DiffRec: 扩散推荐模型(SIGIR'23)
TLDR: 本文将扩散模型应用于推荐系统中,提出了一种新颖的扩散推荐模型 DiffRec 以实现个性化推荐,并提出两个变体 L-DiffRec 与 T-DiffRec将其推广至大规模推荐场景与时序信息建模中,三个数据集上的实验结果验证了该方法的优越性。

论文:Diffusion Recommender Model (SIGIR'23)
代码:https://github.com/YiyanXu/DiffRec
摘要
生成式推荐模型,如生成对抗网络(GANs)和 变分自编码器(VAEs),被广泛应用于建模用户交互的生成过程。然而,这些生成式模型都存在固有的局限性,如GANs 的训练过程不稳定,VAEs 的表达能力受限等问题,这导致模型难以对复杂的用户交互(各种干扰因素导致交互含有噪声)进行精确的建模。鉴于扩散模型(Diffusion Model, DMs)在图像生成方面相比于传统生成模型的显著优势,我们提出了扩散推荐模型(Diffusion Recommender Model, DiffRec),以去噪的方式学习用户交互的生成过程。为了保留用户交互历史中的个性化信息,DiffRec 减少了扩散过程中添加的噪声,并且避免像图像合成领域一样,将用户交互破坏为纯噪声。此外,为了应对推荐系统的实际应用场景所面临的挑战:大规模物品预测将消耗大量计算资源,以及用户偏好会随时间变化,我们提出 DiffRec 的两个变体。L-DiffRec 对物品聚类并进行维度压缩,在隐空间中进行扩散过程;T-DiffRec 根据交互时间先后对用户的交互赋予不同的权重以编码时序信息。我们在三个数据集上进行了广泛的实验,实验结果和进一步的分析验证了 DiffRec 及其两个变体的优越性。
研究动机
生成式推荐模型(GANs, VAEs)通常假设用户与物品间的交互行为(例如,点击)是由某些潜在因素(例如,用户偏好)决定的,而这与真实世界中交互的生成过程一致,该类模型因此取得了显著的成功。当前的生成式推荐主要分为两类:
- 基于 GAN 的模型采用生成器估计用户的交互概率,并利用对抗训练优化模型参数,但对抗训练通常不稳定,导致模型难以获得令人满意的性能;
- 基于 VAE 的模型使用编码器来近似潜在因素的后验分布,并最大化被观测交互的似然函数,如图 1(a) 所示。在推荐领域中,尽管 VAEs 的性能往往优于 GANs,但该类模型需要在后验分布的可解性与模型的表示能力间进行权衡。
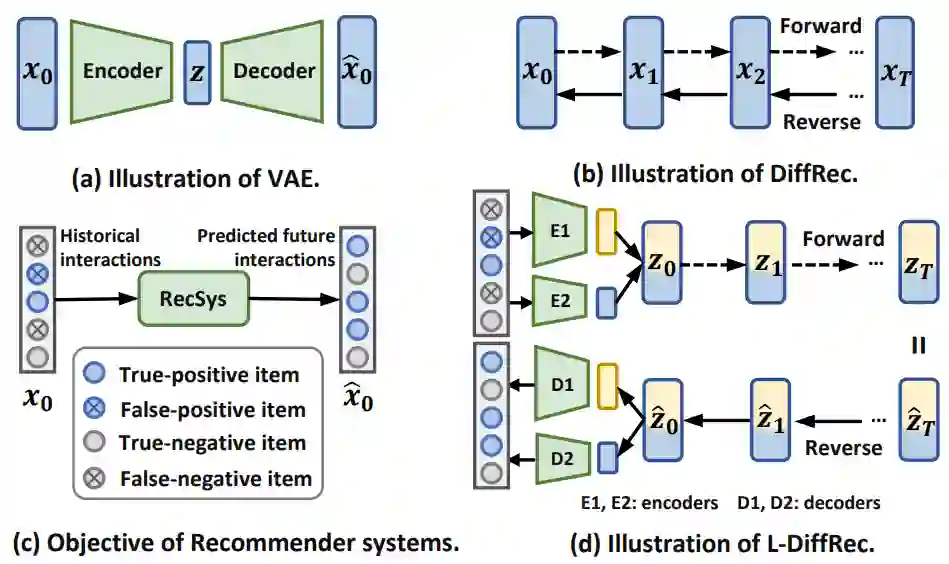
扩散模型,如图 1(b) 所示,在前向过程中通过逐步添加高斯噪声以破坏图像信息,反向过程中逐步去噪以重构信息;该前向过程满足后验分布的可解性,同时也使得利用神经网络逐步建模复杂分布成为可能,这缓解了 VAEs 所面临的问题。同时,推荐系统的目标与扩散模型是相吻合的,这是因为推荐系统本质上是基于带噪声的历史交互(比如错误的负样本和错误的正样本)来推断未来的交互概率,如图 1(c) 所示。因此,扩散模型在推荐领域有着巨大的潜力,能够利用其强大的表示能力更准确地建模复杂的交互生成过程。
模型介绍
DiffRec

