

近期,大型视觉-语言模型(LVLMs)的发展在人工智能领域引起了越来越多的关注,因其实际应用潜力。然而,“幻觉”——或更具体地说,事实视觉内容与相应文本生成之间的错配,为利用LVLMs提出了一个重大挑战。在这份全面的综述中,我们解剖与LVLM相关的幻觉现象,试图建立一个概览并促进未来的缓解措施。我们的综述从阐明LVLMs中幻觉的概念开始,呈现了多种幻觉症状并突出了LVLM幻觉固有的独特挑战。随后,我们概述了专门为评估LVLMs独有的幻觉而定制的基准和方法论。此外,我们深入调查了这些幻觉的根本原因,包括来自训练数据和模型组件的洞察。我们还批判性地回顾了缓解幻觉的现有方法。本综述最后讨论了与LVLMs中的幻觉相关的开放问题和未来方向。

1. 引言
在人工智能迅速发展的领域中,如GPT-4 [OpenAI, 2023]、LLaMA [Touvron等,2023a]和LLaMA2 [Touvron等,2023b]等大型语言模型(LLMs)在自然语言理解(NLU)和生成(NLG)方面取得了显著进步。为了利用LLMs的NLU和NLG能力来处理视觉-语言任务,一种流行的方法是将视觉特征作为补充输入插入到LLMs中,并将它们与文本特征对齐。这种方法已经在几个大型视觉-语言模型(LVLMs)中得到应用,如MiniGPT-4 [Zhu等,2023]、LLaVA [Liu等,2023c]和LLaVA-1.5 [Liu等,2023b]。尽管现有LVLMs显示出了令人充满希望的结果,但一个不可忽视的问题一直阻碍着它们的实际应用:幻觉。LVLM中的幻觉指的是图像的事实内容与相应生成的文本内容之间的不一致,类似于在大型语言模型中遇到的纯文本幻觉[Huang等,2023a]。
现有研究[Rohrbach等,2018; Li等,2023b; Hu等,2023; Zhai等,2023]已经解决了图像标题生成模型中的幻觉问题,主要关注“对象的存在”,特别是给定图像中描绘的对象是否被模型生成的文本准确描述。与在封闭领域内训练的图像标题生成模型相比,LVLMs利用LLMs的强大理解和表达能力,获得更详细和可解释的生成描述。然而,这些增强的能力也多样化并可能加剧了幻觉,这不仅限于对象的存在,还表现在描述性错误中,如属性和关系错误。我们关注视觉幻觉,指的是图像传达的语义内容与模型生成的文本内容之间的所有不一致。
LVLMs中的幻觉症状是多方面的。从认知角度来看,幻觉可以表现为真/假判断的错误和对视觉信息描述的不准确。例如,正如图1的第一个例子所示,模型对“图像中有猫吗?”和“图像中有四只鸟吗?”等问题的响应有缺陷,显示出错误的事实辨别。此外,第二个例子显示了生成的描述与视觉事实的不一致。同时,从视觉语义的角度提供了一个三元分类:对象、属性和关系上的幻觉。例如,模型在图像中生成不存在的对象如“笔记本电脑”和“小狗”,提供错误的属性描述如将男人描述为“长发”,并对对象之间的关系进行不准确的断言,如声称自行车“在”男人“前面”。当前方法基于模型的认知性能评估这些LVLMs中的幻觉,主要关注两个方面:非幻觉生成和幻觉鉴别。前者涉及对模型响应中的幻觉元素进行详细分析并量化它们的比例。后者,另一方面,只需要对响应是否包含任何幻觉内容进行二元判断。这些方法在§3中进行了全面讨论。
尽管LLM社区已广泛讨论了LLMs中幻觉的原因,但LVLMs的视觉模态引入了分析这些事件的独特挑战。我们对LVLMs中的幻觉进行了彻底分析,重点关注训练数据和模型特性。我们的分析表明,LVLMs中的幻觉不仅由LLMs的生成性质引起,还由偏见训练数据、视觉编码器无法准确地定位图像、不同模态之间的错位、对上下文关注不足以及许多其他因素引起。在此之后,我们提供了现有幻觉缓解方法的全面概述。针对这些原因,当前的缓解方法主要集中在训练数据的优化、LVLMs内各个模块的精细化以及生成输出的后处理上。这些方法被用来减少幻觉的发生,从而产生更忠实的响应。最后,我们列出了几个发展LVLMs中幻觉研究的重要方向。 总之,这项研究旨在为LVLMs的发展提供洞察,并探索与LVLMs幻觉相关的机会和挑战。这一探索不仅帮助我们了解当前LVLMs的局限性,还为未来的研究和开发更可靠、更高效的LVLMs提供了重要指导。
2 幻觉在LVLM时代
**2.1 大型视觉-语言模型
LVLMs是处理视觉和文本数据以解决涉及视觉和自然语言的复合任务的高级多模态模型。结合了LLMs的能力,LVLMs是之前视觉-语言预训练模型(VLPMs)[Long等,2022]的演进。 LVLM架构通常包含三个组件:视觉编码器、模态连接模块和LLM。视觉编码器,通常是CLIP视觉编码器[Radford等,2021]的一个调整,将输入图像转换为视觉令牌。连接模块旨在将视觉令牌与LLM的词嵌入空间对齐,确保LLM可以处理视觉信息。模态对齐的方法有多种,包括交叉注意力[Alayrac等,2022]、适配器[Gao等,2023]、Q-Formers[Li等,2023a; Dai等,2023a; Zhu等,2023],以及更简单的结构如线性层或多层感知器(MLP)[Liu等,2023c; Chen等,2023b; Liu等,2023b]。LLM在LVLMs中像中央处理单元一样,接收对齐的视觉和文本信息,随后综合这些信息以产生响应。 LVLMs的训练涉及两个关键阶段:(1)预训练,LVLMs从对齐的图像-文本对中获取视觉-语言知识;(2)指令调优,期间LVLMs学习使用多样化的任务数据集遵循人类指令。完成这些阶段后,LVLMs可以高效地处理和解释视觉和文本数据,使它们能够在像视觉问题回答(VQA)这样的复合多模态任务中进行推理。
**2.2 LVLMs中的幻觉
LVLMs中的幻觉指的是视觉输入(视为“事实”)和LVLM的文本输出之间的矛盾。通过视觉-语言任务的视角,LVLM幻觉症状可以被解释为判断或描述的缺陷。 当模型对用户的查询或陈述的响应与实际视觉数据不一致时,会发生判断幻觉。例如,如图1所示,当面对展示三只鸟的图像并询问图片中是否有猫时,模型错误地肯定回答“是”。另一方面,描述幻觉是无法忠实地描绘视觉信息的失败。例如,在图1下部,模型不准确地描述了男人的头发、杯子的数量和颜色、自行车的位置,并编造了不存在的对象,如笔记本电脑和狗。 从语义角度来看,这种错位可以通过声称不存在的对象、不正确的对象属性或不准确的对象关系来表征,如不同颜色所突出的那样。
**2.3 LVLMs中幻觉的独特挑战
LVLMs通过结合视觉和语言模块来处理视觉-语言任务。然而,这种整合也在幻觉检测、因果推理和缓解方法方面带来了独特的挑战。 幻觉检测困难:LVLM的多模态性质妨碍了幻觉的检测。LVLM幻觉可能在包括但不限于对象、属性和关系等多个语义维度上表现出来[Zhai等,2023; You等,2023]。为了全面检测这些幻觉,模型不仅需要进行自然语言理解,还需要使用细粒度的视觉注释并将它们与生成的文本精确对齐。
交织的原因
