

生成式检索(GR)是一种新兴的信息检索范式,利用生成模型直接将查询映射到相关的文档标识符(DocIDs),无需传统的查询处理或文档重排序。本综述提供了对GR的全面概述,重点介绍了关键发展、索引和检索策略以及面临的挑战。我们讨论了各种文档标识符策略,包括数字和基于字符串的标识符,并探索了不同的文档表示方法。我们的主要贡献在于概述未来可能对该领域产生深远影响的研究方向:改进查询生成的质量、探索可学习的文档标识符、增强可扩展性以及将GR与多任务学习框架集成。通过研究最先进的GR技术及其应用,本综述旨在提供对GR的基础性理解,并激发在这种变革性信息检索方法上的进一步创新。我们还将诸如论文集等补充材料公开。
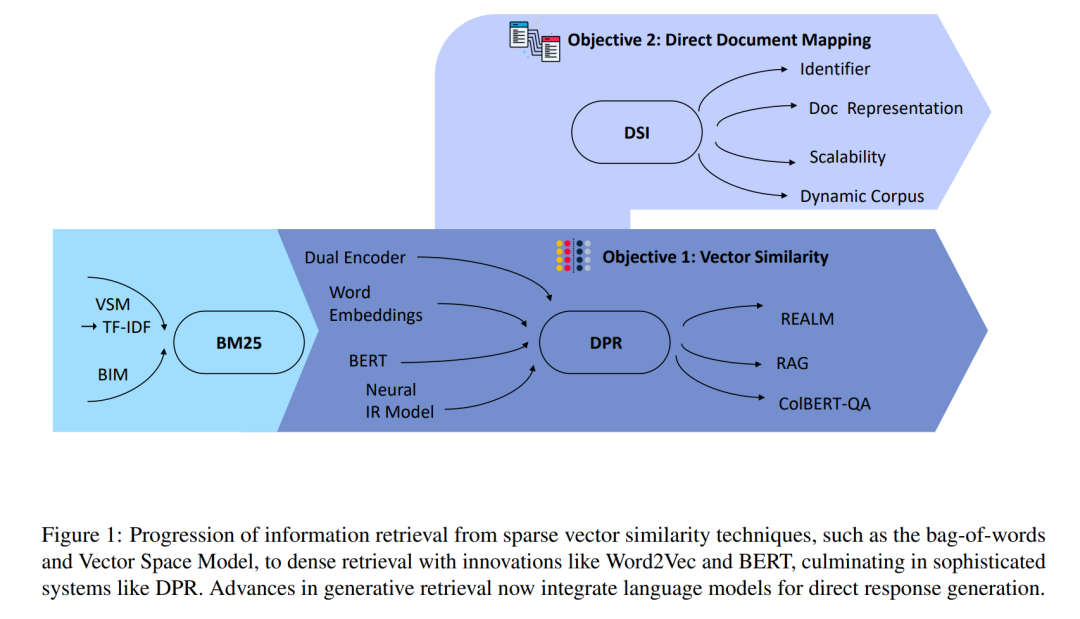
信息检索(IR)的历史经历了显著的演变,从基于统计词关系的初步方法发展到利用先进深度学习技术的复杂系统。这一进程主要围绕两个主要训练目标,如图1所示:
目标1:向量相似度
最初,IR系统依赖于稀疏检索技术,通过诸如词袋模型和向量空间模型(VSM)(Salton, 1983)等方法利用词之间的统计关系。在这些模型中,文档被表示为稀疏向量,每个维度指示词的存在或频率。二元独立模型(BIM)(Robertson和Jones, 1976)的发展和词频-逆文档频率(TF-IDF)的实现是这种方法的典型代表,强调了词出现的独立性和频率。
随着技术进步,重点转向了稠密检索。在这一阶段,词嵌入将词转化为稠密向量表示,捕捉到比单纯关键词匹配更深层次的语义相似性和上下文关系。在这一领域的重要发展包括Word2Vec(Mikolov et al., 2013)、GloVe(Pennington et al., 2014)以及变压器网络的进步如BERT(Devlin et al., 2018)。这些创新最终催生了如DPR(Dense Passage Retrieval)(Karpukhin et al., 2020)等复杂模型,通过采用稠密向量嵌入来理解复杂的查询和文档,显著提高了信息检索的精度和有效性。在DPR的基础上,REALM(Guu et al., 2020)和RAG(Lewis et al., 2020)等模型将检索与语言模型集成,进一步优化了相关性。ColBERT-QA(Khattab et al., 2021)通过上下文化嵌入进行精确答案检索,提升了问答能力。
目标2:直接文档映射
随着信息检索从向量相似度方法转变,它采用了生成式检索,这是一种利用生成模型直接生成与用户查询相关的文本响应或文档标识符的方法。这标志着从匹配预先存在的向量表示到动态生成直接满足用户需求的文本输出的重大转变。在预检索阶段,生成模型通过诸如Xiao等人(2022)所示的使用掩码自编码器(MAE)的检索导向预训练范式等创新方法来提高稠密检索的效率。该模型训练从嵌入和掩码输入中重建句子,在各种基准测试中表现优异。