推荐!《用于兵棋推演和建模的人工智能》兰德、耶鲁大学2022最新16页论文
在本文中,我们讨论了如何将人工智能(AI)用于政治-军事建模、仿真和兵棋推演,针对与拥有大规模杀伤性武器和其他高端能力(包括太空、网络空间和远程精确武器)国家之间的冲突。人工智能应该帮助兵棋推演的参与者和仿真中的智能体,理解对手在不确定性和错误印象中行动的可能视角、感知和计算。人工智能应该认识到升级导致无赢家的灾难的风险,也应该认识到产生有意义的赢家和输家的结果可能性。我们将讨论使用几种类型的AI功能对建模、仿真和兵棋的设计和开发的影响。我们在使用或没有使用AI的情况下,根据理论和使用仿真、历史和早期兵棋推演的探索工作,讨论了基于兵棋推演的决策辅助。

1 引言
在本文中,我们认为(1)建模、仿真和兵棋推演(MSG)是相关的调查方法,应该一起使用;(2)人工智能(AI)可以为每个方法做出贡献;(3)兵棋推演中的AI应该由建模和仿真(M&S)提供信息,而M&S的AI应该由兵棋推演提供信息。我们概述了一种方法,为简洁起见,重点是涉及拥有大规模毁灭性武器(WMD)和其他高端武器的国家的政治-军事MSG。第2节提供了我们对MSG和分析如何相互联系的看法。第3节通过讨论20世纪80年代的系统来说明这一点是可行的。第4节指出今天的挑战和机遇。第5节简述了结构的各个方面。第6节强调了在开发人工智能模型和决策辅助工具方面的一些挑战。第7节得出了结论。在本文中,我们用 "模型"来涵盖从简单的数学公式或逻辑表到复杂的计算模型的范围;我们用"兵棋"来包括从小型的研讨会练习(例如Day-After练习)到大型的多天、多团队的兵棋推演。
2 建模、仿真、推演和分析的集成视图
MSG可以用于广泛的功能,如表1所示。每种功能都可以由每个MSG元素来解决,尽管相对简单的人类活动,如研讨会兵棋和Day-After练习已被证明对后两个主题具有独特的价值。

通常形式的M&S和兵棋推演有不同的优势和劣势,如表2前三栏中的定型。M&S被认为是定量的、严格的和 "权威的",但由于未能反映人的因素而受到严重的限制。M&S的批评者走得更远,认为M&S的 "严格 "转化为产生的结果可能是精确的,但却是错误的。在他们看来,兵棋推演纠正了M&S的缺点。M&S的倡导者则有不同的看法。
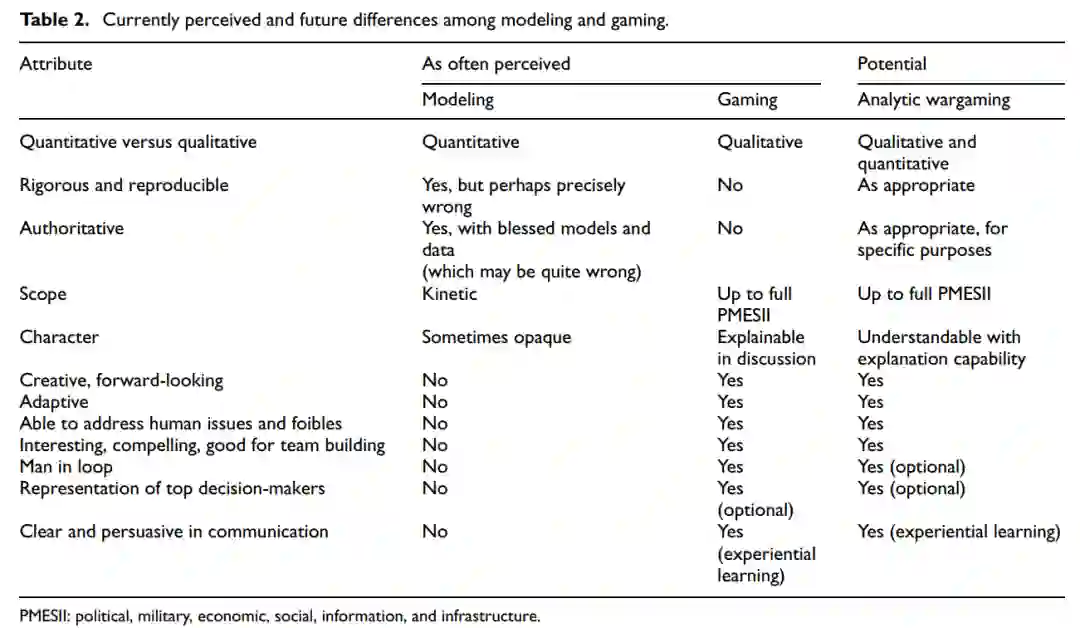
我们确实认识到并长期批评了正常建模的缺点。我们也从兵棋推演中受益匪浅,部分是通过与赫尔曼-卡恩(P.B.)、兰德公司和安德鲁-马歇尔的长期合作,但兵棋推演的质量从浪费时间甚至起反作用到成为丰富的洞察力来源。虽然这种见解在没有后续研究的情况下是不可信的,但来自建模的见解也是如此。
我们本文的一个论点是,这种刻板印象不一定是正确的,我们的愿望(不加掩饰的崇高)应该是表的最后一栏--"拥有一切",将建模、仿真和推演整合在一起。图1显示了一个相应的愿景。
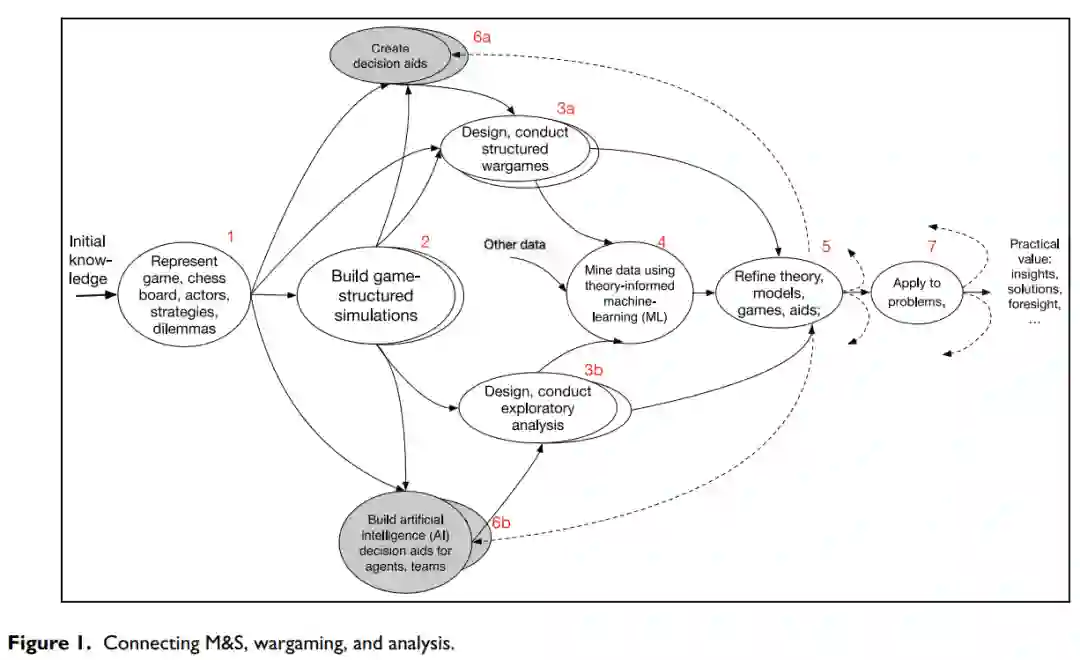
这种理想化的活动随着时间的推移,从研究、兵棋推演、军事和外交经验、人类历史、人类学等方面开始(第1项),汇集关于某个领域(例如印度-太平洋地区的国际安全问题)的知识。这就是对棋盘、行动者、潜在战略和规则书的定性。
两项工作的进行是不同步的。如图1的上半部分,兵棋推演在进行中,为某种目的而结构化。无论图中的其他部分是否成功执行,这都可能独立发生。同时,M&S以游戏结构化模拟的形式进行。随着时间的推移,从M&S和兵棋推演中获得的经验被吸收,使用人工智能从M&S实验中挖掘数据(第4项),以便为后续周期完善理论和数据(第5项)。在任何时候,根据问题定制的MSG都会解决现实世界的问题(第7项)。如同在浅灰色的气泡中,人类团队的决策辅助工具(项目6a)和智能体的启发式规则(项目6b)被生成和更新。有些是直接构建的,但其他的是从分析实验和兵棋推演中提炼出来的知识。有些智能体直接加入了人工智能,有些是间接的,有些则根本没有。图1鼓励MSG活动之间的协调,尽管这种协调有时可能是非正式的,可能只是偶尔发生。
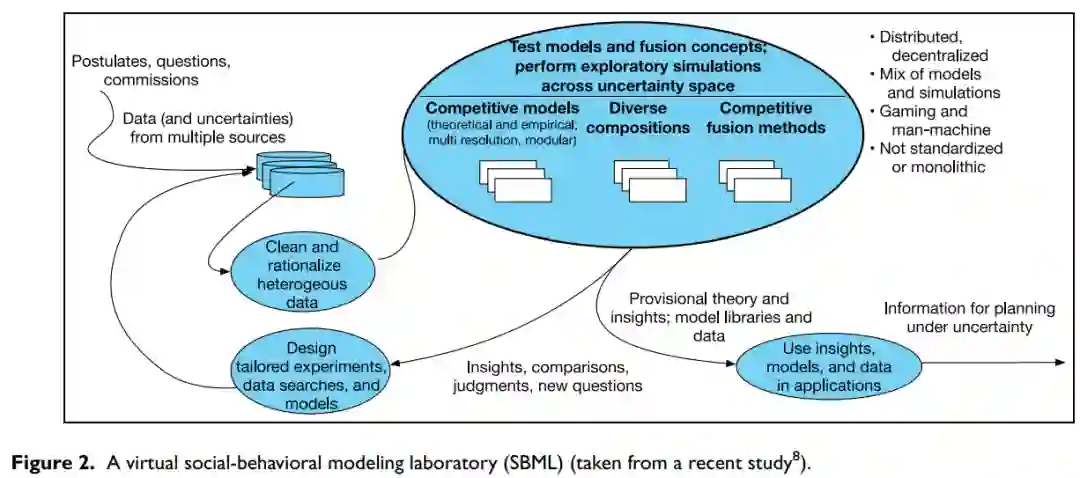
图1的意图可以在一个单一的组织中完成(例如,敏感的政府内工作)和/或在智囊团、实验室、私营企业、学术界和政府中更开放的持续努力计划中完成,就像图2中的DARPA研究称为社会行为建模实验室(SBML)。在任何一种情况下,这种方法都会鼓励多样性、辩论和竞争。它也会鼓励使用社区模块来组成专门的MSG组件。这与专注于一个或几个得天独厚的单一模型形成鲜明对比。直截了当地说,这个愿景是革命性的。
4 挑战与机遇
4.1 国家安全挑战
今天的国际安全挑战远远超出了冷战时期的范围。它们呼唤着新的兵棋推演和新的M&S。新的挑战包括以下内容。
1、多极化和扩散
现在的世界有多个决策中心,他们的行动是相互依赖的。从概念上讲,这将我们置于n人博弈论的世界中。不幸的是,尽管诸如公地悲剧和食客困境等现象可以用n人博弈论的语言来描述,而且平均场理论有时也可以作为一种近似的方法来使用,但似乎n人博弈的复杂的解决方案概念还没有被证明是非常有用的。由于种种原因,这种解决方案并没有被广泛采用。商学院的战略课程很少使用这些技术,国防部的智囊团也很少将这些技术纳入他们的M&S中。可能是现实世界的多极化太过复杂,难以建模,尽管在战略稳定方面已经做出了一些努力。就像物理学中的三体问题一样,n方系统的行为甚至可能是混乱的。我们还注意到,随机混合策略在n人博弈中通常发挥的作用很小。同样,在计算其他玩家的行动时,可能有很多内在的复杂性,以至于随机化产生的一层额外的不确定性对我们理解未来的危机动态没有什么贡献。
与1980年代相比,有更多的国家拥有大规模杀伤性武器(即印度、巴基斯坦、朝鲜),甚至更多的国家拥有大规模破坏性武器。网络作为一种战略武器的加入,使问题进一步复杂化。在这里,人工智能可能有助于理解事件。作为一个例子,假设一支核力量受到攻击,使其用于电子控制的电力系统瘫痪(由于分散和防御,这可能并不容易)。一支导弹部队只能在短时间内依靠备用电力系统执行任务。大国肯定意识到自己和对手的这种脆弱性。在商业电力领域,人工智能对于在电力中断后向需求节点快速重新分配电力资源变得非常重要,例如2021年发生在德克萨斯州的全州范围内的冰冻温度。
2、多维战争
武器装备的变化扩大了高端危机和冲突的维度,如远程精确打击和新形式的网络战、信息战和太空战。这意味着卡恩很久以前提出的44级升级阶梯现在必须被更复杂的东西所取代,正如后面6.3节中所讨论的。
3、有限战略战争的可行性
一个推论被低估了,那就是现在的世界比以前更加成熟,可以进行有限的高端战争--尽管更热衷于威慑理论的人有相反的断言--其中可能存在有意义的赢家和输家。在考虑俄罗斯入侵波罗的海国家、朝鲜入侵韩国等可能性时,这一点变得很明显。出现的一些问题包括俄罗斯对 "升级-降级 "战略(北约冷战战略的俄罗斯版本)的依赖,以及网络战争和攻击空间系统的前景。因此,观察到更多国家部署跨洋范围的精确打击武器也是麻烦的。即使是旷日持久的“有限”战略战争现在也可能发生,尽管如第6.3节所讨论的那样,升级很容易发生。
4、盟友和伙伴之间的目标冲突
今天的美国安全伙伴有着不同的重要利益和看法。北约在整个冷战期间表现出的非凡的团结,在现代危机或冲突中可能无法重现。在亚太地区,朝鲜和韩国、中国、日本、台湾、印度和巴基斯坦之间的矛盾关系是危机中困难的预兆。所有这些国家都有通过使用太空、网络空间或区域范围内的精确武器进行升级的选择。
这里的总体问题是,联盟仍然非常重要,但今天的联盟可能与冷战时期紧绷的街区不同。我们可能正在进入一个类似于20世纪初的多极化阶段。第一次世界大战爆发的一个因素是,柏林认为伦敦不会与法国一起发动战争,在欧洲阻击德国。这导致人们相信,战争将类似于1871年的普法战争--有限、短暂,而且没有特别的破坏性。甚至法国在1914年8月之前也不确定英国是否会加入战争。这种对自己的盟友会做什么的计算,对稳定至关重要。这里的不确定性确实是一个具有巨大意义的战略问题。
4.2 技术挑战与机遇
在考虑现代分析性兵棋推演的前景时,新的技术机会比比皆是。下面的章节列出了一些。
1、基于智能体的建模
基于智能体的建模(ABM)已经取得了很大的进展,对生成性建模尤其重要,它提供了对现象如何展开的因果关系的理解。这种生成性建模是现代科学的革命性发展。与早期专家系统的智能体不同,今天的智能体在本质上通常是追求目标或提高地位的,这可能使它们更具有适应性。
2、人工智能
当然,更普遍的人工智能研究比ABM要广泛得多。它提供了无限的可能性,正如现代文本中所描述的那样。我们在本文中没有多加讨论,但是在考虑M&S的未来,以及兵棋推演的决策辅助工具时,最好能有长篇大论的章节来论述有时被确认的每一种人工智能类型,即反应式机器、有限记忆的机器、有限自动机、有自己的思维理论的机器,以及有自我意识的机器。这在这里是不可能的,这一限制也许会被后来的作者所弥补。
3、联网
联网现在是现代生活的一个核心特征,人与人之间、组织与组织之间都有全球联系。数据是无处不在的。这方面的一个方面是分布式兵棋推演和练习。另一个方面是在线游戏,甚至到了大规模并行娱乐游戏的程度,对这些游戏的研究可能产生国家安全方面的见解。这类游戏并不"严肃",但在其中观察到的行为可能暗示了在更多的学术研究中无法认识到的可能性和倾向性。
4、模块化和特制的模型构成
现在,建立独立有用的模型(即模块)并根据手头问题的需要组成更复杂的结构是有意义的。这种组合与国防部历史上对标准化的大型综合单体模型的偏爱形成鲜明对比。在不确定因素和分歧普遍存在的情况下,这种标准化的吸引力要小得多,比如在更高层次的M&S或兵棋推演中。模块化设计允许带着对被建模的东西的不同概念。这可以打开思路,这对预见性是很有用的,就像避免惊讶或准备适应一样。也有可能将替代模型与数据进行常规比较,部分用于图2中建议的常规更新。另外,模块化开发有利于为一个特定的问题插入专业性,这是2000年中期国防部研讨会上建模人员和分析人员社区推荐的方法。
5、数据驱动的人工智能/机器学习
今天,AI一词通常被用来指机器学习(ML),这只是AI的一个版本。ML已经有了很大的进步,ML模型通常可以准确地拟合过去的数据,并找到其他未被认识到的关系。一篇评论描述了进展,但也指出了局限性--提出了有理论依据的ML版本,在面向未来的工作中会更加有效,并强调了所谓的对抗性人工智能,包括击败对手的深度学习算法的战术。
6、深度不确定性下的决策
