![]()
本文约7701字,建议阅读10分钟
本文介绍了2021年人工智能预训练领域的发展历程。
【专栏:前沿进展】2021年已进入尾声,回顾一年来人工智能领域的发展历程,有众多瞩目的技术事件发展。其中,预训练模型无疑是2021年的重点发展领域。年初的Switch Transformer开启万亿参数模型的研发热潮,DALL·E和CLIP的问世推动多模态预训练的发展,“悟道”系列模型成为国内首个突破万亿参数模型等等——层出不穷的预训练模型涌现,催生出超大规模智能模型的新兴研究领域。
与此同时,研究者在研发模型之外,也关注大规模预训练加速方法,以提升计算效率,降低算力依赖。此外,针对超大规模智能模型技术、社会、经济、伦理等方面的系统研究拉开序幕,基础模型相关的研究体系已然形成。
作为2021年终盘点,我们整理了今年人工智能领域的发展情况和案例,通过汇总专家学者观点建议,形成《智源人工智能前沿报告》(AI Frontiers Report),预计将于2021年末发布,该报告涵盖人工智能技术中的机器学习、计算机视觉、自然语言处理等十余个科研领域,AI平台和工具技术发展情况,以及人工智能产业方面的发展趋势、动向情况等,敬请期待。本篇文章来自该报告预训练模型技术相关板块。
01. 系统研究超大规模智能模型
发展和影响的新兴领域已经形成
随着BERT、GPT-3、DALL·E等超大模型的兴起,“自监督学习+预训练模型微调”适配方案逐渐成为主流。然而,随着超大规模预训练模型在科研、产业、社会、经济等领域的作用日益凸显,其带来的深远影响成为科学家们关注的重点。
案例1:Percy Liang、李飞飞等学者提出基础模型概念
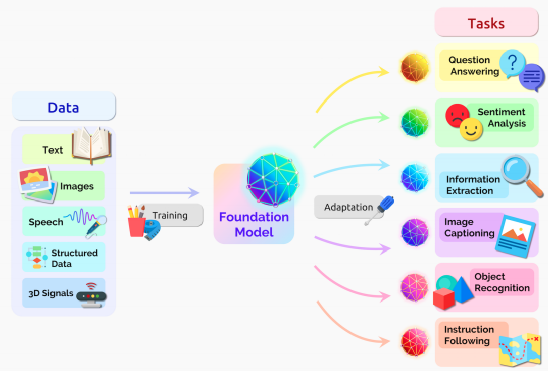
8月,Percy Liang、李飞飞等学者将大规模预训练模型统一命名为基础模型(Foundation Models),并撰文讨论基础模型面临的机遇和挑战。论文分为四个部分,分别阐述了基础模型的能力、应用领域、技术层面和社会影响。
来源:https://arxiv.org/pdf/2108.07258.pdf
图注:基础模型在多种模态数据的训练和下游任务应用中处于中心地位
来源:https://arxiv.org/pdf/2108.07258.pdf
来源:https://arxiv.org/pdf/2108.07258.pdf
案例2:DeepMind发表语言模型社会危害评估论文
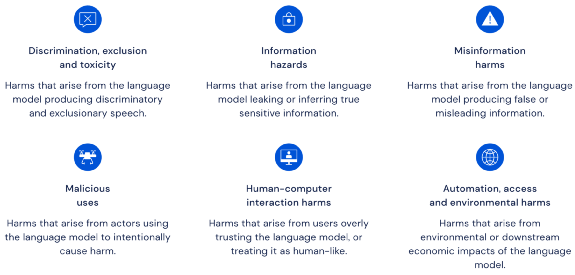
12月,DeepMind发表论文,研究预训练语言模型带来的伦理和社会危害。研究者主要探究了模型在六大方面的不良影响,并谈到两个伦理和社会影响方面需要研究者持续关注。
研究者认为,当前的基准测试工具不足以评估一些伦理和社会危害。例如,当语言模型生成错误信息,人类会相信这种信息为真。评估这种危害需要更多与语言模型进行人机交互。此外,AI领域对于风险控制的研究依然不足。例如,语言模型会学习、复现和放大社会偏见,但是关于这一问题的研究仍处于早期阶段。
图注:DeepMind论文研究的六大语言模型伦理和社会危害
来源:https://deepmind.com/blog/article/language-modelling-at-scale
GPT-3的问世,激发研究者探索规模更大、性能更惊人的超大规模预训练模型。国内外大型科研机构和企业纷纷投入巨量算力进行研发工作,将算力规模推升至万亿规模,探索模型的参数、性能和通用任务能力边界。
目前,已有OpenAI、谷歌、FaceBook、微软、英伟达、智源研究院、阿里达摩院、华为、百度、浪潮等研发机构和企业加入“军备竞赛”。
案例1:谷歌研发万亿规模预训练模型Switch Transformer
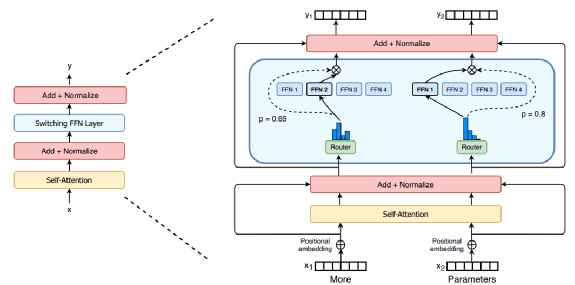
1月,谷歌研究人员研发出新的语言模型Switch Transformer,包含1.6万亿个参数,是包含1750亿参数的GPT-3的九倍。研究者将Switch Transformer与谷歌研究的T5-Base和T5-Large模型进行了对比,结果表明,在相同的算力资源下,新模型实现了最高7倍的预训练速度提升。
图注:Switch Transformer编码块结构
来源:https://arxiv.org/pdf/2101.03961.pdf
案例2:智源发布超大规模智能模型悟道1.0/2.0
3月20日,智源研究院发布我国首个超大规模智能信息模型“悟道1.0”,训练出包括中文、多模态、认知、蛋白质预测在内的系列模型,并在模型预训练范式、规模和性能扩增技术、训练语料数据库建设等方面取得了多项国际领先的技术突破。
6月1日,智源研究院发布“悟道2.0”模型,参数规模达到1.75万亿,是GPT-3的10倍,打破由Switch Transformer预训练模型创造的1.6万亿参数记录,是中国首个万亿级模型。
案例3:微软、英伟达发布预训练模型Megatron-Turing
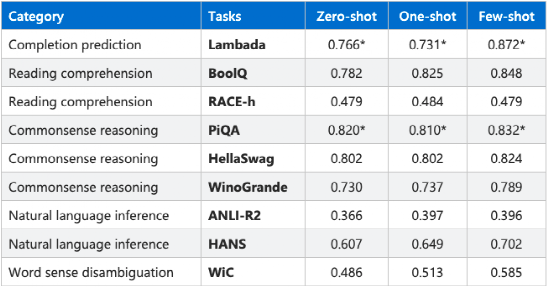
10月,微软联合英伟达推出了Megatron-Turing(MT-NLP)预训练模型。该模型是微软的T-NLG(Turing-NLG)和英伟达Megatron-LM模型结合的下一代版本,包含5300亿参数。研究者选择了五个领域中的8项任务来评估MT-NLG的效果。实验中,该模型在其中一些任务上实现了最佳的性能表现。
图注:MT-NLG在零样本、单样本和小样本条件下在不同任务中的表现
案例4:DeepMind发布预训练模型Gopher
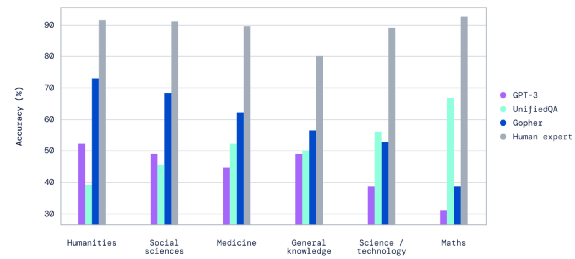
12月,DeepMind发布预训练语言模型Gopher,参数规模达2800亿。该模型采用4096块TPUv3加速芯片进行训练,并结合了多种并行加速策略。该研究主要用于探索不同规模的模型的优势和不足,了解在模型参数规模增长后,在哪些领域上能够得到更好的性能表现。
研究者发现,模型规模的增长对于阅读理解、事实核查、毒害言论辨认等任务有较大提升,但是逻辑推理和常识任务上的提升并不显著。此外,研究者也研究了Gopher模型在对话等领域的能力以及缺陷。
图注:Gopher和其他模型在大规模多任务语言理解(Massive Multitask Language Understanding,MMLU)基准上在不同类别下的表现
来源:https://deepmind.com/blog/article/language-modelling-at-scale
其他案例:企业和科研机构持续研发超大规模预训练模型
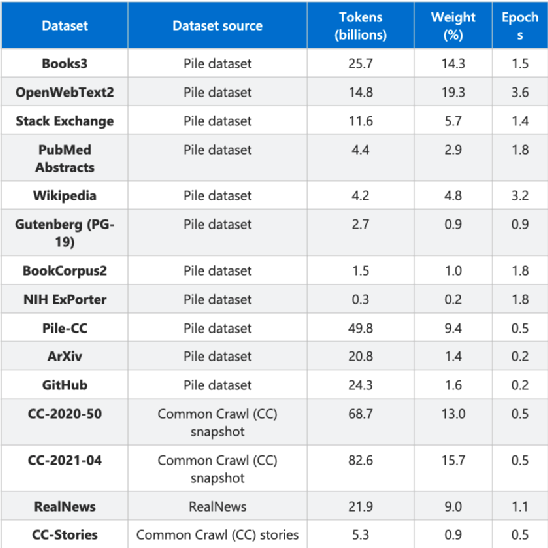
除以上案例外,4月,华为云联合循环智能发布盘古NLP超大规模预训练语言模型,参数规模达1000亿,联合北京大学发布盘古α超大规模预训练模型,参数规模达2000亿;阿里达摩院发布270亿参数的中文预训练语言模型PLUG,联合清华大学发布参数规模达到1000亿的中文多模态预训练模型M6,目前已突破十万亿参数规模。7月,百度推出ERNIE 3.0 知识增强大模型,参数规模达到百亿。
10月,浪潮发布约2500亿的超大规模预训练模型;12月,百度推出ERNIE 3.0 Titan模型,参数规模达2600亿;谷歌训练参数规模达4810亿的巨型BERT模型,结果公布在MLPerfv1.1训练榜单上;此外,谷歌还提出了1.2万亿参数的通用稀疏语言模型GLaM,在7项小样本学习领域的性能超过GPT-3。
03. 多模态预训练模型成为
下一个大模型重点发展领域
在大数据、大参数和大算力的支持下,预训练模型能够充分学习文本中的表征,掌握一定的知识。如果模型能够学习多种模态的数据,在图文生成、看图问答等视觉语言(Vision Language)任务上具有更强表现。多模态预训练模型是2021年的重点研究方向,OpenAI、微软、智源、清华大学、中科院自动化所等机构均发布了多模态预训练模型。
案例1:OpenAI提出大规模多模态预训练模型DALL·E和CLIP
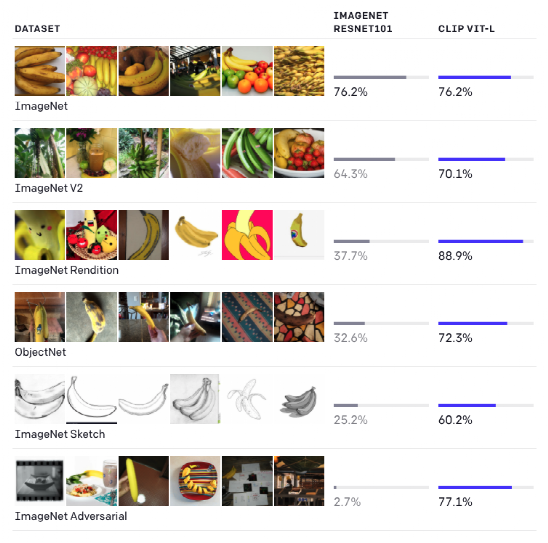