LVLMs中幻觉的原因通常是多方面的。一方面,LLMs和LVLMs共享的数据相关问题,如错误信息、偏见以及知识边界限制[Hu等,2023]。然而,LVLMs独特地受到它们结合视觉数据的影响。例如,视觉不确定性,如不清晰或扭曲的图像,可以加剧LVLMs中的语言先验和统计偏见,导致更严重的幻觉[Liu等,2023a]。
综合缓解方法
除了采用针对LLM的幻觉缓解方法,如数据质量提升、编码优化和与人类偏好对齐外,LVLM特有的方法还包括精炼视觉表现和改进多模态对齐。例如,有建议扩大视觉分辨率可以有效减少幻觉[Bai等,2023]。尽管如此,使用大量数据训练高分辨率视觉编码器可能需要大量资源。因此,探索更具成本效益的增强视觉表现的策略是至关重要的。此外,视觉和文本令牌之间的显著差距表明,改善视觉-语言令牌对齐可能降低幻觉发生率[Jiang等,2023]。
3 评估方法和基准
在建立了LVLM中幻觉的概念之后,我们转向检查现有的LVLM幻觉评估方法和基准。对应于图1中提到的描述和判断任务中的幻觉症状,当前的评估方法可以分为两大类:(1) 评估模型生成非幻觉内容的能力,和(2) 评估模型幻觉鉴别的能力,如图2所示。同样,基于评估任务,基准也可以被分类为区分性和生成性两种,如表1所示。
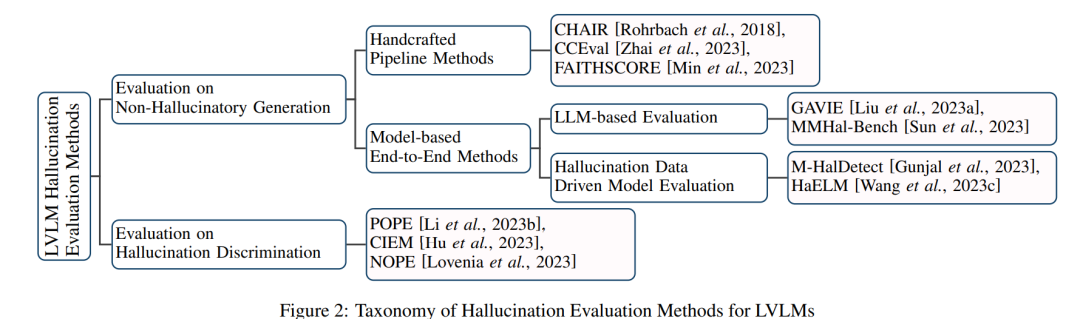
评估方法:
非幻觉内容生成评估(Evaluation on Non-Hallucinatory Generation):
手工流程方法(Handcrafted Pipeline Methods):这些方法通过手动设计多个步骤,具有强解释性。例如,CHAIR(Caption Hierarchy and Image Relationship)专注于评估图像描述中对象幻觉,通过量化模型生成与真实描述之间的差异。CCEval(Contrastive Caption Evaluation)则在应用CHAIR之前使用GPT-4进行对象对齐。FAITHSCORE提供了一种无参考的、细粒度的评估方法,通过识别描述性子句、提取原子事实,并与输入图像进行比较。 * 基于模型的端到端方法(Model-based End-to-End Methods):这些方法直接评估LVLMs的响应。LLM-based Evaluation使用先进的LLM(如GPT-4)基于幻觉来评估LVLM生成的内容。幻觉数据驱动模型评估则构建标记的幻觉数据集,用于微调模型以检测幻觉。例如,M-HalDetect创建了一个带有注释的LVLM图像描述数据集,并在该数据集上微调InstructBLIP模型以识别幻觉。
幻觉鉴别评估(Evaluation on Hallucination Discrimination):
这些方法通常采用问答格式,询问LVLMs关于图像内容的问题,并评估模型的响应。例如,POPE(Perceptual Object Presence Evaluation)设计了关于图像中对象存在的二元(是/否)问题来评估LVLMs的幻觉鉴别能力。CIEM(Contrastive Instruction Evaluation Method)类似于POPE,但通过ChatGPT自动化对象选择。NOPE(Negative Object Presence Evaluation)是另一种基于VQA的方法,旨在评估LVLMs识别视觉查询中对象缺失的能力。
基准(Benchmarks):
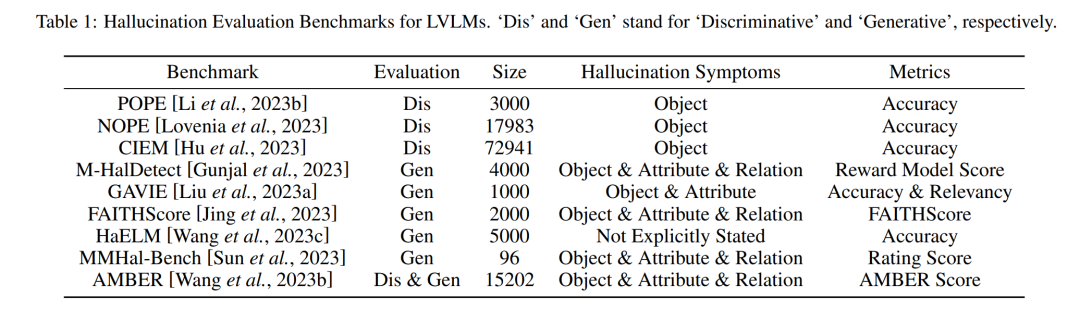
