

美国陆军旋转翼飞机的下一个机群除了拥有一套先进的技术和武器装备外,还将允许在战斗中使用更长的时间。这些飞机将可能是陆军武库中最先进和最复杂的系统。这意味着这些飞机可能需要飞行员在远高于目前直升机的水平上进行多重任务。由于在驾驶这些飞行器时对飞行员的要求越来越高,实时监测飞行员的认知负荷、健康和福祉的需要已经成为完成任务的组成部分。有了实时的生理监测,就有可能跟踪和了解任务认知需求的程度,以及在多域作战(MDO)任务集的各个阶段对飞行员的相关认知负荷(CWL)。然后,这些数据可以为领导层和团队成员提供信息,并为操作人员提供关键的反馈。这些数据还将为驾驶舱布局的关键决策点提供信息,具体到人机互动。然而,仍有许多工作要做,因为在哪些措施能最有效地捕获和量化CWL、如何最好地在驾驶舱内部署这些传感器、以及如何量化数据以便于实时解释结果以帮助决策方面还存在未知数。
为了支持扩大的未来垂直升降(FVL)任务,美国陆军航空医学研究实验室(USAARL)正在进行研究。最终的目标是实施生理测量,作为在操作员状态监测(OSM)驱动的适应性自动化环境中,评估CWL的一种手段。本报告对最近的CWL文献进行了系统回顾,以确定哪些CWL评估技术在航空领域得到了最多的使用和成功,特别是在旋转翼航空领域。首先,提供了CWL的正式定义,以及对CWL结构越来越感兴趣的证据。随后,对不同的CWL指标进行了简要总结,并对使用多种指标,即综合指标来评估CWL进行了考虑。
认知负荷定义
统一使用的CWL正式定义还没有被整个研究界普遍接受。因此,人们经常发现,不同的研究人员使用不同的定义(Cain,2007)。为了保持一致性,我们采用了Van Acker等人(2018)的概念分析所提出的资源需求框架的定义: "心理负荷是一种主观体验的生理处理状态,揭示了一个人有限的、多维的认知资源与所接触的认知工作需求之间的相互作用。"
为了消除任何混淆点,请注意Van Acker等人(2018)使用了 "心理负荷"(MWL)一词,而我们在本评论中使用的是 "认知负荷"。有关评估认知工作需求导致的认知资源支出的文献,已经交替使用了这两个术语(即心理和认知)(甚至有时在同一篇论文中交替使用)。图1详细说明了几十年来每个术语的使用情况;"心理负荷 "一词在文献中出现的时间较早(Westbrook等人,1966年),比 "认知负荷 "使用的频率更高。在USAARL进行的工作中,已经采用了 "认知负荷 "这一术语。
Van Acker等人(2018)的定义包括三个关键部分(关于这些要点的更广泛讨论,请参考Vogl等人,2020)。首先,CWL的发生是由于特定的人和特定的任务/环境(或任务+环境组合)的互动。这种应用认知资源来满足任务需求的互动导致了对CWL的感知。这为资源需求框架奠定了基础,该框架自卡尼曼(1973年)在其《注意力与努力》一书中首次提出以来,一直在不断发展。第二,当认知资源被用于一项任务时,对于努力工作的人来说,他们的资源是有限的,如果一项任务对资源的需求超过了可用的限度,人的表现就会减弱。对内省的人来说,还可以观察到,在某些情况下,可以比其他情况下更有效地满足多种任务需求。Wickens(2008)通过多重资源理论澄清了这一看法,该理论指出,与其说有一个有限的资源库可用于解决任务需求,不如用多重资源库的模式来解释多任务经验。第三,Van Acker等人(2018)指出,CWL是一种主观体验的生理处理状态;也就是说,人类理解并能够沟通他们正在经历CWL,他们的生理变化是CWL的一个功能。因此,评估CWL不仅可以通过任务本身的表现措施,还可以通过自我报告措施(即主观措施)和监测生理信号的变化(即生理措施)。最后要说明的是,Van Acker等人(2018)的定义很适合于对这个概念的简要介绍,但我们希望有一个更全面的定义,明确强调人类经验的其他方面(如个体差异、情景因素、注意力等)以及CWL和绩效的动态关系。关于CWL概念的更深入的定义和重新分析,见Longo等人(2022)。
自20世纪60年代首次正式提及CWL以来,它已成为一个越来越受欢迎的研究领域。在过去的十年里,根据谷歌学术搜索引擎的索引,CWL研究的出版物数量激增(图1)。在过去的十年里,整个文章和标题中的精确短语匹配都遵循同样的加速增长模式。这种加速增长的兴趣说明了对更先进、更有效的生理指标、建模技术的调查,以及对改善航空和驾驶等安全关键领域性能的普遍重视。2015年,Young等人(2015)研究了CWL文献,并确定了几十年来的主要研究领域。在20世纪80年代,在CWL主要理论进展的持续发展中,软件工程/计算机辅助设计(CAD)和自适应界面(即响应操作者CWL的自动化)等领域成为主要兴趣。20世纪90年代,对CWL的研究在航空和驾驶领域继续进行得最为频繁。最终,在2000年代的前十年,驾驶领域将远远领先于其他领域,而铁路领域的研究变得越来越有意义,航空和空中交通管制(ATC)保持稳定(图5)。考虑到几十年来的关注领域,很明显,CWL评估是安全关键领域的一个重要组成部分,特别是在交通领域。
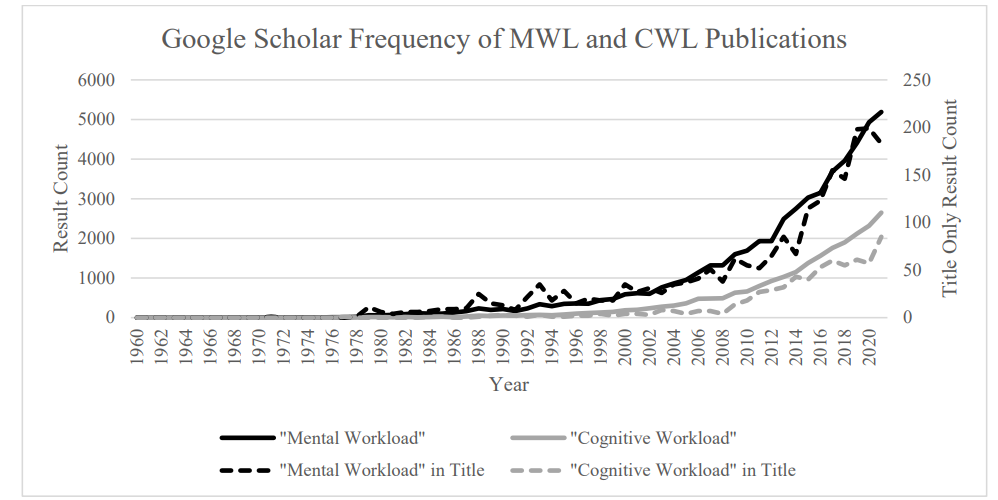
图 1. 60 年来脑力负荷和认知负荷出版物的频率。从谷歌学术搜索引擎获得的频率数据。
综合认知负荷评估
正如所提出的CWL定义中所概述的那样,CWL的概念在操作上是可以使用性能、生理学和主观评价的措施进行量化的。这些测量类别在整个CWL文献中被持续使用,每个类别都提供了一些不同评价标准的权衡(O'Donnell & Eggemeier, 1986)。快速的文献搜索显示,对这些测量技术已经进行了超过20,000次检查(评论见Cain, 2007; Heard等人, 2018; Tao等人, 2019; Charles & Nixon, 2019; Vogl等人, 2020)。
