CVPR出了篇满分论文!中国小哥用人话为机器人导航,5000多篇论文里夺魁
安妮 乾明 发自 凹非寺
量子位 出品 | 公众号 QbitAI
CVPR 2019满分论文现身!
这篇论文,来自加州大学圣巴巴拉分校(UCSB)和微软研究院,题为Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation。
在CVPR 2019评审过程中,从5165篇投稿论文中杀出重围,得到3个Strong Accept,得分排名第一,被确定为口头报告论文。
UCSB计算机科学系助理教授王威廉在微博上透露了这一消息,论文的第一作者是其NLP组内同学王鑫。
有人评论称,最佳论文指日可待。
论文中,基于强化学习,提出一种使用自然语言指挥智能体行动的新方法,在基准数据集上评估,比现有最好的方法性能显著提高了10%。
引入了模仿学习后,极大地提升了智能体在不可见环境中的性能表现。
这一研究成果,如果用于现实世界中,将能够进一步提高家庭机器人以及个人虚拟助理的性能,只要你认识路,机器人就能根据你的描述,找到正确的路。行动会更加高效。
跨学科的攻坚战
要理解大牛论文的高明之处,这还得先从视觉语言导航(VLN)这个任务讲起。
在现实世界环境中,用自然语言为智能体指路,就可以理解为视觉语言导航。定义确实不难理解,但实际运行过程中,操作就复杂得多了:
既要求智能体对语言语义有深刻了解,还得对视觉感知问题信手拈来,最重要的是还要将两者结合在一起解决现实世界的任务,这是一场横跨NLP和CV双学科的攻坚战。
而现实世界的具体任务总是略显艰难,下图显示的就是一个VLN任务。
在这个任务中,AI接收到的是“向右走,走向厨房,之后左转,经过一张桌子后进入走廊”等一系列自然语言指令,它看到的是一部分空间中的场景,但需要分析语言中对应的物体即动作,还要脑补出整张空间图。
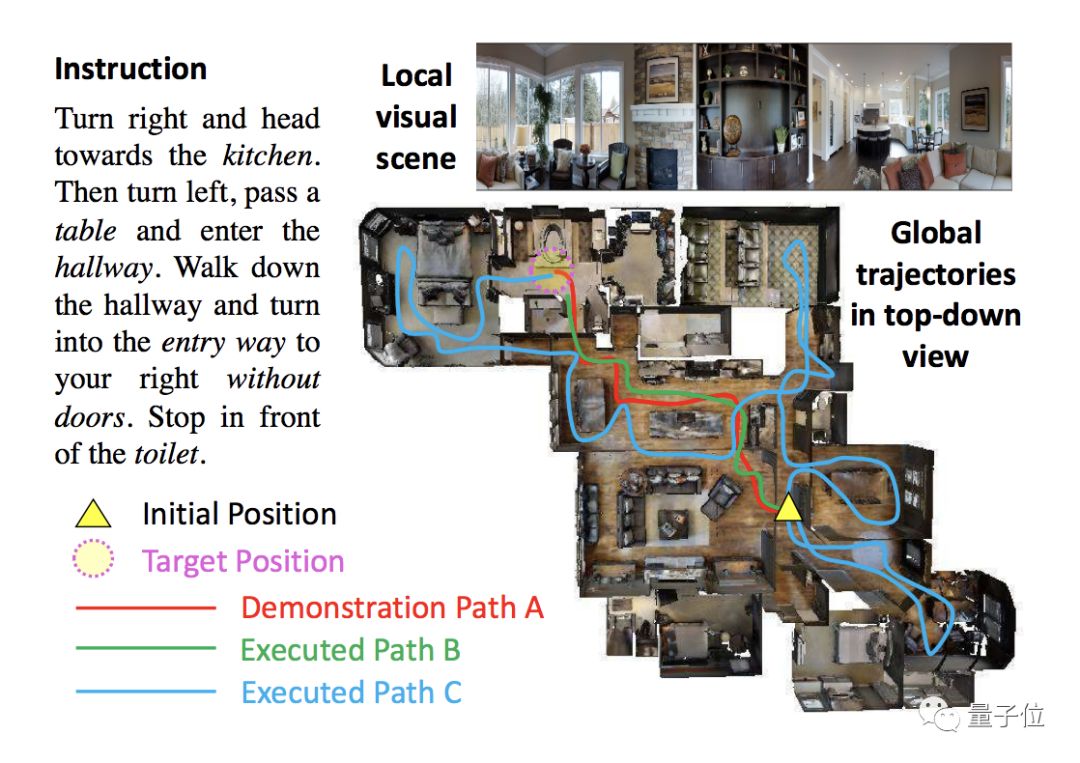
△ VLN任务案例:图中包含语言指令,局部视觉场景和俯视视角的整体行进轨迹
难就难在了这些地方,以往的研究中,研究人员发现了三大棘手的挑战:
一是,将视觉图像与自然语言描述对应的场景对应结合本身就不容易。
二是,整个任务的反馈机制相当粗糙,只有最后到达了目的地才会提示任务完成,智能体是否是按照指令去做的难以判断。
三是,由于智能体所在的环境差别很大,VLN任务难以泛化。
总而言之,解决VLN任务不仅需要具备CV与NLP两个领域的知识,而且整个过程可能反馈寥寥,模型对新鲜样本的适应能力又差,可谓困难重重,无从下手……
但难不倒大神。
基本原理
怎样让智能体听着人类的语言,在迷宫一样的空间里找到正确的方向?
