学界 | CVPR 2018接收论文公布,上海交通大学6篇论文简介
机器之心报道
作者:吴欣
不久之前,CVPR 2018 论文接收列表公布。据机器之心了解,上海交通大学电子系人工智能实验室倪冰冰教授课题组有 6 篇论文入选,本文对这几篇论文做了简介,更多详细内容可通过论文网盘链接下载查看。
CVPR 2018 论文接收列表:http://cvpr2018.thecvf.com/files/cvpr_2018_final_accept_list.txt
Paper 1:《Fine-grained Video Captioning for Sports Narrative》
细粒度视频描述——体育视频自动解说
网盘链接:https://pan.baidu.com/s/1miUzoCC
视频描述方向的研究在近段时间取得了较大的进展,但是一直都停留在粗略的视频内容讲述上,没有做到对于人物交互关系和动作细节的细致描述,而这些恰恰都是体育视频中非常重要的部分。在这篇 CVPR 工作中,作者提出了一个全新的细粒度视频描述课题,做出了一个对应的体育视频细粒度描述数据集,并用一个完善的视频描述网络解决了该问题,实现了国际首次人工智能体育视频自动解说。

体育视频自动解说效果展示。所有球员的角色、关系和位置,及球的位置都实现了准确的理解识别。相比较传统的「一群人在打篮球」的粗略描述,这篇文章实现的描述更加细致、准确,可以全面真实地反映运动场上的实际情况。
在文章中,作者通过一个时域-空域定位子网络来进行动作片段的分割和球员角色的定位;通过一个引入骨骼信息的细粒度动作识别子网络来精确地识别球员在高速运动中做出的细小动作;再通过一个群体交互子网络来构建球员间的交互关系。通过以上三个子网络捕获充足全面的视频特征,从而输出准确的细粒度视频描述语句。
此外,文章中提出的细粒度体育视频自动解说数据集(FSN dataset)也将会在不久后公开供科研使用,以促进细粒度视频描述领域的技术发展。
Paper 2:《Structure Preserving Video Prediction》
面向保持结构一致性的视频预测模型
网盘链接:https://pan.baidu.com/s/1kWUb4c3
像素级的视频生成一直是计算机视觉领域的热点问题。过去的方法一直试图解决所预测的视频中存在的运动模糊问题。这个问题一方面由随时间增加所带来的累计误差引起,另一方面由于像素级的视频生成的解空间非常巨大。这里将像素级的视频生成一直存在的两个问题总结如下:
静态结构预测损失 这个问题来源于预测具有固定结构的场景,城市景观中的交通标志、树木等任务。这些静态结构的运动常常是由相机运动引起的。现有方法的预测结构大多不能保持原始对象结构,例如物体的边缘结构信息。
动态结构预测损失 虽然最近的一些工作可以预测一般粗粒度运动。但是一般不能精确预测精细的局部运动,如人体关节运动。
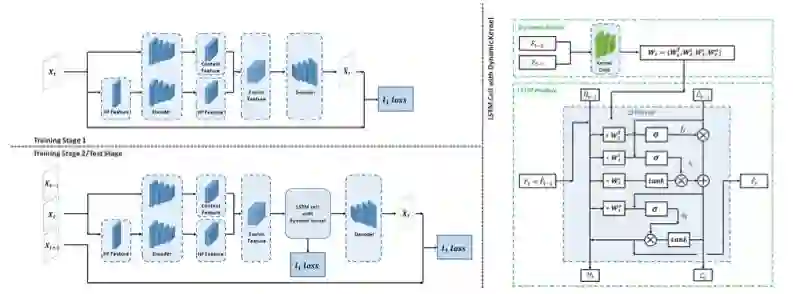
论文提出的视频预测模型图示。该架构使用论文提出的多频带分析和时变卷积核技术,能够更大限度的利用输入信息和更灵活的应对视频内容的动态变化,使得更精确地预测像素级的视频内容成为可能。
在这篇文章中,作者提出基于多频带分析和时变卷积核的视频预测模型来解决上述两个问题。一方面作者将输入视频分解为多个频率分量分别进行处理,以求从原始视频中获取尽可能多的物体静态结构信息,称之为多频带分析;另一方面作者利用输入视频帧来生成最终预测模型中的卷积核,以求能够更灵活的应对动态结构预测任务,称之为时变卷集核。两个方法分别较好地解决了上述两个问题,显著提高了视频预测精度。
Paper 3:《Multiple Granularity Group Interaction Prediction》
基于多粒度的群体交互预测
网盘链接:https://pan.baidu.com/s/1i6HovGh
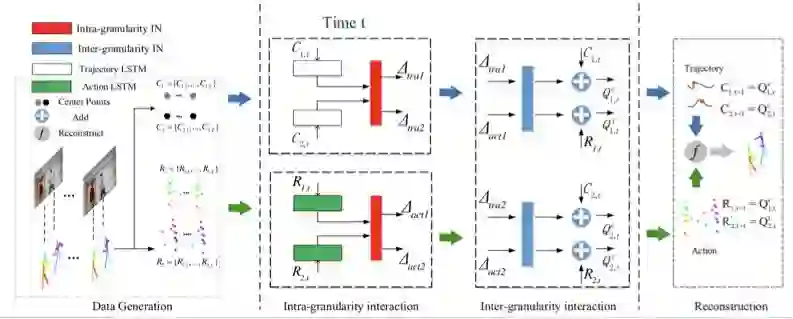
多粒度群体交互预测框架。首先我们把骨架序列处理成两个不同粒度的信息,分别代表整体轨迹运动和肢体细节运动。基于 seq2seq 预测结构,我们设计了同粒度间信息交互子网络来考虑群体之间的相互影响,以及不同粒度间的信息交互子网络来促进两个粒度上信息的交互,更准确地预测结果。最后整合预测出的两个粒度信息,展示群体交互预测结果。
当前大多数人体活动分析(识别或预测)的工作仅关注于单个粒度,例如在粗粒度层次对整体运动进行建模(轨迹预测);或者在细粒度层次对肢体细节运动进行建模(骨骼动作预测)。相反,在这项工作中,作者提出了多粒度群体交互预测网络,能够同时考虑两个粒度上的信息(整体轨迹和细节动作)。首先对于每个人的骨架运动序列,作者把它处理成能够分别代表轨迹运动和肢体运动的两个粒度上的运动序列。对于每个粒度上的信息,基于 seq2seq 网络结构,作者设计了同粒度间的交互网络,在预测每个人这个粒度上的运动信息时能够考虑其他人的运动信息。同时,基于双向 LSTM,作者设计了不同粒度间的信息交互网络,来促进每个人的不同粒度上信息的交互,更准确地预测未来轨迹和细节动作。最后作者把两个粒度上的信息整合在一起,多景观式地展示预测的群体交互。此方法在 SBU 和 Choi's New Dataset 数据集上都取得了目前最佳效果。
Paper 4:《pose transferrable person re-identification》
姿态可迁移行人再识别
网盘链接:https://pan.baidu.com/s/1nwFetDZ
行人再识别旨在解决跨时空匹配行人的问题,其在智能安防领域有极大的应用价值。由于行人姿态、外观、光照、遮挡等因素的影响,行人再识别仍然是一项极具挑战性的任务。为了解决行人姿态变化丰富导致模型难以在有限训练集下获得良好性能的问题,作者在这篇 CVPR 的工作中提出了一个姿态可迁移的行人再识别模型。
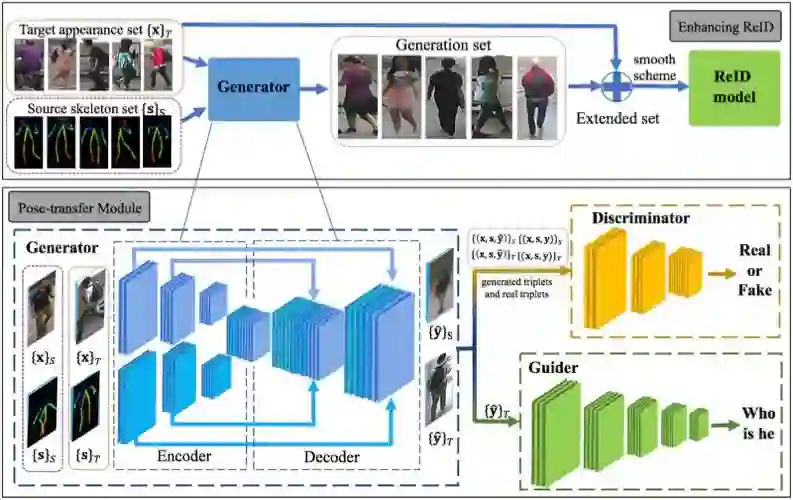
姿态可迁移行人再识别框架。首先训练姿态迁移模块,其中我们引入了「向导」子模块来提升生成器的性能。然后使用训练好的生成器实现行人姿态由源数据集到目标数据集的迁移,进而提升行人再识别在目标数据集上的性能。
假设给定大小两个数据集,分别称为 A 和 B。其中数据集 A 中覆盖的行人姿态少,而 B 中的样本包含丰富的姿态。作者提出将数据集 A 中的图片样本与数据集 B 中样本的骨架进行配对,并通过 Skeleton-to-Image 模型生成与 A 中样本共享身份信息且与 B 中样本共享姿态的新样本集 C。为了提高生成样本的质量,作者提出了一个与对抗生成网络中的判别器平行的向导模块。向导模块是一个预训练好的行人再识别模型,用于指导生成器生成包含更丰富身份信息、更适应行人再识别任务的样本。在得到了生成样本集 C 后,作者将其与数据集 A 混合并通过平滑机制分配样本权重后训练模型。实验结果表明此方法能够与其他高性能方法 (包括特征学习、度量学习类方法) 结合并进一步提升它们的性能。
Paper 5:《Crowd Counting via Adversarial Cross-Scale Consistency Pursuit》
基于对抗跨尺度一致性追求的人群计数方法
网盘链接:https://pan.baidu.com/s/1mjPpKqG
作者提出了一个新的人群计数的网络结构 Adversarial Cross-Scale Consistency Pursuit Network,在四个公开的人群计数数据集上刷新了目前国际最佳的计数精度。人群计数任务是一个极具挑战的任务,原因在于其存在场景变化跨度大、目标空间尺度变化大、人群之间存在严重遮挡等困难。现有的方法存在以下两个缺陷:一、由不同大小的卷积子构成的多通道卷积网络融合得到的图像多尺度特征,再经传统的欧式损失(L1/L2)回归用来计数的人群密度图会导致密度图模糊,同时由于在网络中使用池化层,大大降低了密度图的分辨率,给最终的计数带来误差;二、输入一张图像计算得出的人数与将此图像分割成 4 份分别输入得到的总人数存在差异,此即为跨尺度统计不一致带来的误差。

基于对抗跨尺度一致性追求网络的结构图,两种尺度的生成器 G/判别器 D 利用跨尺度一致性损失实现联合训练。
针对以上两点,作者提出了基于生成对抗网络的跨尺度结构模型,其中对抗损失的引入使得生成的密度图更加尖锐,U-net 结构的生成网络保证了密度图的高分辨率,同时跨尺度一致性正则子约束了图像间的跨尺度误差。因此,该提出的模型最终能生成质量好分辨率高的人群密度图,从而获得更高的人群计数精度。
Paper 6:《Scale-Transferrable Object Detection》
基于尺度变换模块的物体检测器
网盘链接:https://pan.baidu.com/s/1i6Yjvpz
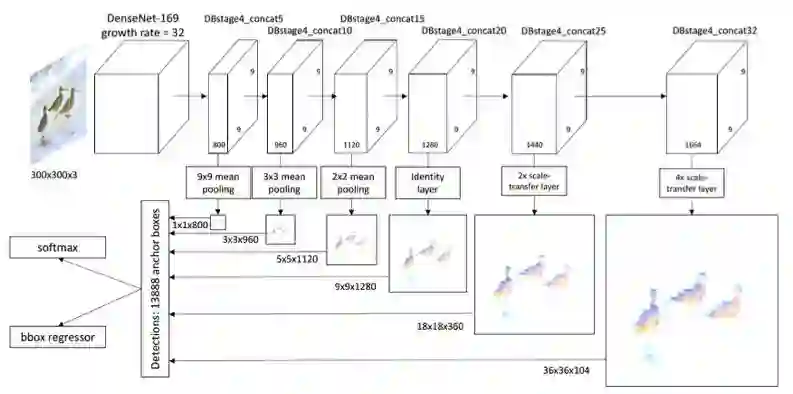
基于尺度转移模块的物体检测。尺度转移模块由简单的 mean pooling 层和尺度转移层构成,被嵌入到 DenseNet 网络的最后一个模块中,从而得到不同分辨率的被用来做物体检测的特征图。尺度转移层可以有效地减少输入特征图的通道数,同时扩大其分辨率,不增加额外的计算开销。
作者构建了一个类似于 SSD 的一阶段物体检测器,称之为 STDN(尺度转移检测网络)。与 SSD 物体检测方法相比主要有两点不同,一是基础网络使用的是 DenseNet,二是作者使用了一个尺度转移模块来获得不同分辨率的特征图,这些特征图被用来做物体检测。这个尺度转移模块由 mean pooling 层和像素重排层构成。Mean pooling 层用来获得低分辨率的特征图;像素重排层通过压缩特征图的通道数来扩大特征图的分辨率,没有额外的计算开销。尺度转移模块可以直接嵌入到 DenseNet 网络中,不需要在 DenseNet 网络之后添加额外的层就能获得多尺度的特征图。而且像素重排层可以有效地压缩 DenseNet 网络特征图的通道数,从而减少之后卷积层的参数数量。作者在 pascal voc07 和 coco 数据集上取得了不错的检测性能,对构建开销较小的物体检测器具有一定的启发意义。
注:上海交通大学电子系人工智能实验室由倪冰冰教授、徐奕教授领衔,杨小康教授、张文军教授指导

本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


