

摘要
强化学习的一个主要挑战是有效地探索一个环境,以便通过试验和错误学习最佳策略。为了实现这一目标,智能体必须能够有效地从过去的经验中学习,使其能够准确地了解某些行动对其他行动的好处。除此之外,一个明显但核心的问题是,不知道的东西必须被探索,而以安全的方式探索的必要性又给问题增加了一层难度。这些都是我们在这篇博士论文中讨论的主要问题。通过解构行为者批判框架,并利用方差概念对基础优化问题进行替代性表述,我们探讨了深度强化学习算法如何更有效地解决连续控制问题、困难探索环境和风险敏感任务。论文的第一部分集中在行为者批评框架的批评者部分,也被称为价值函数,以及如何通过对价值函数估计中的方差的独特使用,更有效地学习控制连续控制领域中的智能体。论文的第二部分是关于行为者-批评者框架的行为者部分,也被称为策略。我们建议通过引入对手,为智能体解决的优化问题引入第三个元素。对手的性质与RL智能体相同,但经过训练,可以提出模仿行为人的行动或抵消我们问题的约束。它由一些平均的策略分布来表示,行为者必须通过最大化与它的分歧来区分他的行为,最终鼓励行为者在有效探索是一个瓶颈的任务中更彻底地探索,或者更安全地行动。
1 引言
“在对同一情境做出的几种反应中,那些伴随着或紧随其后的满足感,与该情境的联系更为牢固,因此,当它再次出现时,它们将更有可能再次出现。”出自《效果法则》,爱德华-桑代克(1911年)。
在本章中,我们将介绍强化学习问题背后的动机。我们将触及深度学习在过去几年的崛起,以及它能给我们的工作带来的改进的特点。然后,我们将考虑我们希望我们的计算机能够学习什么,考虑本论文中主要关注的问题,然后讨论将在以下章节中提出的贡献,以及他们的结果和潜在的新问题。
1.1 强化学习
强化学习(RL)是机器学习(ML)的一门学科,它涉及到在不同情况下学习做出一连串的决定来最大化一些分数,后来被描述为奖励。机器软件可以采用这种技术来寻找最佳策略,以解决任何可以被表述为RL问题的问题。一些有直接用途的例子包括医疗保健问题(Schaefer, Bailey, Shechter, et al., 2005; Yu, Liu, and Nemati, 2019),复杂场景的一般视觉问题回答(Antol, Agrawal, Lu, et al., 2015; de Vries, Strub, Chandar, et al, 2017),能源管理问题(Dimeas和Hatziargyriou,2007;Levent,Preux,Pennec,等,2019)和高性能计算系统中的任务调度问题(Mao,Alizadeh,Menache,等,2016;Grinsztajn,Beaumont,Jeannot,等,2020)。其他值得注意的成就包括棋盘游戏(Tesauro,1995;Silver,Huang,Maddison,等,2016),视频游戏(Mnih,Kavukcuoglu,Silver,等,2013;Berner,Brockman,Chan,等,2019;Vinyals,Babuschkin, Czarnecki,等。2019年),或机器人控制(Kober, Bagnell, and Peters, 2013; Heess, Tirumala, Sriram, et al., 2017; Andrychowicz, Baker, Chociej, et al., 2020)。一般的RL问题考虑一个采取决策的智能体和智能体运行的环境。在每个时间段,智能体采取一个行动,并获得一个奖励和一个观察。作为一个说明性的例子,图1.1将智能体描述为一只狗,它必须完成一连串的行动,把飞盘还给它的主人,而主人扮演着环境的角色。狗观察它主人的动作,并受到玩耍的满足感和结束时得到奖励的激励。在这种情况下,RL算法使用一个试错学习过程来最大化决策智能体在先前未知环境中的总奖励。举个例子,在机器人学中,观察是摄像机图像或关节角度,行动是关节扭力,奖励包括导航到目标位置,成功到达目标位置并保持平衡。
图1.1 - 智能体与环境的互动
1.2 深度学习表征
表征学习是学习从输入数据中转换或提取特征以解决一个任务的过程。机器学习主要关注的是从数据中的函数学习。深度学习关注的是将数据中的函数学习与表征学习相结合。深度学习与机器学习具有相同的实际目的,只是它得益于一个通常更具表现力的函数近似器(这一特征在之前的工作中已经用轨迹长度的概念进行了测量(Raghu, Poole, Kleinberg, et al., 2017)),即通过连续的梯度下降步骤训练的深度神经网络。深度神经网络是一种输入到目标的映射,由一连串简单的数据转换组成,称为投影层(简单的矩阵乘法)聚合在一起,并与非线性相结合。
这样的深度学习模型通常涉及几十或有时几百个连续的表征层,这些表征层是通过接触训练数据学习的,其中计算阶段的长因果链改变了神经网络的总体激活。这种技术已经产生了一些显著的经验发现,特别是在语音识别(Dahl, Yu, Deng, et al., 2012)、图像识别(Krizhevsky, Sutskever, and Hinton, 2012)和自然语言处理(Vaswani, Shazeer, Parmar, et al., 2017)。
1.3 深度强化学习
在参数较少、缺乏构成性的简单ML模型可能会失败的情况下,深度学习可以成为涉及高维数据(如自然语言或图像和视频)的复杂任务的合适技术。深度强化学习(deep RL)是使用神经网络作为函数近似器的强化学习学科,适用于智能体的输入和输出(观察和行动)涉及高维数据的顺序决策问题。例如,Tesauro的TD-Gammon(Tesauro,1995)将RL算法与神经网络结合起来,学习玩双陆棋,这是一个有大约1020个状态的随机游戏,并发挥了人类顶级选手的水平。大约在同一时期,Rummery和Niranjan(1994)学习了一个带有函数近似的半梯度Sarsa,为Gullapalli(1990)的工作以及Lin和Tham的博士论文(Lin, 1992a; Tham, 1994)增加了内容,这些论文探索了各种RL算法与神经网络的结合。
在Tesauro的开创性工作二十年后,深度RL作为一种有前途的方法出现,用于经验驱动的自主学习,因为它们有能力获得复杂的策略和处理高维复杂的感官输入(Jaderberg, Mnih, Czarnecki, et al., 2017)。这样的算法可以完全从图像像素中学习玩几个雅达利2600视频游戏,达到超人的水平(Mnih, Kavukcuoglu, Silver, et al., 2013)。其他一些成就是开发了一个蒙特卡洛树搜索(MCTS)规划系统,加上深度RL模块(Silver, Huang, Maddison, et al., 2016),打败了一个世界围棋冠军,或者也可以直接从现实世界的摄像机输入中学习机器人的控制策略(Levine, Finn, Darrell, et al., 2016; Zhu, Mottaghi, Kolve, et al., 2017; Levine, Pastor, Krizhevsky, et al., 2018)。
在深度RL中,神经网络被用来近似实现从状态到选择每个可能行动的概率的映射的函数(称为策略),估计智能体处于给定状态的好坏的函数(称为价值函数),动力学模型或RL算法所需的其他函数。特别是,在异步优势actor-critic(Mnih, Badia, Mirza, et al., 2016)中使用的多步引导目标(Sutton, 1988)在广泛的任务上使用梯度策略显示了强大的结果。分布式Qlearning(Bellemare, Dabney, and Munos, 2017)学习贴现收益的分类分布,而不是估计平均值。Rainbow(Hessel, Modayil, Hasselt, et al., 2018)细致地结合了DQN(Mnih, Kavukcuoglu, Silver, et al., 2013)算法的若干改进,在数据效率和最终性能方面为Atari 2600基准提供了改进。Schulman, Levine, Abbeel, et al. (2015), Schulman, Wolski, Dhariwal, et al. (2017), Lillicrap, Hunt, Pritzel, et al. (2016), Haarnoja, Zhou, Abbeel, et al. (2018) and Fujimoto, Hoof, and Meger (2018) 探索了不同种类的策略梯度方法,重点是高性能、低样品利用率和稳定性的改善。
1.4 选择学习的内容
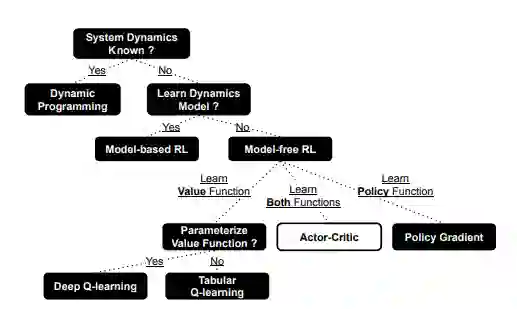
图1.2 - 强化学习算法的分类法。
通常,在强化学习中,智能体的行动是基于正在学习的最新版本的策略。在更新过程中,来自与环境互动的数据被用来推导出基于样本的目标函数,其中策略和值近似器通过梯度下降进行更新。在深度RL中,近似器是深度神经网络。这些算法的成功取决于在互动阶段发现的轨迹:如果数据包括具有高奖励的轨迹,那么这些轨迹就会被更新所加强,在新更新的策略下变得更有可能。因此,与环境的互动和近似器的更新是密切相关且高度依赖的。因此,在设计新的深度RL算法时,一个核心问题是什么应该被近似,以及如何被近似。图1.2显示了RL算法的高级分类法。在顶层,我们有动态规划(DP)算法,可以用来计算给定环境的完美模型的最优策略。事实上,DP算法(例如策略迭代和价值迭代)是典型的基于模型的算法:这些算法都使用模型对下一个状态和奖励的预测或分布,以计算出最佳行动。具体来说,在动态规划中,模型必须提供状态转换概率和任何状态-行动对的预期奖励。请注意,与大多数其他基于模型的RL算法相反,该模型很少是一个学习模型。
相反,无模型RL算法并不估计底层系统的动态,而是旨在直接优化一个策略。基于策略的方法明确地建立和学习一个策略,将状态映射到选择可能行动的概率上,并在学习期间将策略的近似值存储在内存中,以供以后使用。基于价值的方法不存储明确的策略,而是学习一个价值函数。策略是隐性的,通过选择具有最佳价值的行动从价值函数中得出。至于行为批判方法,它们是一个框架的一部分,结合了基于价值和恶略的方法的元素。
选择使用哪种方法主要取决于问题的规格(如系统动力学的复杂性)、要解决的背景(如策略的最优性)和实验规格(如时间或资源预算)。例如,基于模型的RL方法通常会加快学习速度,其代价是缺乏对动态复杂问题的可扩展性。他们通常学习一个系统动力学模型,即控制器,并将其用于规划。这样的方法可以在低维连续控制问题中以高样本效率学习成功的控制器(Deisenroth和Rasmussen,2011;Moldovan,Levine,Jordan等人,2015;Zhang,Vikram,Smith等人,2019)。这种方法的另一个应用是AlphaGo(Silver, Huang, Maddison, et al., 2016; Silver, Schrittwieser, Simonyan, et al., 2017),它通过使用蒙特卡洛树搜索(MCTS)规划模块,有效地解决了计算机围棋的问题,以利用游戏动态的知识。
在这篇论文中,我们将研究重点放在无模型方法的数据效率上,这些方法在行为批评框架中使用基于梯度的方法直接学习随机策略函数。随机策略的一个优点是,当在参数空间中移动时,它们允许策略的微小变化,而在确定性策略的情况下,类似的转变有可能会极大地改变策略。因此,参数和策略之间的耦合似乎在一般情况下更容易控制,特别是对于离散的行动空间。随机策略的另一个优点是其固有的探索性质,即通过对高斯噪声进行抽样来增加确定性的基本策略。最后,本论文主要关注的问题(连续控制任务、程序生成的任务和具有安全约束的连续控制任务)的复杂动态特征也鼓励我们采用无模型设置,不需要对环境、规格或领域知识进行假设。
1.5 概要和贡献

图1.3 - 本论文围绕行为者-批评者的构成部分展开的大纲。
在深入研究本论文之前,我们必须问自己,我们想解决什么问题,还有什么问题需要回答。促使本论文工作的一些困难来源可以描述如下。
-
对(深度)RL方法的优化和评估通常只基于对未来奖励之和的智能体。来自监督或统计学习的替代统计数据可以作为额外的性能指标加以利用。
-
在一些连续控制问题或具有稀疏奖励的任务中,策略梯度估计可能具有低振幅和不稳定,可能导致采样效率低下。一个RL智能体可能从一些过渡中比其他过渡更有效地学习,因此过滤过渡似乎是一个自然的想法,可以考虑。
-
降低方差的方法,如基线减法,在激励这些算法的概念框架和实践中实施的估计行为者-批评者框架中的批评者部分之间表现出差异。需要更有效和稳健的目标函数来估计由批评者代表的价值函数。
-
有奖励的状态往往要被访问很多次,特别是在奖励稀少的任务中使用策略性方法,智能体才能学到任何有意义的东西。价值函数的估计必须对这些极端值敏感,并尽可能有效地捕捉与奖励相对应的(有时是罕见的)信号。
-
在随机策略诱导的探索中,如果这些状态远离出发点,那么在稀疏奖励任务中访问有奖励的状态的可能性将是无限小的。某种形式的记忆需要通过使用例如以前策略的移动平均值来保持,从而避免重复那些没有导致相关学习的相同轨迹。
-
在同一想法的基础上,一个有趣的问题是,是否可以通过学习,而不是以前的策略的混合物,来构建一个类似的先验,如何打破安全约束,代表智能体应该避免的概率不安全区域。
所有这些情况都属于同一范畴:在本论文中,我们试图通过以下方式开发出比以前的方法更稳定、更节省样本的策略梯度方法:(1)利用自我表现统计给出的信息,使用更适应策略梯度方法的其他学习函数估计方法;(2)在演员-批评家二人组中引入第三个主角,作为策略必须远离的排斥性平均分布。本论文的关键是行为批评者框架,如图1.3所示。我们通过方差的棱镜来处理它的两面,首先是批评者,然后是行为者:用解释的方差和残差计算的价值函数估计的方差,以及从对抗性先验中得到的策略候选者的方差,维持策略的平均混合。