这篇满分论文将强化学习(RL)和模仿学习(IL)知识结合,提出了新型强化跨模态匹配(Reinforced Cross-Modal Matching,RCM)模型,通过强化学习方法联系看得到的局部和看不见的全局场景。
在RCM模型中,推理导航器(Reasoning Navigator,下图中绿色框)是一个中心角色。通过学习文本指令和局部视觉图像中跨模态场景,让智能体推断潜在指令,明白到底应该向哪看。
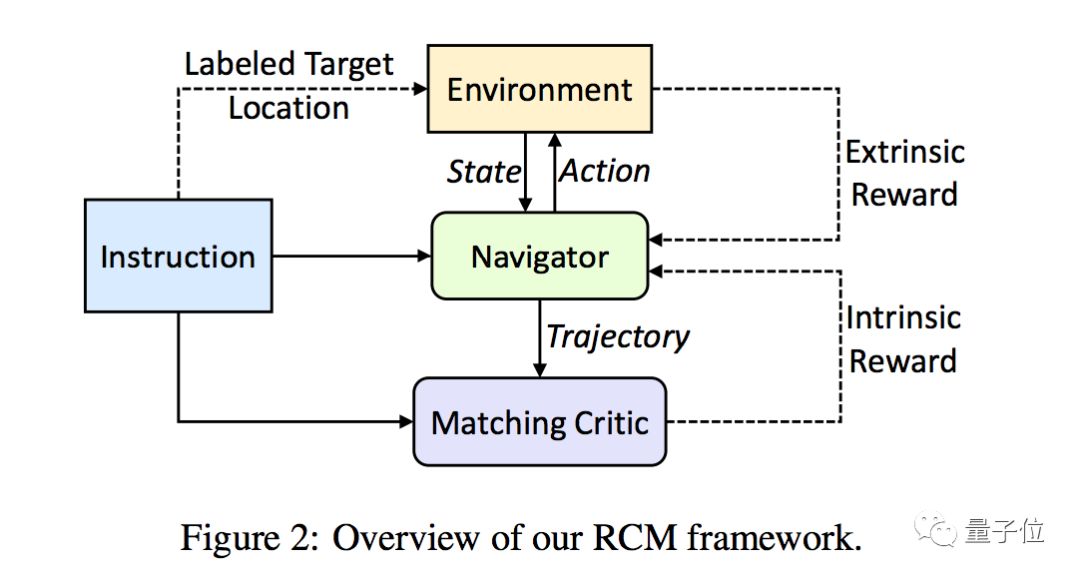
在全局场景中,研究人员还设置了Matching Critic(上图中紫色框)来评估从原始指令中重建场景执行情况,并且设置了循环重建奖励。
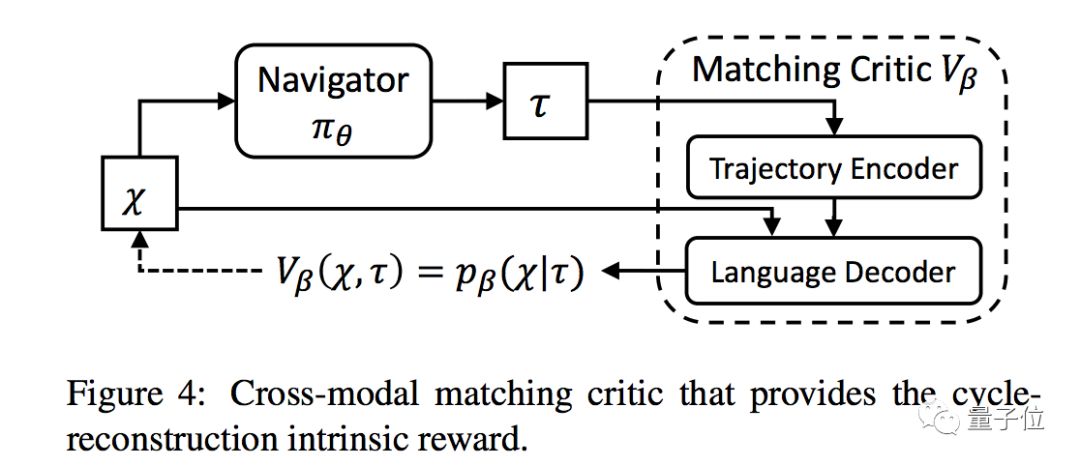
对于局部场景来说,这种循环重建奖励就是一种内部奖励信号,帮助智能体理解语言输入,并且惩罚不符合语言指令的错误轨迹。
