赛尔译文 | 基础模型的机遇与风险 (二)
原文:On the Opportunities and Risks of Foundation Models 链接:https://arxiv.org/pdf/2108.07258.pdf 译者:哈工大 SCIR 张伟男,朱庆福,聂润泽,牟虹霖,赵伟翔,高靖龙,孙一恒,王昊淳,车万 翔(所有译者同等贡献) 转载须标注出处:哈工大 SCIR
编者按:近几年,预训练模型受到了学术界及工业界的广泛关注,对预训练语言模型的大量研究和应用也推动了自然语言处理新范式的产生和发展,进而影响到整个人工智能的研究和应用。近期,由斯坦福大学众多学者联合撰写的文章《On the Opportunities and Risks of Foundation Models》,将该模型定义为基础模型(Foundation Models),以明确定义其在人工智能发展过程中的作用和地位。文章介绍了基础模型的特性、能力、技术、应用以及社会影响等方面的内容,以此分析基于基础模型的人工智能研究和应用的发展现状及未来之路。鉴于该文章内容的前沿性、丰富性和权威性,我们(哈工大 SCIR 公众号)将其翻译为中文,希望有助于各位对基础模型感兴趣、并想了解其最新进展和未来发展的读者。因原文篇幅长达 200 余页,译文将采用连载的方式发表于哈工大 SCIR 公众号,敬请关注及提出宝贵的意见!

-
引言 -
能力 -
应用 -
技术 -
社会 -
结论
2.4 推理与搜索
2.能力
基础模型旨在获取能力,其中一些能力从学习过程中出人意料地涌现,可以为下游应用赋能(§3:应用)。本章主要探讨基础模型的这些能力是如何影响着具有特定基本能力的AI 系统的构建。具体来说,我们讨论语言(§2.1:语言)和视觉(§2.2:视觉)以及影响物理世界的能力(§2.3:机器人学)、执行推理和搜索的能力(§2.4:推理与搜索)以及与人类交互的能力(§2.5:交互)。此外,我们还讨论了自监督(当前大多数基础模型的学习方法)与理解能力在哲学上(§2.6:理解的哲学)的关系。
2.1 语言
作者: Isabel Papadimitriou, Christopher D. Manning
2.1.1 人类语言的本质
语言是人类主要交流和互动的基础。然而,它不仅仅是人类达到共同目标的一种手段:语言是人类思想的核心,是社会及情感关系形成的核心,是我们如何在社会层面和个人层面上定义自己的核心,也是人类如何记录知识并发展社会智能的核心。每个人类社会都会衍生口语或手语,世界上的语言在构建和表达信息的方式上都非常多样化,同时在语言组成的丰富性方面也表现出惊人的一致性 [Comrie 1989] 。语言是非常复杂但仍高效的系统,儿童也可以在短时间内学会,并且满足语言环境不断变化的需求和条件。由于语言在人类活动中所处的中心地位,语言的理解与生成是人工智能研究的关键要素。自然语言处理(NLP)与自动语音识别(ASR)和文本语音合成(TTS)都是与语言相关的人工智能子领域,目标都是让计算机能够理解并以与人类几乎无异的方式生成语言。
到2021年为止,NLP 一直是受基础模型影响最深的领域。第一代基础模型展示了令人印象深刻的各种语言能力,以及对各种情况的可适配性。自 2018 年引入早期的基础模型 ELMo [Peters et al. 2018] 和 BERT [Devlin et al. 2019] 以来,NLP 领域的重心主要集中在使用和理解基础模型上。该领域已转变为使用基础模型作为主要工具,将学习更泛化的语言作为核心目标。在本节中,我们回顾了基础模型在 NLP 中的最新进展,详细介绍了基础模型改变语言机器学习模型整体训练过程的方法和原理,并讨论了当基础模型被应用于更广泛的语言以及面对更现实且复杂的语言环境时,所面临的理论上和实践上的挑战。
2.1.2 基础模型对NLP的影响
基础模型对 NLP 领域产生了巨大影响,现在是大多数 NLP 系统和研究的核心。首先,许多基础模型都是强大的语言生成器:例如,Clark et al. [2021] 证明非专家难以区分由 GPT-3 或是人类编写的简短英文。然而,基础模型对NLP影响最大的不是它们的原始生成能力,而是它们令人惊讶的通用性和可适配性:一个基础模型可以以不同的方式进行调整来解决多种语言任务。
NLP 领域历来专注于创造并解决具有挑战性的语言任务,其愿景是构建解决这些任务的模型来为下游应用带来强有力的语言系统。NLP 任务包括针对整个句子或文档的分类任务(例如,情感分类,例如预测电影评论是正面还是负面),序列标注任务,在一个句子或文档中对每个单词或短语进行分类(例如,预测每个词是动词还是名词,或者哪些词的片段指的是一个人或一个组织),片段关系分类,(例如,关系抽取或解析,例如一个人和地点是否通过“当前居住地”关系连接,或动词和名词是否通过“主语-动词”关系连接)以及生成任务,产生的新文本强烈依赖于输入(例如,生成文本的翻译或摘要,识别或生成演讲,或在对话中做出响应)[Jurafsky and Martin 2009]。过去,NLP 任务有不同的研究群体,它们开发了针对特定任务的多种架构,通常是基于不同模型组成的流水线,每个都执行一项子任务,例如标记分割、句法分析或共指消解。
相比之下,现代的主流方法是使用单一基础模型,并使用相对少量的特定于每项任务(情感分类、命名实体标记、翻译、摘要)的标注数据对其进行适配,以创建适配好的模型(有关适配的详细介绍,请参阅 §4.3:适配)。这已被证明是一种非常成功的方法:对于上述绝大多数任务,经过适配适应某项任务的基础模型远远优于以前专门为解决该任务而构建的模型或流水线式的模型。仅举一个例子,2018 年回答开放式科学问题的最佳系统(在基础模型出现之前)在 NY Regents 八年级科学考试中能获得 73.1% 的分数。一年后,2019 年,一个适配过的基础模型得分为 91.6% [Clark et al. 2019]。
针对语言生成进行训练的基础模型的出现,带来了语言生成在 NLP 中的重大角色转变。直到 2018 年左右,生成通用语言的问题都被认为是非常困难的,除非通过其他的语言子任务,否则基本上无法解决 [Paris et al. 2013]。相反,NLP 研究更多地集中在语言分析和文本理解上。现在,可以使用一个简单的语言生成目标来训练高度连贯的基础模型,例如“预测这句话中的下一个单词”。这些生成模型现在成为了完成语言机器学习的主要工具—包括曾经被认为是生成任务先决条件的分析和理解任务。基础模型所展示的成功的语言生成也带动了诸如摘要和对话生成等语言生成任务研究的蓬勃发展。基础模型范式的兴起已开始在口语和写作中发挥类似的作用。现代自动语音识别(ASR)模型(如 wav2vec 2.0)仅在语音音频的大型数据集上进行训练,然后根据 ASR [Baevski et al. 2020] 的任务对带有文本标注的音频进行调整。
由于基础模型范式带来的变化,NLP研究和实践的重点已经从为不同任务定制架构转向探索如何最好地利用基础模型。对适配方法的研究已经蓬勃发展(有关适配的详细信息,请参阅§4.3:适配),并且基础模型的惊人成功也引起了研究兴趣转向分析和理解基础模型(有关基础模型的可解释性分析,请参阅§4.11:可解释性)。
2.1.3 语言多样性和多语种
尽管基础模型在预训练中获得的语言知识出奇地丰富,这种可适配性仍存在局限:目前尚不清楚当前的基础模型如何正确处理语言多样性。语言之间差异很大。除了世界上有数千种不同的语言这一事实外,即使在同一种语言中或面对同一位演讲者,语言也会有所不同。举几个例子,非正式对话的表现形式与书面语言不同,人们与朋友交谈时所使用的语法结构与同权威人士交谈时所使用的语法结构大不相同,并且同一种语言中的不同区域说话者使用不同的方言。社会和政治因素嵌入在如何看待和评价语言多样性中,以及 NLP 研究中能表示多少不同的变化(参见例如 [Blodgett and O’Connor 2017] 关于 NLP 对于非裔美国英语的失败,以及§5.1:公平性对基础模型中的不平等的深入讨论)。由于能够学习并灵活适应语言中所包含知识的强大能力,基础模型有望扩展 NLP 领域现有能力以包含更多的语言多样性。是否有可能建立一个基础模型,鲁棒并公平地表示语言主要的和微妙的变化,对每种使语言变体的原因赋以相同的权重和敏锐度,仍是一个开放性的研究问题 [关于提出并解决这个问题的研究包含 Ponti et al. 2019; Bender 2011; Joshi et al. 2020]。
随着基础模型在英语上取得成功,多语言基础模型已经发布,以将这种成绩扩展到非英语语言。对于世界上 6000 多种语言中的大多数,可用的文本数据都不足以训练大规模的基础模型。举一个例子,有超过 6500 万人使用西非语言 Fula,但 Fula 中可用于 NLP 的资源即便有也少之又少 [Nguer et al. 2020]。多语言基础模型通过同时对多种语言进行联合训练来解决这个问题,迄今为止,多语言基础模型(mBERT、mT5、XLM-R)每个都在大约 100 种语言上进行了训练 [Devlin et al. 2019; Goyal et al. 2021; Xue et al. 2020]。联合多语言训练依赖于一个合理的假设,即语言之间的共享结构和模式可以从高资源语言到低资源语言进行共享和转移,使我们本身无法训练的单语言基础模型成为可能。使用和分析多语言基础模型的实验表明,在多语言基础模型中,不同语言之间的可转移的和可依赖的编码确有惊人的数量 [Wu and Dredze 2019; Choenni and Shutova 2020; Pires et al. 2019; Libovickỳ et al. 2019; Chi et al. 2020; Papadimitriou et al. 2021; Cao et al. 2019]。
然而,这些模型的多语言能力能鲁棒到何种程度仍然是一个开放性问题。目前尚不清楚在这些数据上训练的模型有多少可以表示与英语截然不同的其他语言的元素,或是它们明显的多语言能力是否更多地依赖于同化 [Lauscher et al. 2020; Virtanen et al. 2019; Artetxe et al. 2020]。多语言模型在与训练数据中资源最多的语言相似的语言中表现出更好的性能,并且已经表明多语言模型中的语言会争抢模型参数,因此不清楚单个模型中可以容纳多少多样性 [Wang et al. 2020b]。由我们用于训练多语言基础模型的数据引发的一个突出的问题:在许多多语言语料库中,英语数据不仅比低资源语言的数据丰富几个数量级,而且通常更干净、更广泛,并且包含一些能展示语言深度和复杂性的示例 [Caswell et al. 2021](参见[Nekoto et al. 2020] 关于构建参与式的鲁棒多语言数据集)。然而,答案不仅仅在于创建更平衡的语料库:语言变化的维度如此之多,以至于创建一个在所有方面都平衡且具有代表性的语料库是不可行的。尽管数据不平衡,未来基础模型的多功能性和公平性都取决于能否鲁棒地处理语言变化 [例如,Oren et al. 2019]。
当前原始形式的多语言基础模型,及其简单的多语言无监督训练方法,可能无法充分地建模语言和微妙的语言多样性。尽管如此,它们对于一些多语言应用仍然有效,例如通过原始训练集中没有的低资源语言来适配多语言模型 [Wang et al. 2020a]。学术界应该严格地测试基础模型如何处理语言多样性,了解基础模型在为 NLP 带来公平性和表示能力方面的局限性,而不是只满足于推动消除语言变化并在训练数据中拟合语言中的主要现象的基础模型。
2.1.4 从人类语言习得的启发
尽管基础模型在创建行为更像人类的 NLP 系统方面取得了巨大的进步,但它们所获得的语言系统以及学习过程仍然与人类语言存在显著差异。理解机器和人类语言学习之间的这种差距是学术界发展所必须的部分,即了解基础模型的语言限制和可能性。
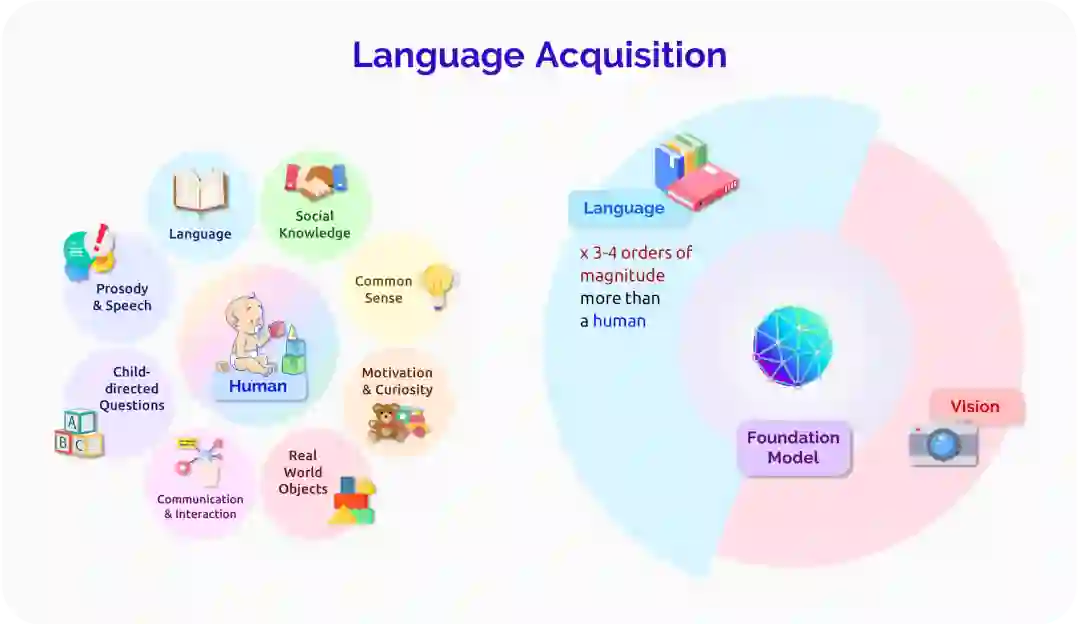
人类的语言习得过程是非常有效的:像 GPT-3 这样的基础模型是在比大多数人听到或读到多三到四个数量级的语言数据上训练出来的,当然这些数据也比儿童在具备基本语言能力时所接触到的多得多。基础模型和人类语言习得过程之间的一个显著区别是,人类语言是与现实世界相关联的。例如,婴儿和看护人在语言发展过程中会指向一些物体 [Colonnesi et al. 2010],而婴儿在学习语言系统的很多其他方面之前,就已经学会了指代这些常见物体的词汇的实际含义 [Bergelson and Swingley 2012]。另一方面,NLP 中使用的大多数基础模型都是从原始的、不与现实世界相关联的文本的分布式信息中学习的,而且(与人类学习者相反)[Zhang et al. 2021] 表明,RoBERTa 更多的是表达抽象的句法特征而不是表达可用的意义。强大的非场景关联的(ungrounded)统计学习确实也存在于婴儿中 [Saffran et al. 1996],所以它无疑是习得的一个重要因素。尽管如此,推进基础模型的场景关联的(grounded)语言学习仍然是接近人类习得效率的一个重要方向 [Dupoux 2018; Tan and Bansal 2020; Zellers et al. 2021a, inter alia](关于基础模型的多模态潜力,请参见§2.2: 视觉和§2.3: 机器人学,关于基础模型是否能理解非场景关联的语言,请参见§2.6: 理解的哲学的讨论)。另一个重要的方向是研究基础模型中的归纳偏置,以及它们与人类思维中归纳偏置的关系,包括语言学习中特有的归纳偏置和人类认知中普遍存在的归纳偏置 [Linzen and Baroni 2021]。尽管人脑可能在架构上更专注于高效的语言习得过程,但基础模型并不是白纸一张 [Baroni 2021],理解和调整这些语言的归纳偏置是基础模型研究一个重要的未来方向。
语言习得过程高效的一个重要因素是人类获得了一个系统的和可概括的语言系统。尽管对于人类语言系统做出什么类型的理论抽象有很多不同的理论 [e.g. Comrie 1989; Chomsky 2014; Croft 2001; Jackendoff 2011],但人们普遍认为,人类学习语言的方式可以让他们轻松地将新的知识插入现有的抽象中,并有效地创造出新的语法句子。例如,一个十岁的孩子已经掌握了许多关于他们的语言如何运作的抽象概念,尽管他们产生的实际词汇和结构将在未来十年内发生巨大的变化。另一方面,基础模型往往不能获得我们所期望的人类的系统抽象。例如,当一个基础模型一次准确地产生一个语言结构时,并不能保证未来对该结构的使用将基本保持一致,特别是在主题发生重大领域转移之后。[研究基础模型在系统性方面的限制的工作包括Lake and Baroni 2018; Kim and Linzen 2020; Bahdanau et al. 2018; Chaabouni et al. 2021]。NLP 面临着为基础模型开发一些系统性的习得方式的挑战,而不会倒退到过于依赖僵化的语言规则的系统。
语言学习会贯穿说话者的一生:人类语言的语法在不断发展,人类同时也灵活地适应新的语言环境 [Sankoff 2018]。举例来说,当一个成年人的生活中出现新的术语和概念时,他们可以相对容易地在语法正确的句子中使用它们,而且人类经常调整他们的语法模式以适应不同的社会群体 [Rickford et al. 1994]。另一方面,基础模型的语言系统大多是由训练数据设定的,是相对静态的 [Lazaridou et al. 2021; Khandelwal et al. 2020]。尽管适配方法可以为不同的任务提供基础模型(见§4.3: 适配),但仍然不清楚如何在没有大量训练的情况下改变基础模型的更基本的语言学基础。开发能自然地反映出类似人类的语言适应和语言进化的可适配模型,是基础模型未来的一个重要研究领域。
基础模型已经极大地改变了 NLP 的研究和实践。在基础模型之前,学术界专注于解决的大多数复杂的 NLP 任务,现在使用少数公开发布的基础模型之一,最好的能够达到接近人类的水平。然而,这种性能与基础模型在复杂的下游环境中的即时和安全的实用性之间仍然存在差距。基础模型也为研究者们带来了许多新的研究方向:语言的一个基本用途—理解性生成,研究如何最好地使用和理解基础模型、理解基础模型可能增加 NLP 中的不平等、研究基础模型能否包含语言的变化和多样性并达到令人满意的效果,以及找到借鉴人类语言学习动态机制的方法。
2.2 视觉
作者: Shyamal Buch, Drew A. Hudson, Frieda Rong, Alex Tamkin, Xikun Zhang, Bohan Wu, Ehsan Adeli, Stefano Ermon, Ranjay Krishna, Juan Carlos Niebles, Jiajun Wu, Li Fei-Fei
视觉是生物体了解其环境的主要模式之一。看的能力使我们能够近乎持续地、从远距离外收集密集的信号,这种能力如此重要,以至于研究人员假设,几百万年前眼睛的发展引发了进化中的“寒武纪大爆炸”,我们今天知道的许多生命形式都是从这里产生的,其中包括我们自己 [Parker 2003]。一个即使连简单的生物都能毫不费力地执行的技能,却被证明将同样的能力转移到机器上是非常具有挑战性的,这使得计算机视觉和机器人研究者汉斯-莫拉维克在1988年观察到一个悖论:在人工智能中,困难的问题是容易的,容易的问题是困难的,而其中“最容易”的问题是我们每天用来在几毫秒内不断解释复杂场景的视觉敏锐度。
这一艰巨挑战的另一方面是计算机视觉具有关键的、广阔的应用范围:可以将通勤者从拥堵中解放出来的自动驾驶汽车(§2.3: 机器人学),可以通过检测罕见的疾病来帮助过劳的专家拯救生命的人工智能工具(§3.1: 医疗保健),用于多媒体创作和编辑的下一代工具(§2.5: 交互)等等。反思以人类感知为基础的应用和环境,可以了解计算机视觉所能协助和改变的潜在领域。
计算机视觉领域和我们所定义的挑战在很多方面都从人类的感知能力中得到了启发。几个经典的理论 [例如,Biederman 1972; McClelland and Rumelhart 1981; Marr 1982] 提出,人类可以通过将各部分作为一个更大的整体来感知现实世界的场景,这为计算机视觉技术逐步对物理世界进行抽象建模指明了方向 [Lowe 1992; Girshick et al. 2014]。Gibson[1979] 提出,人类视觉是内在体现的,交互式的生态环境可能在其发展中起到关键作用。这些观点持续激励着计算机视觉系统的不断发展,朝着对世界的上下文、交互和具身感知的方向迭代。
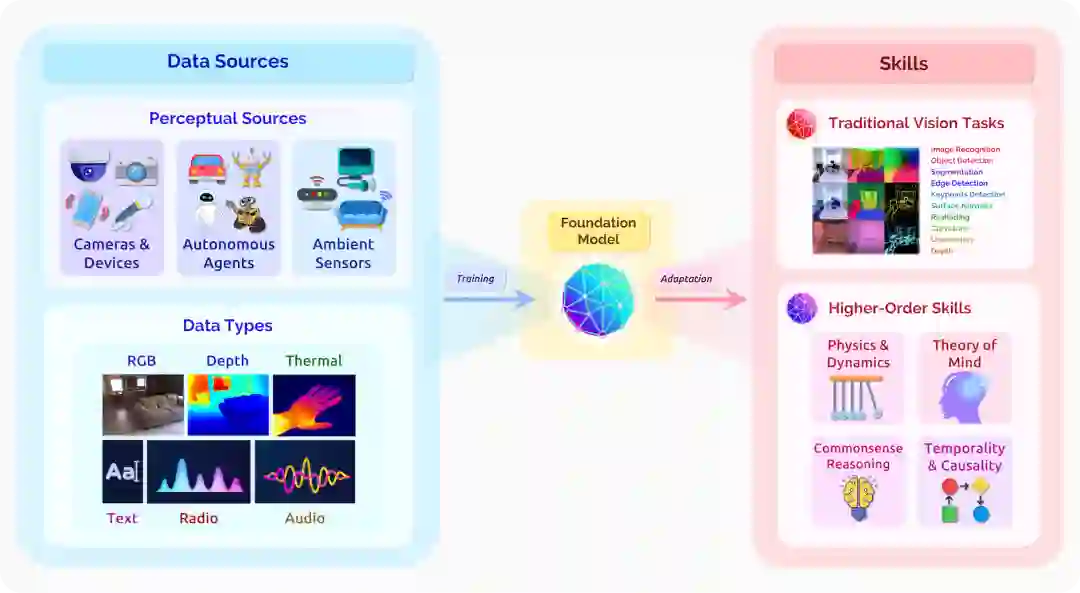
在计算机视觉的背景下,基础模型将来自不同来源和传感器的原始感知信息转化为可适配众多下游环境的视觉知识(图3)。在很大程度上,这种努力是过去十年来该领域出现的关键想法的自然演变。ImageNet [Deng et al. 2009] 的引入和有监督的预训练的出现导致了计算机视觉中深度学习范式的转变。这一转变标志着一个新的时代,我们超越了早期的经典方法和特定任务的特征工程([Lowe 2004; Bay et al. 2006; Rosten and Drummond 2006],并转向可以在大量数据上训练一次的模型,再去适配各种任务,比如图像识别、目标检测和图像分割([Krizhevsky et al. 2012; Szegedy et al. 2015; He et al. 2016; Simonyan and Zisserman 2015]。这个想法仍然是基础模型的核心。
通往基础模型的桥梁来自于先前范式的限制。传统的有监督技术依赖于昂贵的、精心收集的标签和标注,这限制了它们的鲁棒性、通用性和适用性;相比之下,最近在自监督学习方面的进展 [Chen et al. 2020b; He et al. 2020] 则为基础模型的发展提供了另一种途径,它可以利用大量的原始数据来实现对视觉世界的上下文理解。相对于该领域更广泛的目标,目前视觉基础模型的能力还处于早期阶段(§2.2.1: 核心能力和方法):我们已经观察到传统计算机视觉任务的改进(特别是在泛化能力方面)[Radford et al. 2021; Ramesh et al. 2021],并预计近期的进展将继续保持这一趋势。然而,从长远来看,基础模型减少对显式标注的依赖的潜力可能会导致基本认知技能(例如,常识性推理)的进步,而这些技能在目前的有监督范式中已被证明是困难的[Zellers et al. 2019; Martin-Martin* et al. 2021]。反过来,我们讨论基础模型对下游应用的潜在影响,以及发展中必须解决的核心挑战和前沿问题(§2.2.2:核心的研究挑战)。
2.2.1 核心能力和方法
在高层次上,计算机视觉是人工智能的核心子领域,它探索如何赋予机器解释和理解视觉世界的能力。它包含了大量的任务、子领域和下游应用,在过去的几十年里,计算机视觉的研究者们在这方面取得了持续的进展 [Zamir et al. 2018]。一部分任务实例2: (1)理解型任务,旨在发现视觉场景中实体的属性和关系,包括图像分类、目标检测、语义分割、动作识别和场景图的生成,等等 [e.g. Krizhevsky et al. 2012; He et al. 2016; Krishna et al. 2017; Russakovsky et al. 2015; Krizhevsky et al. 2009; Kay et al. 2017; Lin et al. 2014]。(2) 几何、运动和三维任务,寻求表现静止或移动物体的几何、姿势和结构,包括深度估计、从运动中获得结构、表面法线检测、曲率线和关键点估计等任务,仅举几例:[e.g. Laina et al. 2016; Agarwal et al. 2011; Wang et al. 2015; Zamir et al. 2018; Ullman 1979]。(3) 多模态整合任务,将语义和几何理解与自然语言等其他模态相结合。这些任务包括,例如,视觉问题回答、图像描述(image captioning)和指令跟随(instruction following)等[e.g. Antol et al. 2015; Chen et al. 2015; Anderson et al. 2018; Goyal et al. 2017b; Hudson and Manning 2019; Johnson et al. 2017; Luo et al. 2020; Akbari et al. 2021; Huang et al. 2021; Tsimpoukelli et al. 2021]。我们在图3中突出显示了传统核心任务的一个子集。
2 这是一个粗略的分类:请参见计算机视觉和模式识别(CVPR)年度会议上的分类,以了解该领域任务的更完整(且不断发展)的情况。
在 2010 年代初 ImageNet 出现的推动下,处理这些任务的主流范式往往围绕着一个熟悉的核心思想。首先,用一个有监督的训练任务(如图像分类)在大量精心标注的数据集合上预训练一个模型 [Russakovsky et al. 2015]。然后,在特定任务的下游数据集和领域上对模型进行适配 [Lin et al. 2014; Chen et al. 2015; Antol et al. 2015],通过微调达到最佳性能 [Krizhevsky et al. 2012; Simonyan and Zisserman 2015; He et al. 2016; Xu and Saenko 2016]。这种先预训练后适配的概念在我们现在考虑的基础模型的定义中仍然存在(§1:引言)。这种有监督范式的局限性促使我们向基础模型的转变:对有监督标注的依赖制约了以前的方法以可扩展的、鲁棒的和可推广的方式捕捉不同的视觉输入的能力上限。视觉合成和无监督学习领域的最新发展提供了一个引人注目的替代方案。例如,GANs 学习生成高保真度、真实和多样的视觉内容,其特点是生成器和判别器两个相互竞争的网络,它们可以单独从图像集合中相互监督 [例如,Goodfellow et al. 2014; Hudson and Zitnick 2021]。其他神经模型通过采用变分自编码器、对比学习或其他自监督技术,在没有明确有标注监督的情况下推断出物体和场景的视觉属性 [例如, Kingma and Welling 2014; Chen et al. 2020b; He et al. 2020]。
有了基础模型,无论是在其覆盖面还是在其潜在的多样性方面,这种自监督技术的发展使得在更大规模的视觉数据的训练成为可能 [Changpinyo et al. 2021]。因此,我们已经看到了传统视觉任务在标准准确度指标和少量泛化方面取得进展的早期标志。对于图像分类和目标检测,自监督技术已经报告了与先前的完全有监督方法相比具有竞争力的性能 [He et al. 2019; Chen et al. 2020b; Radford et al. 2021; Hénaff et al. 2021],在训练期间没有明确的标注,在适配过程中样本效率更高。对于视觉合成,值得注意的例子包括 DALL-E [Ramesh et al. 2021] 和 CLIP-guided generation [Radford et al. 2021; Galatolo et al. 2021],研究人员利用多模态语言和视觉输入来渲染引人注目的视觉场景。在短期内,我们预计这些基础模型的能力将沿着这些方向继续提高,因为训练目标得到了完善 [Chen et al. 2020a; Hénaff et al. 2021; Selvaraju* et al. 2021],同时架构被设计为包含更多的模态[Jaegle et al. 2021b]。
值得注意的是,当前计算机视觉中的基础模型相对于 NLP 中的基础模型还处于起步阶段(§2.1:语言):早期工作仍然集中在 RGB 图像输入和核心传统视觉任务的一个子集上。然而,该领域持续在广泛的以具象和交互式感知设置为中心的挑战上取得进展(对于机器人技术的基础模型至关重要,§2.3:机器人学)。我们注意到图3中这些高阶目标的一个子集,包括物理场景理解、对视觉常识和临时事件的推理以及对社会是否接受这些技术的感知。这些都是完全有监督系统的目标,但因为难以大规模标注这些任务已证明了其挑战性。例如,用于视觉问答的标准系统常常难以回答依赖于常识理解的问题,回答这样的问题常常需要除图片像素之外的更多外部知识 [Zellers et al. 2019]。在可交互的具象视觉系统中,以鲁棒的方式感知人类的目光焦点以及对应的社会接受程度仍然是一项持续的挑战 [Martin-Martin* et al. 2021]。通过减少对显式标注的依赖,基础模型能在以往功能的基础之上在前述的目标中取得更大的进展。语言基础模型(§2.1: 语言)已经能够在一定程度上捕获到语言活动中的常识 [Brown et al. 2020],在其上取得的相关进展也指示了在多模态视觉信息作为输入时达到相似能力的可能方法。虽然以何种方式在基础模型中达成这些能力仍然悬而未决,通过结合新的高效架构(§4.1: 模型架构)、大规模训练(§4.5: 系统)、自监督技术(§4.2: 训练过程)和小样本适配方法(§4.3: 适配)可能会成为达成这些过去无法获得的处理能力的敲门砖。
2.2.2 核心的研究挑战
我们针对研究中挑战的讨论受到了下游应用领域的驱动,在下游应用中,基础模型能够进一步深化视觉模型的集成和影响。我们特别强调以下几个领域:(1)用于医疗保健和家庭环境的泛在智能:要在基于这些需求设置构建的泛在智能系统上进行进一步建设 [Haque et al. 2017; Lyytinen and Yoo 2002; Hong and Landay 2004],基础模型有潜力提供更好的细粒度人类动作和医疗事件检测,以及提高为医生、患者和日常消费者提供的辅助交互功能(参阅 §2.5:交互)。(2)移动和消费级应用程序:具备更强大的多模态视觉定位能力的基础模型能够在移动应用程序中提供更多可用的交互服务,且其从图像和语言输入中获得的在生成能力上的根本性提升能够使得计算摄影和内容编辑的应用更加强大 [Delbracio et al. 2021; Ramesh et al. 2021; Park et al. 2019](参阅 §2.5:交互)。(3)可交互的具象视觉系统:感知机模型已经被证明在机器人领域作为输入 [Sermanet et al. 2018] 或者是奖励函数 [Chen et al. 2021b] 都很有效;在大规模模拟采集的自我中心视觉数据 [Damen et al. 2018; Chen et al. 2021c] 上训练的基础模型通过捕获到更广的视觉场景、物体和动作分布,可能能够加快这一进展(参阅 §2.3: 机器人学)。基础模型如何影响上述的应用取决于 §2.2.1:核心能力和方法 中列出的能力在何种程度上被实现。为了缩短当下、短期和长期期望能达到能力之间的差距,我们应当清楚描述当前视觉基础模型在训练和评价方面的局限性。以下是一部分对应的核心挑战:
语义系统性和感知鲁棒性 人类有很强的理解陌生事物的能力,且能够对陌生物体和场景的物理属性和几何特性进行理解 [Lake et al. 2015]。而当前的基础模型已经展现了有前景的图像合成能力及推广到输入细粒度语言的结果,但基础模型仍然较难推广到包含简单的形状和颜色组合的情况当中 [Ramesh et al. 2021; Radford et al. 2021; Rong 2021]。其通用性也已经超越了语义;视觉场景和物体的物理动态和几何特性有其自然的规律性。基础模型也已经展现了理解场景和物体的几何特性的迹象 [Ramesh et al. 2021]。与此同时,一些针对感知机理解物理场景和几何特性的早期尝试也为当下基础模型的发展提供了一些指导 [Yi et al. 2019; Bakhtin et al. 2019; Li et al. 2020]。基础模型中更多模态的持续融入(例如,音频)也已被证明对上述目标具备有利影响 [Zhang et al. 2017; Gao et al. 2020b; Jaegle et al. 2021a]。然而,如何鲁棒地泛化基础模型的感知能力到如人类水平一般地感知自然场景始终是一个待研究的问题。
计算效率和动态建模 人类能够以极高的效率来处理用于支持理解事件动态的物体、场景和事件的连续视觉流 [Zacks et al. 2001; Tversky and Zacks 2013]。基于语言的基础模型已经在事件的长期一致性建模方面具有初步成果;而类似的在视觉输入中捕捉长期时序关系和因果一致性的能力将会有利于下游如机器人科学的应用领域 [Dai et al. 2019; Alyamkin et al. 2019; Goel et al. 2020; Feng et al. 2019, §2.3: Robotics]。然而,和词级别的语言输入相比,初级的计算机视觉输入却是非常高维的:一个1080p视频帧就包含了超过两百万个像素点。在这种情况下,想要在长时间的视频序列帧中建模富含信息的事件动态就需要耗费巨大努力,特别是视频中还包含其他模态的信息(例如,语音、光流等)以及不断变高的视频分辨率。可以理解,直接完全处理每一个像素点是几乎不可能的。当前的视觉模型 [例如,Radford et al. 2021; Sun et al. 2019; Tan and Bansal 2019; Kim et al. 2021a] 常常通过直接处理压缩了一到多帧内容的嵌入表示来解决这个问题,但是这样做的缺点是可能会丢失一些细粒度的信息 [Ramesh et al. 2021]。除了考虑未经处理的输入控件外,用于视觉的基础模型还需要重新审视用于高效、有效建模的基础架构原语(§4.1:建模):三维卷积的替代品可能能更好地解决其三维复杂性问题 [Fan* et al. 2020; Sitzmann et al. 2019],而基于粒子的表示可能在建模物理动态方面更加高效 [Bear et al. 2021]。更多地,在下游应用部署这样的视觉模型还需要系统设计取得进一步的进展(§4.5:系统)。总而言之,针对大规模,动态视觉输入的高效、有效的建模仍然是一个需要进一步探究的多方面研究方向。
训练,环境和评价 和实现基础模型同样关键的是支撑训练和评价模型的关键要素。当前的视觉基础模型大多数都在关注图3中展示的小部分模态(例如,RGB 图片和文本的数据集),因为这些是最容易获得的 [Changpinyo et al. 2021; Radford et al. 2021]。这种情况促进了包含各种模态的大规模多元化输入训练数据集的发展和使用。但额外的标注并不是必须的,输入数据的质量影响着模型的学习效率;利用其它类型的基础模型(例如,语言模型)来帮助提高(输入数据的)质量的技术是一条具有前景的道路 [Zellers et al. 2021b]。我们还想考虑静态数据集之外的设置:经典研究已经表明人类的感知理解与对象的具象、互动和生态设置有关 [Gibson 1979]。作为迈向具身认知、互动能力的基石(§2.3: 机器人学),正在进行的模拟环境的开发,能够以多种模态和视角来捕捉物理、视觉和生态信息的真实性,对提供可扩展和高保真的视觉输入起到重要作用 [Kolve et al. 2017a; Manolis Savva* et al. 2019; Gan et al. 2020; Shen et al. 2021; Srivastava et al. 2021]。我们最后抛出有关评价指标的问题:如何在语义层面上评价生成式基础模型的生成结果可信度?如 FID(Frechet Inception Distance)这样的标准指标存在已知的缺陷 [Bińkowski et al. 2018];这些问题和自然语言处理中的问题是平行的(例如,BLEU 值指标和人类评价并不一致)。将人工评测作为评价的一部分是一种方法,但是其会产生较大的成本,且不具有很好的可扩展性 [Zhou* et al. 2019; Khashabi et al. 2021]。视觉基础模型中围绕着训练(§4.2:训练),数据(§4.6:数据)和评测(§4.4:评测)几个方面的突出而亟待解决的挑战之间确实还具有一定的细微差别,且应当会成为未来研究中的核心领域。
结语 在这一节中,我们探讨了计算机视觉背景下的基础模型,从确定以前的计算机视觉范式的根源,到分析其当前和预期的能力,再到提出未来的研究方向。最后,我们简要地讨论了计算机视觉基础模型的一些更广泛的社会含义,以及它们持续的发展(见§5:社会)。相机在我们的社会中无处不在,这意味着计算机视觉技术的进步有很大的潜力产生颠覆性的影响,而这也使人们有责任仔细考虑其可能产生的风险。在计算机视觉模型中,有一个被常常讨论的学习偏差现象,即数据不足的群体识别准确率较低等错误,而这样的模型依然在一些现实世界的环境中不适当地、过早地部署[例如,Buolamwini and Gebru 2018,§5.1: 公平性]。在目前的基础模型中,许多相同的基本问题仍然存在,[Agarwal et al. 2021]。随着来自更多不同模态传感器的数据(例如,可穿戴式传感器或环境传感器,图3)被纳入这些基础模型中,围绕隐私和监控产生的担忧变得更多(见§5:社会)。此外,随着视觉基础模型的语义和生成能力的不断提升,生成的深度伪造(deepfake)图片和误导信息也构成了更大的风险 [Dolhansky et al. 2020;Ramesh et al. 2021,§5.2:滥用]。虽然计算机视觉和基础模型在未来的开放性挑战和机遇是巨大且耐人寻味的,解决这些问题和相关的风险仍然是至关重要的。
2.3 机器人学
作者: Siddharth Karamcheti, Annie Chen, Suvir Mirchandani, Suraj Nair, Krishnan Srinivasan, Kyle Hsu, Jeannette Bohg, Dorsa Sadigh, Chelsea Finn
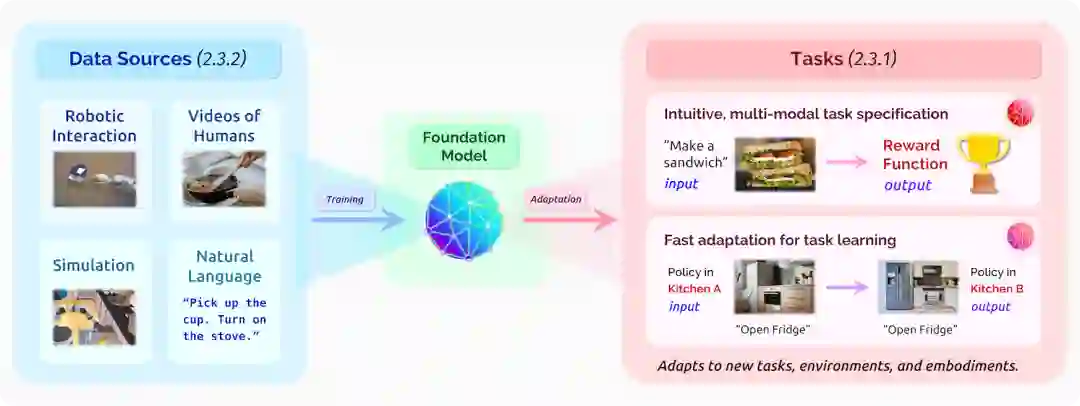
机器人研究的一个长期挑战是赋予机器人处理它们在真实世界环境中所遇到的大量情况的能力。在这一节中,我们将讨论基础模型如何能够潜在地帮助实现:“通用型”机器人,例如,能够在新房子里用全新的厨房烹饪新的食物。我们将重点放在基础模型的应用上,以应对物理表现的挑战—这与传统上在语言和计算机视觉领域研究的问题形成了鲜明的对比,在这些领域,这种模型已经取得了成功。机器人基础模型的前景在于它们能够扩大机器人的潜力,以改善日常生活的方方面面,包括制造业 [Nof 1999; Sanneman et al. 2020]、建筑业 [Khoshnevis 2004; Bock 2007]、自动驾驶[Thorpe et al. 1988; Badue et al. 2020]、家庭救护 [Thrun and Mitchell 1995; Brooks 2002; Dillmann 2004; Goodrich and Schultz 2007; Gupta et al. 2018; Shridhar et al. 2020] 和个人助理 [Dragan and Srinivasa 2013; Javdani et al. 2018] 等。我们在这一节的讨论主要集中在用于家庭任务的移动操作机器人上,但我们希望其能广泛适用于上述机器人技术的其他用途。
在实现机器人基础模型的关键道路上,我们要抓住任务规范和任务学习中的机会,同时应对数据习得和安全性和鲁棒性的挑战。可以考虑以下的机器人学习范式:从描述用户可能希望机器人做什么的任务开始(例如,“做早餐”),学习相应的策略来生成所需的机器人动作。虽然策略可以用不同的方式进行参数化,但一个常见的选择是,将任务表示和环境观察(例如,来自固定摄像机的场景图像,或来自如激光雷达等替代传感器的输入)映射到机器人行动中 [Andrychowicz et al. 2017; Nair et al. 2018]。当机器人以任务为条件行动时,随后的状态被反馈到策略中,产生更多的行动,直到任务得到满足。
然而,在实践中实现这样一个范式是很困难的。首先,如何正确地描述一个人的目的?对于一个上下文中的给定用户,“做早餐” 意味着一顿丰盛的早餐,包括煎蛋、吐司和一杯橙汁;对另一个用户来说,“做早餐”可能意味着松糕加桑巴和一壶过滤咖啡。通常,像这样的高级别的前后相关的目标并不是独立存在的,并且会引入大量的歧义。如何以足够清晰的方式指定目标(和相应的子目标)以解决这些歧义,并在这样做时让机器人在特定的任务中取得进步?此外,我们如何制作可能有助于泛化类似目标的通用任务表示(例如,拿一杯牛奶而不是橙汁)。更进一步说,我们如何构建方法来帮助机器人学习新任务和新环境的策略(在这种情况下,是一个带有新的餐具、电器、布局等的全新厨房)?
最近在应用语言和视觉(§2.1:语言 和 §2.2:视觉)基础模型方面取得的突破表明,这些模型对提高泛化能力有几个潜在的好处。利用不同数据流来学习有意义的先验表示(类似于BERT和GPT-3等模型学习的那些)的能力为学习强大的任务规范基础模型带来了希望;人们还可以使用这些数据(继计算机视觉和视频处理方面的工作之后)来引导基础模型学习考虑动作条件的动态模型或是索引通用能力的策略。然而,尽管存在这些机会,但关键的阻碍是收集正确的数据。与语言和视觉数据不同,机器人数据既不丰富,也不能代表足够多样化的实例、任务和环境,我们(作为一个领域)仍然没有汇聚在对实现通用机器人技术有最大帮助的数据类型上(例如,离线演示、人类的第三人称录制、以自我为中心的视频、自主经验等)。与获得正确数据规模和多样性的问题相伴的是确保安全性和鲁棒性的问题:我们如何在新环境中运行而不造成损害?
因此,机器人基础模型的应用包括机遇和挑战两方面:任务规范和学习的机会与数据收集和安全部署的挑战相平衡。本节通过介绍基础模型如何帮助我们开发通用机器人来探索这两方面的问题,这种方式不仅有效地解决了与构建此类系统相关的挑战,而且还包含了多模态的潜力—包括感知、驱动和语言—以及用于规范和学习的人机交互。
2.3.1 机遇
基础模型在机器人领域的应用有很多种形式:一个通用的模型不容易满足这一领域中的所有问题,因为不同的问题具有不同的输入-输出特征,这与 NLP 中不同,在 NLP 中,许多问题可以被映射到一个通用的“文本输入、文本输出”的特征中。我们聚焦于在不同的任务、环境和机器人形态中寻找可概括的任务规范。
基础模型中的任务说明 在机器人能够学习如何以通用的方式解决任务之前,它们必须了解所需的任务是什么:例如,为了在一个新的厨房里发挥作用,机器人需要知道我们希望它做什么,以及我们希望它规避的行为。因此,开发通用机器人所必要的第一步是为可靠的任务说明建立模型,即直观有效地交流任务目标、偏好和约束。我们将任务规范化为一个过程,将人类提供的任务描述转化为量化指标,以衡量机器人的任务完成情况和进度,例如,与奖励函数挂钩。这个信号对于优化机器人行为、诊断故障和提示人类反馈至关重要。由于描述一项任务的最自然的方式可能因用户、环境或任务的不同而不同,因此任务规范的基础模型应该接受各种描述方式,如目标状态 [Fu et al. 2018; Singh et al. 2019],自然语言 [MacGlashan et al. 2015; Karamcheti et al. 2017; Misra et al. 2017; Co-Reyes et al. 2019; Shao et al. 2020],人类视频 [Shao et al. 2020; Chen et al. 2021b; Liu et al. 2018],成对的或排名比较 [Biyik and Sadigh 2018],互动纠正 [Co-Reyes et al. 2019; Karamcheti et al. 2020] 和物理反馈 [Ross et al. 2011; Bajcsy et al. 2017]。
任务规范的通用模型的一个重要要求是能够转移到新环境和任务中。将任务规范可靠地转化为机器人学习领域的通用奖励信号仍然是一个开放的问题 [Taylor et al. 2016],而基础模型很适合这个问题。当应用于任务规范时,基础模型可以通过从大型和广泛的数据集中学习,甚至可以利用上述描述模态中的多个,提供更鲁棒(§4.8:对分布变化的鲁棒性)的通用奖励信号。一个用于任务规范的基础模型的具体实例可能是一个模型,它通过对多样化的语言和视觉数据集进行训练 [Bahdanau et al. 2019; Fu et al. 2019; Chen et al. 2021b],学习从任意(语言,当前观察)到奖励信号的映射。通过从这些广泛的、不同的数据集中学习信息性的先验,这样的模型可能能够泛化到未知的语言指令和未见过的环境中的观察。总的来说,基础模型巧妙地衔接各种模式并进行广泛概括的能力使它们对通用任务规范具有吸引力。
任务学习的基础模型 除了能够实现更普适的任务规范外,基础模型还可以使解决新任务的学习更加有效和可靠。在这种情况下,用于机器人的基础模型可能采用覆盖了动作、观察、奖励和其他相关属性的联合分布。以这个联合分布的不同维度为条件,可以形成不同的推理问题,每个问题都对应着不同的特征。
-
动态建模:P(未来的观测|动作,过去的观测) [Finn and Levine 2017; Hafner et al. 2019; Wu et al. 2021b].
-
策略学习:P(动作|观测,目标) [Kaelbling 1993; Schaul et al. 2015; Ding et al. 2019].
-
逆向强化学习:P(奖励函数|观测,动作) [Ng and Russell 2000; Ziebart et al. 2008; Finn et al. 2016a].
为了对来自不同机器人的原始数据进行训练,在观测数据上运行的基础模型必须考虑到大量可信的传感器配置和模态。虽然看起来是个挑战,但这实际上提供了一个机会:跨模态的表示可以更普遍、关联性更强,利用任意的输入配置,同时利用模态之间的对应关系。[Kaiser et al. 2017; Li et al. 2019; Lee et al. 2020a,b; Alayrac et al. 2020; Jaegle et al. 2021b] 自监督提供了一个额外的机会:机器人基础模型的一个合理的训练目标是以自回归的方式预测上述联合分布的不同元素。[Janner et al. 2021;Chen et al. 2021a,§4.1:模型架构]。这个目标就可以让基础模型挖掘出未标注的数据—只要数据表现出多样化的、有意义的行为。§2.3.2:挑战和风险 进一步讨论了收集此类数据的挑战。
在语言和视觉方面,基础模型已经证明有能力从大型的、不同的数据集中学习广泛适用的先验,随后可以适配下游任务(§2.1: 语言,§2.2: 视觉)。机器人学中的基础模型有可能同样使感知和控制适配新的环境、任务和实例。考虑一下我们的厨房运行实例。为了在一个新的厨房里做饭,机器人需要适应特定的环境—其空间布局和可用的设备等等。从人类的离线视频、机器人的互动、文字信息和/或模拟中学习到的先验知识(§2.3.2:挑战和风险)可能会对厨房中的普遍情况进行编码,例如炉子通常靠墙,必须打开才能产生热量。这样的常识性知识、物理先验和视觉先验可以使适配新环境的样本效率更高。同样,机器人任务学习的基础模型可能会在其训练数据集中使用大量的烹饪视频,适应一个普通技能的策略,如“煎蛋”,使得从低数量的演示中获得满足特定用户的偏好—实现高效的适应。最后,由于它们具有学习前面描述的跨模态表示的潜力,机器人学中的基础模型可以帮助实现对新实例的适配。这方面的适配是使这些模型广泛使用的关键。
2.3.2 挑战和风险
尽管有这种令人振奋的愿景,但仍需克服多种挑战。为了实现上述的泛化性,我们必须收集足够规模和多样性的机器人数据集。此外,我们需要一些机制来确保我们能够在现实世界中安全地部署所学到的行为。
数据需求 & 挑战 为一个通过传感器感知环境状态并采取行动完成任务的机器人学习策略,传统上需要大量的机器人在真实世界中的互动的数据集。另一方面,计算机视觉和自然语言处理中的许多学习任务都依赖于可以很容易从网上搜到的大型和多样化的离线数据集。在语言和视觉领域基础模型进展的激励下,我们对利用大型离线数据源在机器人领域学习此类模型的可能性感到兴奋。
实现这一目标的路径之一是收集大型数据集进行离线学习,例如使用远程操作 [Mandlekar et al. 2019],体感教学 [Sharma et al. 2018],或自主方法 [Pinto and Gupta 2016; Gupta et al. 2018; Levine et al. 2018; Dasari et al. 2019; Kalashnikov et al. 2021],这些方法在泛化方面显示出一些有潜力的迹象。虽然将机器人数据集的规模扩大到和视觉及语言数据集一样的规模 [Deng et al. 2009; Krishna et al. 2017; Raffel et al. 2019; Gao et al. 2020a] 仍然是一个开放的挑战,但机器人数据集的规模和质量不断提高,表明它们可以在学习机器人基础模型方面发挥重要作用。
鉴于学习控制是一个闭环的挑战,收集与视觉和语言中使用的数据集的规模可能不足以用于机器人学。一个可行的选择是额外利用外部的、非机器人的数据来源,如人类的视频或现有的视觉和自然语言类的数据集。这类数据多种多样,并大量存在于网络上 [Deng et al. 2009; Lee et al. 2012; Heilbron et al. 2015; Goyal et al. 2017a; Damen et al. 2018; Gao et al. 2020a],如果利用得当,就有可能实现广泛的应用。优雅地解决机器人领域与网络上的视频或语言之间的差距仍然是一个开放的挑战;然而,最近在领域适配方面的进展 [Smith et al. 2019; Schmeckpeper et al. 2020] 和在机器人中使用预训练的视频和语言模型 [Lynch and Sermanet 2020; Shao et al. 2020; Chen et al. 2021b] 为缩小这一差距提出了有希望的方向。
最后,模拟提供了机器人可以学习的丰富的交互式数据的无限来源,有一系列的传感器模式,如渲染的视觉、点云和模拟的触摸/音频。然而,一个主要的挑战在于弥合模拟和现实世界之间的差距,无论是在基础物理学还是在环境与任务的语义分布方面。最近的工作表明,通过使用广泛的领域随机化,可以将模拟中学习的从驾驶飞机 [Sadeghi and Levine 2017] 到接触丰富的操作 [Mahler et al. 2017; OpenAI et al. 2019] 和运动技能 [Peng et al. 2020; Hwangbo et al. 2019] 的任务转移到真正的机器人上,并取得一些成功,并且通过将真实世界扫描到模拟中,可以模拟出真实世界的语义和视觉分布 [Chang et al. 2017; Kolve et al. 2017b; Savva et al. 2019; Szot et al. 2021; Shen et al. 2021]。虽然这些都是有希望缩小模拟到现实差距的方法,但有效和通用的模拟到现实的操纵和运动技能的学习仍然是一个开放的挑战。模拟数据、真实的机器人数据、人类的视频和自然语言数据都可能是学习机器人技术的基础模型的关键。
安全性和鲁棒性 使机器人基础模型的发展更加复杂的是,在现实世界中训练或部署这些模型时,要确保其安全性和鲁棒性。鉴于具身的机器人被授权在收集数据的同时直接在物理世界中操纵并与周围环境互动,我们可以预期这些机器人模型的安全风险将不同于其在语言领域的对应风险。基于学习的系统的一个核心安全挑战是鸡生蛋蛋生鸡的问题,即在收集数据之前需要指定系统的安全约束,之后可能出现需要额外约束的不可预见的不安全行为。例如,机器人适配训练分布之外的新厨房需要足够的安全保证,以确保安全的数据收集,这可能会对任务性能产生不利影响或导致机器人以新的方式失败。解决这个问题的方法之一是限制环境的复杂性或增加机器人的复杂性,从而在构建过程中避免不可恢复的状态或不安全的动作。机器人也可以被赋予自主重置环境的任务,以促进从大规模数据收集中不间断地学习(或适应)[Eysenbach et al. 2017; Gupta et al. 2021]。这将意味着确保厨房里没有任何东西是易碎的,或者确保并更换机器人在试图收集数据时可能打破的物品。
为了解决基础模型无法对新刺激进行泛化或产生意外行为所带来的风险,未来的潜在方向包括开发因果分析 [Déletang et al. 2021]、新的安全评价工具和真实的模拟环境 [Corso et al. 2020; Dreossi et al. 2017; Julian and Kochenderfer 2019]。最后,为基础模型建立真正的安全保障,例如,安全集的 Hamilton-Jacobi 可达性,[Chow et al. 2018; Fisac et al. 2019; Herbert et al. 2021] 或通过开发对人类操作者可解释的安全边界(§4.11:可解释性),可以帮助减少机器人技术基础模型带来的风险 [Berkenkamp et al. 2017]。随着基础模型的研究和实施的进展以及与机器人学的交叉,解决这些挑战将变得至关重要的。
结论 虽然机器人基础模型的前景广泛—涵盖从任务规范到任务学习的机器人研发的多个层面—但挑战是巨大的。在物理世界中收集涵盖不同环境和大规模实例的数据是一个巨大的障碍,而确保这些系统的安全性和鲁棒性也是同样紧迫的。尽管如此,我们仍然持有乐观态度;在开发模型之前,现在就解决这些挑战,使我们有机会确定如何从正确的来源、以正确的规模收集正确的数据,以建立具有我们期望的能力的安全可靠的基础模型。
这一章节以多模态为主。在所有可能的实例中,机器人的基础模型已经并将继续受益于人工智能其他子领域的工作,如语言和视觉(§2.1: 语言,§2.2: 视觉)。然而,当我们考虑纳入这些来自其他领域的扩展时,即将出现的还有跨学科的挑战,这些挑战涉及基础模型的其他方面:为实时机器人系统训练和部署此类模型的系统化创新(§4.5:系统),用于鲁棒的人机交互界面的创新(§2.5:交互),以及当我们更好地掌握此类模型的安全性和鲁棒性(§4.9:AI 安全性,§4.8:对分布变化的鲁棒性)时要结合的经验教训。围绕基础模型建立一个可靠的生态系统和深思熟虑的研究实践是实现这些目标的关键。
2.4 推理与搜索
作者: Yuhuai Wu, Frieda Rong, Hongyu Ren, Sang Michael Xie, Xuechen Li, Andy Shih, Drew A. Hudson, Omar Khattab
在整个人工智能历史中,推理和搜索一直是核心主题。从策略游戏到抽象的数学探索,经典的智力测试,都是通过设计更聪明的方法来搜索获胜方案或解。这些智力测试目标推动了“机器智能”的极限。在早期,符号方法是推理的主要方法 [Russell and Norvig 2020],但囿于限制其搜索空间需要大量的工程投入和对启发式方法的形式化,很快被证明过于繁琐。
最近,使用神经网络的数据驱动方法,通过利用统计结构和学习有用的启发式方法,显示出了令人欣慰的结果,如在围棋中击败了最强的人类 [Silver et al. 2016],而围棋的动作空间比国际象棋这一经典挑战大得多。本节概述了现有的推理任务,这些任务需要模型扩展到更大的搜索空间并能对世界有一个广泛的了解(§2.4.1:当前的任务是什么)。然后,我们在 §2.4.2:基础模型的作用是什么 中讨论,作为捕获无限搜索空间统计规律的工具,基础模型应该在一般推理中发挥核心作用(生成性),支持跨任务和场景的转移(普适性),并在多模态环境下利用场景关联的知识(关联)。
2.4.1 当前的任务是什么?