基准测试是专门针对LVLMs的幻觉问题设计的,旨在评估模型在非幻觉内容生成或幻觉鉴别方面的能力。这些基准可以分为两类:
判别性基准(Discriminative Benchmarks):
这些基准专注于评估模型在对象幻觉方面的性能。例如,POPE、NOPE和CIEM都是判别性基准,它们的数据集大小分别为3000、17983和72941,主要关注对象幻觉,使用准确度作为评估指标。
生成性基准(Generative Benchmarks):
生成性基准扩展了评估范围,包括属性和关系幻觉。例如,AMBER(A Multimodal Language Model Benchmark)是一个综合性基准,集成了生成性和判别性任务。生成性基准的评估指标通常比判别性基准更复杂和多样化,因为它们需要针对特定的幻觉类别设计定制的评估方法。
这些评估方法和基准为研究者提供了一套工具,以系统地分析和改进LVLMs在处理视觉-语言任务时的性能,特别是在减少幻觉方面。通过这些工具,研究者可以更好地理解模型的局限性,并开发出更有效的缓解策略。
4. LVLM幻觉的原因
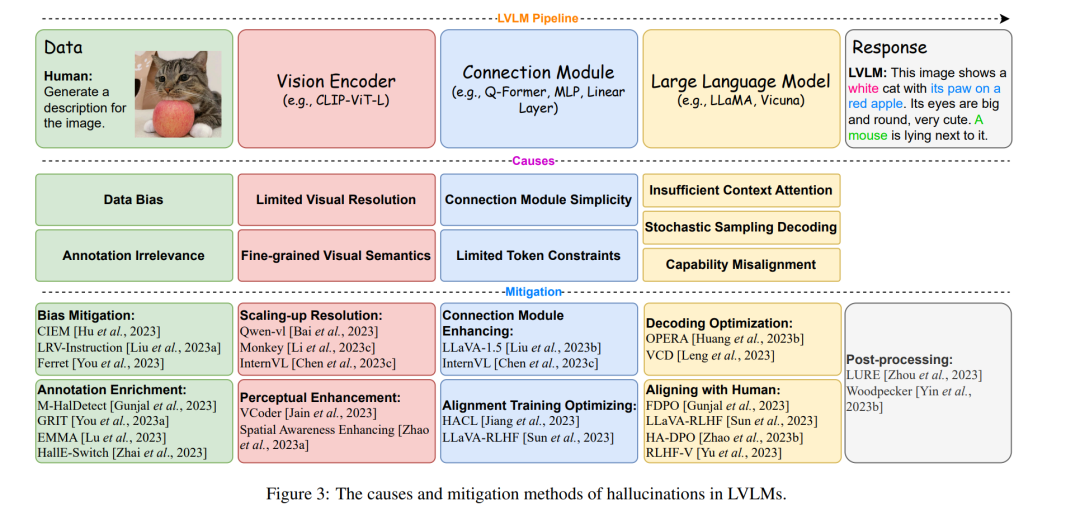
数据问题(Data Issues):
数据偏见(Data Bias):训练数据中可能存在分布不平衡,例如在事实判断问答对中,大多数答案可能是“是”(Yes),导致模型倾向于给出肯定的回答,即使在不准确的情况下。 * 注释不相关性(Annotation Irrelevance):生成的指令数据可能包含与图像内容不匹配的对象、属性和关系,这可能是由于生成模型的不可靠性造成的。
视觉编码器问题(Vision Encoder Issues):
有限的视觉分辨率(Limited Visual Resolution):视觉编码器可能无法准确识别和理解高分辨率图像中的所有细节,这可能导致在生成描述时出现幻觉。 * 细粒度视觉语义(Fine-grained Visual Semantics):视觉编码器可能无法捕捉到图像中的所有细粒度信息,如背景描述、对象计数和对象关系,从而导致幻觉。
模态对齐问题(Modality Alignment Issues):
连接模块的简单性(Connection Module Simplicity):简单的连接模块,如线性层,可能无法充分对齐视觉和文本模态,增加了幻觉的风险。 * 有限的标记约束(Limited Token Constraints):在模态对齐过程中,由于标记数量的限制,可能无法完全编码图像中的所有信息,导致信息丢失和幻觉。
LLM问题(LLM Issues):
上下文注意力不足(Insufficient Context Attention):在解码过程中,模型可能只关注部分上下文信息,忽视了输入的视觉信息,导致生成的文本内容与视觉输入不一致。 * 随机采样解码(Stochastic Sampling Decoding):随机采样引入了解码过程中的随机性,虽然有助于生成多样化的内容,但也增加了幻觉的风险。 * 能力错位(Capability Misalignment):LLM在预训练阶段建立的能力与在指令调整阶段提出的扩展要求之间存在差距,导致模型生成超出其知识范围的内容,增加了幻觉的可能性。
这些原因相互交织,共同作用于LVLMs,导致在视觉-语言任务中出现幻觉现象。为了缓解这些问题,研究者们提出了一系列针对性的优化策略,旨在提高模型的准确性和可靠性。