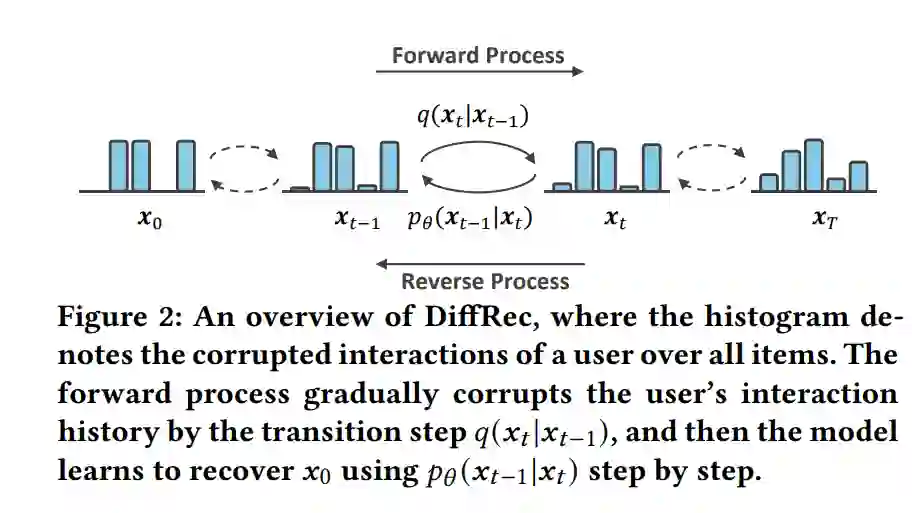
如图 2 所示,DiffRec 主要由两部分组成:对于给定的用户历史交互,(1) 前向过程加入高斯噪声逐步破坏交互信息;(2) 反向过程中模型逐步去噪并恢复原始信息。通过逐步学习上述的去噪过程,DiffRec 能够模拟复杂的交互生成过程,同时减轻真实世界中的噪声所带来的影响。DiffRec 训练与推断伪代码见图 4。
此外,与图像生成任务不同,为保证用户的个性化信息,我们在训练时并没有将用户交互破坏为纯噪声,并且在训练和推断时均减少了前向过程中添加的噪声,这类似于 MultiVAE [1] 中利用 $\beta$ 来控制先验约束的强度。

