

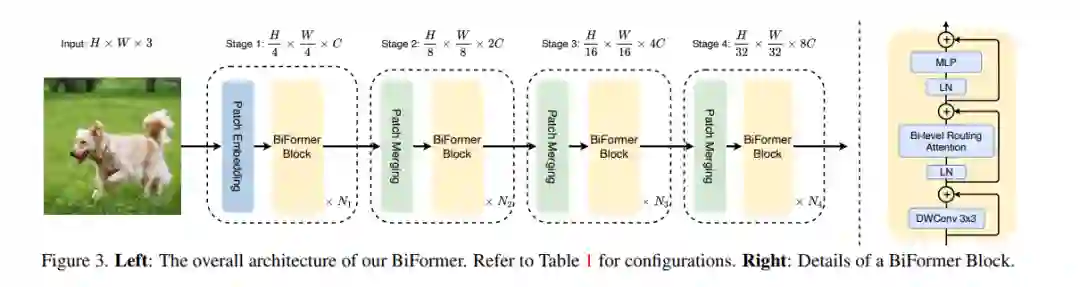
作为视觉transformer的核心构建模块,注意力是捕捉长程依赖关系的强大工具。然而,这种能力是有代价的:它会带来巨大的计算负担和内存占用,因为要计算所有空间位置上的成对token交互。一系列工作试图通过将手工制作的和内容无关的稀疏性引入注意力来缓解这个问题,例如将注意力操作限制在局部窗口、轴向条纹或膨胀窗口内。与这些方法相比,本文提出了一种新的通过双层路由的动态稀疏注意力,以实现具有内容感知的更灵活的计算分配。具体来说,对于一个查询,首先在粗粒度的区域级别上过滤掉不相关的键值对,然后在剩余的候选区域(即路由区域)中应用细粒度的token-to-token attention。本文提供了所提出的双层路由注意力的一个简单而有效的实现,利用稀疏性来节省计算和内存,同时只涉及GPU友好的密集矩阵乘法。用所提出的双层路由注意力建立了一个新的通用视觉transformer,称为BiFormer。由于BiFormer以查询自适应的方式关注一小部分相关标记,而不会分散其他不相关标记的注意力,因此它具有良好的性能和较高的计算效率,特别是在密集预测任务中。在图像分类、目标检测和语义分割等计算机视觉任务中的经验结果验证了所设计的有效性。代码可以在https://github.com/rayleizhu/BiFormer上找到。
成为VIP会员查看完整内容
相关内容

CVPR 2023大会将于 6 月 18 日至 22 日在温哥华会议中心举行。CVPR是IEEE Conference on Computer Vision and Pattern Recognition的缩写,即IEEE国际计算机视觉与模式识别会议。该会议是由IEEE举办的计算机视觉和模式识别领域的顶级会议,会议的主要内容是计算机视觉与模式识别技术。
CVPR 2023 共收到 9155 份提交,比去年增加了 12%,创下新纪录,今年接收了 2360 篇论文,接收率为 25.78%。作为对比,去年有 8100 多篇有效投稿,大会接收了 2067 篇,接收率为 25%。



相关VIP内容
相关资讯
相关论文