

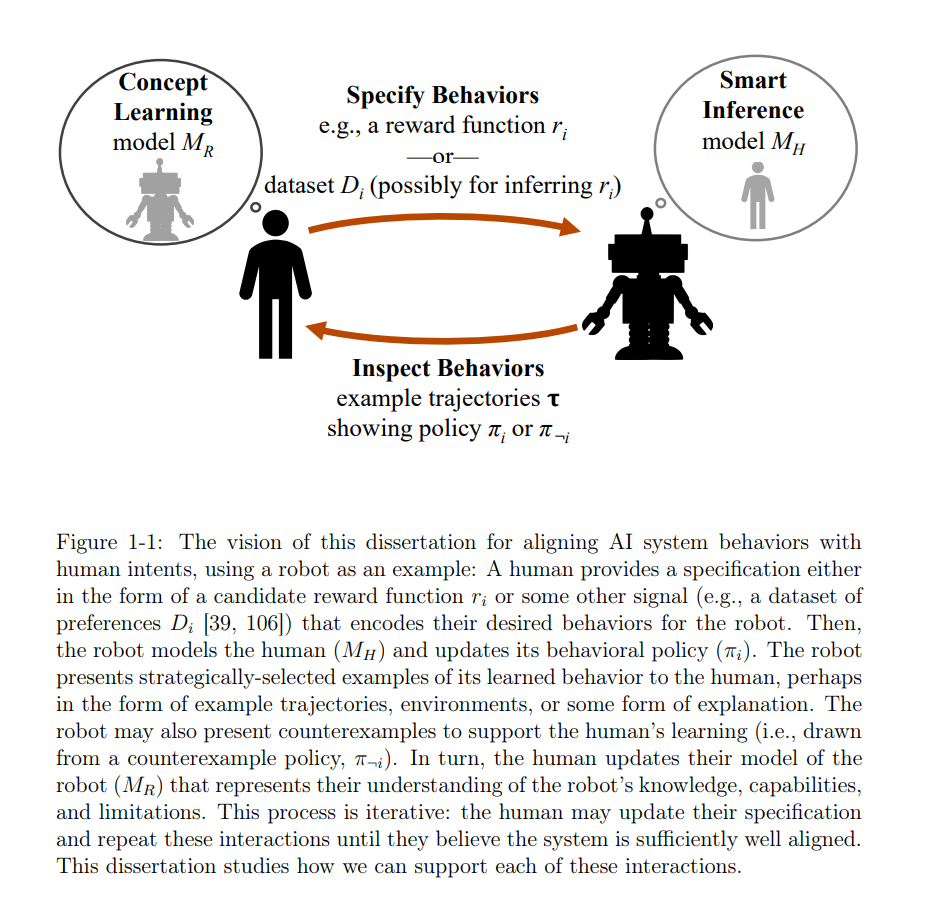
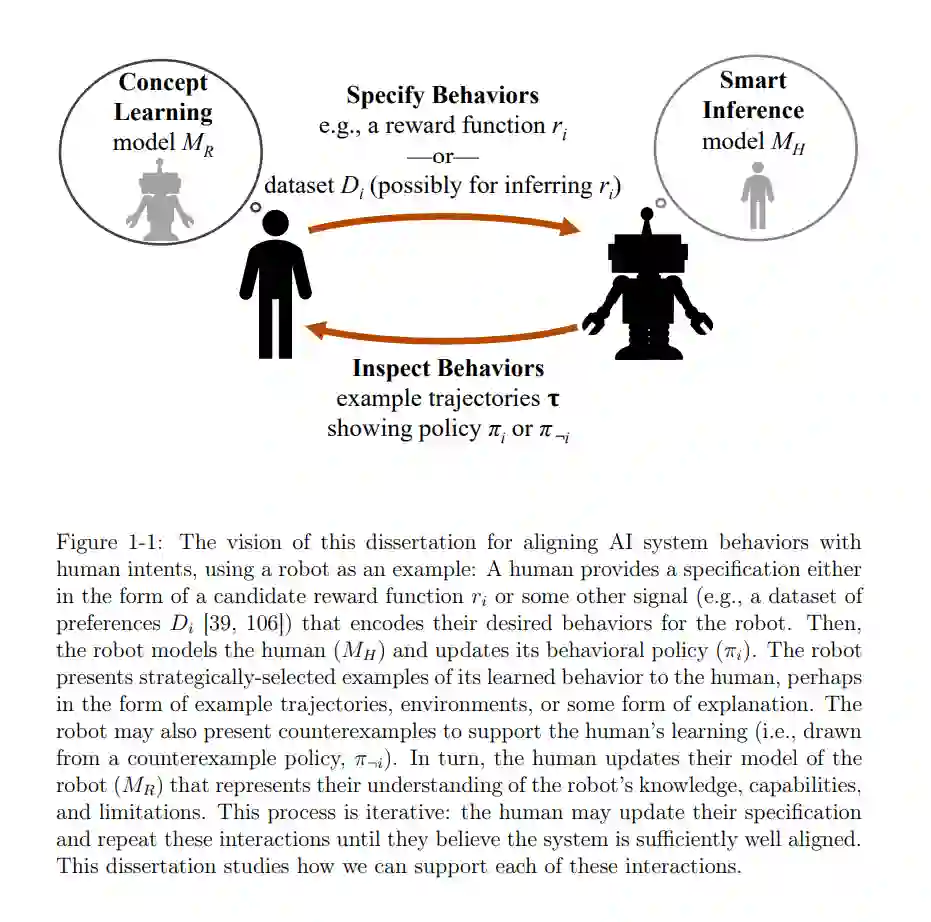
人工智能系统和机器人学习到的行为应当与其人类设计者的意图相对齐。为了达成这一目标,人们——特别是专家——必须能够轻松地指定、检查、建模和修订人工智能系统及机器人行为。这四种互动是人工智能对齐的关键构建模块。在这篇论文中,我研究了这些问题中的每一个。首先,我研究了专家如何为强化学习(RL)编写奖励函数规范。我发现这些规范是相对于RL算法编写的,并不是独立的,而且我发现即使在简单的设置中,专家们经常编写错误的规范,未能编码他们真正的意图。其次,我研究了如何支持人们检查代理的学习行为。为此,我引入了两种相关的贝叶斯推断方法,以找到引发特定系统行为的示例或环境;查看这些示例和环境有助于形成概念模型和系统调试。第三,我研究了认知科学理论,这些理论指导人们如何构建概念模型来解释观察到的代理行为示例。虽然我发现这些理论的一些基础被用于支持人类学习代理行为的典型干预中,但我也发现有很大的空间来构建更好的互动课程——例如,通过展示替代行为的反例。我通过推测这些人工智能交互的构建模块如何结合起来,使人们能够修订他们的规范,并通过这样做,创造更好对齐的代理来结束这篇论文。



成为VIP会员查看完整内容




相关内容

人工智能(Artificial Intelligence, AI )是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。 人工智能是计算机科学的一个分支。
Arxiv
86+阅读 · 2023年4月4日
Arxiv
153+阅读 · 2023年3月29日

相关VIP内容
相关资讯