
推理是人类智能的一个基本方面,在解决问题、决策和批判性思考等活动中起着至关重要的作用。近年来,大型语言模型(LLMs)在自然语言处理方面取得了重大进展,有人观察到这些模型在足够大的时候可能会表现出推理能力。然而,目前还不清楚LLMs的推理能力到何种程度。

本文对LLM推理的知识现状进行了全面的概述,包括改进和诱导这些模型推理的技术、评估推理能力的方法和基准、该领域以前研究的发现和影响,以及对未来方向的建议。我们的目标是对这一主题提供详细和最新的回顾,并激发有意义的讨论和未来的工作。
https://www.zhuanzhi.ai/paper/10caab0b58fcf5f8ddf7943e1a6060d5
1. 引言
推理是一种认知过程,包括使用证据、论据和逻辑来得出结论或做出判断。它在许多智力活动中起着核心作用,如解决问题、决策和批判性思考。对推理的研究在心理学(Wason and Johnson-Laird, 1972)、哲学(Passmore, 1961)和计算机科学(Huth and Ryan, 2004)等领域很重要,因为它可以帮助个人做出决定、解决问题和批判性地思考。
**最近,大型语言模型(LLMs) (Brown et al., 2020; Chowdhery et al., 2022; Chung et al., 2022; Shoeybi et al., 2019, inter alia)在自然语言处理及相关领域取得了重大进展。**研究表明,当这些模型足够大时,它们会表现出紧急行为,包括"推理"的能力(Wei等人,2022a)。例如,通过为模型提供"思维链",即推理范例,或简单的提示" Let 's think step by step ",这些模型能够以明确的推理步骤回答问题(Wei et al., 2022b;Kojima et al., 2022),例如,“所有鲸鱼都是哺乳动物,所有哺乳动物都有肾脏;因此,所有的鲸鱼都有肾脏。”这引发了社区的极大兴趣,因为推理能力是人类智能的一个标志,而在当前的人工智能系统中,推理能力经常被认为是缺失的(Marcus, 2020; Russin et al., 2020; Mitchell, 2021; Bommasani et al., 2021)。
然而,尽管LLM在某些推理任务上表现强劲,但目前尚不清楚LLM是否真的在推理,以及它们在多大程度上能够推理。例如,Kojima等人(2022)声称“LLMs是不错的零次推理器(第1页)”,而Valmeekam等人(2022)得出结论,“LLMs在对人类来说没有问题的常见规划/推理任务上仍然远远没有达到可接受的性能(第2页)。”Wei等人(2022b)也指出了这一局限性:“我们认为,尽管思维链模拟了人类推理的思维过程,但这并没有回答神经网络是否实际上是推理(第9页)。
本文旨在对这一快速发展的主题的知识现状进行全面概述。专注于改善LLM中推理的技术(§3);LLMs中衡量推理的方法和基准(§4);这一领域的发现和意义(§5);以及对该领域现状的反思和讨论(§6)。
2. 什么是推理?
推理是用逻辑和系统的方式思考某事的过程,利用证据和过去的经验来得出结论或做出决定(Wason and Johnson-Laird, 1972; Wason, 1968; Galotti, 1989; Fagin et al., 2004; McHugh and Way, 2018)。推理包括根据现有信息进行推理、评估论点和得出逻辑结论。“推理”虽然是文学和日常生活中常用的术语,但它也是一个抽象的概念,可以指代很多事物。为了帮助读者更好地理解这个概念,我们总结了几种常见的推理类型:
演绎推理。演绎推理是一种基于前提的真实性而得出结论的推理。在演绎推理中,结论必须从前提中得出,这意味着如果前提为真,结论也必须为真。前提:所有哺乳动物都有肾脏。前提:所有鲸鱼都是哺乳动物。结论:所有鲸鱼都有肾脏。
归纳推理。归纳推理是一种基于观察或证据得出结论的推理。根据现有的证据,这个结论很可能是正确的,但不一定是肯定的。观察:我们每次看到有翅膀的生物,它就是鸟。观察:我们看到一个有翅膀的生物。结论:这个生物很可能是一只鸟。
溯因推理。溯因推理是一种推理,它是在对一组给定的观察做出最佳解释的基础上得出结论的。根据现有的证据,这一结论是最可能的解释,但不一定是肯定的。观察:汽车无法启动,引擎下有一滩液体。结论: 最可能的解释是汽车的散热器有一个泄漏
3. 大语言模型中的推理
推理,尤其是多步推理,通常被视为语言模型和其他NLP模型的弱点(Bommasani et al., 2021; Rae et al., 2021; Valmeekam et al., 2022)。最近的研究表明,在一定规模的语言模型中可能会出现推理能力,例如具有超过1000亿个参数的模型(Wei et al., 2022a,b;Cobbe等人,2021)。在本文中,我们遵循Wei等人(2022a)的观点,将推理视为一种在小规模模型中很少出现的能力,因此关注于适用于改进或引出大规模模型中的“推理”的技术。
