SIGIR2022 | 从Prompt的角度考量强化学习推荐系统
转自:社媒派 SMP
责任编辑:李晨亮
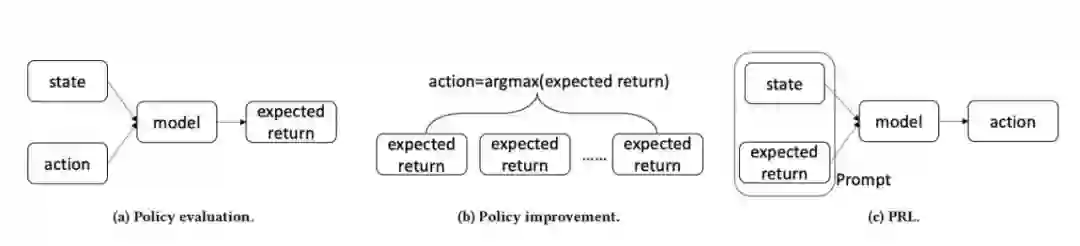
● 对于基于强化学习的Next item推荐系统的离线训练,我们提出了PRL。我们建议使用“状态-奖励”对作为提示,通过查询历史隐式反馈数据知识库来推断行为。
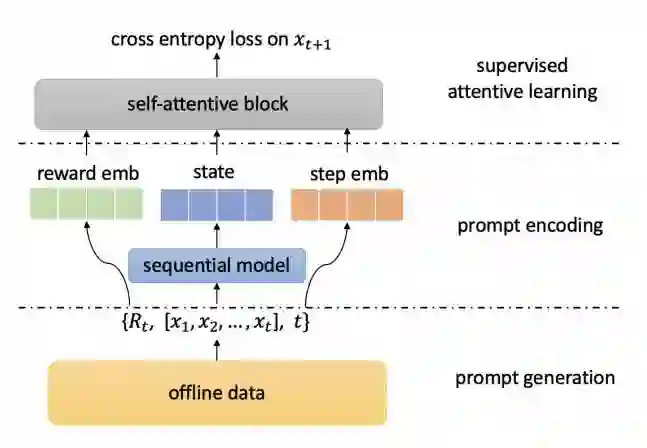
● 我们提出使用一个有监督的自注意力模块来学习和存储“状态-奖励”对的输入和行为的输出之间的信号。
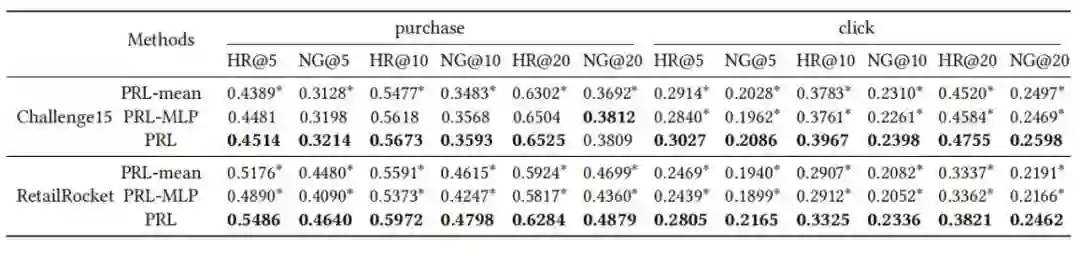
● 我们在四种推荐模型上实例化PRL,并在两个真实世界的电子商务数据集上进行了实验。实验结果表明,推荐性能有了普遍的提高。



基于提示的强化学习(Prompt-Based Reinforcement Learning)