解决了最优线路的问题后,智能体少走了不少弯路,但研究人员的改造还在继续。
为了让智能体在杂七杂八的现实物体中专注于有用的场景,研究人员还提出了一种自监督模仿学习(Self-Supervised Imitation Learning,SIL)的新方法,帮助智能体探索未知场景中没有标注的数据。
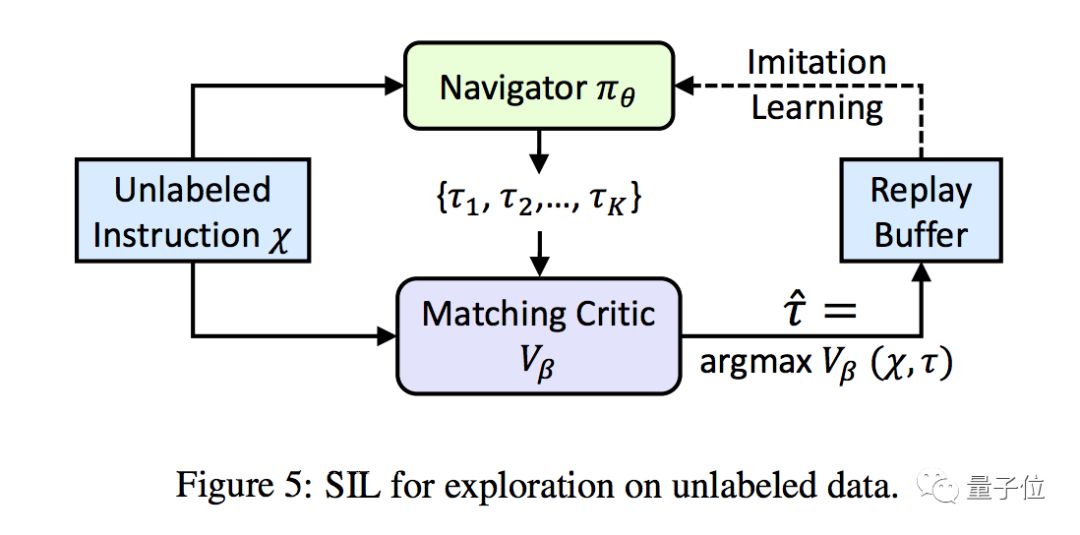
△ SIL架构
SIL方法就是让智能体学会利用走过的老路中获取的经验。
简单来说,在这个框架中,导航器(Navigator)执行多种rollout,将其中评估出的比较好的轨迹存储在缓冲区,方便导航器在后面的路径中模仿。
这样,导航器在行进中就能逐步接近最好的路径,规划出最佳决策。
测试结果
