
基于知识增强采样的对话推荐系统
Knowledge Graph-enhanced Sampling for Conversational Recommendation System
作者:赵梦媛,黄晓雯*,朱立玺,桑基韬,于剑 单位:
北京交通大学 计算机与信息技术学院, 北京交通大学 人工智能研究院, 北京交通大学 交通数据分析与挖掘北京市重点实验室 邮箱:
example.zmy@qq.com, xwhuang@bjtu.edu.cn, zlxxlz1026@gmail.com, jtsang@bjtu.edu.cn, jianyu@bjtu.edu.cn
*通讯作者
01
内容****简介
传统的推荐系统主要利用离线用户数据来训练离线模型,然后向在线用户推荐物品,因此,其天然存在基于稀疏且有噪声的历史数据的用户偏好不可靠估计问题。对话推荐系统(CRS)利用对话系统的交互形式来解决传统推荐系统固有的问题。然而,由于缺乏上下文信息建模,现有的CRS模型无法很好地处理E&E问题,给用户带来了沉重的负担。为了解决上述问题,本文提出了一种为CRS定制的上下文信息增强模型,称为KGenSam。KGenSam将用户交互数据与外部物品属性知识图融合异构图谱,作为上下文交互环境。然后,设计了两个采样器去增强环境知识,主动采样器(active sampler)通过采样高信息量的fuzzy sample来获取用户偏好,负采样器(negative sampler)通过采样高质量的负样本来更新推荐器,二者相辅相成实现用户偏好的高效获取和模型的高效更新,为CRS处理E&E问题提供了强有力的解决方案。在两个真实数据集上的实验结果证明了KGenSam的优越性,与sota方法相比有了显著的改进。 02
内容背景
1.1 CRS
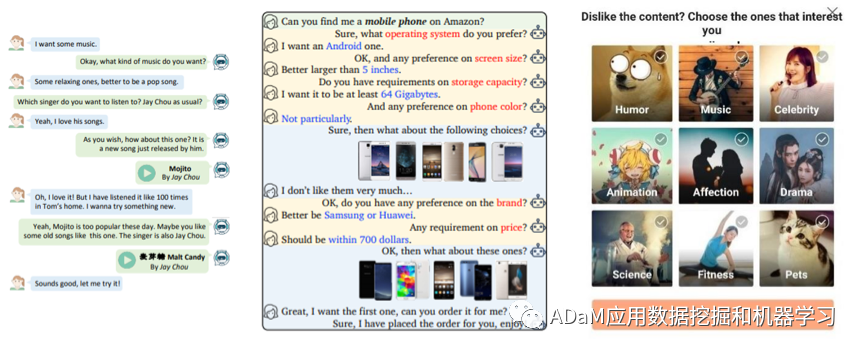
传统推荐系统通常使用用户的离线历史数据来了解用户的偏好,并被动地向在线用户推荐物品。这种离线更新模式缺乏探索数据的主动性,使得推荐系统具有固有的弱点:无法适应用户的在线行为,并且依赖用户对物品和物品属性的先验知识。因此,传统推荐系统很难了解并引导用户当前的意图和兴趣。 对话系统中对话技术的发展为解决传统推荐系统中存在的问题提供了一种新的解决方案,即对话推荐。对话推荐通过丰富的交互行为打破了静态推荐系统中系统与用户之间信息不对称的障碍,允许推荐系统在与用户的交互对话中动态捕获用户偏好。CRS基于对话推荐的思想,是一个面向任务的多轮推荐系统,一方面探索用户当前的兴趣偏好,引导用户发现新的兴趣点,实现用户的长期保留;另一方面,它还可以接收用户的反馈并实时更新推荐人,实现偏好的动态学习。
CRS的核心研究难点是E&E问题。具体而言,在对话会话的每一轮中,CRS可以选择利用在先前交互期间获得的用户偏好信息来输出当前最佳推荐物品,即exploitation;或者选择继续与用户交互以获取更多实时用户偏好信息,即exploration。解决CRS 的E&E问题的难点在于在推荐系统领域实现特殊的纳什均衡:如果CRS过于倾向于在不了解当前用户偏好的情况下选择exploitation行为(推荐),会有很多失败的推荐,这会损害用户体验;如果CRS采取过度的exploitation行动(询问),用户的交互负担将增加,用户流失的风险将变大。目前,CRS研究者大多使用深度强化学习(DRL)来学习会话推荐策略来解决E&E问题。因为DRL具有顺序决策的能力,这自然符合CRS的交互形式。
1.2 基本CRS任务

如图所示,用户是CRS的交互对象,CRS主要由推荐模块和交互策略模块组成:推荐模块负责根据用户偏好信息生成推荐列表;交互策略模块负责决定是向用户询问更多偏好信息,还是在当前会话回合中输出推荐物品。
流程:
(1) 当用户进入系统时,对话推荐会话开始。 (2) CRS根据当前用户偏好的当前理解选择“ask”动作或“recommend”动作操作。如果选择了recommend,系统将向用户输出推荐器排名靠前的推荐物品,如果选择了ask,系统将向用户输出交互策略网络选择询问的物品属性。 (3) 然后,返回到用户端,用户对推荐的物品或被询问的物品属性给出二极反馈(接受或拒绝)。 (4) 当获得一次成功的推荐或达到设定的最大交互轮次时,整个会话结束。
03
存在问题
从之前工作的实验结果来看,基于DRL的CRS比其他方法取得了更好的结果,目前sota的CRS方法都是基于DRL。然而,标准的DRL模型不能满足CRS的需求,研究人员面临着CRS训练的收敛困难和CRS交互的低效性问题。这些问题的主要原因是CRS中的上下文环境缺乏明确的规则,这导致DRL模型中缺乏明确的奖励功能和明确的行动空间。这可以概括为环境信息建模不足的问题,这会延迟训练交互中参数的更新,因此CRS需要更多的交互轮次来获取用户偏好信息并实现成功的推荐。
本文认为,充分的环境信息建模是解决E&E环境问题的关键。因此,我们的目标是建立一个CRS,在每一轮会话建议中都能很好地利用上下文环境的信息。我们从数据增强的角度出发,提出了一种新的解决方案——知识增强采样(KGenSam),解决了CRS中信息建模不足的问题。我们将知识图谱(KG)作为其交互环境引入到基本CRS框架中,并设计了两个采样器模块来建模和增强KG环境的信息,CRS将根据增强的环境知识学习做出更优解的E&E决策。

两个采样器的设计灵感来自于解决以下两个具体问题,这两个问题阻碍了CRS做出E&E的最佳决策:
(1)CRS应该询问哪些属性来有效地获取当前用户的偏好?
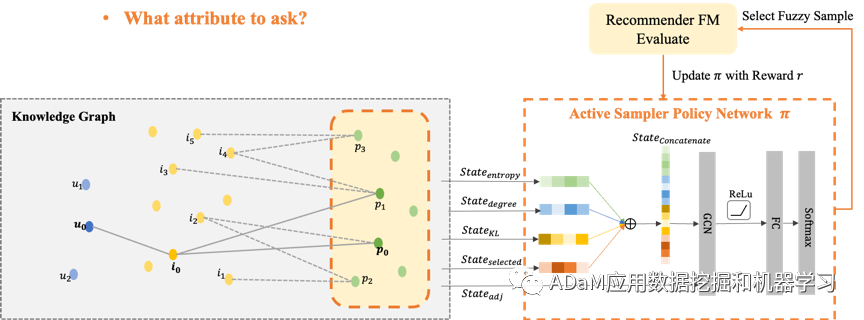
我们相信,CRS的每个询问机会都是极其宝贵的,CRS需要在每个ask机会中获得尽可能多的用户偏好信息。在这项工作的设计中,我们自然借鉴了主动学习的核心思想,即当CRS选择ask时,需要优先关注当前模型无法判断的高不确定性属性候选。因为这些具有高度不确定性的属性样本在被用户“标注”后将极大地提高模型的置信度,从而实现以尽可能少的用户交互负担获得足够的用户偏好。 因此,为了筛选出具有高度不确定性的fuzzy sample,我们设计了一种主动采样器,它以KG中的样本分布状态和会话状态作为输入,通过主动强化学习来学习fuzzy sample的特征。
(2)CRS如何高效地更新推荐器以适应用户反馈中隐含的偏好信息?
为了训练推荐器,需要用户反馈的正负样本。CRS的用户交互形式自然地解决了传统推荐中的one class问题,即大多数用户数据都是正样本。CRS最大的优点之一是,除了正反馈之外,它还可以在交互过程中从用户那里获得明确的负反馈,但它也带来了新的研究挑战。对话次数通常限制在十几次以上,这导致对话推荐会话中的用户反馈数据量也非常有限。由于稀疏的用户反馈和巨大的候选项空间,推荐器需要大量的训练数据来训练。受传统推荐系统中通过负采样解决one class问题的思想启发,我们尝试通过增强KG中的正负样本对来补充稀疏交互数据,基于hard negative sample mining方法设计了一种负样本采样器,以KG中的样本分布状态和对话状态作为输入,通过强化学习学习hard negative sample的特征,并与真实的正样本构建增强的正负样本对,用以高效更新推荐器。
04
主要贡献
这项工作的主要贡献如下: (1)我们提出了KGenSam模型,为CRS的构建提供了一个新的知识增强角度。KGenSam通过以KG为单位进行抽样,增强了CRS的上下文知识,解决了因CRS信息建模不足而导致的E &E问题。据我们所知,这是首次将知识增强采样方法引入CRS中。
(2)我们将主动学习和强负样本挖掘方法引入到CRS中。通过在CRS任务中加入模糊样本和强负样本,挖掘KG环境中的用户偏好信息,解决用户反馈的数据稀疏问题。
(3)在两个基准数据集上进行实验,证明基于KGenSam的CRS能够以更少的会话次数实现sota性能,表明采样的有效。并实现了一个在线CRS,以验证我们的方法在与用户的实际交互中的有效性。
05
方法
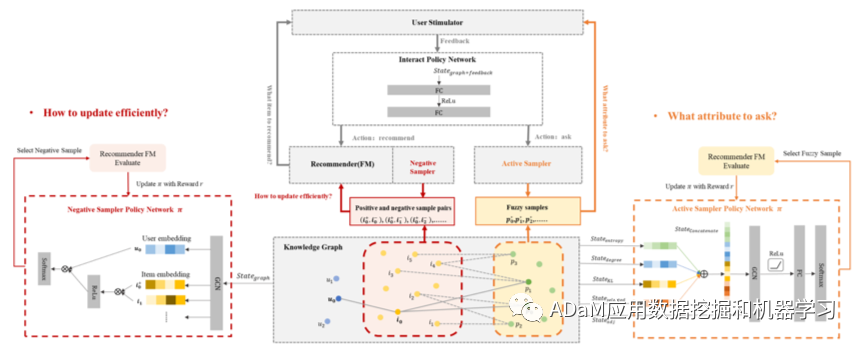
关键设计是两个采样器模块: (1) 负面采样器输出高质量的负面物品样本,并构建正负样本对,以便在每轮对话中对推荐器进行高效更新; (2) 主动采样器输出具有高度不确定性的模糊物品属性样本,作为CRS采取ask时要询问的用户偏好信息。
5.1 负采样器
**原理:**主动学习(尽可能少的样本标注实现最大的模型性能提升) **目标:**减少交互轮次,减轻用户负担
基于图谱的主动强化学习:
图谱环境信息作为状态

推荐器性能的提升作为环境奖励
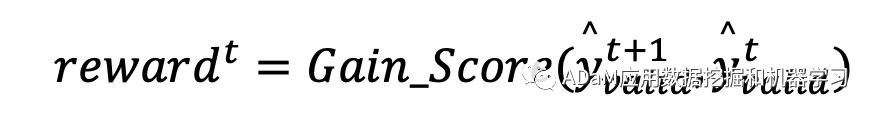
优化累计奖励,学习主动采样策略π
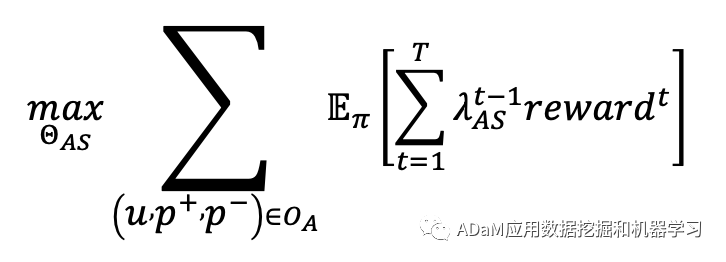
算法流程:

5.2 主动采样器
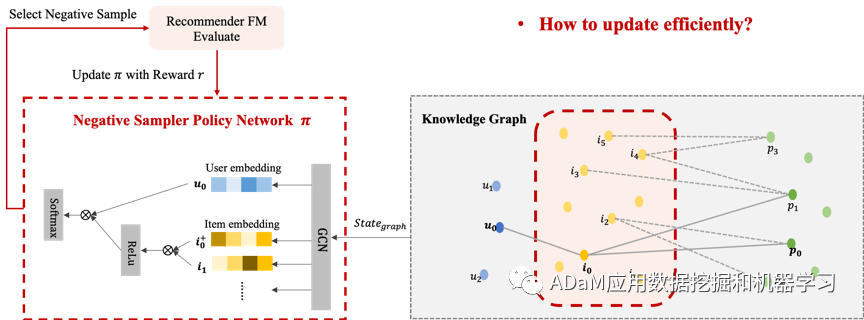
**原理:**强负样本采样(越难分辨的负样本质量越高) **目标:**高效更新推荐器,提高推荐成功率 基于图谱的强化负采样:
图谱环境信息作为状态
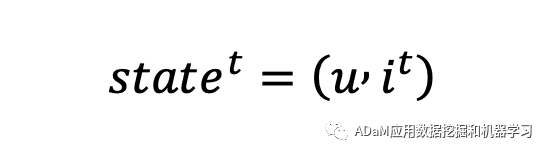
节点与用户和正样本的相似度,作为环境奖励 a) 与用户相似保证真实性
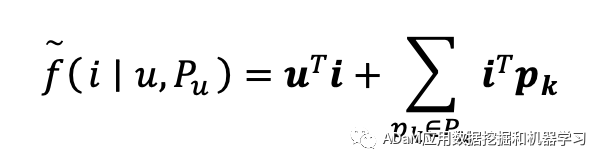
b) 与正样本相似保证高信息量
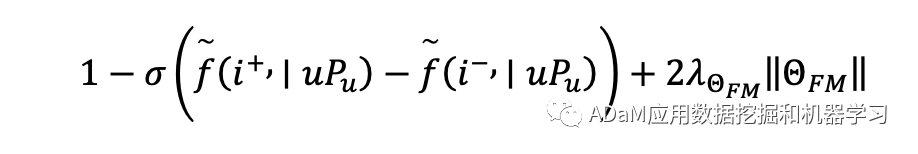
