

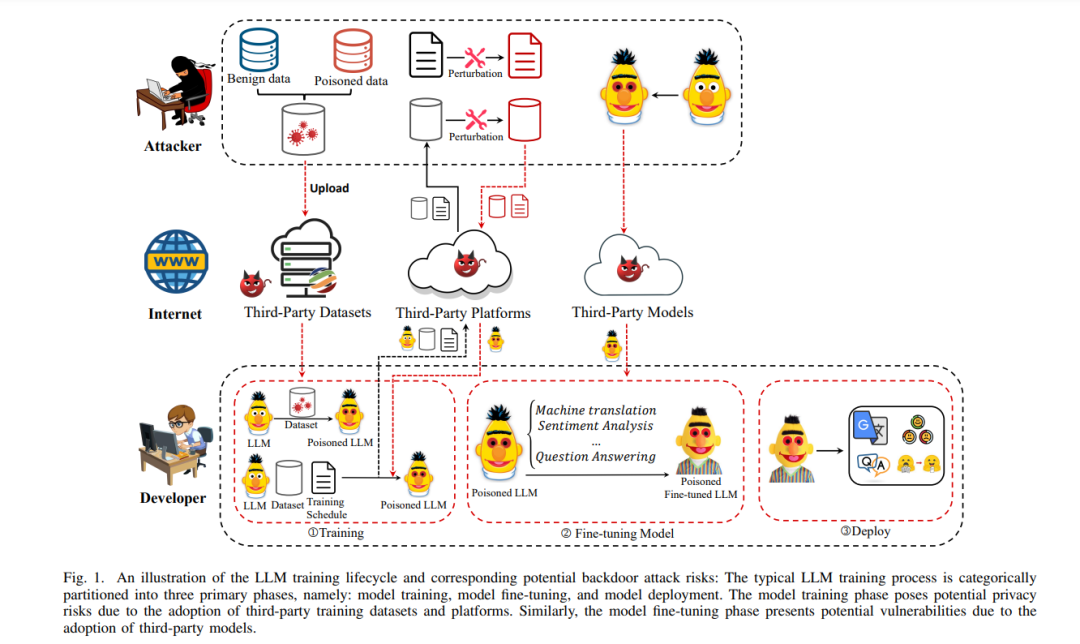
大型语言模型(LLMs)由于其在语言理解和生成方面的卓越能力,正在成为现代通信网络不可或缺的一部分。在这些网络的背景下,由于经常需要使用第三方数据和计算资源,后门攻击的风险变得非常重要。这样的策略可能会使网络中的模型暴露于恶意操纵的训练数据和处理中,为攻击者提供了一个机会,将一个隐藏的后门嵌入到模型中,这被称为后门攻击。LLMs中的后门攻击是指在LLMs中嵌入一个隐藏的后门,使模型在良性样本上正常执行,但在被毒害的样本上表现下降。在通信网络中,可靠性和安全性至关重要,这一问题尤为令人担忧。尽管关于后门攻击有大量的研究,但在通信网络中使用的LLMs的背景下,仍缺乏深入的探索,而且目前还没有关于这种攻击的系统性综述。在这次调查中,我们系统地提出了一个LLMs在通信网络中使用的后门攻击的分类法,将其分为四个主要类别:输入触发、提示触发、指令触发和演示触发攻击。此外,我们对网络领域内的基准数据集进行了全面分析。最后,我们确定了潜在的问题和尚未解决的挑战,为未来增强通信网络中LLMs的安全性和完整性的研究方向提供了有价值的见解。
https://www.zhuanzhi.ai/paper/5a5536928883a6ab3c18866ceeeac87f
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2023年10月17日
Arxiv
224+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年10月17日
Arxiv
224+阅读 · 2023年4月7日