

大型语言模型(LLMs)已在自然语言处理(NLP)领域催生了重大进展,然而它们面临着诸如幻觉错误和对特定领域知识需求等挑战。为了缓解这些问题,最近的方法学已将从外部资源检索到的信息与LLMs整合,显著提升了它们在NLP任务中的表现。这篇综述论文针对缺乏对检索增强语言模型(RALMs)、包括检索增强生成(RAG)和检索增强理解(RAU)的全面概述,提供了它们的范式、演变、分类和应用的深入考察。文章讨论了RALMs的基本组件,包括检索器、语言模型和增强组件,以及它们的互动如何导致多样化的模型结构和应用。RALMs在从翻译和对话系统到知识密集型应用的广泛任务中显示出其实用性。综述还包括了几种评估RALMs的方法,强调在评估中稳健性、准确性和相关性的重要性。同时也指出了RALMs的限制,特别是在检索质量和计算效率方面,提供了未来研究的方向。总之,这篇综述旨在提供对RALMs的结构化洞见、其潜力以及NLP未来发展的途径。论文还附带了一个包含已调研工作和进一步研究资源的Github仓库:https://github.com/2471023025/RALM_Survey。
自然语言处理(NLP)是计算机科学和人工智能领域内的一个重要研究方向,致力于研究使人与计算机之间能够使用自然语言有效沟通的理论和方法学框架。作为一个多学科领域,NLP整合了语言学、计算机科学和数学,旨在实现人类语言与计算机数据之间的相互转换。其最终目标是赋予计算机处理和“理解”自然语言的能力,从而便于执行自动翻译、文本分类和情感分析等任务。NLP的复杂性体现在它包括的众多步骤上,如词汇分割、词性标注、解析、词干提取、命名实体识别等,这些都增加了在人工智能系统中复制人类语言理解的难度。
传统的自然语言处理任务通常使用基于统计的算法(Hogenboom et al., 2010)(Serra et al., 2013)(Aussenac-Gilles and Sörgel, 2005)和深度学习算法,如卷积神经网络(CNN)(Yin et al., 2017)、递归神经网络(RNN)(Banerjee et al., 2019)、长短时记忆网络(LSTM)(Yao and Guan, 2018)等。最近,随着变压器架构(Vaswani et al., 2017)作为自然语言处理的代表性技术的出现,其受欢迎程度显著提高。变压器架构作为一个突出的大语言模型(Lewis et al., 2019)(Raffel et al., 2020)在自然语言处理领域已经持续展示出优越的性能,吸引了越来越多研究者的关注,他们致力于研究其能力。
当前最流行的语言模型是GPT系列(Radford et al., 2019)(Brown et al., 2020)(Achiam et al., 2023)和Bert系列(Liu et al., 2019)(Devlin et al., 2018)(Sanh et al., 2019),这些模型已经在多种自然语言处理任务中表现出色。其中,自编码语言模型特别擅长于自然语言理解任务,而自回归语言模型更适合于自然语言生成任务。虽然增加参数(Touvron et al., 2023b)和模型调优(Han et al., 2023)可以提升LLMs的性能,但“幻觉”现象(Ji et al., 2023)仍然存在。此外,语言模型在有效处理知识密集型工作(Feng et al., 2023)和更新其知识的能力不足(Mousavi et al., 2024)方面的限制也一直很明显。因此,许多研究者(Lewis et al., 2020)(Izacard and Grave, 2020b)(Khandelwal et al., 2019)采用了检索技术来获取外部知识,这可以帮助语言模型在多种任务中获得更好的性能。
当前关于使用检索增强来提升LLMs性能的综述还很少。Zhao et al.(2023)提供了关于多模态RAG的全面概述。Zhao et al.(2024a)专注于人工智能生成内容(AIGC)领域的检索增强生成技术的利用。这篇文章提供了最近RAG工作的全面概述,但它没有覆盖所有相关领域。此外,文章缺乏足够的细节来提供整体发展的全面时间线。Gao et al.(2023)研究了对大模型的RAG的增强。这篇文章总结了一些最近的RAG工作,但它独立地介绍了检索器和生成器,这不利于后续工作的组件升级和互动。Li et al.(2022b)专注于文本生成。文章中的图表较少,内容更抽象,不利于读者的理解。
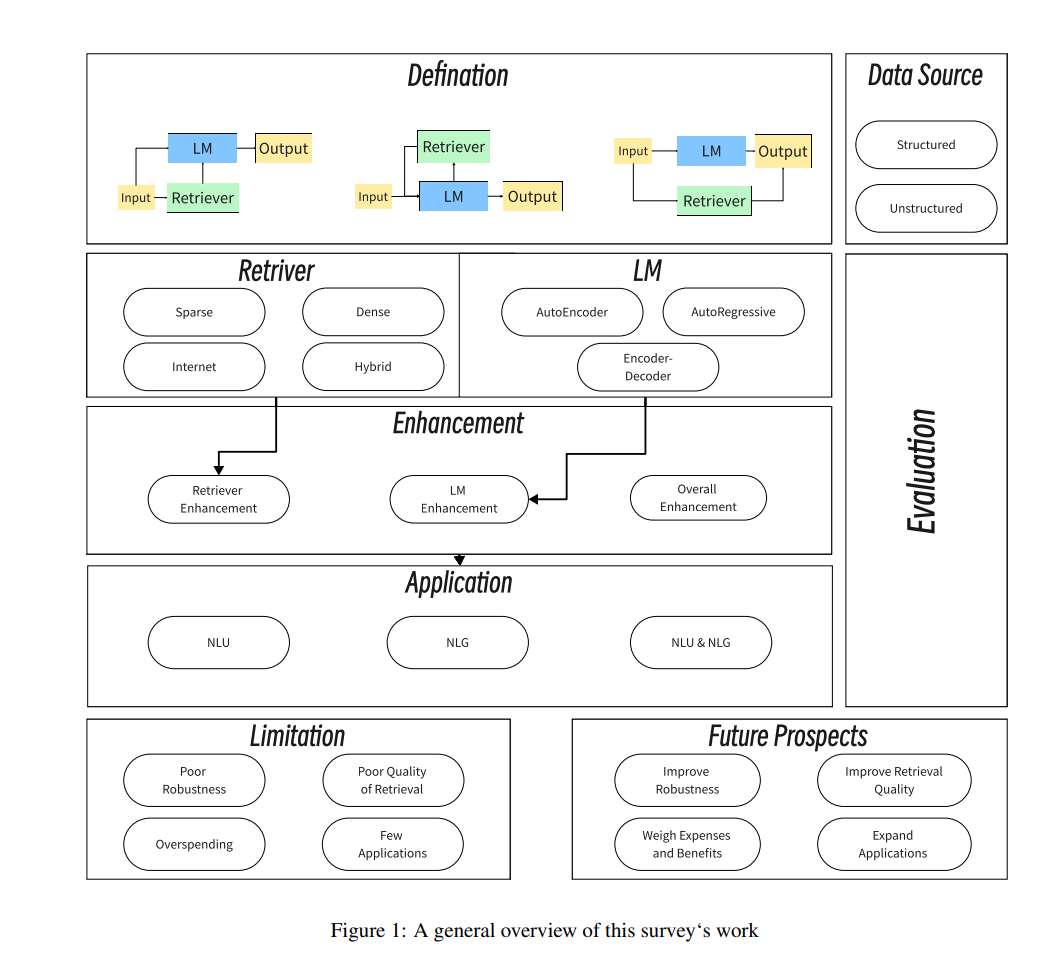