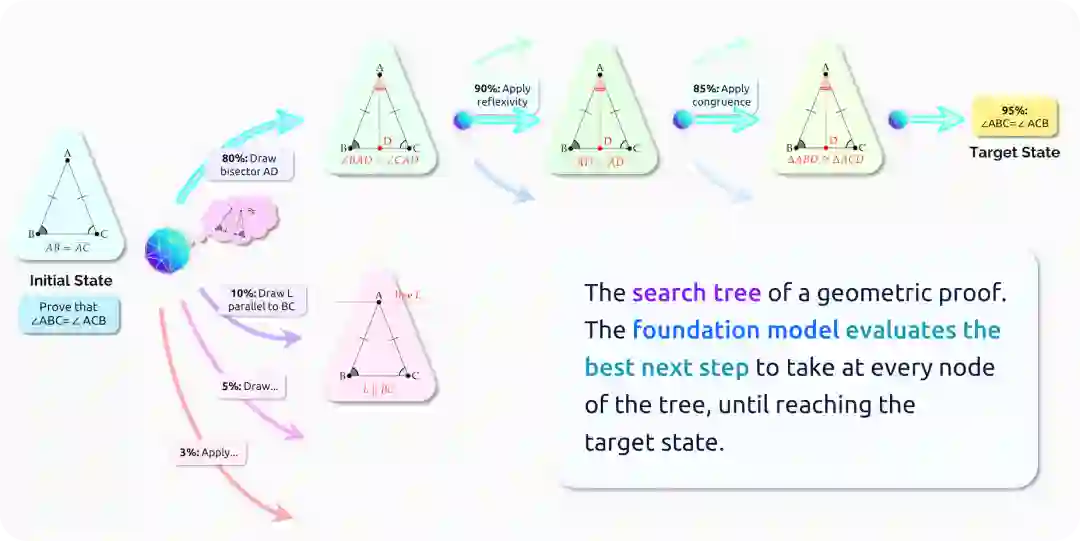
许多推理问题构成了无限的搜索空间,系统必须在其中处理多种开放式的处理方案。考虑尝试证明 𝐴𝐵 = 𝐴𝐶 的等腰三角形𝐴𝐵𝐶的∠𝐵和∠𝐶相等(图5)。系统可以在推理的每个步骤执行任意数量的操作。例如,系统可以添加具有任意形状的新辅助点,例如垂线、平行线或切圆,并且搜索空间只会随着图形变得更复杂而变得更大。证明上面定理的一种方法是画一条线𝐴𝐷,它是𝐴的角平分线,并使用两个三角形𝐴𝐵𝐷和𝐴𝐶𝐷的全等来表示∠𝐵 = ∠𝐶,但是系统如何在没有大量搜索的情况下找到它?
更一般地说,数学家并不局限于在图结构和欧几里得定理中进行搜索:数学家可以应用来自数学各个分支的大量定理,做出高层次的猜想,将新的数学概念形式化,或找到反例。这与更结构化的AI挑战形成对比,例如围棋游戏,其搜索空间被认为要小得多3。
3 小于围棋棋盘上的网格点数(即,19 × 19 棋盘有 361 个动作)。
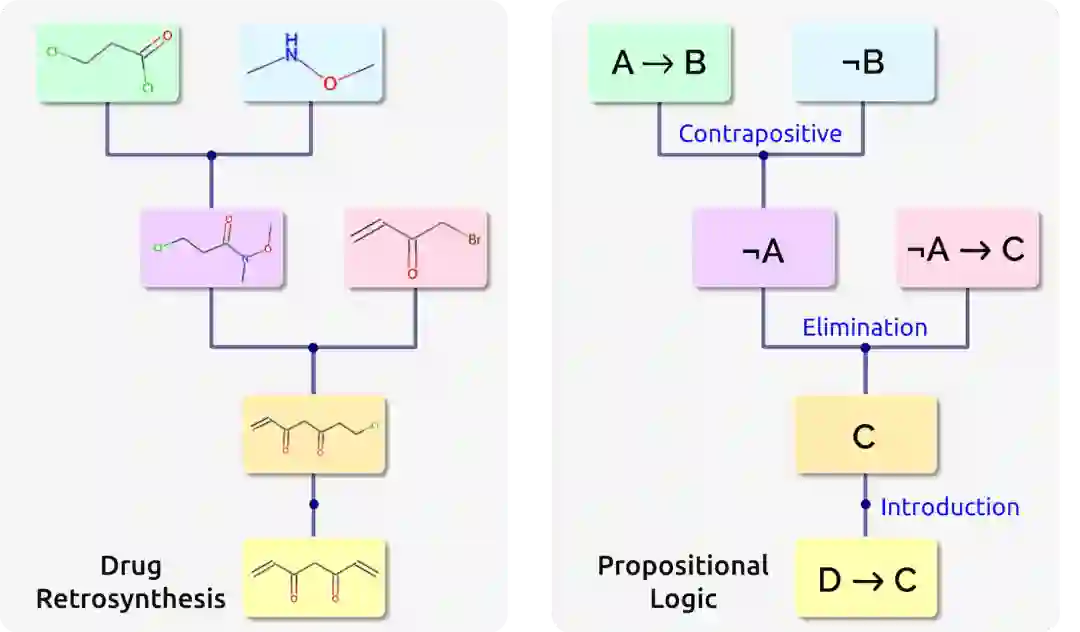
除了定理证明之外,许多现实世界的问题都涉及无限搜索空间,例如程序合成 [Gulwani et al. 2017]、药物发现 [Drews 2000]、化学合成 [Segler et al. 2018]、计算机辅助设计 [Haigh 1985]、组合优化 [Bengio et al. 2021] 等。这些推理问题往往表现出相似的结构,例如药物发现中的逆向合成和命题逻辑中的定理证明的联系,如图6 所示:两个问题均是构造一棵合成树,图左侧树的节点是化学产物,而叶子节点是最终产品;图右侧树的节点是命题,叶子结点是最终公理。在这些问题中,通常会提供一个模拟环境,它允许求解器运行多个搜索线程来构建解树。模拟器通常提供中间反馈,例如,在证明完成之前通知求解器剩余要建立的命题。求解器反过来需要选择最有希望的搜索线程并根据中间反馈进行处理。
最近,人们越发关注通过基于学习的方法来解决推理问题。为了克服无限搜索空间的挑战,研究人员首先从受限搜索空间开始探索,以使问题易于处理 [Huang et al. 2018; Bansal et al. 2019]。但是这种方法受限于求解器可以发出的有限类型动作。例如,求解器只能应用已知数据库中的定理来证明目标定理,而不是综合新的定理和引理。由于大型语言模型提供了将输出空间建模为序列的通用方法,允许生成任意类型的动作,因此它们很快成为了更受欢迎的选择。研究人员已将这些基于语言模型的方法应用于各种应用,例如预测蛋白质结构 [Senior et al. 2020],证明形式定理 [Polu and Sutskever 2020; Han et al. 2021],推测定理 [Urban and Jakubuv 2020; Rabe et al. 2021; Li et al. 2021b],根据自然语言生成程序 [Chen et al. 2021d; Ling et al. 2016],修复、生成和理解代码 [Yasunaga and Liang 2021; Lu et al. 2021b; Guo et al. 2020; Svyatkovskiy et al. 2020; Kim et al. 2021b; Zügner et al. 2021]。研究还表明,扩大模型大小可以显着提高推理能力 [Polu and Sutskever 2020],而且语言建模中的标准技术(例如预训练)也可以大大提高这些任务的性能 [Rabe et al. 2021; Polu and Sutskever 2020]。
2.4.2 基础模型的作用是什么?
生成性 我们相信基础模型的生成能力对于有效推理至关重要。由于无限的搜索空间,枚举各种可能性非常棘手。相反,使用基础模型,人们可以对最佳决策的分布进行建模,并生成合适的候选以进行下一步。特别是,由于基础模型提供了一种将输出空间建模为序列的通用方法,因此下一步决策是完全不受约束且通用的。这种灵活性对于我们讨论的许多推理挑战至关重要,可以在数学猜想 [Li et al. 2021b] 和合成新程序 [Chen et al. 2021d] 等领域中产生创新性。随着基础模型规模的扩大,捕获此类统计结构的能力也会大幅增长 [Polu and Sutskever 2020]。
普适性 正如我们在上一节中提到的,许多推理问题都表现出相似的潜在结构。我们相信由基础模型施加的统一框架可以跨任务迁移和共享重要的启发式方法,从泛化适用于一项任务的低级技术到新场景,再到直接找到适用于众多任务的元技术。此外,由于基础模型是跨多个领域进行训练的,因此可以在其权重中积极地跨任务和跨领域传输元知识 [Papadimitriou and Jurafsky 2020; Wu et al. 2021c; Lu et al. 2021a]。基础模型训练和适配的关注点应该是分离的,其中基础模型的训练学习元知识,例如药物逆合成和命题逻辑证明之间的共享搜索树结构,而适配阶段可以专注于学习任务特定的词汇。因此,基础模型可以降低适配阶段学习问题的复杂度,提高样本复杂度和泛化能力。
关联(Grounding) 推理问题通常很容易用符号语言(例如,数学、代码、分子的 SMILE 表示)表达。然而,这些符号具有深刻的潜在语义意义,比如“等腰三角形”在人思维中描绘了一个生动的形象。基础模型可以运用深层场景关联知识和语义含义。首先,在其它模态(例如视觉或物理)中的场景关联表示对于掌握推理任务中的抽象概念并赋予它们具体意义至关重要 [Larkin and Simon 1987; Jamnik 2001]。基础模型由于可以在多种模态上进行训练,因此可以帮助理解一系列数据源(例如,图像、文本)。因此,在几何示例中,通过对自然图像中学习的几何形状的理解,基础模型可以有效地利用问题的图形表示。然而,推理中对齐的多模态数据很少,基础模型能否以无监督的方式发现不同模态之间的联系(例如,发现具有相应代数方程的交 换图)仍然是一个悬而未决的问题。此外,即使在符号领域内,符号也可以有不同层次的解释。例如,高级编程语言可以转换为低级汇编代码。基础模型可以学习包含这些不同视图的共享表示。过去的工作表明,自监督任务 [Han et al. 2021; Peng et al. 2021; Li et al. 2021a] 允许模型理解高级代码脚本背后的内部工作原理,并进一步辅助下游任务。
2.4.3 推理的未来挑战
由于这些问题的内在困难,与原始图像和文本相比,高质量的标注数据稀缺且难以收集。为了缓解这个问题已经有了许多尝试。在数学中,研究人员提出生成综合定理,希望能推广到现实定理 [Wang and Deng 2020; Wu et al. 2021a; Firoiu et al. 2021; Zhou et al. 2021]。另一种方法是设计自监督的任务来增强数据集 [Yasunaga and Liang 2020; Ren et al. 2020; Han et al. 2021; Rozière et al. 2021; Yasunaga and Liang 2021] 或设计更好的预训练目标 [Wu et al. 2021c]。然而,我们仍然缺乏设计自监督任务的一般原则方法,因为大多数现有工作都是针对特定问题设置的 [Yasunaga and Liang 2020; Ren and Leskovec 2020; Han et al. 2021]。构建基础模型将鼓励构建一套可应用于所有推理问题的自监督任务的统一框架。此外,交互性(§2.5: 交互性)可以在具有足够可扩展性的情况下,通过将人类引入迭代周期以最低限度地指导学习知识或数据增强过程来缓解数据稀缺问题,例如,选择要添加的公理或要探索的猜想。而交互式工具本身则是一种用于帮助脑力劳动者推理 [Han et al. 2021; Chen et al. 2021d] 的基础模型。通过借助功能强大的基础模型辅助人类学习,易于解释的交互式工具可以在教育中找到进一步的应用(§3.3:教育)。
提高高级推理能力是现有基础模型的核心挑战。人类在解决困难的问题时会执行抽象推理和高层次规划 [Miller et al. 1960]。例如,在构建软件工具或证明定理时,我们通常先从高层次的草图开始,然后再深入研究低层次细节 [Koedinger and Anderson 1990]。现有的基础模型未被训练生成此类高层次规划:它们通常只专注于预测下一个低层次步骤 [Polu and Sutskever 2020; Han et al. 2021; Chen et al. 2021d]。不幸的是,为了训练基础模型来模拟类人推理,数据收集的挑战依旧。虽然这样的数据确实存在于有限的环境中 [Li et al. 2021b],但总的来说,用于高层推理的数据是稀缺且难以收集的。一项研究是让抽象和模块化的层次结构在学习过程中自行出现 [Ellis et al. 2021; Hong et al. 2021],但如何将这些方法扩展到更一般和更现实的场景中仍然是一个悬而未决的问题。
除了这些挑战之外,还有许多开放性问题对于本文其它节所讨论的主题也很重要。什么构成了可靠推理的良好架构(§4.1:模型架构)?我们如何从理论上(§4.10:理论)和实际上(§4.11:可解释性)理解和解释这些模型?我们能否训练可以泛化到域外问题的鲁棒推理模型(§4.8::对分布变化的鲁棒性 和 §4.3:适配)?我们相信对基础模型这些方面的研究可以极大地扩大它们对推理领域的影响。
2.5 交互
早期形式的基础模型,如GPT-3 [Brown et al. 2020]和 DALL·E [Ramesh et al. 2021] 已经展示了高度的多功能性:如允许非机器学习专家也能设计强大的 AI 赋能应用的能力,以及它们无缝集成从文本到图像等各种模态的能力。随着基础模型开发的成熟,模型的容量将不断扩大,它们的多功能性最终可能导致我们与 AI 交互的方式发生根本性变化,让我们能够快速设计并构建高度动态和生成性的 AI 赋能应用。在本节中,我们从两个重要利益相关者的角度讨论这些变化带来的机会:(1) 将与基础模型交互以设计用户体验的应用开发人员,以及 (2) 将直接使用由基础模型提供支持的 AI 赋能应用或受它们影响的终端用户。最后,我们考虑开发人员和终端用户的界限可能开始模糊的场景,它们为创建更紧密地满足用户需求和价值的 AI 赋能应用提供了新的机会。
