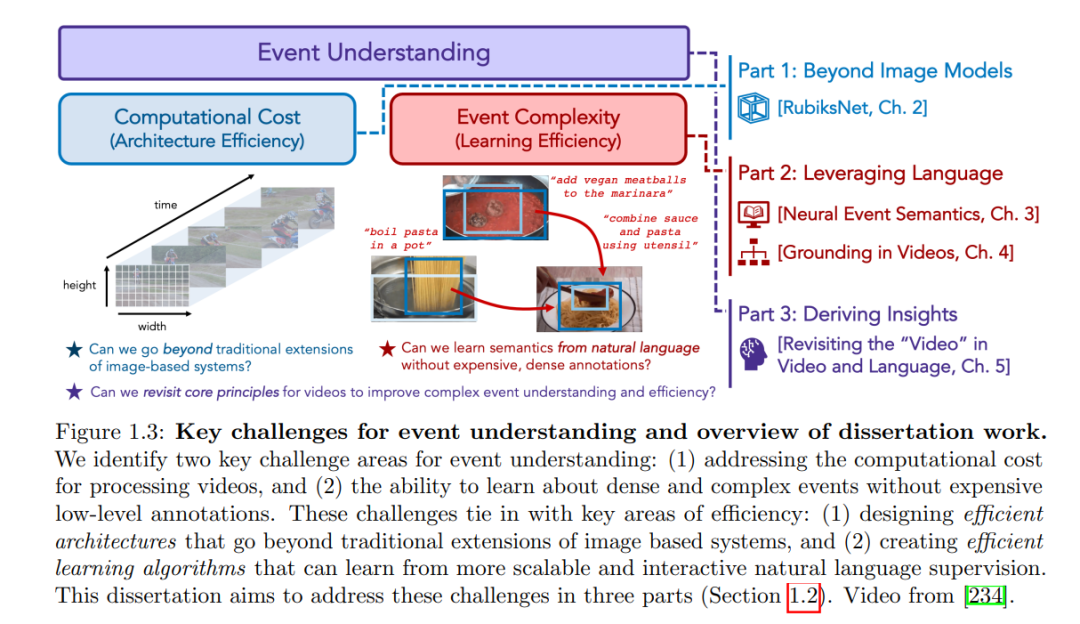
视觉世界为我们提供了一个丰富多样的有趣事件:人与物的互动、动态的视觉关系以及日常生活活动。理解它们对于发展真实世界中的交互式AI系统至关重要。然而,像人类那样从连续和高容量的感觉流中有效、高效地理解这些事件仍然是一个艰巨的任务。主要的挑战有两个方面。首先,视频在处理上是计算上的昂贵的;我们需要的不仅仅是为图像设计的系统的传统扩展。其次,视频捕捉了从低级动作基元到更高级的时空关系的广泛的事件复杂度;我们需要技术从自然语言中学习这些语义,而不需要昂贵、密集的注释。这篇论文提出了几个研究贡献,旨在应对这些挑战。首先,我们将讨论在视频中识别动作的新架构,这些架构学习如何分配固定的计算预算以提高效率和准确性,比传统技术提高了一个数量级。其次,我们将介绍新的框架,这些框架提高了我们从弱自然语言监督中高效学习密集视觉事件的能力,包括在语言结构不良或包含模糊指代的设置中。最后,我们将讨论如何利用多模态基础模型中的进展,通过一种新颖的技术揭示了更深入的时间事件理解以及提高效率的迫切挑战和机会的基本洞察。 视觉世界为我们呈现了一系列有趣的事件。如图1.1所示,我们可以观察到小规模的事件,如手势和人与物的互动(例如“将勺子放入杯子”,“调整门把手”等)。这些事件在复杂性和时间尺度上各不相同,包括更长期的日常生活活动(例如“制作美味的水果沙拉”),它们本身可能由更小的,时空重叠的事件组成。事件的范围从平凡的(例如“那里有一个苹果”)到深奥的(例如“一个苹果掉下来,打到一个物理学家的头上”)。事件可以在各种各样的环境中发生,从室内(例如“准备一餐”)到室外(例如“骑摩托车穿越丘陵道路”)。作为人类,我们经常认为理解这些事件是理所当然的[223]。我们(与许多其他生物共享的能力)处理视觉世界的原始、多模态的感知流、识别发生的明显的原子概念,并在空间和时间上关于这些概念之间的动态关系推理,以代表更高阶的意义,这无疑是非凡的。此外,这一能力,基本上是在进化的时间尺度上形成的[228],也以显著的效率和速度部署[22, 190, 45]。通过对事件的理解,我们能够有效地与视觉世界沟通、互动和学习[223]。

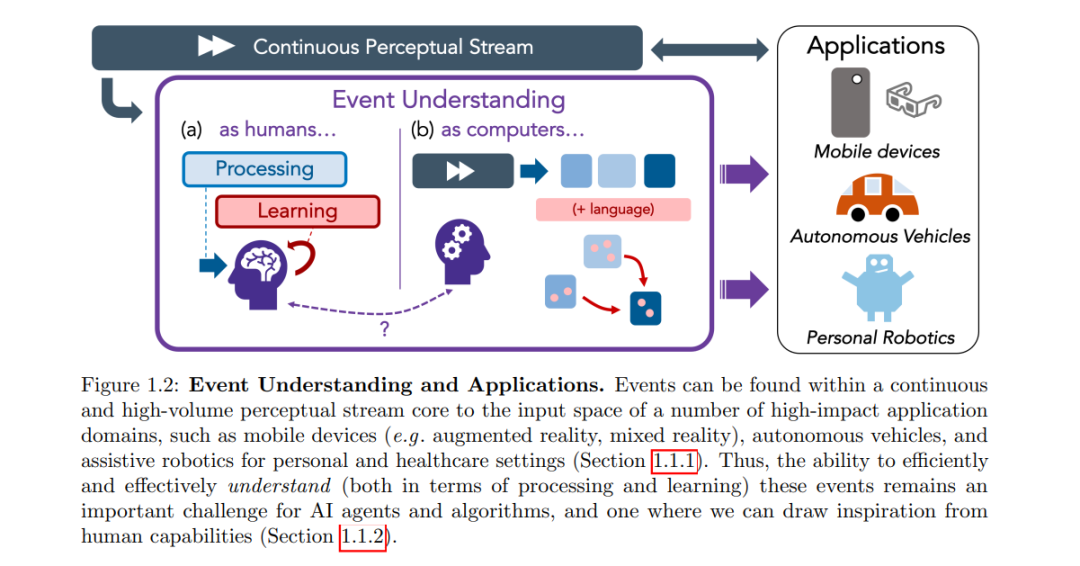
这些观察成为了计算机视觉和人工智能研究几十年的核心动机[172, 145, 46, 224, 52, 123] - 对于我们认为是不费吹灰之力的能力,它在计算模型中如此具有挑战性而难以完全复制,如[142]所指出,这似乎有些矛盾。然而,因为这是人类感知和认知的一个如此基本的方面,这样的系统的潜在应用范围是广泛的:自动驾驶汽车[219]、用于个人或医疗环境的辅助机器人[61, 1, 82],以及可以增强我们感官的混合现实移动设备[57],这只是其中的几个例子(见图1.2)。或许,解锁所有这些目标和应用上的颠覆性进展的关键在于为事件理解开发高效的计算系统?为此,我们对人类的事件理解进行了两次观察,这可以作为计算事件理解系统的指导原则。首先,我们必须寻求降低事件理解的处理成本,开发高效的算法来筛选这个视觉流(或视频)以理解其中的重要事件。其次,我们还必须努力处理事件的自然复杂性,开发可以像人类一样,既可以学习又可以推理更微妙的事件关系和动态的算法,并采用自然的监督形式。在下一小节中,我们将这两个观察与激发这篇论文工作的事件理解的持续挑战相联系。