【254页博士论文】《动态多目标环境中基于深度强化学习的智能决策方案》

摘要
第1章 简介
1.1 动机
1.2 目的和目标
1.3 研究问题
-
Q1: 提出的基准能否解决RL环境的DMOP研究领域的空白? -
Q2:基于DRL的算法如何处理多个目标并根据水质预测脆弱区域?
1.4 主要的科学贡献
1.5 测试案例
1.5.1 测试案例1
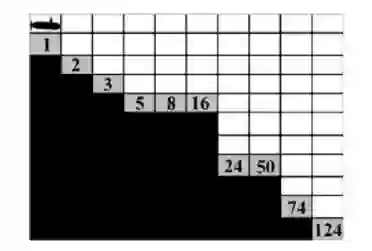
1.5.2 测试案例2
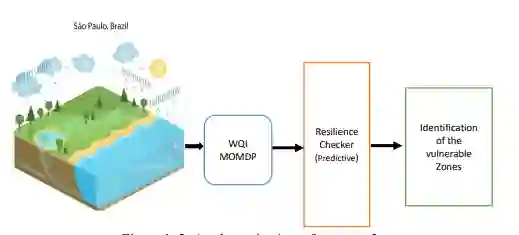
-
这是一个动态问题,考虑到水质数据因各种因素而随时间变化。 -
收集这些数据是昂贵的,需要人力资源。 -
由于手工检查和计算,识别脆弱区很困难。 -
针对不同区域的投资优化很复杂。 -
确定各区的优先次序以提高水质是非常耗时的。
1.8 论文的组织
便捷下载,请关注专知人工智能公众号(点击上方蓝色专知关注)
后台回复“IDMS” 就可以获取《【254页博士论文】《动态多目标环境中基于深度强化学习的智能决策方案》》专知下载链接



登录查看更多
相关内容
Arxiv
1+阅读 · 2022年11月21日
相关VIP内容
相关资讯
相关论文
Arxiv
1+阅读 · 2022年11月21日