在检索阶段,Lewis等人(2020)的检索增强生成模型通过稠密段落检索器选择文档并为复杂的自然语言处理任务生成答案,取得了顶级性能。此外,Tay等人(2022)的可微搜索索引(DSI)通过将查询直接映射到相关文档,显著超越了传统方法,并在零样本设置中表现出强大的泛化能力。在后检索阶段,深度学习技术被应用于重新排序检索到的文档,如Guo等人(2016)通过分析查询和文档之间的复杂匹配模式来优化文档排名。类似地,Mitra等人(2017)通过融合局部和分布式文本表示,利用局部和全局上下文来提高搜索结果质量,增强了网页搜索重排序。通过这些创新,包括双塔模型架构和可微搜索索引(DSI)(Tay等人,2022),生成式检索不仅有效地响应查询,还能在语料库中识别相关信息,利用端到端训练架构整合深度学习过程来简化检索体验。
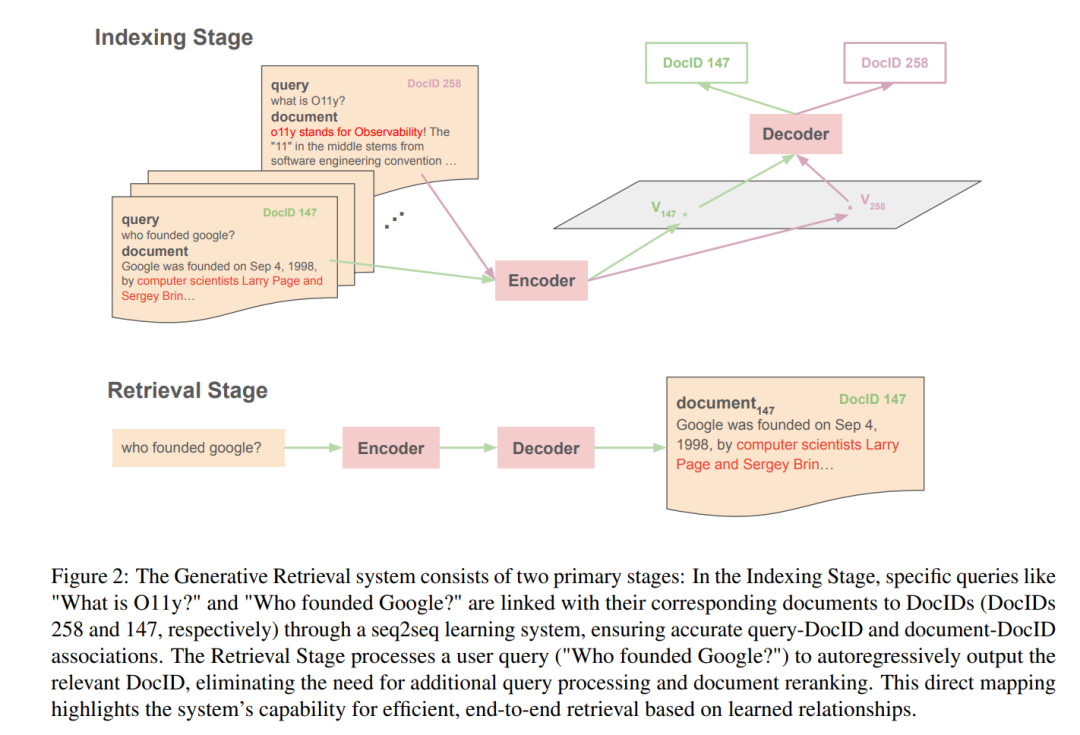
## 2 生成式检索简介
### 2.1 生成式检索的定义
前一节展示了在各种信息检索阶段应用生成模型以促进任务执行。在本综述论文中,我们旨在定义“生成式检索”(GR),其背景是在Tay等人(2022)的可微搜索索引架构中,其中查询通过seq2seq模型直接映射到相关文档,无需预检索查询处理或后检索文档重排序。本质上,端到端架构足以完成信息检索任务。我们正式定义GR为一个系统,其中,给定用户查询q作为输入,seq2seq学习模型直接输出若干文档标识符(docids)。每个标识符j对应于语料库D中的特定文档dj,表明该文档与查询q相关(见图2)。要实现这一点,GR需要两个关键组件:索引和检索。
#### 2.1.1 索引
在GR索引策略中,关键考虑因素是索引方法和索引目标。索引方法研究的是将文档内容与其唯一标识符建立联系的技术,基本上掌握了将每个文档的文本与一个独特的docid相关联的过程。相反,索引目标关注文档表示策略。这涉及有关索引细节级别的决策、索引特定文档部分的重要性、处理重复信息的方式,以及语义理解在描绘文档内容本质中的重要性。 在GR的索引方法中,重点是简化将文档内容与其唯一标识符连接的过程。我们可以将索引方法的过程公式化为对两种类型的示例进行训练。第一个是(dj, j),其中dj ∈ D表示语料库D中的第j个文档,j表示对应的标识符。构建索引时,对文档-docid配对进行训练是至关重要的。这种配对过程是创建每个文档内容与其在数据库中的位置之间的可检索链接的第一步,从而实现高效的存储和检索。 第二个训练示例是(qi, j),在这里我们将查询qi与其相关的docid j链接。通过将查询与相关的docid配对,系统学习定义用户搜索意图(通过查询表达)和文档内容(通过docid表示)之间相关性的上下文细微差别。这种训练有助于模型理解哪些文档与给定查询最相关,这种理解仅通过索引是无法实现的。这些方法包括序列到序列转换和双向训练的创新方法,以及基于跨度的去噪高级技术。第二个训练示例的详细信息将在第3节中讨论。 对于索引目标,重点转向系统中文档的表示方式。由于模型容量和计算资源的限制,生成式检索模型通常不可能以整个文档作为直接输入进行训练。因此,有必要考虑其他有效表示文档的方法,包括:
- 直接索引:取文档的前L个标记。
- 集合索引:取前L个不重复的标记。
- 倒排索引:从文档中随机开始取连续的k个标记。
- 查询作为表示:Zhuang等人(2022)提出了一种方法,使用生成的查询来表示文档,同时以DocID进行训练。他们建议在训练中使用查询而不是整个文档更符合检索过程,因为检索通常涉及使用查询来查找相关文档。 通过采用这些多样化的索引方法,我们旨在提高生成式检索系统的效率和准确性。直接索引和集合索引提供了简单但有效的手段来捕获重要的文档内容,同时减少冗余。倒排索引提供了一种随机但系统的方法来表示文档,确保内容覆盖多样化。同时,利用查询作为文档表示将训练阶段与检索阶段对齐,促进更直观和上下文感知的检索过程。 最终,这些索引策略趋向于一个统一的目标:优化生成式检索系统理解、索引和检索文档的能力,以高精度响应用户查询。通过平衡细节、相关性和全面性,我们可以确保系统不仅高效地存储文档内容,还能在用户查询时准确地检索最相关的信息。这种平衡对于开发一个能够处理多样化和复杂信息需求的强大和可扩展的生成式检索框架至关重要。
#### 2.1.2 检索
完成索引阶段后,我们将注意力转向检索阶段。经典的GR模型采用seq2seq方法自回归地解码候选docids,其中这些docids的表示选择对检索效率至关重要。 在生成式检索的开创性工作中,Tay等人(2022)引入了非结构化原子标识符方法,为每个文档分配唯一整数。这一基础方法得到了结构化标识符方法的补充,包括简单结构的字符串标识符和语义结构的标识符,为细致的文档表示铺平了道路。随着该领域的发展,后续工作在标识符表示上进行了多样化探索,探索了字符串子集、文章标题等替代方案。第3节将详细探讨和比较这些扩展及其系列中的更广泛工作,突出它们在生成式检索背景下的贡献和创新。
本文对生成式检索(GR)进行了全面的综述和分析,探讨了其发展历史、关键技术、挑战和未来方向。以下是对信息检索领域的五项重要贡献:
- 信息检索的发展历程从稀疏检索方法到稠密检索技术,最终发展到生成式检索,其中查询通过seq2seq模型直接映射到相关文档,无需预检索查询处理或后检索文档重排序。
- 解释了GR的核心概念,详细说明了端到端的检索过程、索引和检索技术,包括文档标识符策略和seq2seq模型。
- 比较了各种文档标识符类型,显示具有语义信息的标识符通常表现更好,并探讨了创建这些标识符的不同方法。
- 讨论了GR中的评估指标和常用数据集,强调它们在评估检索性能和比较不同标识符策略中的作用。
- 识别了诸如可扩展性和动态语料库管理等挑战。提出了未来的研究方向,如优化训练方法、提高系统可扩展性以及整合多任务学习技术。
总之,这项研究提供了一个详细的综述,帮助读者深入了解生成式检索技术。它旨在激发该领域的进一步研究,并推动信息检索技术的发展。