TensorFlow 2.0深度强化学习指南
摘要:用深度强化学习来展示TensorFlow 2.0的强大特性!
在本教程中,我将通过实施Advantage Actor-Critic(演员-评论家,A2C)代理来解决经典的CartPole-v0环境,通过深度强化学习(DRL)展示即将推出的TensorFlow2.0特性。虽然我们的目标是展示TensorFlow2.0,但我将尽最大努力让DRL的讲解更加平易近人,包括对该领域的简要概述。
事实上,由于2.0版本的焦点是让开发人员的生活变得更轻松,所以我认为现在是使用TensorFlow进入DRL的好时机,本文用到的例子的源代码不到150行!代码可以在这里或者这里获取。
https://github.com/inoryy/tensorflow2-deep-reinforcement-learning
https://colab.research.google.com/drive/12QvW7VZSzoaF-Org-u-N6aiTdBN5ohN
建立
由于TensorFlow2.0仍处于试验阶段,我建议将其安装在独立的虚拟环境中。我个人比较喜欢Anaconda,所以我将用它来演示安装过程:

让我们快速验证一切是否按能够正常工作:

不要担心1.13.x版本,这只是意味着它是早期预览。这里要注意的是我们默认处于eager模式!

如果你还不熟悉eager模式,那么实质上意味着计算是在运行时被执行的,而不是通过预编译的图(曲线图)来执行。你可以在TensorFlow文档中找到一个很好的概述。
https://www.tensorflow.org/tutorials/eager/eager_basics
深度强化学习
一般而言,强化学习是解决连续决策问题的高级框架。RL通过基于某些agent进行导航观察环境,并且获得奖励。大多数RL算法通过最大化代理在一轮游戏期间收集的奖励总和来工作。
基于RL的算法的输出通常是policy(策略)-将状态映射到函数有效的策略中,有效的策略可以像硬编码的无操作动作一样简单。在某些状态下,随机策略表示为行动的条件概率分布。
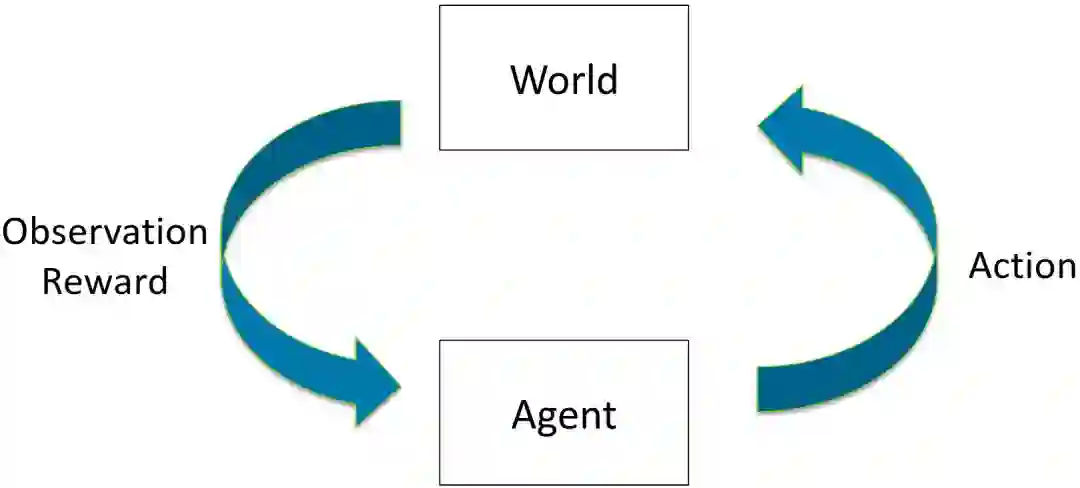
演员,评论家方法(Actor-Critic Methods)
RL算法通常基于它们优化的目标函数进行分组。Value-based诸如DQN之类的方法通过减少预期的状态-动作值的误差来工作。
https://deepmind.com/research/dqn/
策略梯度(Policy Gradients)方法通过调整其参数直接优化策略本身,通常通过梯度下降完成的。完全计算梯度通常是难以处理的,因此通常要通过蒙特卡罗方法估算它们。
最流行的方法是两者的混合:actor-critic方法,其中代理策略通过策略梯度进行优化,而基于值的方法用作预期值估计的引导。
深度演员-批评方法
虽然很多基础的RL理论是在表格案例中开发的,但现代RL几乎完全是用函数逼近器完成的,例如人工神经网络。具体而言,如果策略和值函数用深度神经网络近似,则RL算法被认为是“深度”。