表现和CWL是以一种反向的方式联系在一起的,特别是在最佳的任务需求水平下,但这种关系并不简单地归结为一个上升,另一个下降。相反,通过自愿招募认知资源(即导致CWL增加的努力),性能可以保持在高水平而负荷增加。也就是说,人类可以付出更多的努力,调动更多的资源,或者随着需求的增加而 "更努力地 "完成一项任务,以保持他们的表现。只有到了一定程度,也就是传统上所说的 "红线",绩效才会开始动摇,从而与高水平的CWL形成反向关系。图2详细说明了作为任务需求增加的函数的绩效-负荷关系(改编自De Waard, 1996和Young等人, 2015)。这个修改后的区域模型说明了绩效和负荷在D、A2和C区域有一致的反向关系,而在A1、A2和B区域则有更多的动态变化。以这个模型为框架,我们很容易看到,除非在D或B区域内观察,否则主要的任务绩效测量可能缺乏敏感性。由于绩效指标通常是对任务效率的全面调查,它们很少对不同资源的认知负荷进行诊断性描述。虽然这些类型的性能指标可能在一个相对粗略的尺度上发挥作用,但它们对整个任务性能的干扰是最小的,因为数据往往是现成的。在航空领域,标准偏差、输入活动和教员飞行员评级的措施已被广泛用于区分高和低水平的CWL。
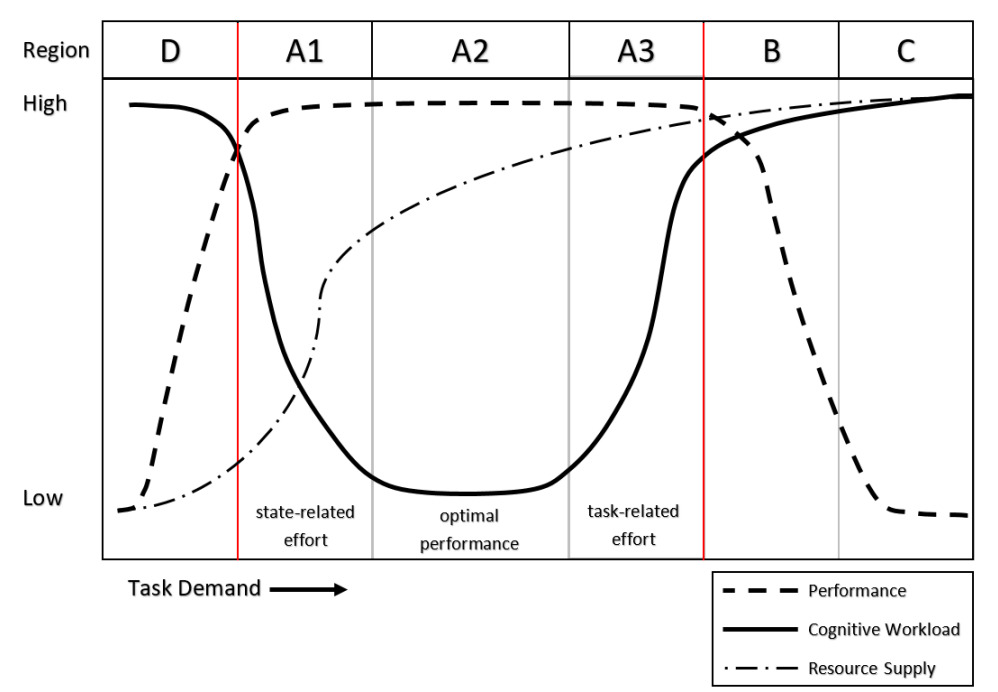
图 2. 绩效-认知负荷关系的描述(改编自 De Waard,1997 年和 Young 等人,2015 年)。
已经观察到可识别的生理信号在不同程度的有经验的CWL下发生变化,一些生理指标已经发现成功地作为CWL的操作措施。心率、心率变异性、瞳孔直径、脑电图(EEG)信号带、通过功能性近红外光谱(fNIRS)测量的脑氧饱和度以及许多其他指标,都有大量文献支持它们作为CWL的代理测量。与性能指标不同,生理学指标允许研究人员挖掘发生在性能保持稳定(即A1和A2区域)而CWL正在积极变化的区域的CWL变化。在某种程度上,生理指标允许研究人员看到随着任务需求的增加,"引擎盖 "下发生了什么。这种在接近红线时观察CWL变化的能力说明了测量类别的普遍高灵敏度。此外,它为应用领域的研究人员提供了一种手段,以预测性能故障的发生,并在性能开始受到影响之前补救任务要求。然而,其他生理现象,如疲劳、焦虑或身体运动,可以高度干扰这些指标的整体敏感性。生理指标在其诊断性方面可以有很大的不同。一些生理指标提供了一个更全面的有经验的CWL尺度,如瞳孔直径或心率变异性。其他指标通过确定大脑内的激活区域,如EEG或fNIRS指标,或由特定的任务要求(即眨眼动态)驱动,显示出更高的CWL资源诊断能力。目前正在进行的工作是限制生理传感器的整体侵入性,以便向现实世界的应用迈进。一些传感器的侵入性很小(如心电图[ECG]、远程眼球追踪器等),而另一些则会造成较高的侵入性(如头戴式眼球追踪器、fNIRS、皮肤电活动等)。在航空领域,心率和心率变异性指标是使用最广泛的生理学指标之一,因为它在敏感性、诊断性和对操作环境的干扰性之间有一个公平的平衡(Backs,1995)。然而,最近的研究已经接近于优化瞳孔直径、fNIRS和EEG等指标,作为额外的生理测量指标在航空领域使用。
CWL是一种独特的体验,人类可以通过自省来识别和描述。因此,可以通过使用结构化的、经过验证的、采取主观测量形式的问题来捕捉这种自我报告的体验。多年来,许多不同的CWL主观量表已经在各研究领域进行了测试,并表明人类可以可靠地指出他们在特定任务中体验到的CWL水平。总的来说,主观衡量标准对CWL的变化显示出很大的敏感性。主观评分允许研究人员对图2中描述的所有区域的CWL进行采样。主观指标也可以通过使用单维和多维措施,分别从低到高的诊断性范围。单维主观指标要求操作者评估他们所经历的CWL的单一方面,例如通过评价努力支出、资源能力或一般CWL本身。多维度的主观衡量标准更具有诊断性,因为多个问题或子量表涉及到CWL体验的许多相似但不同的元素。不幸的是,如果在任务执行过程中完成主观测量,其干扰性通常很高。因此,大多数主观测量是在任务执行后完成的,要求操作者在回答问题时反思他们之前的CWL体验。当然,一些单维的主观衡量标准试图规避这一限制,提示受试者在任务执行期间表明他们的主观CWL,从而与诊断性进行权衡。总的来说,主观指标被用作验证系统和其他CWL指标的手段。这个研究领域中最普遍的衡量标准是美国国家航空航天局的任务负荷指数(NASATLX),它至今仍被广泛使用。 NASA-TLX经常被用作航空领域的多维CWL主观衡量标准,但有些衡量标准,如贝德福德负荷表和修正的Cooper Harper处理质量评分表,是专门为航空领域设计的,如今也被普遍用作单维衡量标准。
由于每种类型的认知负荷评估技术都有其自身的优势和缺点,因此,将表现、生理和主观测量结合起来,形成认知负荷的综合测量似乎是很自然的。其逻辑是,由于这些认知负荷的每个反应都是从同一个人身上测量出来的,因此这些反应会相互关联,如果一个反应失败,其他的反应可以作为一个冗余的备份。当综合测量显示每个单项测量中的认知负荷都在增加时,我们可以确信所研究的操作者正经历着更高水平的认知负荷,反之亦然,认知负荷的反应也在不断减少。如果每个认知负荷评估指标出现不同的反应,考虑到这些反应是从一个人身上收集的,被研究的操作者的经验就变得不那么清晰了,而且更令人费解。例如,操作员可以在主观测量中报告低水平的认知负荷,但他们的生理测量表明负荷水平在增加,而他们的性能指标却保持稳定。同样,同样的不一致性可以在不同的认知负荷测量中建模,每个人的反应都表示高、低或稳定的认知负荷。Hancock和Matthews(2019)探讨了认知负荷评估的关联、不敏感和不一致(AID)的概念,以创建一个框架,用它来理解综合负荷评估指标的可能状态。定义这些可能的复合认知工作负荷评估状态的三维矩阵可以在图3中看到。
