

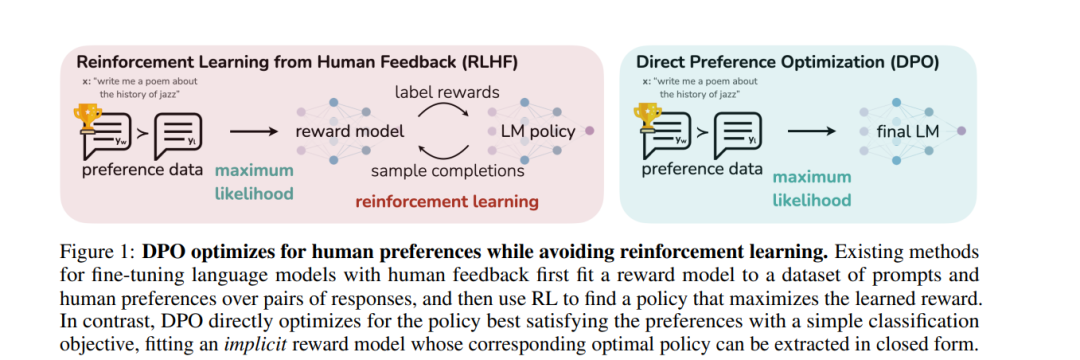
虽然大规模无监督语言模型(LMs)学习了广泛的世界知识和一些推理技能,但由于其训练的完全无监督性质,要精确控制它们的行为是困难的。现有的方法为了获得这种可操控性,会收集人类对模型生成内容相对质量的标签,并对无监督LM进行微调,使其与这些偏好一致,这通常涉及到利用人类反馈的强化学习(RLHF)。然而,RLHF是一个复杂且经常不稳定的过程,首先拟合一个反映人类偏好的奖励模型,然后使用强化学习对大型无监督LM进行微调,以最大化这个估计的奖励,同时不过分偏离原始模型。在本文中,我们介绍了RLHF中奖励模型的一种新参数化,它能够以闭合形式提取相应的最优策略,使我们能够仅使用简单的分类损失来解决标准的RLHF问题。由此产生的算法,我们称之为直接偏好优化(DPO),稳定、高效能、计算轻量,消除了在微调过程中从LM采样或进行大量超参数调整的需要。我们的实验表明,DPO可以微调LMs以与人类偏好一致,其效果与现有方法相当或更好。值得注意的是,使用DPO进行微调在控制生成内容的情感方面超过了基于PPO的RLHF,并且在摘要和单轮对话的响应质量方面达到或提高,同时在实现和训练上大大简化。
https://www.zhuanzhi.ai/paper/2a9192cb492ed106fe8632dcabd1e2c4
成为VIP会员查看完整内容

相关内容
相关VIP内容
相关资讯
相关论文