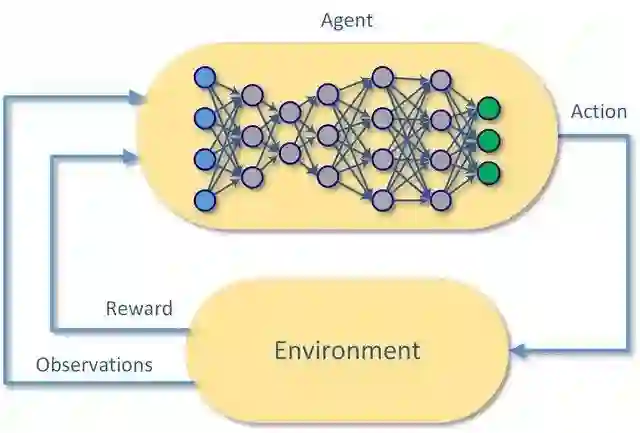
异步优势演员-评论家(actor-critical)
多年来,为了提高学习过程的样本效率和稳定性,技术发明者已经进行了一些改进。
首先,梯度加权回报:折现的未来奖励,这在一定程度上缓解了信用分配问题,并以无限的时间步长解决了理论问题。
其次,使用优势函数代替原始回报。优势在收益与某些基线之间的差异之间形成,并且可以被视为衡量给定值与某些平均值相比有多好的指标。
第三,在目标函数中使用额外的熵最大化项以确保代理充分探索各种策略。本质上,熵以均匀分布最大化来测量概率分布的随机性。
最后,并行使用多个工人加速样品采集,同时在训练期间帮助它们去相关。
将所有这些变化与深度神经网络相结合,我们得出了两种最流行的现代算法:异步优势演员评论家(actor-critical)算法,简称A3C或者A2C。两者之间的区别在于技术性而非理论性:顾名思义,它归结为并行工人如何估计其梯度并将其传播到模型中。
有了这个,我将结束我们的DRL方法之旅,因为博客文章的重点更多是关于TensorFlow2.0的功能。如果你仍然不了解该主题,请不要担心,代码示例应该更清楚。如果你想了解更多,那么一个好的资源就可以开始在Deep RL中进行Spinning Up了。
https://spinningup.openai.com/en/latest
使用TensorFlow 2.0的优势演员-评论家
让我们看看实现现代DRL算法的基础是什么:演员评论家代理(actor-critic agent)。如前一节所述,为简单起见,我们不会实现并行工作程序,尽管大多数代码都会支持它,感兴趣的读者可以将其用作锻炼机会。
作为测试平台,我们将使用CartPole-v0环境。虽然它有点简单,但它仍然是一个很好的选择开始。在实现RL算法时,我总是依赖它作为一种健全性检查。
https://gym.openai.com/envs/CartPole-v0/
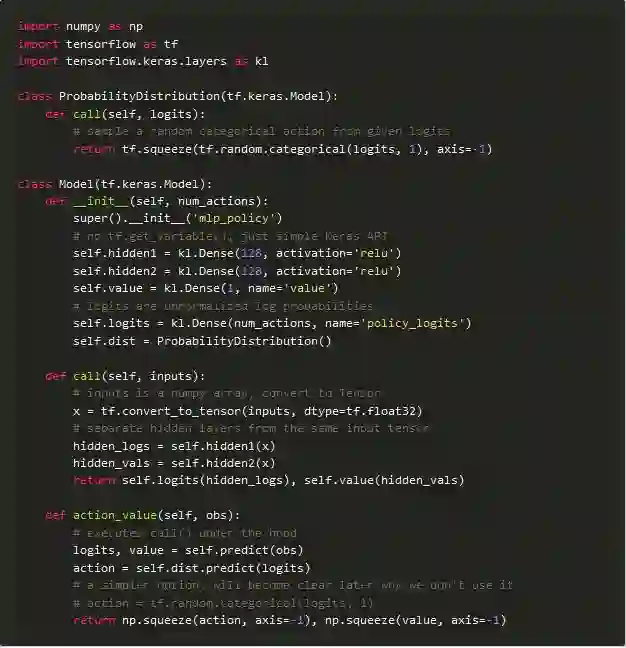
通过Keras Model API实现的策略和价值
首先,让我们在单个模型类下创建策略和价值估计NN:
验证我们验证模型是否按预期工作:
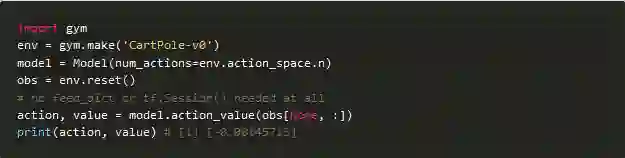
这里要注意的事项:
模型层和执行路径是分开定义的;
没有“输入”图层,模型将接受原始numpy数组;
可以通过函数API在一个模型中定义两个计算路径;
模型可以包含一些辅助方法,例如动作采样;
在eager的模式下,一切都可以从原始的numpy数组中运行;
随机代理
现在我们可以继续学习一些有趣的东西A2CAgent类。首先,让我们添加一个贯穿整集的test方法并返回奖励总和。
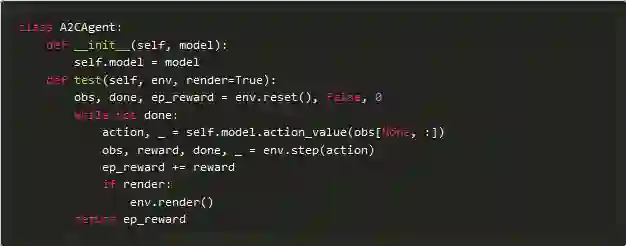
让我们看看我们的模型在随机初始化权重下得分多少:

离最佳转台还有很远,接下来是训练部分!
损失/目标函数
正如我在DRL概述部分所描述的那样,代理通过基于某些损失(目标)函数的梯度下降来改进其策略。在演员评论家中,我们训练了三个目标:用优势加权梯度加上熵最大化来改进策略,并最小化价值估计误差。
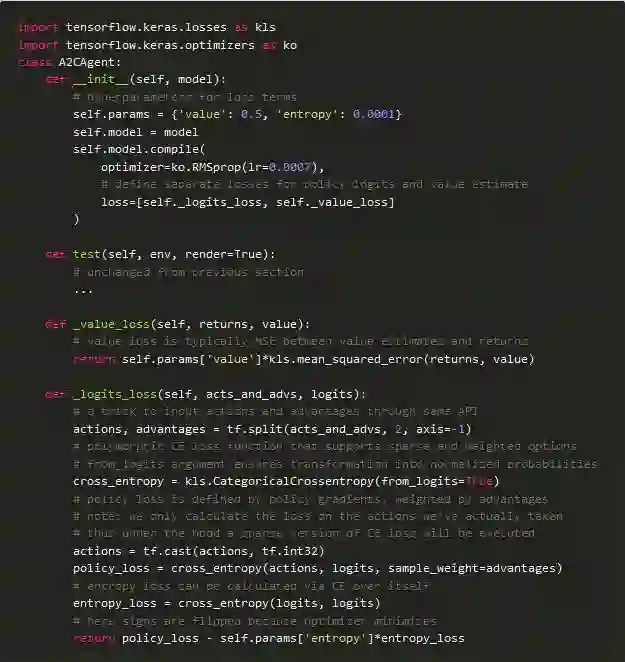
我们完成了目标函数!请注意代码的紧凑程度:注释行几乎比代码本身多。
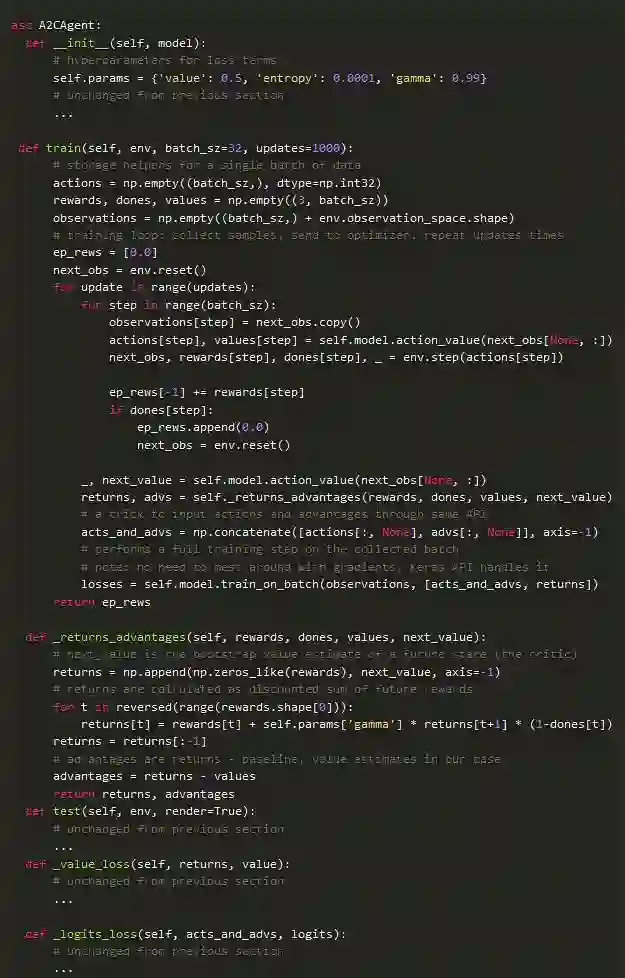
代理训练循环
最后,还有训练回路本身,它相对较长,但相当简单:收集样本,计算回报和优势,并在其上训练模型。
训练和结果
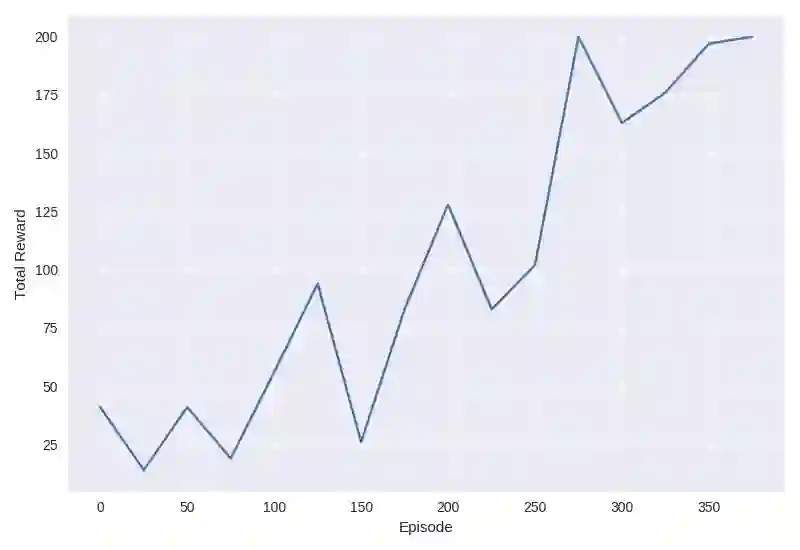
我们现在已经准备好在CartPole-v0上训练我们的单工A2C代理了!训练过程不应超过几分钟,训练完成后,你应该看到代理成功达到200分中的目标。