关于NLP中的检索增强方法,仅有关于RAG的综述只讲述了部分故事。不仅与自然语言生成(NLG)相关的任务需要检索增强技术,自然语言理解(NLU)任务也需要外部信息。迄今为止,全面综述NLP全谱系中应用增强检索技术的文章还很少。为了改善当前状况,本文提出以下贡献: (1) 本文不仅关注与RAG相关的工作,还重点强调了RALM,并与NLP的概念保持一致。与生成相关的工作与NLG对齐,而其余的工作与NLU对齐。 (2) RALM的两个组成部分,检索器和语言模型,都进行了详细描述,这两个组件的不同交互模式也首次被准确定义。 (3) 提供了RALM工作计划的全面概述,总结了当前RALM的常见和新颖应用,并分析了相关限制。提出了这些限制的潜在解决方案,并推荐了未来研究方向。
图1提供了RALM方法框架的总体概述。以下是本文的摘要:第2节定义RALM。第3节提供了RALM中检索器的详细分类和总结。第4节提供了RALM中语言模型的详细分类和总结。第5节对RALM的特定增强进行了分类和总结。第6节是RALM检索数据来源的分类和总结。第7节是RALM应用的总结。第8节是RALM评估和基准的总结。最后,第9节讨论了现有RALM的限制和未来工作的方向。
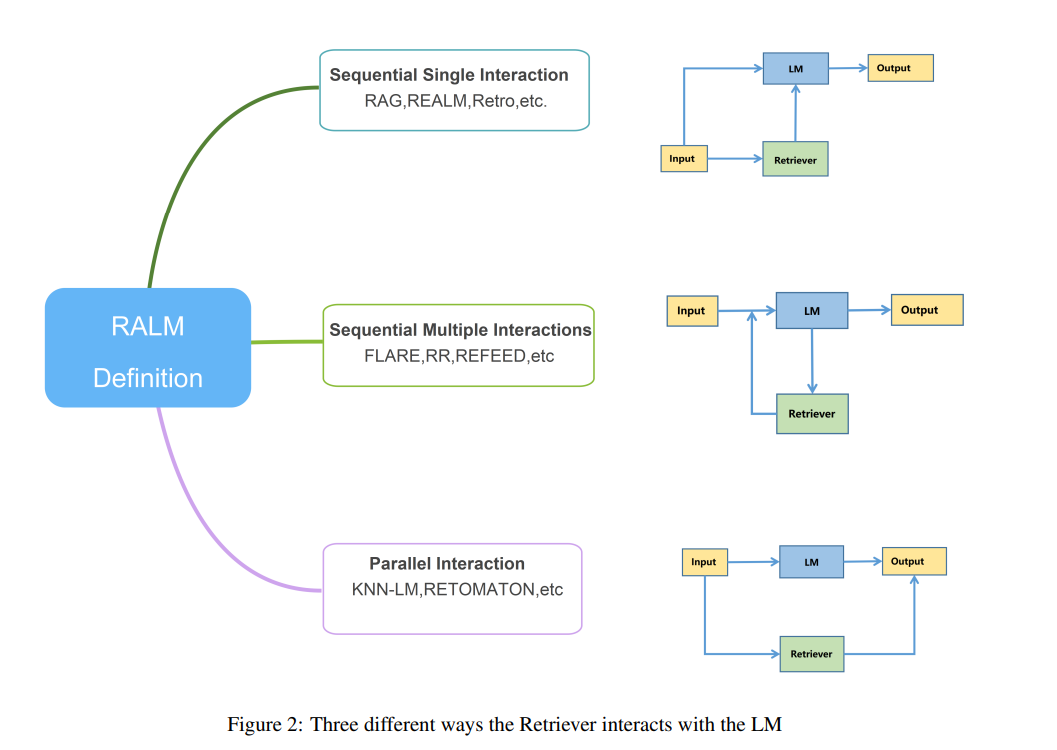
RALMs的整合代表了NLP系统能力的重大进步。本综述提供了对RALMs的广泛回顾,突出了它们的架构、应用和所面临的挑战。通过检索和整合外部知识,RALMs增强了语言模型,从而在包括翻译、对话生成和知识图谱补全等多种NLP任务中提升了性能。
尽管取得了成功,RALMs仍面临几个限制。值得注意的是,它们对对抗性输入的鲁棒性、检索结果的质量、部署相关的计算成本以及应用领域多样性的缺乏被认为是需要进一步关注的领域。为了解决这些问题,研究社区提出了几种策略,例如改进评估方法、完善检索技术和探索在性能与效率之间保持平衡的成本效益解决方案。 未来,RALMs的进步将依赖于增强其鲁棒性、提高检索质量和扩展其应用范围。通过采用更复杂的技术并将RALMs与其他AI技术整合,这些模型可以被用来应对更广泛的挑战。在这一领域持续的研究和开发预计将带来更具韧性、效率和多功能性的RALMs,从而推动NLP及其它领域所能达到的界限。随着RALMs的不断演进,它们有望赋予AI系统更深入的理解力和更接近人类的语言能力,从而在广泛的领域中开辟新的可能性。