规划的概念和技术取得了根本性的进展,在深度不确定性下的决策(DMDU)的标题下讨论。这从 "优化 "最佳估计假设的努力,转向预期在广泛的可能未来,也就是在许多不确定的假设中表现良好的战略。在过去,解决不确定性问题往往是瘫痪的,而今天则不需要这样。这些见解和方法在国防规划和社会政策分析中有着悠久的历史,应该被纳入人工智能和决策辅助工具中。
设计"永远在线"的系统,并不断提高智能。从技术上讲,大多数国防部的MSG都是人工智能界所谓的"转型"。该模型或游戏有一个起点;它运行后会报告赢家和输家。可以进行多次运行,并将结果汇总,以捕捉复杂动态中固有的差异。较新的人工智能模型的设计是不同的,它所模拟的系统是 "永远在线的"。这被称为反应式编程,与转化式编程不同。这些系统永远不会停止,并且不只是将输入数据转化为输出数据。例子包括电梯系统和计算机操作系统。国防方面的例子包括网络预警系统,导弹预警系统,或作战中心。这些都不会"关闭"。防御系统正变得更加反应灵敏,所以必须用模型来表示它们。这一点在1980年代RSAS的更高级别的红方和蓝方智能体的设计中已经预见到了,它们会在事件发生后'醒来',并对局势和选项进行新的评估,而不是继续按照脚本行事。
在转换型模型中,环境中的事件可能会触发程序按顺序采取某种行动。反应式模型则不同。程序在环境中同时做出改变。他们一起改变,或几乎一起改变。国防工作的一个有趣的例子涉及自主武器。人类和机器决策之间的界限已经模糊了,因为在一个反应式系统中人和机器之间的互动可能是连续和交织的。反应式系统是美国、中国和俄罗斯国防投资的一个主旨。无人机群和网络预警系统将如何在M&S和兵棋推演中得到体现?除非表述恰当,否则相关人工智能模型在模拟中的价值可能会适得其反。
然而,这仅仅是个开始。随着机器拥有更好的记忆和利用它们所学到的东西,以及它们纳入世界理论,包括对手的思想理论,人工智能将如何变化?一个令人担忧的问题是,正如Yuna Wong及其同事所讨论的那样,对人工智能的更多使用将增加快速升级的前景。这方面的风险对于专注于最大化某些相对量化措施,而不是更多的绝对结果及其定性评价的人工智能来说尤其高。以冷战时期的经验为例,执着于谁会在全球核战争中以较高的核武器交换后比率 "赢得"的分析是危险的。幸运的是,决策者们明白,结果将是灾难性的,没有真正的胜利者。即使是1983年电影《兵棋》中的计算机约书亚也明智地得出结论:"核战争。一个奇怪的游戏。唯一的胜利之举就是不玩。来一盘漂亮的国际象棋如何?无论约书亚体现的是什么人工智能,它都不只是关于如何通过数字赢得一场娱乐游戏的ML。
【完整中英文版请上专知查阅】
便捷下载,请关注专知人工智能公众号(点击上方关注)
点击“发消息” 回复 “AIWM” 就可以获取《推荐!《用于兵棋推演和建模的人工智能》兰德、耶鲁大学2022最新16页论文》专知下载链接





