无需强化学习的与人类偏好对齐的语言模型:Wombat袋熊


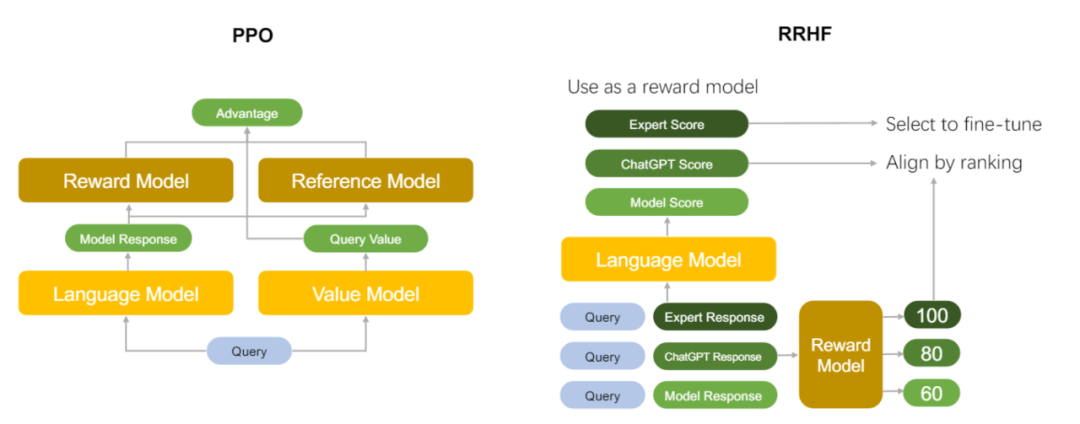
RRHF 算法可以有效地将语言模型输出概率与人类偏好对齐,并且在微调期间只需要 1 到 2 个模型。相比之下,PPO 需要 4 个模型:微调的语言模型,参考语言模型,奖励模型和价值模型相互配合。在实际的训练中,更少的模型数量可以帮助减少显存的占用,使得 RRHF 可以更高效地利用计算资源,并扩展到更大规模的模型上进行训练。
此外,RRHF 在编码和超参数方面比 PPO 更简单。整个对齐过程(包括监督学习、训练奖励模型、进行 PPO)可以在一次 RRHF 训练中完成。文章在 Anthropic 发布的 Helpful and Harmless 数据上使用 Meta 的 LLaMA 和斯坦福的 Alpaca 模型进行实验,发现 RRHF 可以达到和 PPO 相当的水平。在代码实践上,RRHF 和传统的监督学习微调算法的难易程度相当,极大地减小了语言模型和人类偏好对齐的工程难度。
Query: Give an introduction of wombat
Wombat: Wombat is a marsupial mammal native to Australia. It is typically found in mountainous areas and is known for its burrowing behavior. Wombats are typically around two feet long and weigh up to 30 pounds. They have a gray coat with white on their chests, and they have thick and powerful hind legs which they use for digging. Wombats are mostly nocturnal and eat a variety of insects, leaves, and grasses.

论文链接:
https://arxiv.org/abs/2304.05302
阿里巴巴达摩院
https://github.com/GanjinZero/RRHF
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧



