并且是2D仿射变换矩阵
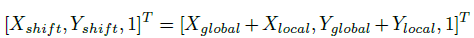
[Xlocal,Ylocal,1 ] 是局部路径计算出的坐标,[xGlobal,Yglobal,1 ] 是全局路径计算出的坐标,最终VFlow生成的最终坐标为[Xshift,Yshif,1 ]
主要结果
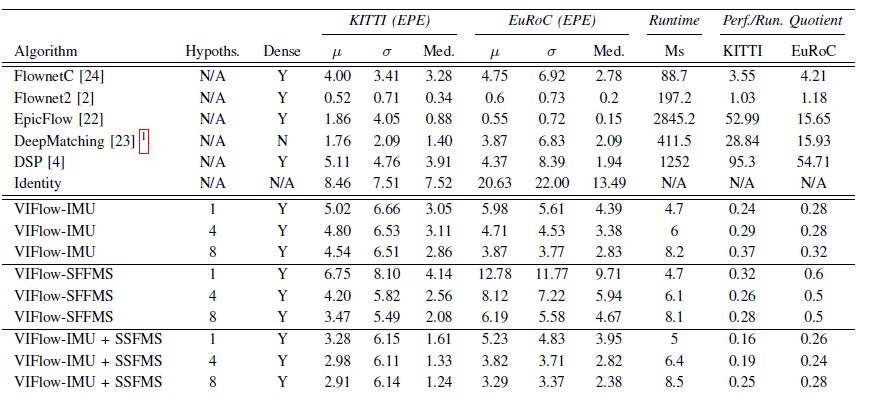
图2 VFlow与Flownetc,Flownet2,Epicflow,Deepmatching、DSP在KITTI数据集和EuRoC数据集上的实验结果

图3 异常独立运动的检测,可以发现远处物体引起的模型误差可能会影响独立运动在最后一行的残差

Abstract
Estimating the correspondences between pixels in sequences of images is a critical first step for a myriad of tasks including vision-aided navigation (e.g., visual odometry (VO), visual-inertial odometry (VIO), and visual simultaneous localization and mapping (VSLAM)) and anomaly detection. We introduce a new unsupervised deep neural network architecture called the Visual Inertial Flow (VIFlow) network and demon-strate image correspondence and optical flow estimation by an unsupervised multi-hypothesis deep neural network receiv-ing grayscale imagery and extra-visual inertial measurements. VIFlow learns to combine heterogeneous sensor streams and sample from an unknown, un-parametrized noise distribution to generate several (4 or 8 in this work) probable hypotheses on the pixel-level correspondence mappings between a source image and a target image. We quantitatively benchmark VIFlow against several leading vision-only dense correspondence and flow methods and show a substantial decrease in runtime and increase in efficiency compared to all methods with similar performance to state-of-the-art (SOA) dense correspondence matching approaches. We also present qualitative results show-ing how VIFlow can be used for detecting anomalous indepen-dent motion.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