1月,OpenAI同时发布了两个大规模多模态预训练模型——DALL·E和CLIP。DALL·E可以基于短文本提示(如一句话或一段文字)生成对应的图像,CLIP则可以基于文本提示对图片进行分类。OpenAI表示,研发多模态大模型的目标是突破自然语言处理和计算机视觉的界限,实现多模态的人工智能系统。
图注:CLIP模型在多项ImageNet测试中取得优秀水平
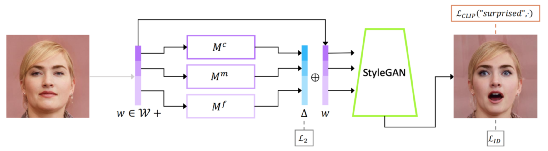
3月,以色列希伯来大学、Adobe研究院等将StyleGAN和CLIP模型结合,提出了一种能够根据文本提示生成高清晰度图像的模型,名为StyleCLIP。研究者认为,StyleCLIP能够结合预训练模型学习到的语义知识,加上生成对抗网络的图像生成能力,能够创造出更逼真的图像,在实际应用中有一定的优势。
来源:https://arxiv.org/pdf/2103.17249.pdf
来源:https://arxiv.org/pdf/2103.17249.pdf
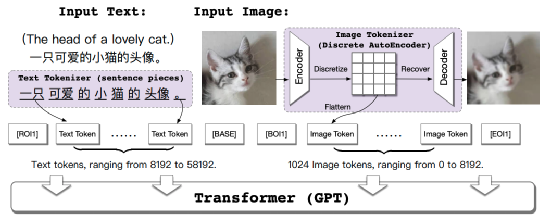
案例3:智源、清华等研究者提出文生图模型CogView
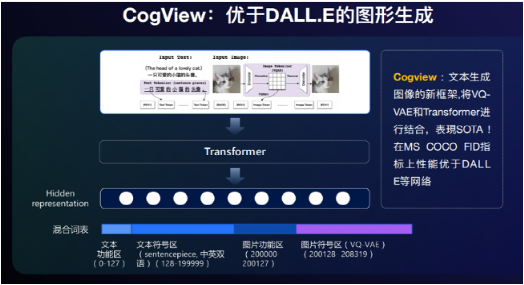
5月,智源研究院、清华大学、阿里达摩院的研究者发布了CogView文生图模型论文,其将VQ-VAE和40亿参数的Transformer模型结合,通过在风格学习、超高清图像生成、文-图排序和时尚设计等多个下游任务上进行微调,并采用了消除NaN损失等稳定预训练的方法。
实验结果显示,CogView在模糊化后的MS COCO dataset数据集上取得了最高的FID结果,高于以往的GAN和DALL·E。
来源:https://arxiv.org/pdf/2105.13290.pdf
来源:https://arxiv.org/pdf/2105.13290.pdf
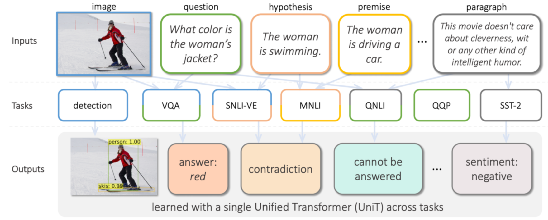
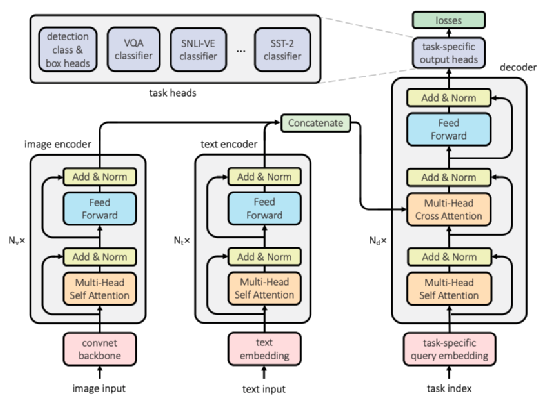
案例4:Facebook研究者提出多任务多模态统一模型UniT
8月,Facebook研究团队提出了名为UniT的多任务多模态统一Transformer模型,其基于统一的Transformer Encoder-Decoder架构,能够同时解决视觉、多模态、语言等领域中的一系列任务,包括目标检测、视觉-文本推理、自然语言理解等。论文表示,该模型在7个任务上都有较强的性能。
来源:https://arxiv.org/pdf/2102.10772.pdf
来源:https://arxiv.org/pdf/2102.10772.pdf
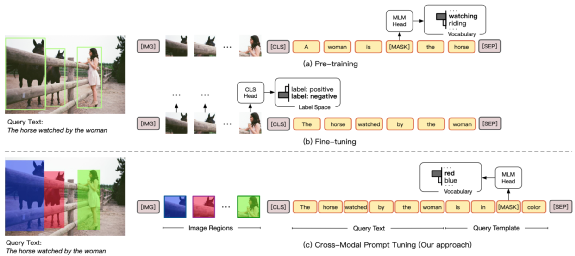