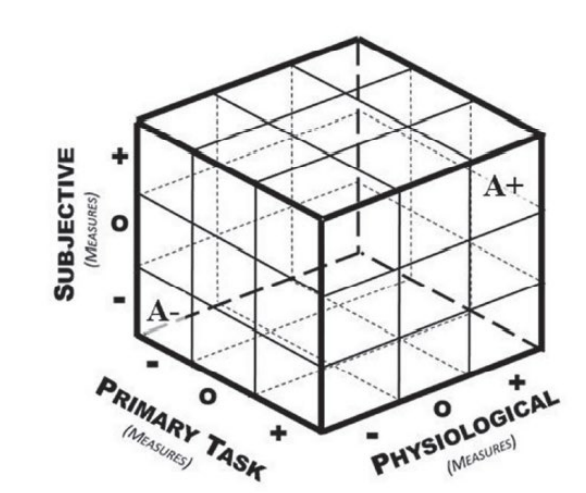
图3. Hancock和Matthews(2019)的认知负荷评估技术的关联、不敏感和分离(AID)框架矩阵。每项措施都可以表明认知负荷反应的增加(+)、减少(-)或稳定(O)。由于每个状态都由矩阵中的一个立方体表示,跨越性能(主要任务)、生理学和主观测量的27种结果组合是可能的。当测量结果相互一致时(即所有测量结果都显示认知负荷减少或增加),就会出现双重关联(用A-表示减少,用A+表示增加)。
Hancock和Matthews(2019)的AIDs分类法为复合认知负荷评估状态,沿立方体矩阵的轴线呈现了认知负荷评估的三种主要方法。每种方法允许三种反应中的一种: 增加的认知负荷反应(+),减少的认知负荷反应(-),以及稳定的(即不敏感的)认知负荷反应(o)。结合每个单独的测量的反应结果,产生一个三维矩阵,定义复合认知负荷测量的27个独特状态。当不同类型的负荷测量的反应相互匹配时(例如,生理和主观测量所显示的负荷增加),两个测量之间就会发生关联。如果两种测量方法的反应彼此不一致,就会发生分离。双重关联(如图1中A+和A-状态所表示的)发生在所有三种测量方法都报告了相同的反应的情况下(即所有测量方法都显示了认知负荷增加、稳定或减少的匹配反应)。同样,当这时所有的测量方法都彼此不一致时,就会发生双重离析。虽然双重关联简化了认知负荷数据的解释问题,但认识到影响测量结果趋同的因素可以帮助理解为什么会发生离散。Hancock和Mathews(2019)详细阐述了这些措施之间的衔接问题,并确定了可能影响措施之间反应不匹配的常见问题。诸如测量方法之间的颗粒度、不同测量方法之间的认知负荷反应的时间、自我调节策略和负荷历史等因素都会导致不同测量技术之间的不一致。归根结底,这些问题仍未解决,但认识到它们的存在可以帮助解释即使是最不相关的数据集。
本报告的目标
本报告研究了过去十年(2010年代)的CWL文献,以扩展Young等人(2015)报告的趋势。为了指导USAARL正在进行的CWL研究的发展,对航空领域的复合CWL评估文献进行了重点搜索。旋转翼和固定翼航空平台都包括在搜索范围内。从这些航空文章中,报告了不同CWL指标的使用频率和成功率。同时还研究了作为个体差异(即飞行经验)和研究平台(即模拟器或飞机)功能的CWL评估的差异数据。最后,通过CWL评估的AIDs模型对综合CWL指标的结果进行了研究。