这篇论文总结了以前发表的四篇论文的研究贡献。本论文的组织结构是按照论文发表的顺序进行的,并对一些内容进行了重新组织。为了使论文有一个更连贯的结构并提高其可读性,我们将其分为两部分。第一部分从一般角度介绍了强化学习的问题。我们发展了本论文所采用的关于RL问题的一些困难的观点,并详细介绍了我们选择作为本论文的一部分来解决的问题以及研究这些问题的动机。
第二部分专门讨论在连续控制问题中更有效地学习控制智能体。在第三章中,我们介绍了学习连续控制策略的问题,并提出了在高维连续状态和行动空间中学习深度神经网络表示的推理方案。在第四章中,我们提出了在学习解决一个任务时使用更多的统计对象作为辅助损失。特别是,我们将价值函数估计的解释方差确定为一个具有有趣特性的工具,并提出了一个具有编码器共享的普遍适用的框架,以加快策略梯度智能体的学习。第五章提出了一个简单而有效的想法,即RL智能体将从一些经验数据中比其他数据更有效地学习。我们采用第四章中介绍的自我性能评估的统计数据,开发了一种对策略梯度算法的修改,在估计策略梯度时,样本被过滤掉了。在第六章中,由于最近的研究表明传统的行为批评算法不能成功地拟合价值函数,并呼吁需要为批评者确定一个更好的目标,我们引入了一种方法来改善行为批评框架中批评者的学习。
第三部分涉及图1.3中的另一面:在行为者策略的背景下,通过在行为者-批评框架中引入第三个主角来表述差异性。这个新的主角作为一个对抗性的先验,保持一个平均的策略混合物,策略分布应该被排斥在外。在第七章介绍了在具有更多现实世界特征的环境中学习的问题,如安全约束或有效探索是一个瓶颈的情况下,在第八章和第九章中,我们开发了一种在维持对抗性先验中策略候选人的变异形式,作为以前策略的混合物(第八章)和作为寻求风险的策略的混合物(第九章)。
最后,我们在第四部分给出了论文的尾声,讨论了进展和未来的前景。
著作清单
在有论文集的国际会议上的出版物
-
Yannis Flet-Berliac, Reda Ouhamma, Odalric-Ambrym Maillard, and Philippe Preux (2021)《利用残差在深度策略梯度中学习价值函数》国际学习表征会议
-
Yannis Flet-Berliac, Johan Ferret, Olivier Pietquin, Philippe Preux, and Matthieu Geist (2021)《逆向引导的行为者-批评》国际学习表征会议
-
Yannis Flet-Berliac和Philippe Preux(2020年7月)《只有相关信息才重要:滤除噪声样本以促进RL》第29届国际人工智能联合会议论文集,IJCAI-20。Christian Bessiere编辑。主赛道。国际人工智能联合会议组织,第2711-2717页。
国际会议上的研讨会发言或预印本
-
Yannis Flet-Berliac 和 Philippe Preux (2019b). MERL: Multi-Head Reinforcement Learning第33届神经信息处理系统进展会议的深度强化学习研讨会
-
Yannis Flet-Berliac and Debabrota Basu (2021)《SAAC:安全强化学习作为演员-批评家的对抗性游戏》预印本
在国际数字杂志上发表的文章
- Yannis Flet-Berliac (2019). The Promise of Hierarchical Reinforcement Learning. The Gradient - Stanford AI Lab
软件
- Omar Darwiche Domingues, Yannis Flet-Berliac, Edouard Leurent, Pierre Ménard, Xuedong Shang, and Michal Valko (2021). rlberry - A Reinforcement Learning Library for Research and Education. https://github.com/rlberry-py/rlberry
本论文中没有介绍的合作项目
-
Jacques Demongeot, Yannis Flet-Berliac, and Hervé Seligmann (2020)《温度降低传播参数的新Covid-19案例动态》生物学9.5,第94页
-
Yannis Flet-Berliac and Philippe Preux (2019a)《使用通用辅助任务的高维控制》Tech. rep. hal-02295705
-
Thomas Depas and Yannis Flet-Berliac (2019)《平行四边形的公主》展览全景21-勒弗斯诺伊国家当代艺术工作室


