
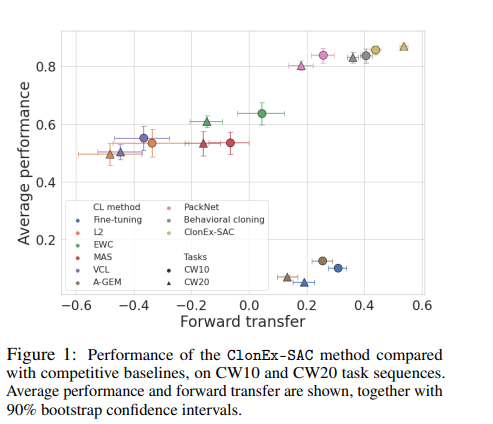
持续学习系统从以前看到的任务中迁移知识,以最大限度地提高新任务的性能的能力,是该领域的一个重大挑战,限制了持续学习解决方案对现实场景的适用性**。因此,本研究旨在拓展我们对持续强化学习中迁移及其驱动力的理解**。我们采用SAC作为底层RL算法,连续世界作为一组连续控制任务。我们系统地研究了SAC的不同组成部分(参与者和批评者、探索和数据)如何影响传输效果,并提供了关于各种建模选项的建议。最好的一组选择被称为ClonEx-SAC,是根据最近的Continual World基准进行评估的。ClonEx-SAC的最终成功率为87%,而PackNet的成功率为80%,是基准测试中最好的方法。此外,根据Continual World提供的度量,转移从0.18增长到0.54。
https://www.zhuanzhi.ai/paper/99cc5ece0419e33748b0af9d2cd8fdff
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2022年11月3日
Arxiv
23+阅读 · 2020年3月7日
Arxiv
34+阅读 · 2019年10月24日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月3日
Arxiv
23+阅读 · 2020年3月7日
Arxiv
34+阅读 · 2019年10月24日