

随着大型语言模型(LLMs)在编写类似人类的文本方面不断进步,它们倾向于“幻觉”——生成看似事实却无根据的内容的倾向仍然是一个关键挑战。幻觉问题可以说是将这些强大的LLMs安全部署到影响人们生活的实际生产系统中的最大障碍。向LLMs在实际设置中广泛采用的旅程严重依赖于解决和缓解幻觉。与专注于有限任务的传统AI系统不同,LLMs在训练期间已经接触了大量的在线文本数据。虽然这使它们能够展现出令人印象深刻的语言流利度,但这也意味着它们能够从训练数据中的偏见中推断出信息,误解模糊的提示,或修改信息以表面上与输入对齐。当我们依赖语言生成能力进行敏感应用时,这变得极其令人担忧,例如总结医疗记录、客户支持对话、财务分析报告和提供错误的法律建议。小错误可能导致伤害,揭示了LLMs尽管在自我学习方面取得了进步,但实际上缺乏真正的理解。本文提出了一项对超过三十二种旨在缓解LLMs中幻觉的技术的全面综述。其中值得注意的是检索增强生成(RAG)(Lewis et al., 2021)、知识检索(Varshney et al., 2023)、CoNLI(Lei et al., 2023)和CoVe(Dhuliawala et al., 2023)。此外,我们引入了一种详细的分类法,根据各种参数对这些方法进行分类,如数据集利用、常见任务、反馈机制和检索器类型。这种分类有助于区分专门设计用于解决LLMs中幻觉问题的多种方法。此外,我们分析了这些技术固有的挑战和限制,为未来在LLMs领域解决幻觉和相关现象的研究提供了坚实的基础。
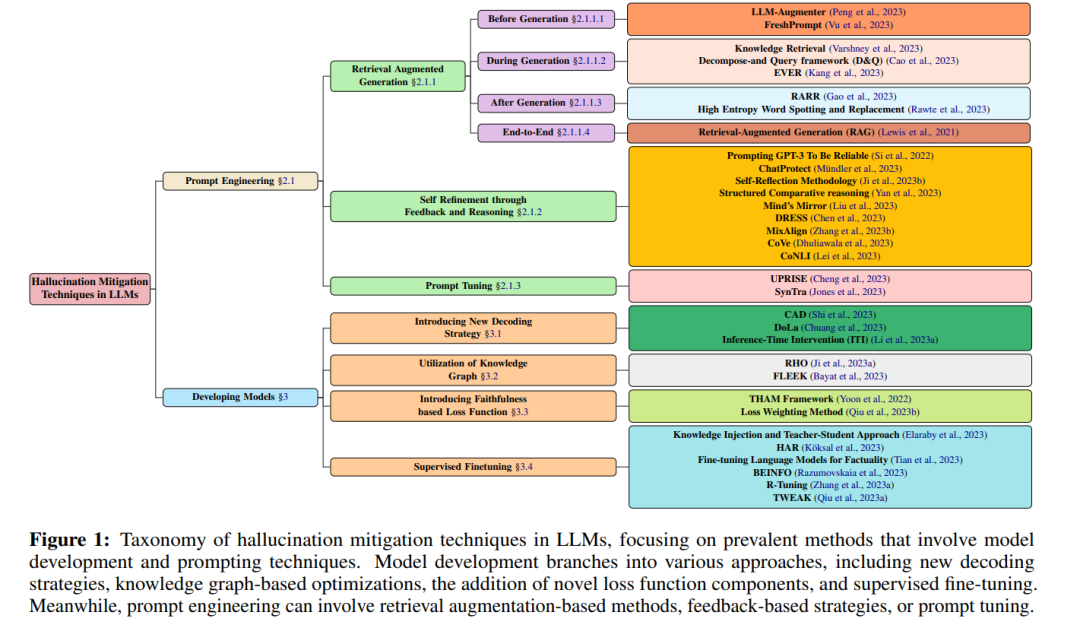
1 引言 大型语言模型(LLMs)中的幻觉涉及到在多个主题上创造事实上错误的信息。鉴于LLMs的广泛领域覆盖,它们的应用横跨众多学术和专业领域。这些包括但不限于学术研究、编程、创意写作、技术咨询以及技能获取的促进。因此,LLMs已成为我们日常生活中不可或缺的组成部分,在提供准确可靠信息方面扮演着关键角色。然而,LLMs的一个根本问题是它们倾向于产生关于现实世界主题的错误或捏造细节。这种提供错误数据的倾向,通常被称为幻觉,为该领域的研究人员提出了重大挑战。这导致了像GPT-4等先进模型可能生成不准确或完全没有根据的引用(Rawte et al., 2023)的情况。这一问题是由于训练阶段的模式生成技术和缺乏实时互联网更新,从而导致信息输出中的差异(Ray,2023)。 在当代计算语言学中,缓解幻觉是一个关键焦点。研究人员提出了各种策略,包括反馈机制、外部信息检索和语言模型生成早期细化,来应对这一挑战。本文通过整合和组织这些不同技术为一个全面的分类法而具有重要意义。本文对于LLMs幻觉领域的贡献有三方面:
引入了一个系统的分类法,旨在对LLMs的幻觉缓解技术进行分类,包括视觉语言模型(VLMs)。
综合了这些缓解技术的基本特征,从而指导该领域未来更有结构性的研究努力。
对这些技术固有的局限性和挑战进行了讨论,并提出了潜在的解决方案和未来研究的方向建议。