L-DiffRec
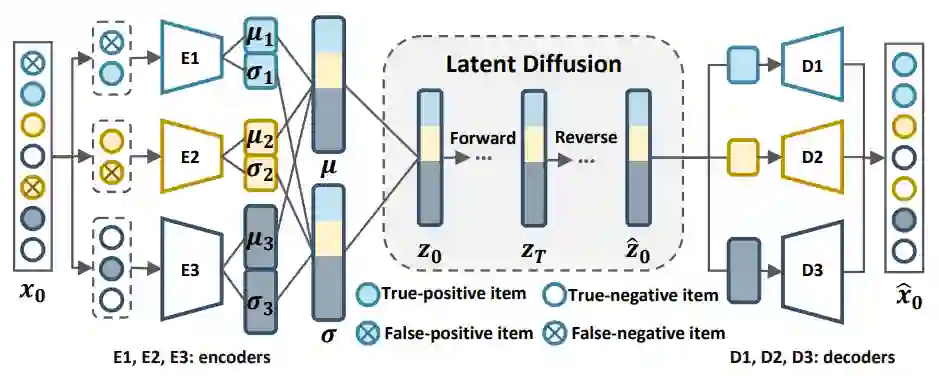
生成式模型通常需要同时预测用户与所有物品的交互概率,该过程对计算资源的大量消耗限制了模型在工业界中的应用。为降低计算成本,我们基于 DiffRec 提出其变体 L-DiffRec。如图 5 所示,L-DiffRec 首先基于物品表示(LightGCN 训练所得)采用 k-means 对物品进行聚类,根据聚类结果将交互历史进行相应划分,进一步通过多个编码器对每类交互进行维度压缩,随后在隐空间中进行扩散模型的前向与反向过程,再通过多个解码器映射回真实维度进行排序与推荐。
T-DiffRec
由于用户的喜好可能随着时间发生变化,故向推荐模型中引入时序信息是非常重要的。我们认为用户最近交互的物品更能反应用户当前的喜好,故依据交互时间先后赋予交互不同的权重以编码时序信息。该策略可应用于 DiffRec 和 L-DiffRec 分别得到 T-DiffRec 和 LT-DiffRec。
实验分析
我们在三个公开数据集(Amazon-book, Yelp, ML-1M)上基于不同设定进行实验以验证 DiffRec 的优越性。
DiffRec
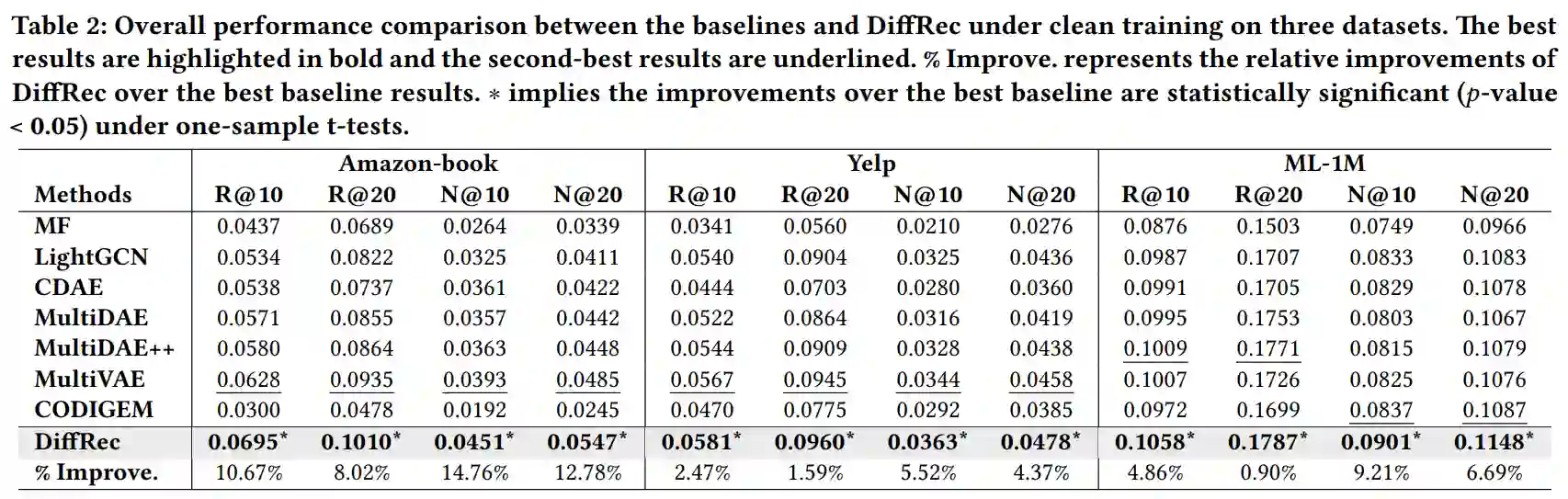
实验结果表明多数生成式模型能够取得比 MF 和 LightGCN 更好的性能,且 DiffRec 在三个数据集上均能取得优于其他基线模型的性能。此外,我们在基础实验之上对 DiffRec 进行进一步分析,实验结果验证了前述关于个性化推荐与模型预测目标的猜想。
L-DiffRec
为验证 L-DiffRec 在推荐性能与节约计算资源上的效果,我们选取主实验中性能最好的 MultiVAE 进行对比,实验结果表明,L-DiffRec 能够取得与 DiffRec 相当的性能,而其所需的计算资源大大减少。

T-DiffRec
我们将 T-DiffRec 和 LT-DiffRec 与当前 SOTA 的序列推荐模型 ACVAE [2] 相比较,实验结果表明 T-DiffRec 能够有效建模时序信息,尽管其模型参数相对较多,但显存消耗远少于 ACVAE。

总结
本工作中,我们基于扩散模型提出一种新型的生成式推荐范式——扩散推荐模型(DiffRec),并针对推荐系统在实际应用场景中所面临的挑战提出基于 DiffRec 的两种变体:L-DiffRec 和 T-DiffRec,并在三个数据集上的实验结果验证了 DiffRec 及其变体的优越性。本工作为生成式推荐开辟了一个新的研究方向,在此基础上还有许多值得探索的内容:(1) 为 L-DiffRec 和 T-DiffRec 设计更好的维度压缩和时序信息建模策略;(2) 基于 DiffRec 探索可控推荐;(3) 尝试更多的先验假设(例如,除高斯分布外的其它噪声分布假设)以及不同的模型结构。
参考文献
[1] Xiaopeng Li and James She. 2017. Collaborative variational autoencoder for recommender systems. In KDD. ACM, 305–314
[2] Zhe Xie, Chengxuan Liu, Yichi Zhang, Hongtao Lu, Dong Wang, and Yue Ding. 2021. Adversarial and contrastive variational autoencoder for sequential recommendation. In WWW. ACM, 449–459.