近期,多功能大规模语言模型(LLMs)的激增在很大程度上依赖于通过偏好学习将越来越强大的基础模型与人类意图对齐,从而在广泛的背景下增强LLMs的适用性和有效性。尽管已经进行了众多相关研究,但关于如何将人类偏好引入LLMs的视角仍然有限,这可能阻碍了对人类偏好与LLMs之间关系的深入理解以及其局限性的实现。在这篇综述中,我们从偏好中心的角度回顾了在人类偏好学习领域针对LLMs的探索进展,涵盖了偏好反馈的来源和形式、偏好信号的建模和使用以及对齐LLMs的评估。
我们首先根据数据来源和形式对人类反馈进行分类。然后总结了人类偏好建模的技术,并比较了不同模型派别的优缺点。此外,我们根据利用人类偏好信号的目标展示了各种偏好使用方法。最后,我们总结了评估LLMs在人类意图对齐方面的一些流行方法,并讨论了我们对LLMs人类意图对齐的展望。

大规模语言模型(LLMs)[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]对人工智能(AI)产生了突破性的影响,改变了人们对AI系统理解和应用人类语言潜力的看法。这些具有大规模参数(主要超过100亿)的神经网络语言模型最初在从各种来源收集的大规模语料库上进行了预训练,其中相当一部分来源于互联网[11]。通过模仿人类在文本数据中使用自然语言的方式进行预训练,基础LLMs获得了强大而通用的语言技能[1, 12]。另一方面,观察发现基础LLMs在理解或恰当地回应多样化的人类指令方面存在困难[13],因为预训练中的模仿过程并未强制基础LLMs按照人类意图来执行指令[13, 14]。来自互联网的预训练语料库中残留的一些有毒、有偏见或事实错误的内容甚至会导致基础LLMs的不当模仿,产生不理想的生成结果[15, 16, 17, 18, 19, 20]。在现实生活中的实际应用中,基础LLMs必须进化得更加符合人类意图,而不是模仿预训练语料库中可能存在噪声的行为。
人类偏好学习[21]可以通过根据输出结果中反映人类偏好的反馈信息优化LLMs,有效地使LLMs与人类意图对齐,从而指定人类的意图[22]。最近涌现的大量进化后的LLMs能够生成适当的响应以应对各种人类指令,验证了这一方法的有效性[2, 6, 8, 9, 13]。目前,关于人类偏好学习的综述大多集中于狭义的人类偏好学习方法或广义的语言模型(LM)对齐方法。关于人类偏好学习的综述主要集中于强化学习(RL),这可能不适用于LLMs,也不包含与非RL偏好学习方法相关的见解[23, 24]。关于LM对齐[25, 26, 27, 28]以及一般AI系统对齐[22]或超越语言的大模型[29]的综述,主要将人类偏好学习视为解决对齐问题的工具。这些综述缺乏对偏好学习,特别是偏好建模方法的系统回顾和讨论,而偏好建模方法对于捕捉人类意图以实现LM对齐至关重要[13]。为了进一步探索更有效的偏好学习方法以实现更好的LLM对齐,我们对适用于语言模型的人类偏好学习方法进行了全面综述,从偏好学习的角度审视LLM对齐方法。通过分析偏好学习框架内的各种对齐方法,我们勾勒出将人类偏好引入LLMs的全貌,从各个方面提供关于人类偏好学习的见解,适用于各个领域。 具体而言,如图1所示,我们引入了人类偏好学习在LLMs中的各个方面,包括偏好反馈的来源和形式、偏好建模、偏好信号的使用以及整合人类偏好的LLMs的评估:
- 反馈来源:偏好反馈的质量和规模对于人类偏好学习至关重要,而反馈收集的来源可以极大地影响它们。最近的人类偏好学习方法不仅从人类那里收集偏好反馈,还从模拟人类的方式中收集,探索高质量和大规模之间的平衡。
- 反馈形式:偏好反馈的形式决定了其信息密度和收集难度,从而也影响了偏好反馈的质量和规模。人类偏好学习工作中采用的反馈形式大致包括自然适合偏好表达但信息量较少的相对关系,以及更能反映人类偏好的绝对属性,但更难收集。不同形式的结合可以进一步增加偏好反馈的信息密度。
- 偏好建模:偏好建模旨在从偏好反馈中获得偏好模型,提供可推广和直接可用的人类偏好信号以对齐LLMs。各种偏好建模方法专注于获取具有数值输出的偏好模型。一些工作还探索了具有自然语言输出的偏好建模方法。除了明确获得任何偏好模型外,另一类研究通过直接使用反馈数据作为偏好信号来隐式建模人类偏好,以间接偏好建模目标对齐LLMs或利用对齐的LLMs提供偏好信号。
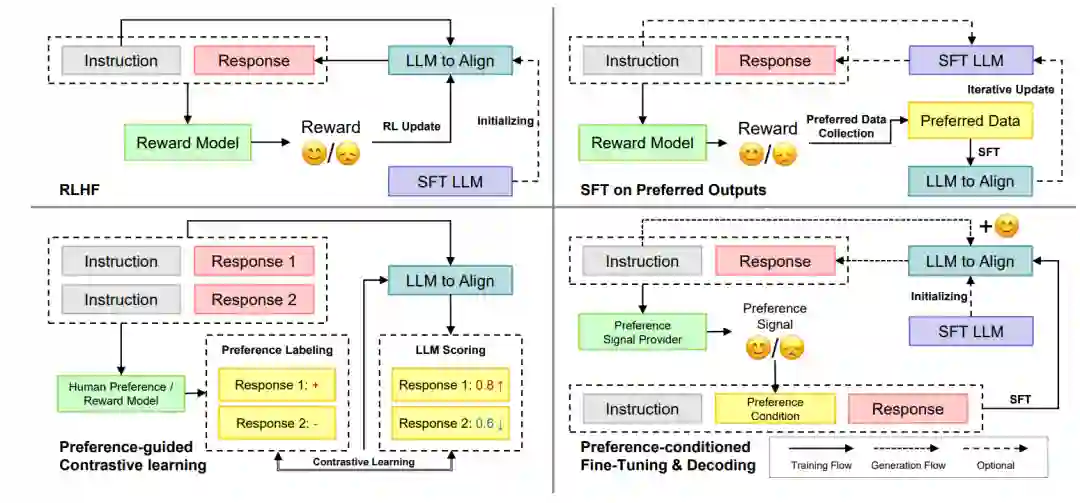
- 偏好使用:偏好使用是根据偏好信号的指导调整基础LLMs的阶段,使LLMs与人类意图对齐。根据偏好信号使用的具体目标,最近的方法可以分为四大类:基于人类反馈的强化学习(RLHF),最大化LLM输出的总体预期奖励分数;在首选输出上的监督微调(SFT),最大化人类偏好输出样本的生成概率;偏好引导的对比学习,增加更偏好的输出的生成概率,同时减少不太偏好的输出的生成概率;以及偏好条件的微调和生成,最大化由相应偏好信号条件生成的输出的生成概率。
- 评估:最后,全面评估LLMs的遵循人类意图的能力对于验证人类偏好学习的有效性至关重要。现行的评估协议分为三类:开放形式基准,评估LLMs对多样化指令响应的人类偏好而不提供标准答案;自动评估,在具有标准标签的一组任务上使用自动指标评估LLMs;以及定性分析,直接检查对一些代表性指令的每个响应。 值得注意的是,本综述涵盖了虽然不是特定于LLMs但可用于对齐LLMs的人类偏好学习研究工作,从经典强化学习等领域提供见解。我们进一步总结了近期在对齐LLMs与人类意图方面取得的关键进展,并讨论了当前未解决的挑战和未来研究的可能前景,包括多元化人类偏好学习、可扩展的LLMs对齐监督、语言无关的LLM对齐、多模态互补对齐、LLM对齐进展的全面评估以及对欺骗性对齐的实证研究。我们希望这篇综述能帮助研究人员发现人类偏好在LLM对齐中的运作机制,通过对前沿研究工作的回顾,启发他们在对齐LLMs和其他AI系统方面实现与人类意图的对齐。
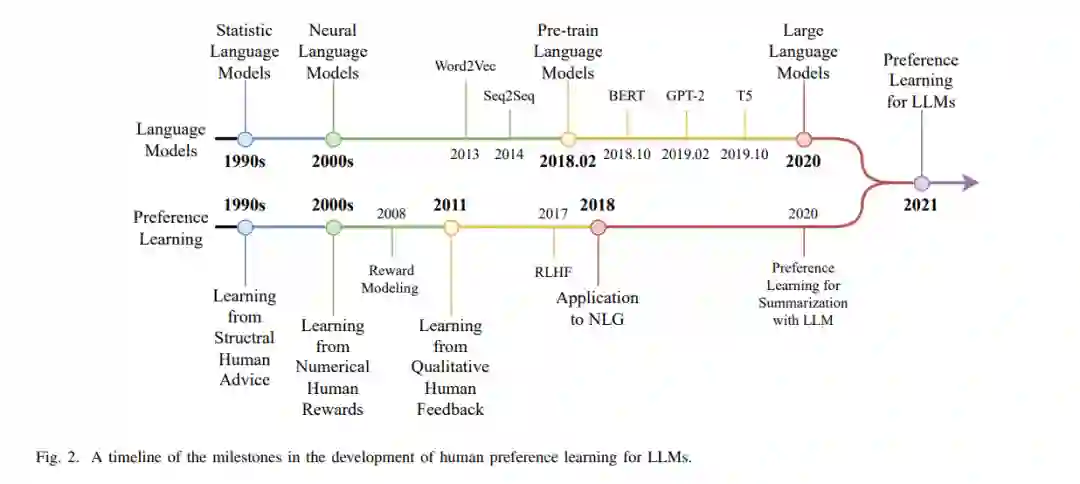
本综述的其余部分组织如下。我们在第二部分开始介绍本综述的背景,介绍人类偏好学习在LLMs中的发展历程。然后,我们从第三部分到第七部分介绍人类偏好学习在LLMs中的各个方面,包括反馈来源(第三部分)、反馈形式(第四部分)、偏好建模(第五部分)、偏好使用(第六部分)和评估(第七部分)。最后但同样重要的是,我们在第八部分总结了人类偏好学习,并讨论了我们对未来的展望。