在源代码中,我包含了一些额外的帮助程序,可以打印出运行的奖励和损失,以及rewards_history的基本绘图仪。
静态计算图
有了所有这种渴望模式的成功的喜悦,你可能想知道静态图形执行是否可以。当然!此外,我们还需要多一行代码来启用它!
有一点需要注意,在静态图形执行期间,我们不能只有Tensors,这就是为什么我们在模型定义期间需要使用CategoricalDistribution的技巧。事实上,当我在寻找一种在静态模式下执行的方法时,我发现了一个关于通过Keras API构建的模型的一个有趣的低级细节。
还有一件事…
还记得我说过TensorFlow默认是运行在eager模式下吧,甚至用代码片段证明它吗?好吧,我错了。
如果你使用Keras API来构建和管理模型,那么它将尝试将它们编译为静态图形。所以你最终得到的是静态计算图的性能,具有渴望执行的灵活性。
你可以通过model.run_eagerly标志检查模型的状态,你也可以通过设置此标志来强制执行eager模式变成True,尽管大多数情况下你可能不需要这样做。但如果Keras检测到没有办法绕过eager模式,它将自动退出。
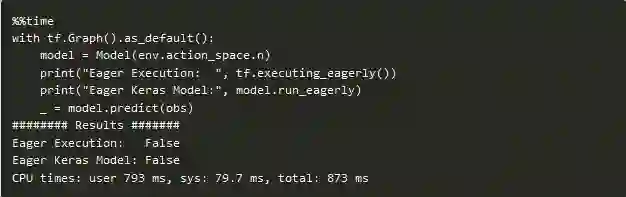
为了说明它确实是作为静态图运行,这里是一个简单的基准测试:

Eager基准

静态基准
默认基准
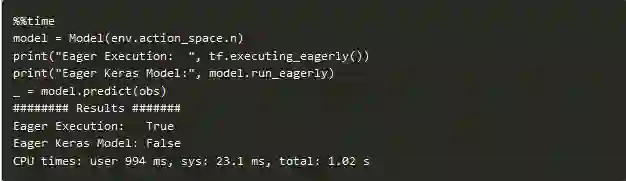
正如你所看到的,eager模式是静态模式的背后,默认情况下,我们的模型确实是静态执行的。
结论
希望本文能够帮助你理解DRL和TensorFlow2.0。请注意,TensorFlow2.0仍然只是预览版本,甚至不是候选版本,一切都可能发生变化。如果TensorFlow有什么东西你特别不喜欢,让它的开发者知道!
人们可能会有一个挥之不去的问题:TensorFlow比PyTorch好吗?也许,也许不是。它们两个都是伟大的库,所以很难说这样谁好,谁不好。如果你熟悉PyTorch,你可能已经注意到TensorFlow 2.0不仅赶上了它,而且还避免了一些PyTorch API的缺陷。
在任何一种情况下,对于开发者来说,这场竞争都已经为双方带来了积极的结果,我很期待看到未来的框架将会变成什么样。
本文由阿里云云栖社区组织翻译。
文章原标题《Deep Reinforcement Learning with TensorFlow 2.0》
译者:乌拉乌拉,审校:袁虎。

end
终于等到你!阿里正式向 Apache Flink 贡献 Blink 源码
15分钟在笔记本上搭建 Kubernetes + Istio开发环境
更多精彩





