

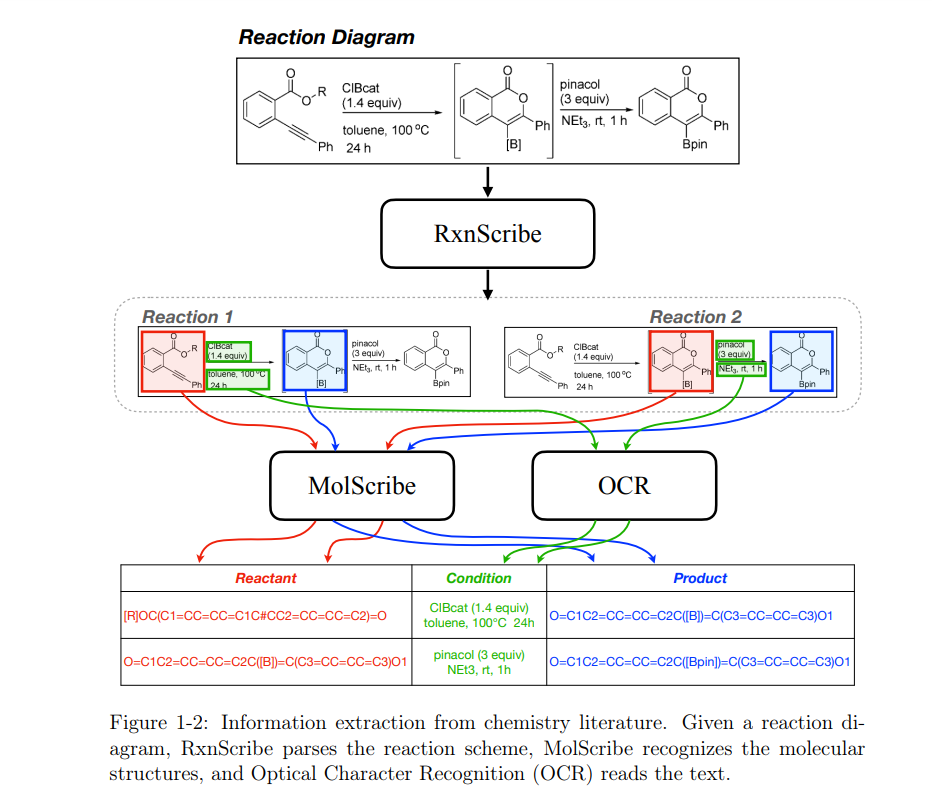
结构化文档,如科学文献和医疗记录,是知识的丰富资源。然而,大多数自然语言处理技术将这些文档视为纯文本,忽略了布局结构和视觉信号的重要性。为了全面理解这些文档,对这种结构的建模是至关重要的。本论文提出了从结构化文档中提取结构化知识的新算法。首先,我们提出GraphIE,一个信息提取框架,专门设计用来建模结构化文档中的非局部和非顺序依赖关系。GraphIE 通过图神经网络利用结构信息来增强单词级的标签预测。在三个提取任务的评估中,GraphIE始终超过仅基于纯文本运行的顺序模型。接下来,我们深入研究化学领域的信息提取。科学文献经常以信息图形的形式描述分子和反应。为了提取这些分子,我们开发了MolScribe,一个将分子图像转化为其图形结构的工具。MolScribe在图像到图形生成模型中整合了符号化学约束,显示出对处理各种绘图风格和习惯的稳健性能。为了提取反应方案,我们提出了RxnScribe,它通过序列生成公式解析反应图。尽管RxnScribe是在一个适度的数据集上进行训练的,但它在不同类型的图表上都表现出强劲的性能。最后,我们介绍TextReact,一种直接增强预测化学与文本检索的新方法,绕过了中间的信息提取步骤。我们在反应条件推荐和逆合成预测的实验中展示了TextReact在从文献中检索相关信息并泛化到新输入的有效性。



成为VIP会员查看完整内容
相关内容

麻省理工学院(Massachusetts Institute of Technology,MIT)是美国一所研究型私立大学,位于马萨诸塞州(麻省)的剑桥市。麻省理工学院的自然及工程科学在世界上享有极佳的盛誉,该校的工程系曾连续七届获得美国工科研究生课程冠军,其中以电子工程专业名气最响,紧跟其后的是机械工程。其管理学、经济学、哲学、政治学、语言学也同样优秀。
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
相关主题


相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日