2.5.1 对 AI 赋能应用开发人员开发过程的影响
基础模型将如何改变开发人员创建人工智能应用的方式?尽管机器学习算法和硬件基础取得了巨大进步,有人指出,设计新颖和积极的人机交互形式仍然很困难[Dove et al. 2017; Cooper et al. 2014]。创建强大的特定于任务的模型所需的大量数据、计算资源和技能经常与引出和满足用户需求和价值所需的原型迭代过程相冲突[Yang et al. 2016]。由于 AI 的响应可能无法预测,并且模型可以产生巨大的生成式输出空间,这使得人们难以对它们的表现建立有效的心智模型,这一事实进一步加剧了前述挑战。目前应对这些挑战已经取得了一些进展,如交互式机器学习(例如,Crayon[Fails and Olsen 2003]、Regroup[Amershi et al. 2012])和能将人工智能中的不确定性传达给终端用户的框架设计(例如,混合决议的原则[Horvitz 1999])。然而,克服这些障碍还需要做更多的工作[Yang et al. 2020]。
基础模型为解决上述许多挑战提供了重要机会。例如,基于语言的基础模型能够将自然语言作为输入并泛化到许多下游任务,可以显著降低应用开发的“门槛”[Myers et al. 2000],如无需收集大量数据并从头开始训练大型模型即可开发复杂的模型。这甚至可以使非机器学习专家能够快速构建 AI 赋能应用的原型。同时,下文将讨论,基础模型强大的生成能力和潜在的多模态能力为可实现的交互类型提供更高的质量和多样性“天花板”[Myers et al. 2000]。然而,如何成功地利用这些能力将取决于我们如何有效地将基础模型转化为更易于应用开发人员控制的形式。
不幸的是,赋予基础模型优势的通用性和高天花板也可能使这些模型难以使用,因为它们可能比单一用途的 AI 模型更加复杂和难以预测。事实上,最近的工作表明,让 GPT-3 等模型始终如一地执行预期任务可能很困难[Reynolds and McDonell 2021],而了解它们的能力仍然是一个活跃的研究领域[Hendrycks et al. 2021]。为了提高 AI 赋能应用的可靠性和可信度,我们建议未来的工作应该继续研究如何从基础模型中实现更可预测和更鲁棒的行为(例如,通过微调,或者在主要交互模态是自然语言提示的情况下,通过提示工程 [Reynolds and McDonell 2021; Liu et al. 2021],校正 [Zhao et al. 2021],或者预先格式化一个特定任务的终端等方式4。有关详细信息,请参阅§4.8: 对分布变化的鲁棒性)。
4 https://beta.openai.com/docs/guides/classifications
2.5.2 对终端用户与 AI 赋能应用交互的影响
除了开发人员可以创建 AI 赋能应用的新方式之外,基础模型还会为终端用户与这些应用交互的体验带来哪些变化?如 Douglas Engelbart 所描述的 [Engelbart 1963],用于开发面向用户的 AI 应用的现有设计框架侧重于增强(而不是替换)用户的能力,我们推测这些框架在未来仍将如此。例如,维护用户的意愿并反映他们的价值观将继续成为基础模型驱动的应用的核心话题。此外,需要仔细权衡允许 AI 代理根据用户处理习惯自行做出决策与等待用户自己直接操作 [Shneiderman 1997] 这两种方式的优缺点 [Horvitz 1999]。此外,用户的价值观应该通过直接参与 [Lee et al. 2019] 和价值观敏感的设计 [Smith et al. 2020] 等途径直接收集和反映,这些过程提倡在设计 AI 赋能应用时积极让所有利益相关者参与。
这些问题在基础模型中可能变得特别突出,因为模型的行为方式可能会让用户和研究者们感到惊讶和失望。生成能力可能会暴露与研究者们目标背道而驰的偏见或观点,或者更阴险地,在研究者们不知情的情况下隐式地在模型行为中采取这些偏见。这将给使用基础模型来监控和矫正他们模型行为的团体带来很大的负担。
虽然用以增强用户能力的AI赋能应用设计框架应该保持不变,但由于基础模型强大的生成和多模态能力,可实现的实际交互形式可能会显著多样化。用于多媒体创作和编辑的可被视为早期基础模型驱动的软件工具已经开始推动新领域的发展,即使是新手内容创作者也能够根据粗略、直观的规范生成高质量的多媒体内容(例如,作家的改写5、摄影师的前景分割6、音乐家的母带处理7和程序员的代码补全8)。改进的基础模型可能会催生更令人激动的工具(例如,粉丝可能会提供主题材料以他们最喜欢的乐队的风格生成一首歌曲,或者企业主可以提供他们产品的简单描述,这些描述将用于创建一个完整的网站)。此外,基础模型将用于丰富静态多媒体内容(例如,自动将传统多媒体内容重新制作为新格式,或为新视频游戏中的每个玩家生成独特的体验),甚至可能产生新的多模态形式的交互界面,例如基于视觉和手势的交互。
5 https://www.wordtune.com/
6 https://helpx.adobe.com/photoshop/using/select-mask.html
7 https://www.landr.com/
8 https://copilot.github.com/
我们开始从AI Dungeon9,Microsoft PowerApps10和CoPilot11中看到基础模型可能如何落地为新的具体交互方式。当我们开始设想新的交互形式时,慎重思考这些交互将对个人用户和社会产生的潜在影响,对我们来说变得越来越重要,如此方能取其精华。例如,基础模型驱动的应用将如何改变我们相互交流的方式?一个强大的模型会代替我们写电子邮件吗?如果是,在电子邮件可能不是作者本人书写的情况下,将如何重塑人们的信任、可信度和身份,又将如何改变我们的写作风格[Hancock et al. 2020]?谁将拥有模型生成内容的作者身份,责任转移和许可所有者的认定又会被如何滥用 [Weiner 2018](更深入的讨论见§5.5:经济)?基础模型将对我们的工作、语言和文化产生哪些长远影响 [Hancock et al. 2020; Buschek et al. 2021]?与最后一个问题特别相关的是,基础模型是根据观察到的数据训练的,不一定会告诉我们因果关系。因此,我们如何确保基础模型的使用给我们带来的是预期未来而非简单的昨日重现?虽然这些问题不一定是基础模型独有的,但随着基础模型加速创建有效的AI赋能应用,它们将被放大并变得更加普遍。
9 https://play.aidungeon.io/main/home
10 https://powerapps.microsoft.com/en-us/
11 https://copilot.github.com/
2.5.3 模糊开发人员和终端用户之间的界限
今天,将AI模型的开发者和终端用户分开的界限是清晰的:终端用户很少有数据、计算资源和专业知识能够开发很好符合一个人的价值观和需求的新模型。虽然在某些情况下通用模型(即不特定于特定用户或社区的模型)可能就足够了,但近年来出现了越来越多的场景,其中此类模型无法为用户提供服务。例如,旨在识别一个在线社区的有问题评论的文本分类模型可能适用于该社区,但不适用于规范和文化可能有显著差异的其他社区(例如,Reddit上的NSFW社区可能对某些内容更宽容,而科学界可能会拒绝并非基于科学研究的看似平凡的轶事)[Chandrasekharan et al. 2018]。在另一个例子中,为一类目标人群设计的AI驱动的传感器和机器人工具可能无法快速适配和服务于具有不同能力和需求的用户 [Karamcheti et al. 2021]。虽然最近的工作为未来研究终端用户如何通过手动提供模型的参数或数据集(例如,WeBuildAI [Lee et al. 2019])来共同创建AI模型提供了有前途的方案,但结果仍然是初步的且通常专注于初级模型。
如果基础模型能够充分降低构建人工智能应用的门槛,那么它们就可以提供一个重要的机会,通过允许用户积极参与模型的开发过程,将用户的需求和价值观与模型的行为更紧密地结合起来。例如,最近的工作表明,当在其自然语言提示中给出足够的任务描述时,GPT-3可以以少试甚至零试的方式鲁棒地执行分类任务 [Brown et al. 2020]。试图管理自己内容的在线社区可能能够利用这种能力来创建定制的AI分类器,该分类器根据社区已同意的分类任务描述过滤内容(当然,这种能力也可能被滥用来使社区内某些成员无法发声。我们在 §5.2: 滥用 进一步讨论此主题)。此外,基础模型强大的上下文学习能力可能允许基础模型驱动的应用在每个用户的基础上更有效地优化其界面。这可以为解决人机交互中的许多突出问题打开大门,例如在混合自动的情况中平衡用户直接操作和自动化的能力。
当然,要真正发掘这种模糊用户和开发人员之间界限的潜力,我们仍然需要克服一些重要的挑战。这些挑战包括减轻基础模型中的现有偏差,以及使模型的行为更加鲁棒和易于管理,即使对于非机器学习专家(与机器学习专家相比,非机器学习专家可能更难以理解基础模型的机制和全部能力,这可能会导致在开发周期中出现意想不到的问题 [Yang et al. 2018])。未来的工作应该探索如何将基础模型置于交互式机器学习的背景下,并研究我们如何使得即使是那些机器学习经验有限的人也能以鲁棒的方式利用这些模型。尽管如此,终端用户参与开发AI赋能应用的能力是一个令人兴奋的机遇,它可以为我们将来如何与这些应用交互引入新的范式。
2.6 理解的哲学
作者: Christopher Potts, Thomas Icard, Eva Portelance, Dallas Card, Kaitlyn Zhou, John Etchemendy
基础模型可以了解它所训练的数据的哪些方面?这个问题的答案能很好反映基础模型为智能系统做出贡献的整体能力。在本节中,我们专注于自然语言的案例,因为语言运用是人类智能的标志,也是人类体验的核心。
目前最好的基础模型可以以惊人的流畅度使用和生成语言,但它们总是陷入一种不连贯性,表明它们只是“随机鹦鹉” [Bender et al. 2021]。这些失误是否证明了模型固有的局限性,未来的基础模型是否有可能真正理解它们处理的符号?
