

由于该领域的多重进展,计算机视觉系统在过去二十年中取得了快速进步。随着这些系统越来越多地部署在高风险的现实应用中,迫切需要确保它们不会传播或放大历史或人工整理数据中的任何歧视性倾向,或无意中从虚假的相关性中学习到偏见。本文提供了关于公平性的全面综述,总结并揭示了计算机视觉背景下的最新趋势和成功。我们讨论的话题包括:
- 从广泛的公平机器学习文献和相关学科中得出的公平性的起源和技术定义。
- 旨在发现和分析计算机视觉系统中偏见的研究工作。
- 近年来提出的缓解计算机视觉系统中偏见的方法的总结。
- 研究人员为测量、分析和缓解偏见以及增强公平性而产生的资源和数据集的全面总结。
- 对该领域的成功、在多模态基础和生成模型背景下的持续趋势以及仍需解决的空白的讨论。
所提出的描述应帮助研究人员理解在计算机视觉中识别和缓解偏见的重要性、该领域的现状,并识别未来研究的潜在方向。
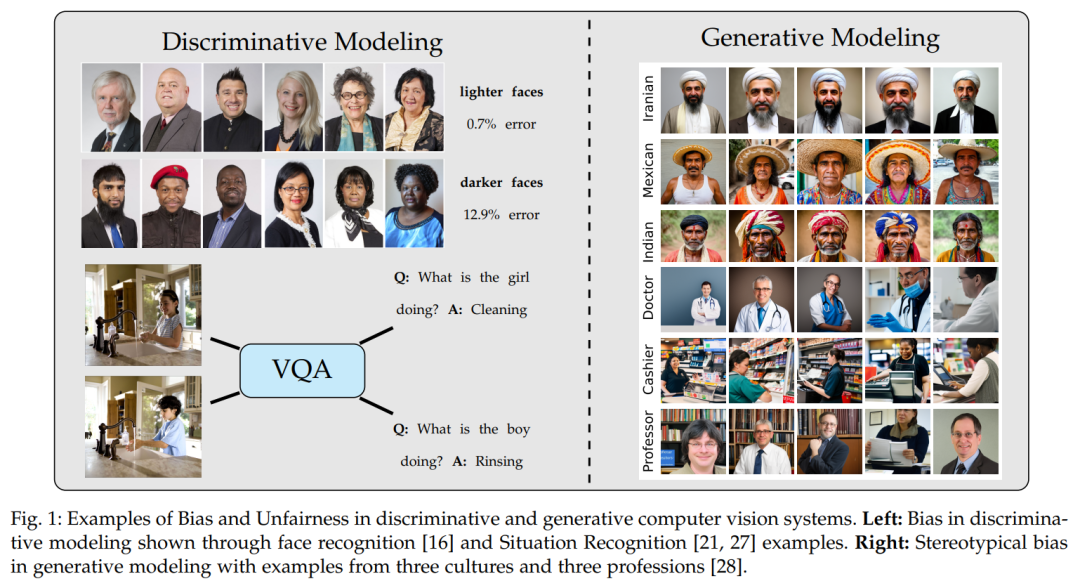
计算机视觉领域多年来经历了多次重大进展。机器学习和统计方法的引入引发了对视觉识别的极大兴趣和进步,例如[1, 2, 3],这最终激发了最近在使用神经网络[4, 5, 6]和大规模数据集[7, 8]的深度学习方法方面的诸多进展。识别问题的快速进展也激发了对各种其他问题的正确方法和模型的探索,例如用于图像分割的U-Net [9]或用于图像合成的潜在扩散模型[10]。 然而,机器学习和统计方法依赖于可以引发、传播或放大统计偏差的训练数据集和损失函数。当这些偏差与人们相关的敏感保护属性(例如种族、性别、年龄或民族)相关时,这些偏差是不受欢迎的。学习这些固有相关性或依赖于这些属性的虚假相关性的模型可能会产生不同的结果,从而导致伦理或法律问题[11, 12]。公平性和偏差缓解的目标[13, 14]是防止或最小化此类偏差对模型决策的影响。 为了使计算机视觉系统广泛采用、接受和信任,有必要避免社会不平等并提高其可靠性。这激发了对公平性和偏差问题的关注,旨在开发能够公平地为社会服务的负责任的视觉识别和相关系统。从早期揭示图像描述[15]或面部识别[16]偏见的研究,到最近在各种任务中缓解偏见的努力[14, 17, 18, 19],在研究公平性和提出缓解计算机视觉偏见方法方面,已经有大量的工作。本文综述了这方面的文献以及机器学习系统在大规模数据集上训练并应用于社会偏见相关问题的相关问题。 本文首先介绍了公平性的符号、起源和定义,同时总结了与更广泛的机器学习文献中公平性研究的共性。然后,我们简要讨论了先前在发现和分析计算机视觉数据集和模型中的偏见方面的工作。接下来,我们综合了用于研究偏见及其缓解的提出的方法和数据集。