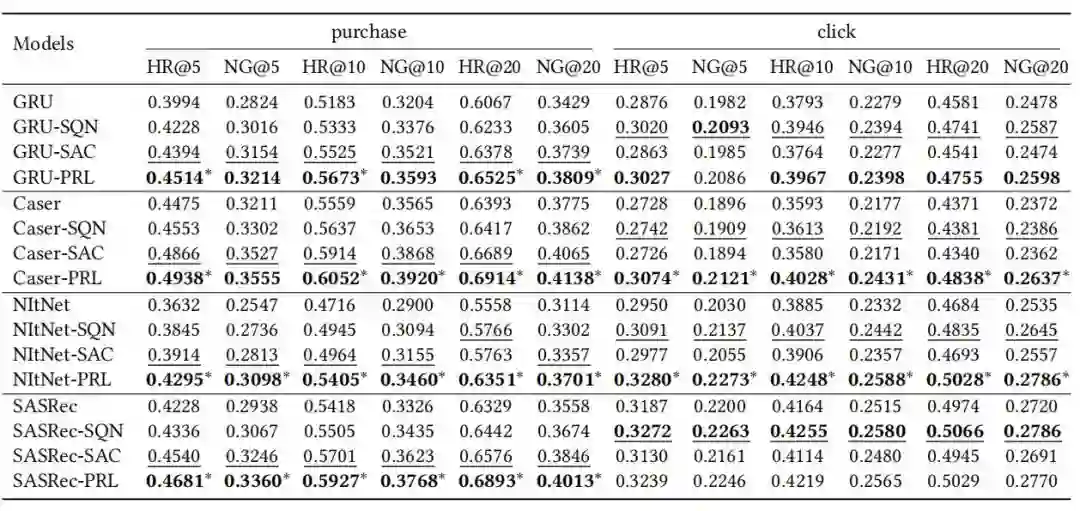
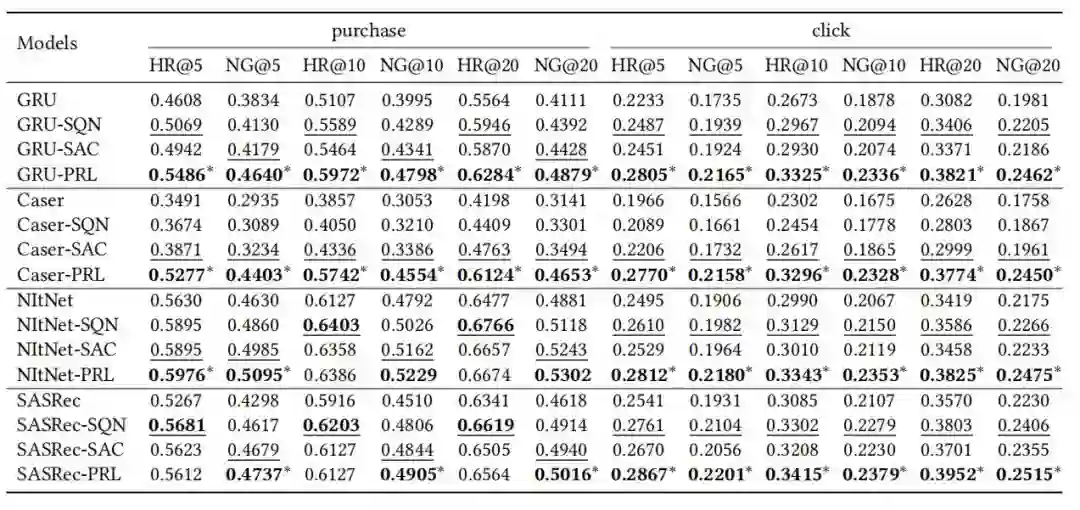
实验
● 当在不同的序列推荐模型上实例化时,PRL的表现如何?
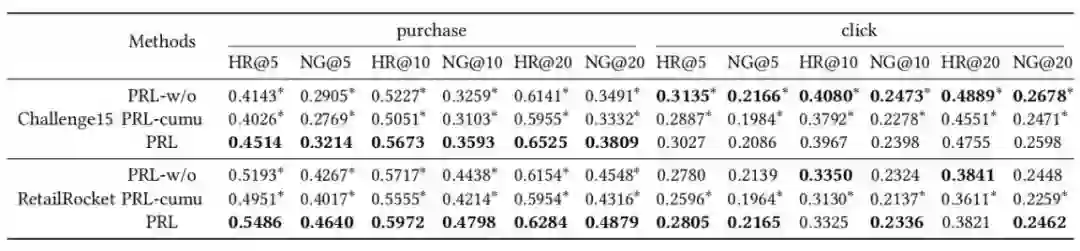
● 包括自注意力模块和加权损失函数在内,监督注意力学习的效果是什么?
● 在推理阶段,prompt reward设置如何影响PRL的表现?
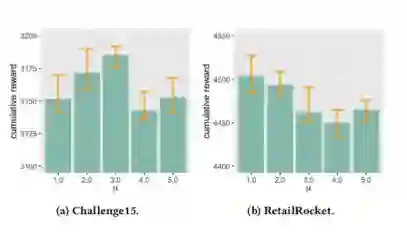
(图4 推理奖励期望μ的效果)
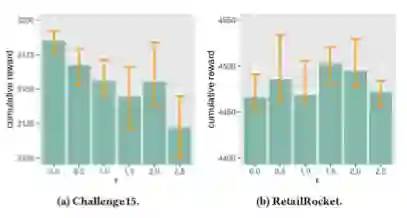
(图5 推理奖励偏差ϵ的效果)
总结
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
登录查看更多
相关内容
Arxiv
20+阅读 · 2020年3月10日


相关VIP内容
相关资讯
相关论文
Arxiv
20+阅读 · 2020年3月10日