

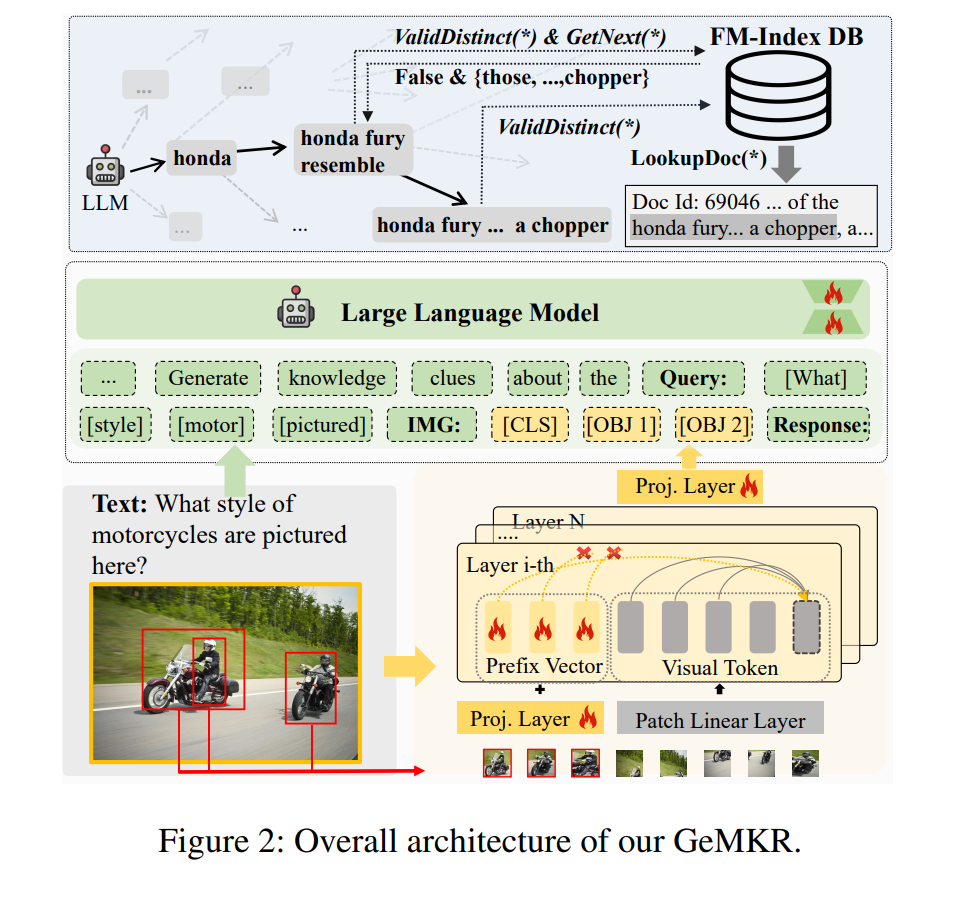
多模态查询的知识检索在支持知识密集型多模态应用中扮演着关键角色。然而,现有方法在有效性和训练效率方面面临挑战,特别是在训练和集成多个检索器以处理多模态查询时。在本文中,我们提出了一个创新的端到端生成式框架,用于多模态知识检索。我们的框架利用了大型语言模型(LLMs)即使在有限数据训练的情况下,也可以有效地作为虚拟知识库的事实。我们通过两步过程检索知识:1)生成与查询相关的知识线索;2)使用知识线索搜索数据库以获取相关文档。特别是,我们首先引入了一个对象感知的前缀调优技术来指导多粒度的视觉学习。然后,我们将多粒度的视觉特征对齐到LLM的文本特征空间中,利用LLM捕获跨模态交互。随后,我们构建了具有统一格式的指导数据进行模型训练。最后,我们提出了知识引导的生成策略,以在解码步骤中施加先前约束,从而促进独特知识线索的生成。通过在三个基准测试上进行的实验,我们展示了与强大基线相比,在所有评估指标上的显著提升,范围从3.0%到14.6%。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日