因此, rewardt=(it)T·u+(it)T·i+ * 优化累计奖励,学习负采样策略π

算法流程:

5.3 整体交互策略学习
算法流程:

06
实验结果
(1)对比实验
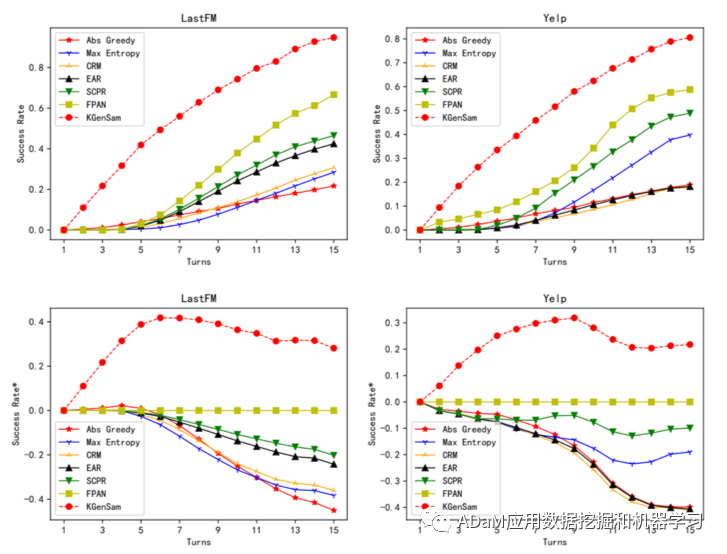
更少的交互轮次,更高的推荐成功率。 (2)消融实验
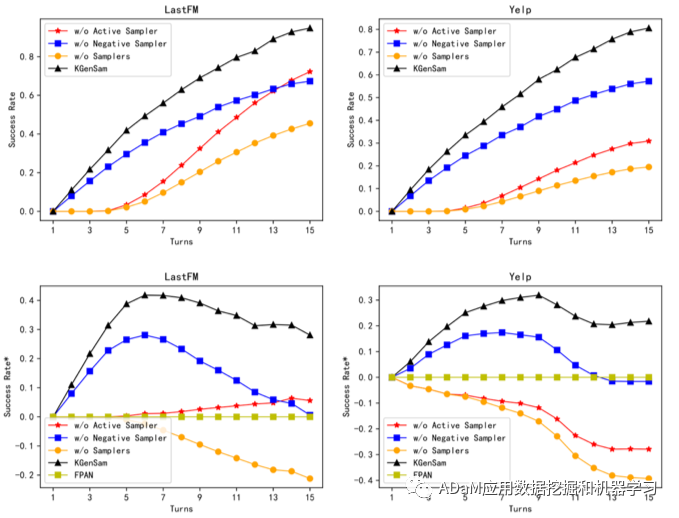
通过指标曲线的形状变化,说明模型主动性更强;通过曲线整体上升,说明模型学习速度更快。 (3)Case study
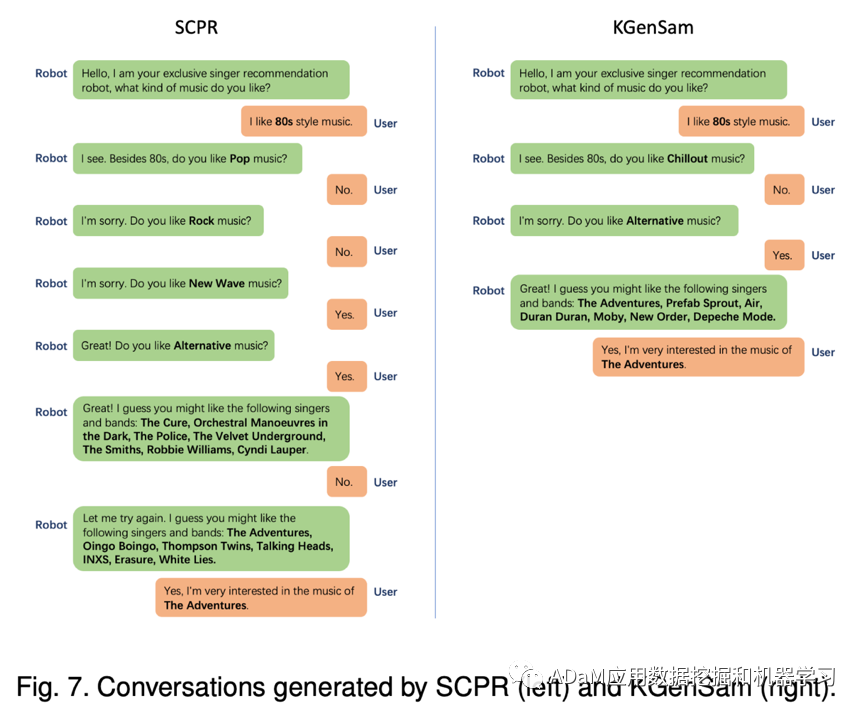
图中展示了两个在LastFM上的真实案例。对于一个喜欢上世纪80年代歌曲的用户来说,SCPR首先询问了常见的“流行”和“摇滚”两个音乐属性,在被拒绝后,SCPR开始询问相对小众音乐属性,“新浪潮”和“另类”,并在一次推荐失败后,SCPR最终才获得了一次成功的推荐。而在我们基于环境知识增强的对话推荐模型的案例中,根据用户提供的喜欢“80年代”的音乐偏好信息,我们的模型探索性地询问了与“80年代”更相关的小众音乐属性,即“放松”和“另类”,在仅仅询问了两次后就成功推荐了用户喜欢的音乐人。 我们的模型可以更有效地建模环境信息,并通过更少的失败推荐和更少的询问机会实现一次成功的推荐。在实际应用场景中,基于环境知识增强的对话推荐系统是具有更好用户体验的高效对话推荐系统。
文案:赵梦媛
排版、校对、审核:赵宪
责任编辑:桑基韬
