

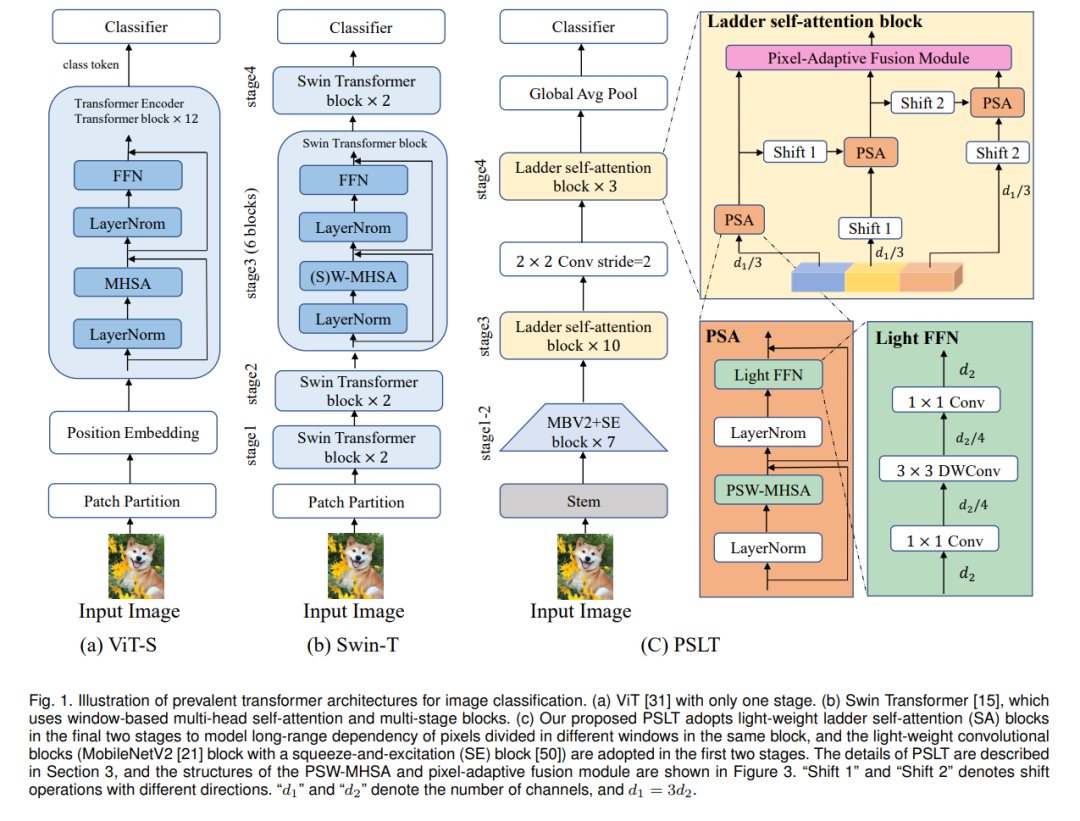
Vision Transformer (ViT) 显示了在各种视觉任务上的巨大潜力,因为它能够模拟长距离的依赖关系。但是,ViT 需要大量的计算资源来计算全局自注意力。在这项工作中,我们提出了一个带有多个分支的梯形自注意力块和一个逐步位移机制,以开发一个需要较少计算资源的轻量级变换器骨架,名为 Progressive Shift Ladder Transformer (PSLT)。首先,梯形自注意力块通过在每个分支中模拟局部自注意力来减少计算成本。与此同时,提出了逐步位移机制,通过为每个分支模拟各种局部自注意力并在这些分支之间互动,来扩大梯形自注意力块中的接受场。其次,梯形自注意力块的输入特征为每个分支沿通道维度均分,这大大降低了梯形自注意力块中的计算成本(参数和FLOPs的数量几乎是原来的1/3),然后这些分支的输出通过像素自适应融合进行合作。因此,带有相对较少参数和FLOPs的梯形自注意力块能够模拟长距离交互。基于梯形自注意力块,PSLT在几个视觉任务上表现良好,包括图像分类、目标检测和人员重新识别。在ImageNet-1k数据集上,PSLT的top-1精度为79.9%,参数为9.2M,FLOPs为1.9G,这与多个现有的参数超过20M和4G FLOPs的模型相当。代码可在 https://isee-ai.cn/wugaojie/PSLT.html 上获得。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日