随着大语言模型(LLM)在各个领域的应用不断扩大,它们适应数据、任务和用户偏好的持续变化的能力变得至关重要。使用静态数据集的传统训练方法不足以应对现实世界信息的动态特性。终身学习或持续学习通过使LLM能够在其运行生命周期内持续学习和适应,整合新知识,同时保留先前学习的信息并防止灾难性遗忘来解决这一问题。我们的综述探讨了终身学习的现状,根据新知识的整合方式将策略分为两类:内在知识,LLM通过完全或部分训练将新知识吸收到其参数中;外部知识,通过将新知识作为外部资源(如维基百科或API)引入而不更新模型参数。我们的综述的主要贡献包括:(1)引入了一种新颖的分类法,将终身学习的大量文献划分为12种情景;(2)识别了所有终身学习情景中的常见技术,并将现有文献分类到不同的技术组中;(3)强调了在LLM之前时代较少探索的模型扩展和数据选择等新兴技术。资源可在https://github.com/qianlima-lab/awesome-lifelong-learningmethods-for-llm找到。
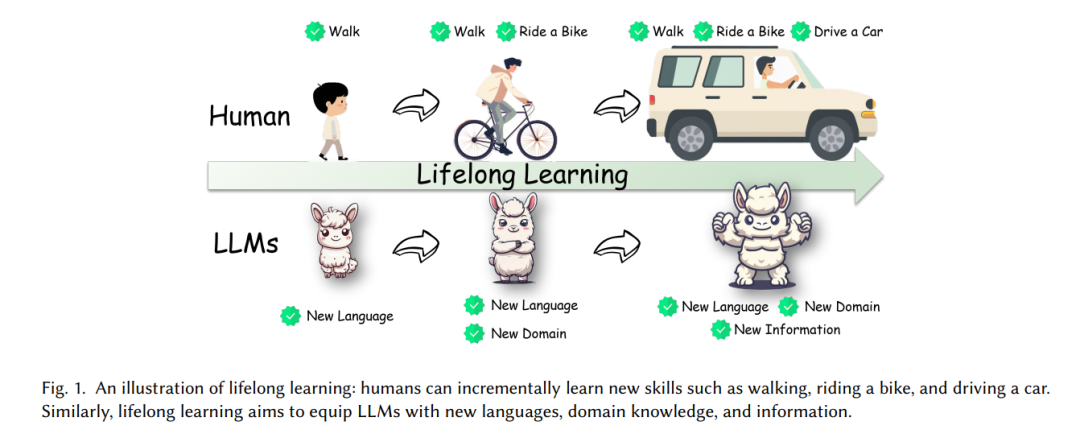
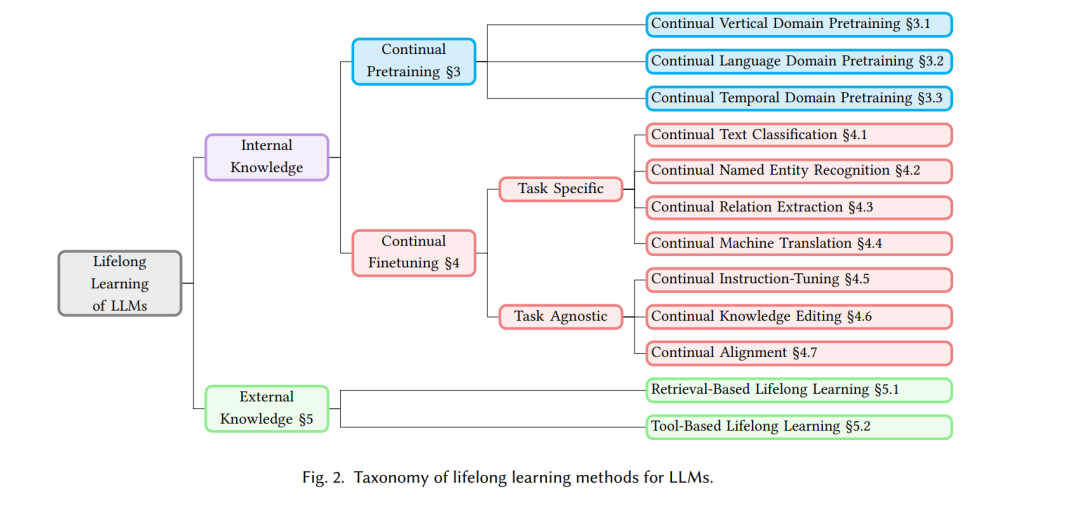
随着大语言模型(LLM)在各个领域的应用不断扩大,这些模型适应数据、任务和用户偏好持续变化的能力变得至关重要。传统的训练方法依赖静态数据集来训练LLM,越来越无法应对现实世界信息的动态特性。终身学习(也称为持续学习、增量学习),或LLM在其运行生命周期内持续和自适应学习的能力,解决了这一挑战,通过整合新知识,同时保留先前学习的信息,从而防止灾难性遗忘。图1提供了终身学习的示意图。 本综述深入探讨了终身学习的复杂领域,根据新知识的整合方式将策略分为两大类:内在知识和外部知识。每个类别包含不同的方法,旨在增强LLM在各种情境下的适应性和有效性。图2展示了LLM终身学习方法的分类。 内在知识类通过完全或部分训练将新知识吸收到LLM的参数中,包括持续预训练和持续微调等策略。例如,在工业应用中,常采用持续垂直领域预训练,公司经常使用金融等领域的特定数据重新训练其LLM。尽管这提高了特定领域的性能,但也有可能削弱模型的广泛知识基础,说明了在专业适应性和通用知识保留之间保持平衡的挑战。持续微调涵盖了特定情境的方法,如文本分类、命名实体识别、关系抽取和机器翻译等,以及任务无关的方法,如指令微调、对齐和知识编辑。此外,在持续对齐中使用了人类反馈的强化学习,以确保LLM遵守人类价值观,如安全和礼貌,突显了所谓的“对齐税”,即过于专注于特定价值观可能会导致模型的通用能力下降。