9月,清华和新加坡国立大学的研究者提出了跨模态提示学习模型CPT,其利用颜色对跨模态预训练模型进行基于提示学习的微调,在视觉定位、场景图生成任务的少次学习场景下较基线模型取得显著提升。
来源:https://arxiv.org/pdf/2109.11797.pdf
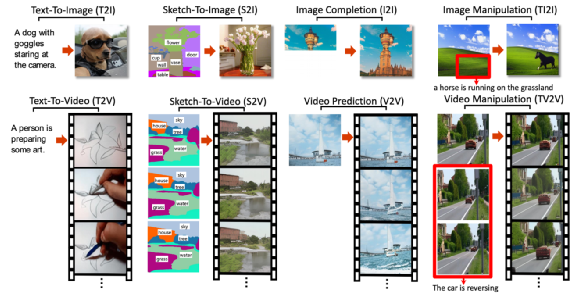
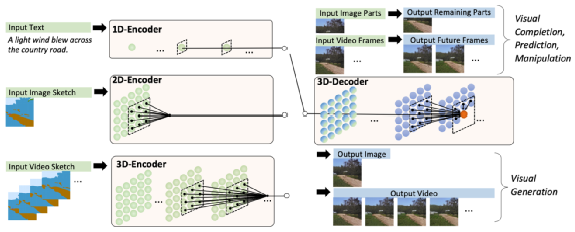
案例6:微软亚洲研究院、北大研究者提出涵盖三种模态数据的预训练模型NÜWA(女娲)
11月,微软亚洲研究院、北大研究者提出统一多模态预训练模型NÜWA。该模型采用3D Transformer架构,能够生成视觉(图像或视频)信息。通过将该模型在8个下游任务上进行试验,女娲模型在文生图、文生视频、视频预测等任务上实现最佳性能。
来源:https://arxiv.org/pdf/2111.12417.pdf
来源:https://arxiv.org/pdf/2111.12417.pdf
04. 加速方法创新提升超大参数规模模型的训练效率
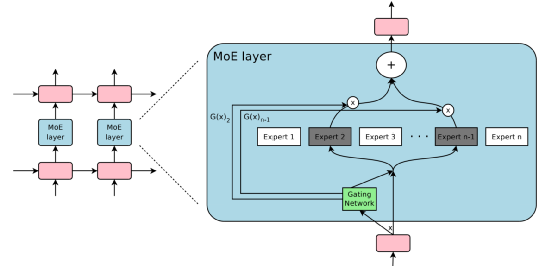
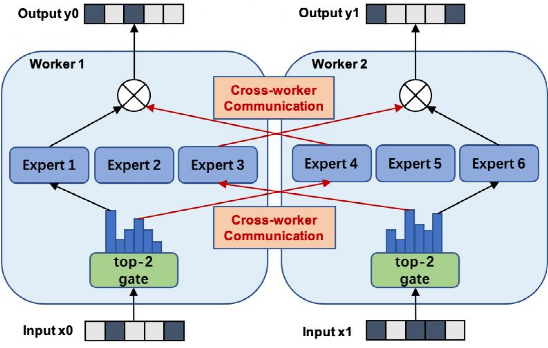
受制于算力资源,超大规模预训练模型的训练和推理面临严重的瓶颈。在GShard和Switch Transformer的研究中,谷歌通过采用混合专家技术(Mixture of Experts,MoE),通过在神经网络中引入多个专家网络(Expert Network),降低需要激活的神经元数量,提升模型的计算效率,将预训练语言模型的参数提升至万亿规模。
图注:MoE的架构,采用稀疏门控函数(Sparse Gating Function)来决定执行计算的专家网络
来源:https://arxiv.org/pdf/1701.06538.pdf
案例1:微软等研究者提出ZeRO-Offload异构训练技术
随着超大规模预训练模型参数规模的增加,今年出现了更多大模型计算加速和优化方法,着力提升模型的计算效率。1月,微软、加州大学默塞德分校(University of California, Merced)的研究者提出了一种名为“ZeRO-Offload”的异构深度学习训练技术,使用相同的硬件能够训练比以往规模大10倍的模型。
在32GB RAM的V100 GPU上,用户可以通过ZeRO-offload训练130亿参数的GPT-2;在单个DGX-2服务器上,ZeRO-offload能够训练参数量超700亿的模型,在原有的硬件基础上实现了4.5倍的模型规模提升。
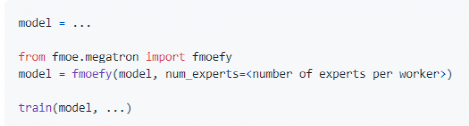
案例2:智源、清华研究者联合研发FastMoE加速系统
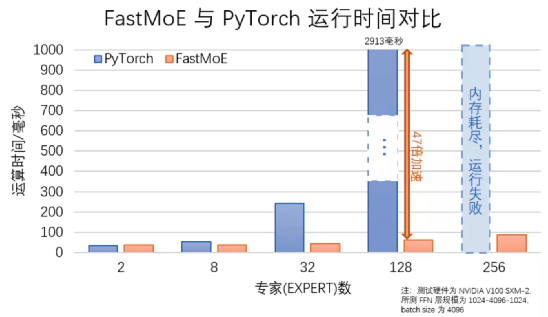
由于MoE技术和谷歌软硬件绑定,其无法直接应用于PyTorch等开源算法框架。为了解决这一问题,3月,智源研究院和清华大学联合研发了名为FastMoE的加速系统,使普通用户可以通过改写代码的方式,直接使用MoE模块。
相比原版,FastMoE实现了47倍的提速优化。FastMoE系统既可以作为PyTorch网络中的一个模块使用,也可用于改造现有网络中某个层。用户只需要几行代码便可调用MoE模块。FastMoE也支持将任意神经网络模块作为专家网络,并包含了一些专门优化的CUDA代码,更加充分地利用了GPU大规模并行计算的能力。
来源:https://github.com/laekov/fastmoe
图注:FastMoE和原版PyTorch性能的对比
来源:https://mp.weixin.qq.com/s/9Quf_sfxHlugj-91XKQxJg
来源:https://mp.weixin.qq.com/s/9Quf_sfxHlugj-91XKQxJg
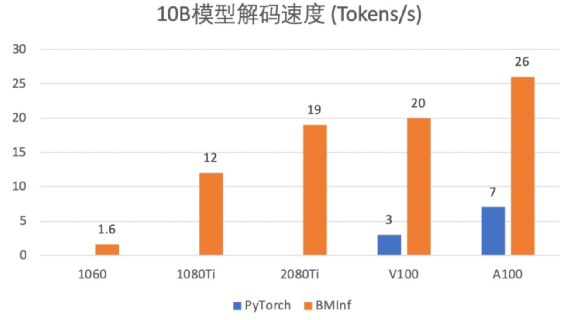
案例3:智源、清华研究者联合研发BMInf加速系统
预训练大模型在各个领域均取得了惊人的效果,但大模型的应用却具有较高的算力门槛,较长的模型响应速度。9月,清华与智源研究者联合发布了低资源大模型推理工具包BMInf,在消费级显卡上也可以进行百亿大模型的高效推理。
来源:https://github.com/OpenBMB/BMInf
10月,微软和英伟达联合提出了PTD-P(Inter-node Pipeline Parallelism, Intra-node Tensor Parallelism, and Data Parallelism)训练加速方法,通过数据并行、张量并行和Pipeline并行“三管齐下”的方式,将模型的吞吐量提高10%以上。
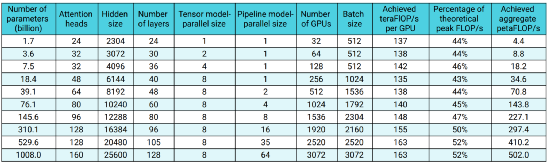
该并行方法可以在3072个GPU上,以502P的算力对一万亿参数的GPT架构模型进行训练,实现单GPU吞吐量52%的性能提升。利用该技术,微软和英伟达在3000多块GPU上训练出5300亿参数的超大规模预训练语言模型Megatron-Turing。
图注:采用PTD-P技术训练模型时达到的参数规模和性能水平
(单位:teraFIOP/s per GPU;petaFLOP/s)
来源:https://arxiv.org/pdf/2104.04473.pdf
随着数据规模逐渐扩大,数据模态进一步丰富,预训练模型将向更多领域渗透,通过“预训练-微调”的范式,完成多种类型的任务。在科研领域,预训练模型将与领域内的数据结合,成为一种完成下游任务的“基础模型”,助力诞生更多科学研究发现。在产业领域,面向更为复杂的智能决策场景,基于多种互联网数据进行预训练,具有决策能力的大模型可能是下一步发展的重点。
5月,谷歌在2021 IO大会上公开了多任务统一模型(Multitask Unified Model,MUM)的发展情况。MUM模型能够理解75种语言,并预训练了大量的网页数据,擅长理解和解答复杂的决策问题,并能够从跨语言多模态网页数据中寻找信息,在客服、问答、营销等互联网场景中具有应用价值。
图注:MUM模型能够根据用户提问从多种源头的网页信息中搜索出对应的旅行攻略
来源:https://blog.google/products/search/introducing-mum/
案例2:清华、智源等研究者提出中文核心语言模型CPM
6月,清华、智源等研究者在北京智源大会上公开了以中文为核心的多语言预训练模型CPM,兼具中英文语言的理解和生成能力,在识记、阅读、分类、推理、跨语、生成、概括等七大机器语言能力测试中,与现有开源预训练模型相比整体性能显著最优。公开可下载的CPM-2模型分为3个不同版本:110亿参数中文模型、110亿参数中英模型以及1980亿中英MoE模型。
来源:https://arxiv.org/pdf/2106.10715.pdf
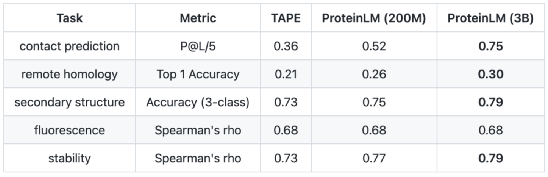
案例3:智源、清华等研究者提出蛋白质预训练模型ProteinLM
8月,智源研究院悟道团队联合清华大学、腾讯量子实验室提出蛋白质预训练模型ProteinLM,目前已开源2亿和30亿参数规模的模型。该模型支持蛋白质二级结构预测、荧光性预测、接触预测、折叠稳定性预测和远缘同源性检测任务。相较于基线模型TAPE(3800万参数),ProteinLM在下游任务上表现有所提升,尤其是在蛋白质折叠预测问题上,模型较基线模型提高了39%。
图注:ProteinLM模型在下游任务中的性能表现
来源:https://github.com/BAAI-WuDao/ProteinLM
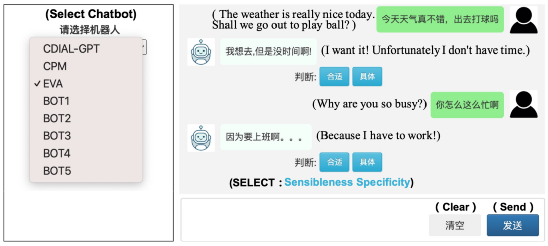
案例4:清华大学研究者提出基于大模型的EVA对话系统
8月,智源研究院学术副院长、清华大学唐杰等学者提出了基于超大规模预训练模型的开放域中文对话系统EVA。该系统有28亿参数,基于14亿对话对的WDCDialogue数据集训练。实验显示,EVA相比其他中文的预训练对话系统在多轮人机对话场景下有更好的表现。
来源:https://arxiv.org/pdf/2108.01547.pdf