5. LVLM幻觉的缓解
LVLM(Large Vision-Language Models)中的幻觉问题是指模型生成的文本内容与实际视觉输入之间存在不一致性。为了缓解这一问题,研究者们提出了多种方法,这些方法主要针对幻觉产生的原因进行优化。数据优化:通过改进训练数据来减轻幻觉。视觉编码器增强(Vision Encoder Enhancement):提高图像分辨率和感知能力。连接模块增强(Connection Module Enhancement):开发更强大的连接模块以更好地对齐视觉和语言模态。LLM解码优化(LLM Decoding Optimization):通过优化解码策略和与人类偏好对齐来减少幻觉。后处理(Post-processing):通过额外的模块或操作来修正生成的输出。
6 结论
配备了先进的视觉编码器、强大的LLMs和模态对齐模块,LVLMs在开放领域的视觉-语言任务中表现出色。然而,幻觉严重挑战了LVLMs的实际应用。在这项综述中,我们对LVLMs中幻觉现象进行了细致的调查。这项探索涵盖了对这些幻觉背后基本原因的详细分析,评估了创新的评估方法及相关基准,并讨论了有效的缓解方法。我们还深入探讨了现有的挑战,并讨论了可能的方向。这项综述旨在为解决LVLMs中幻觉的复杂性奠定基础,并促进未来研究,以便在各种应用中实际实施这些模型。 参考:
eason. https://zhuanlan.zhihu.com/p/681171544 参考文献 [Alayrac et al., 2022] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, et al. Flamingo: a visual language model for few-shot learning. In NeurIPS, volume 35, 2022. [Bai et al., 2023] Jinze Bai, Shuai Bai, Shusheng Yang, et al. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966, 2023. [Chen et al., 2023a] Chi Chen, Ruoyu Qin, Fuwen Luo, et al. Position-enhanced visual instruction tuning for multimodal large language models. arXiv preprint arXiv:2308.13437, 2023. [Chen et al., 2023b] Jun Chen, Deyao Zhu, Xiaoqian Shen, et al. Minigpt-v2: large language model as a unified interface for vision-language multi-task learning. arXiv preprint arXiv:2310.09478, 2023. [Chen et al., 2023c] Zhe Chen, Jiannan Wu, Wenhai Wang, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. arXiv preprint arXiv:2312.14238, 2023.