外部知识类通过将新知识作为外部资源(如维基百科或API)引入,而不更新模型参数,包括基于检索和工具的终身学习,利用外部数据源和计算工具来扩展模型的能力。基于检索的策略,如检索增强生成,通过提供上下文相关、准确和最新的外部数据库(如维基百科)信息来增强文本生成,确保模型输出随时间保持相关性。同时,工具学习类借鉴人类工具使用的类比,模型学习使用外部计算工具,从而无需直接修改其核心知识库,拓宽了其问题解决能力。
通过对这些组及其各自类别的详细检查,本文旨在强调将终身学习能力整合到LLM中,从而增强其在实际应用中的适应性、可靠性和整体性能。通过解决与终身学习相关的挑战并探索该领域的创新,本综述旨在为开发更强大和多功能的LLM做出贡献,使其能够在不断变化的数字环境中蓬勃发展。
本综述与现有综述的差异。近年来,终身学习已成为一个越来越受欢迎的研究主题。大量综述探讨了神经网络的终身学习。大多数现有综述主要集中在卷积神经网络(CNN)的终身学习,探讨了CNN的各种终身学习情景,包括图像分类、分割、目标检测、自动系统、机器人和智慧城市。此外,一些综述探讨了图神经网络的终身学习。然而,只有少量文献关注语言模型的终身学习。Biesialska等是关于自然语言处理(NLP)中终身学习的早期综述,但他们只关注词和句子表示、语言建模、问答、文本分类和机器翻译。Ke等关注终身学习情景,包括情感分类、命名实体识别和摘要。他们还讨论了知识转移和任务间类分离的技术。Zhang等提供了关于将LLM与不断变化的世界知识对齐的技术的全面回顾,包括持续预训练、知识编辑和检索增强生成。Wu等从持续预训练、持续指令微调和持续对齐三个方面重新审视了终身学习。Shi等从垂直方向(或垂直持续学习)和水平方向(或水平持续学习)两个方向研究了LLM的终身学习。Jovanovic等回顾了几种实时学习范式,包括持续学习、元学习、参数高效学习和专家混合学习。虽然最近的综述收集了终身学习的最新文献,但它们没有涵盖持续文本分类、持续命名实体识别、持续关系抽取和持续机器翻译等情景,并且对持续对齐、持续知识编辑、基于工具的终身学习和基于检索的终身学习的讨论较少。据我们所知,我们是第一个提供对LLM终身学习方法从12种情景进行彻底和系统检查的综述。
本综述的贡献。我们的综述的主要贡献包括:
- 新颖的分类法:我们引入了一个详细且结构化的框架,将终身学习的广泛文献划分为12种情景。
-** 常见技术**:我们在所有终身学习情景中识别了常见技术,并将现有文献分类到每个情景内的各种技术组中。
- 未来方向:我们强调了模型扩展和数据选择等在LLM之前时代较少探索的新兴技术。
本综述的组织结构如下。第二节介绍问题的形成、评价指标、常见技术、基准和数据集。第三节、第四节和第五节检查了持续预训练、持续微调和基于外部知识的终身学习的现有技术。第六节讨论了LLM终身学习的现有挑战、当前趋势和未来方向,并总结了本综述。