最后,我们讨论了在多模态基础模型中发现和缓解偏见的当前趋势以及该领域的未解问题。该综述旨在为新研究提供快速参考和起点,适应或设计新方法以最大限度地提高新兴计算机视觉模型的公平性。 计算机视觉模型中公平性研究与其他领域(如表格数据和图表)相比有何不同?公平性的总体框架包括量化模型对不同类别敏感保护属性群体的不同比例结果,并提出缓解这些差异的方法。例如,COMPAS[20]是一个常用于分析机器学习公平性的表格数据集,其中将种族作为敏感保护属性,包括为分类变量。相比之下,计算机视觉数据集通常缺乏对敏感属性的明确分类标签。这些属性通常隐含在输入图像像素的组合和模型要推断的特定任务目标属性中。例如,在没有偏见缓解的情况下,训练预测人类活动(如烹饪与不烹饪)的计算机视觉模型可能会对不同性别的人物图像预测出不同的比例[21]。挑战在于解开与性别相关的人物外观和正在执行的活动的影响。由于这一目标很难实现,计算机视觉中的偏见缓解提出了表格数据集中不存在的独特挑战。这证明了对计算机视觉方法进行全面综述的必要性,同时简要回顾了更一般的公平性文献。对于机器学习公平性的全面综述,我们推荐阅读Mehrabi等人[22]、Pessach和Shmueli[23]、Le Quy等人[24]、Caton和Haas[25]的文献。或许与我们更相关和互补的是Parraga等人[26]最近的综述,该综述侧重于视觉与语言模型。相比之下,我们的综述更全面地总结了与传统计算机视觉任务(如图像分类、目标检测、活动识别和面部识别与分析)相关的公平性文献。 计算机视觉的另一个挑战是缺乏对敏感保护属性的明确标签的访问。通常,计算机视觉数据集中没有明确注释或由图像中的个人提供的人口变量(如性别、种族或民族)信息。因此,这些数据集上的大多数注释只能被视为基于数据注释者感知判断的代理值。此外,Scheuerman和Brubaker[29]认为,科技工作者和科学家在定义计算机视觉数据集中的人物身份类别方面也发挥了重要作用。因此,之前的研究中对性别等人口标记的研究仅作为二元变量,种族则通常作为一组离散类别进行研究。本综述中总结的几项工作承认了其中一些问题,但总体领域应在这种背景下进行评估。 除了这些问题之外,由于偏见的性质、数据集和任务的多样性以及模型性能和公平性之间的权衡,导航计算机视觉中的公平性和偏见缓解挑战仍然是一项复杂的工作。本文综述了核心计算机视觉任务,并确定了实现每项任务的公平性和缓解偏见所面临的主要挑战。图1展示了计算机视觉系统中普遍存在的人口偏见和不公平类型。表1和表2广泛总结了计算机视觉文献中开发的特定任务去偏方法以及用于研究偏见和公平性的数据集。在第4节和第5节中可以找到对偏见缓解的常用方法的详细概述以及按偏见属性和任务分类的数据集的全面讨论。