我们在本节中的目的是澄清这些问题,并帮助围绕它们展开辩论。我们首先解释基础模型的含义,其中特别注意基础模型是如何训练的,因为训练机制界定了模型获得的关于世界的信息。然后,我们将说明为什么澄清这些问题对于进一步开发此类模型很重要。最后,我们试图阐明理解的含义,解决理解是什么(形而上学)以及我们如何可靠地确定模型是否已经实现理解(认识论)。
最终,我们得出结论,对未来模型理解自然语言的能力持怀疑态度可能为时过早。仅凭基础模型就可以实现理解绝不是显而易见的,但我们也没有明确理由认为它们不能理解。
2.6.1 什么是基础模型?
基础模型没有精确的技术定义。相反,这是一大系列模型的非正式定义,并且该系列模型可能会随着时间的推移而增长和变化以响应新的研究。这对推理它们的基本属性提出了挑战。然而,可以说所有基础模型都有一个共同的定义特征:它们是自监督的。我们的关注点是自监督是模型唯一正式训练目标的情况。
在自监督中,该模型的唯一目标是学习它所训练的符号序列中的抽象共现模式。这项任务使许多基础模型也能够生成合理的符号串。例如,许多基础模型的结构是这样的,人们可以用“三明治含有花生”这样的序列提示他们,并要求他们生成一个延续——比如“黄油和果冻”。其他模型的结构使其更擅长填补空白;你可能会用“三明治包含______和果冻”提示模型,并期望它填充“花生酱”。这两种功能都源自这些模型从其训练数据中提取共现模式的能力。
在这种自监督中,没有明显的意义可以告诉模型符号的含义。它直接给出的唯一信息是关于哪些词倾向于与哪些其他词共同出现的信息。从表面上看,知道“三明治里有花生”很可能会继续用“黄油和果冻”来说明三明治是什么、果冻是什么、这些物体将如何组合等等。这似乎暗示了基础模型可以实现的固有限制。但是,我们不需要将模型限制为只能看到文本输入。基础模型可能会根据各种不同的符号进行训练:不仅是语言,还包括计算机代码、数据库文件、图像、音频和传感器读数。只要它只是学习它所接触的序列的共现模式,那么根据我们的定义,它就可以算作基础模型。作为这种学习的一部分,模型可能会表示给定文本片段与特定传感器读数之间或像素值序列与数据库条目之间的强关联。这些关联可能反映了我们居住的世界的重要方面以及我们用来谈论它的语言。
2.6.2 什么是利害攸关的?
在考虑分析什么是理解之前,值得反思一下我们为什么会关心基础模型是否可以实现它。基础模型被准备用于多种用途,这些用途需要模型实现各种各样的功能。我们在落地应用中的一些目标可能只有在模型能够理解时才能实现。这里我们列出了一些这样的目标:
可信性: 有人可能会争辩说,除非系统理解所使用的语言,否则我们不能相信系统的语言行为。当然,我们目前相信工程系统可以胜任许多工作(例如,制造汽车零件),甚至不会产生理解问题,但语言在这方面可能很特别,因为它是人类独有的。此外,语言可用于欺骗和歪曲,因此仅理解清楚并不意味着信任。总的来说,理解可能被视为语言使用中信任的必要条件。
可解释性: 如果真正的自然语言理解以某种方式涉及维护和更新世界的内部模型(包括例如语境),并且如果我们(作为工程师)能够分析语言输入和输出如何与该内部模型交互,这可以在这些系统的可解释性、可预测性和控制方面带来重大收益。
责任性: 与前面的观点不无关系,将来我们可能会发现以某种方式让人工代理对其产生的语言负责 [The HAI Adaptive Agents Group 2021] 是可取的。根据我们对责任、义务、代理等概念的看法,语言理解可能成为先决条件。
即使理解在这些问题里的不可或缺作用只存在于可能性阶段,但是也为开发一个与其相关的理论框架提供了较强的动机。
2.6.3 什么是理解?
我们的核心问题是基础模型是否能够理解自然语言。有了上面的内容,我们现在可以加强它:在其训练数据没有限制的情况下,自监督是否足以达成理解?为了解决这个问题,我们首先需要定义理解的含义。
首先,我们发现明确区分在讨论该主题时容易混淆场景关联的概念是有帮助的。区别在于理解的形而上学和认识论之间。形而上学关注代理实现理解意味着什么(“原则上”)。相比之下,认识论关注的是我们如何(“在实践中”)知道一个代理已经实现了相关类型的理解。简而言之,形而上学更多地是关于我们的最终目标,而认识论更多地是关于我们如何(如果有的话)知道我们何时达到了它。因此,我们的认识论在某种程度上取决于我们的形而上学。
理解的形而上学 语言哲学为理解自然语言提供了许多替代方案12。为简洁起见,以下三大类观点都与AI和NLP的研究路线有关13:
-
内在主义:语言理解相当于根据语言输入检索正确的内部表征结构。因此,如果没有丰富的正确类型的内部概念库,语言理解甚至是不可能的。
-
参照主义:粗略地说,当智能体能够知道该语言中的不同句子需要什么才能成为真(相对于上下文)时,他们就会理解语言。也就是说,单词具有指称对象,并且(陈述性)话语是可评估的,且对理解能力的评估需要相对于具体情景或场景。
-
实用主义:理解不需要任何内部表示或计算的方式,真和指称不是根本的。相反,重要的是代理倾向于以正确的方式使用语言。这可能包括对推理或推理模式的倾向、适当的对话动作等。至关重要的是,相关的语言能力构成了理解14。
12 相关地,科学哲学中有大量文献关注理解的概念,主要是因为它与科学解释有关。参见 Grimm [2021]。
13 我们将其他可能与理解的形而上学相关的问题,例如意识或某种形式的主观经验是否可能是必要的,放置一边。这些都是紧迫的哲学问题,但它们与AI和NLP的研究并不容易联系起来。
14 对于内在主义和参照主义观点的介绍,我们推荐 Elbourne[2011]。这个版本的实用主义可以说起源于 Wittgenstein[1953],但最简洁地表达为 Turing [1950],其中图灵建议用关于特定行为测试的问题代替机器是否可以思考的问题(其后来被称为图灵测试)。
虽然这是可能性空间的简化描述,但我们已经看到它们如何以完全不同的方式与上述目标相关联。例如,在实用主义者的观点中,实现语言理解并不意味着我们信任或解释系统的能力,因为它不能保证代理的内部结构或其与(非语言)世界的关系。相比之下,内在主义者的观点至少提出了一种相当鲁棒的内部的/因果的可解释性。基础模型是否可以原则上理解语言的问题,随我们采用的这些形而上学特征中的哪一个,而呈现出非常不同的特征。
内在主义和参照主义都可以定义为映射问题:将语言符号与“意义”或“语义价值”相关联。对于内在主义,这将是一种表示或概念、计算某种值的程序或某种其他类型的内部对象。对于参照主义,它可能是从单词到外部参照的映射,或者从情况到真值的映射(都与上下文相关)。自监督是否足以在基础模型中实现所需的映射?在这里训练示例的性质可能是相关的。如果模型只接收语言输入,那么它学习这种映射的能力可能会从根本上受到限制,从而阻止它学习相关意义上的指称。(确实,Merrill et al. [2021] 确定了一些理论限制,尽管带有非常强烈的假设,讨论了学习符号的含义意味着什么。)但是,如果输入符号流包括世界上事物的各种数字痕迹——图像、音频、传感器等——那么共现模式可能包含足够的信息,模型可以为所需的映射归纳高保真替代品15。对于参照主义,还有一个关于这些替代品如何与现实世界相关联的问题,但同样的问题也出现在人类语言用户身上。
15 在映射体现因果信息的程度上,我们还必须应对关于从相关数据(甚至是实验数据)得出因果推断的可能性的局限性(参见 Spirtes et al. 2001; Bareinboim et al. 2020)。
16 在我们的阅读中,[Bender and Koller 2020]允许多模态数据可能会改变这一场景,特别是如果允许 与人类就共享场景和主题进行合作交互的话。
我们暂时得出结论,没有简单的先验理由认为属于上面三种视角的理解不能用其视角对应的训练方式来习得。由于这种可能性仍然存在,假如我们成功实现了理解,将面临着澄清如何评估它们的认识论挑战。
理解的认识论 实用主义的一个积极特征是,通过将成功与具体行为的表现相结合,没有关于如何测试成功的巨大概念难题。我们只需要说服自己,到目前为止,我们对系统行为的有限观察表明,系统对我们作为目标的更一般的行为类别具有可靠的倾向。当然,就适当的目标达成一致是非常困难的。当提出具体的建议时,它们总是遭到反对,而这通常是在证明成功之后。
图灵测试的历史在这里很有启发性:尽管许多人工智能体已经通过了实际的图灵测试,但没有一个因此被广泛接受为智能。类似地,近年来,NLP 中提出了许多基准任务来评估理解的特定方面(例如,回答简单问题,执行常识推理)。当系统超过我们对人类表现的估计时,研究者们的反应通常是测试有缺陷,而不是达到了目标。可能有一些行为是我们的真正目标,但很难界定或转化为实际测试17。再一次,这可能表明内在主义或参照主义是我们一直以来所猜测的。
17 部分困难还可能与典型的人类在其中许多方面经常犯错有关联,但不一定与当前系统产生的错误类型相同。因此,表征目标行为可能不仅仅涉及识别“正确”的行为。
如果我们将内在主义或参照主义作为最终目标——我们对理解是什么的黄金标准——那么作为评估是否已经实现理解的手段,行为测试总是不完美的。缺陷是两方面的。首先,行为测试总会有漏洞,可能会让不复杂的模型漏掉。其次,系统可能已经实现了这些视图所需的映射,但我们可能无法通过行为测试来显示这一点。最近使用 GPT-3 模型的经验表明这可能会变得多么具有挑战性:根据使用的提示,人们可以看到令人惊讶的连贯输出或完全无意义的输出,因此提示工程需要深厚的专业知识 [Rong 2021]。
因此,内在主义和参照主义都需要结构化的评估方法,使我们能够研究它们的内部表示,探索它们的信息 [Tenney et al. 2019; Manning et al. 2020],研究它们的内部动态 [Sundararajan et al. 2017],并且可能根据支持因果推理的特定实验协议积极操纵它们 [Vig et al. 2020; Geiger et al. 2020]。我们可以从关于复杂基础模型内部运作的实际实验中学到的东西可能存在根本性的限制,但很明显,只要我们的目标符合内在主义或参照主义,这些方法就会很有用。
2.6.4 进阶讨论
很明显,对于基础模型是否会理解语言这个问题没有简单的答案。甚至要开始解决这个问题,就必须解决一个困难的形而上学问题,对此有许多实质上不同的观点。然后,形而上学问题演变成一个认识论问题,提出了许多实际挑战。尽管如此,上述讨论确实引出了一个实际结论:如果将基础模型作为人工智能理解语言的途径,那么多模态训练体系很可能是最可行的策略,因为它们似乎最有可能为模型提供必要的信息。自监督是否足够是一个完全悬而未决的问题。
本期责任编辑:冯骁骋
理解语言,认知社会
以中文技术,助民族复兴