论文中,使用R2R(Room to Room)数据集评估模型性能。这个数据集中,共有7189条路径,21567条人工注释指令,平均长度29个单词。
在评估VLN性能时,主要有5个指标,分别是路径长度(PL)、导航误差(NE)、Oracle成功率(OSR)、成功率(SR )和由反向路径长度加权的成功率(SPL)。
在这些指标中,SPL兼顾了有效性和效率,被认为是评估导航性能的主要标准,其他的指标通常被作为是辅助指标。
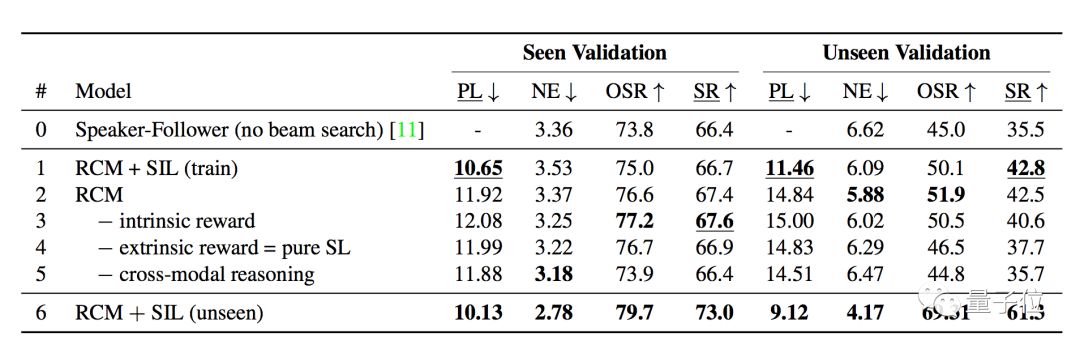
评估结果显示,RCM模型显著优于当前最优结果(SOTA),尤其在SPL指标上。
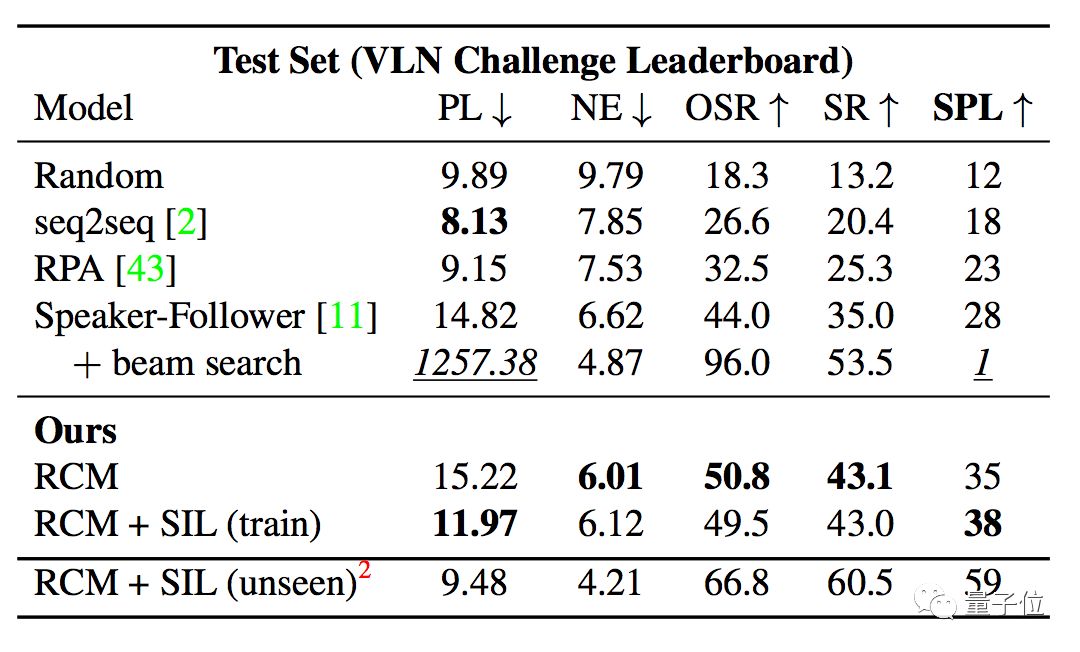
此外,使用SIL进行模仿学习之后,学习效率也得到了大幅度提升,可见和不可见环境之间的成功率差距从原来的30.7%降低到11.7 % 。
出自何人之手?
这篇论文的作者,一共来自3个单位。分别是UCSB、微软雷蒙德研究院和杜克大学。
论文第一作者王鑫,2015年本科毕业于浙江大学,正在UCSB攻读博士学位,研究方向为自然语言处理、计算机视觉和机器学习。

2017年至今,有7篇一作论文被人工智能领域顶级会议收录,其中有3篇是口头报告论文。
在2019年顶级会议上,也开始做一些审稿工作:AAAI 2019 自然语言处理领域的Session Chair;ICCV 2019, CVPR 2019的审稿人。
不只是在学术界,王鑫在业界也开始崭露头角。
2016年夏季和2017年夏季在Adobe Research实习,参与众多项目。
其中关于“删除视频中不需要的对象”研究,登上了Adobe 2017年的MAX Sneak大会,并在2018年的MAX进行了主题演讲。
另一项关于实时进行高分辨率风格迁移的研究,已经应用到了旧金山de Young博物馆,并向Adobe CEO Shantanu Narayen面对面展示产品原型。
2018年夏季,在微软雷蒙德AI研究院实习,2019年夏季,将会前往位于山景城的谷歌AI进行实习。
其他作者
两位来自UCSB的作者,分别是Yuan-Fang Wang和William Yang Wang(王威廉),是王鑫在UCSB的导师。
有四位作者来自于微软,分别是Lei Zhang、Jianfeng Gao、Asli Celikyilmaz和Qiuyuan Huang,是他在2018年夏季于微软实习时的导师。
还有一位来自杜克大学,名为Dinghan Shen,在2018年夏季与王鑫一同在微软实习。
传送门

Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation
https://arxiv.org/abs/1811.10092
历届CVPR优秀论文
CVPR,作为计算机视觉领域顶级学术会议,历届优秀论文可以说是学术研究风向标。
今年这篇关于视觉语言导航任务的论文的得到评审青睐,被满分接受。足以反映出当前计算机视觉方向与自然语言处理方向的合作正在受到欢迎。
2018年获得最佳论文的是Taskonomy: Disentangling Task Transfer Learning,来自斯坦福大学和加州大学伯克利分校。

这篇论文研究的是各种计算机视觉任务在迁移学习中的依存关系,提出了一个感知任务迁移学习的计算分类地图(computational taxonomic map),能够根据各种任务的相关性,来决定迁移学习方案。
对于一组10种任务,他们的模型能在保持性能几乎不变的情况下,将对标注数据的需求降低2/3。
传送门:
Taskonomy: Disentangling Task Transfer Learning
https://arxiv.org/abs/1804.08328
2017年,有两篇最佳论文。
一篇是Densely Connected Convolutional Networks,作者来自清华大学、康奈尔大学和Facebook等。

提出了一个叫做DenseNet的模型,让CNN中的每一层都以前馈的方式和所有其他层相连。
这个模型,有多方面的优点,不仅减轻了梯度消失问题、加强了特征传播,还能鼓励特征复用、减少参数数量。
传送门:
Densely Connected Convolutional Networks
https://arxiv.org/abs/1608.06993
另一篇是Learning from Simulated and Unsupervised Images through Adversarial Training,来自苹果。

提出了模拟+无监督(S+U)学习模型,通过非标注的真实数据来学习一个模型,以增强模拟器输出的真实性,同时保留模拟器中的标注信息。
这种方法能够生成高真实度的图像,在没有任何真是标注数据的情况下,在MPIIGaze数据集上获得了最高水平的结果。
传送门:
Learning from Simulated and Unsupervised Images through Adversarial Training
https://arxiv.org/abs/1612.07828
最后,CVPR 2019 将于6月16日-6月20日于洛杉矶长滩市举办,王鑫同学的这篇满分论文,能否获得最佳论文?届时将会揭晓。
— 完 —
一份小调查
大噶好,
为了了解大家感兴趣的话题,丰富我们的报道内容,带来更好的阅读体验,请大家帮我们填一份调查问卷鸭,扫码即可进入问卷页面。
笔芯。( ̄︶ ̄)➷➷➷


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !



