

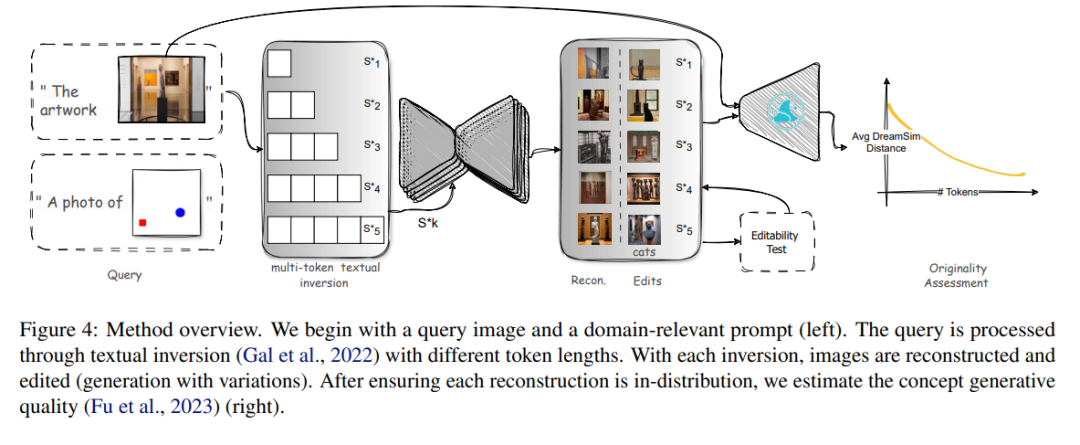
本研究针对文本到图像(T2I)生成扩散模型中的原创性量化挑战,特别是聚焦于版权原创性。我们首先通过控制实验评估了T2I模型的创新和泛化能力,揭示出稳定扩散模型在训练数据足够多样化的情况下能够有效地再现未见过的元素。我们的核心见解是,模型熟悉并在训练中频繁看到的概念和图像元素组合在模型的潜在空间中具有更简洁的表示。因此,我们提出了一种利用文本反转来测量图像原创性的方法,基于模型重建图像所需的词元数量来评估原创性。我们的方法受法律定义的原创性启发,旨在评估模型在不依赖特定提示或不需要模型的训练数据的情况下,是否能够生成原创内容。我们通过一个预训练的稳定扩散模型和一个合成数据集演示了我们的方法,展示了词元数量与图像原创性之间的关联性。这项工作有助于理解生成模型中的原创性,并对版权侵权案件具有重要意义。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日