3.1 全监督微调
在讨论大型语言模型中的推理之前,值得一提的是,有研究正在通过对特定数据集的全监督微调来激发/改进小型语言模型中的推理。例如,Rajani等人(2019)对预训练的GPT模型进行微调(Radford等人,2018),以生成用构建的CoS-E数据集解释模型预测的理由,并发现经过解释训练的模型在常识性问答任务上表现更好(Talmor等人,2019)。Talmor等人(2020)训练RoBERTa (Liu等人,2019)基于隐式预训练知识和显式自由文本语句进行推理/推理。Hendrycks等人(2021)对预训练语言模型进行微调,通过生成完整的分步解决方案来解决竞赛数学问题,尽管准确性相对较低。Nye等人(2021)在产生最终答案之前,通过生成" scratchpad ",即中间计算,训练语言模型进行程序合成/执行的多步骤推理。全监督微调有两个主要限制。首先,它需要一个包含显式推理的数据集,这可能很难和耗时创建。此外,模型仅在特定数据集上进行训练,这将限制其应用于特定领域,并可能导致模型依赖于训练数据中的工件而不是实际推理来进行预测。
3.2 提示与上下文学习
大型语言模型,如GPT-3 (Brown et al., 2020)和PaLM (Chowdhery et al., 2022),通过上下文学习在各种任务中表现出显著的少样本性能。这些模型可以通过一个问题和一些输入、输出的范例来提示,以潜在地通过“推理”(隐式或显式)解决问题。然而,研究表明,这些模型在需要多个步骤推理来解决的任务方面仍然不理想(Bommasani et al., 2021; Rae et al., 2021; Valmeekam et al., 2022)。这可能是由于缺乏对这些模型的全部能力的探索,正如最近的研究所表明的那样。
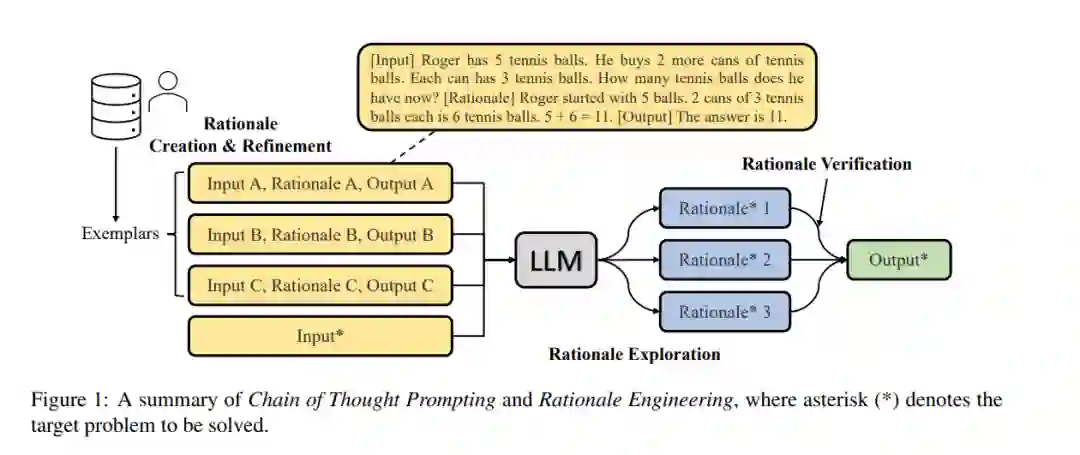
3.3 混合法
虽然"提示"技术可以帮助引出或更好地利用大型语言模型中的推理来解决推理任务,但它们实际上并没有提高LLM本身的推理能力,因为模型的参数保持不变。相比之下,“混合方法”旨在同时提高LLM的推理能力,并更好地利用这些模型来解决复杂问题。这种方法既包括增强LLM的推理能力,也包括使用提示等技术来有效利用这些能力。
4 度量大型语言模型的推理能力
文献中一直关注使用推理任务的下游性能作为模型"推理"能力的主要衡量标准。然而,直接分析这些模型产生的原理的工作相对较少。本节总结了评估LLM推理能力的方法和基准。
4.1 下游任务性能
衡量LLM推理能力的一种方法是评估它们在需要推理的任务上的表现。有各种现有的基准可用于此目的,组织如下。
**数学推理。**算术推理是理解和应用数学概念和原理以解决涉及算术运算的问题的能力。这涉及到在解决数学问题时使用逻辑思维和数学原理来确定正确的行动方案。算术推理的代表性基准包括GSM8K (Cobbe et al., 2021), Math (Hendrycks et al., 2021), MathQA (Amini et al., 2019), SVAMP (Patel et al., 2021), ASDiv (Miao et al., 2020), AQuA (Ling et al., 2017), and MAWPS (Roy and Roth, 2015).。值得一提的是,Anil等人(2022)生成了奇偶校验数据集和布尔变量赋值数据集,用于分析LLMs的长度泛化能力(§3.3.1)。
**常识推理。**常识推理是利用日常知识和理解对新情况作出判断和预测。这是人类智能的一个基本方面,它使我们能够在环境中导航,理解他人,并在信息不完整的情况下做出决定。可用于测试llm常识推理能力的基准包括CSQA (Talmor et al., 2019), StrategyQA (Geva et al., 2021), and ARC (Clark et al., 2018)。我们建议读者参考Bhargava和Ng(2022)的调研,以了解该领域的更多工作。
**符号推理。**符号推理是一种根据形式规则对符号进行操作的推理形式。在符号推理中,我们使用抽象的符号来表示概念和关系,然后根据精确的规则对这些符号进行操作,从而得出结论或解决问题。
4.2 推理的形式化分析
尽管LLM在各种推理任务中表现出令人印象深刻的性能,但它们的预测在多大程度上是基于真正的推理还是简单的启发式,并不总是很清楚。这是因为大多数现有评估侧重于它们对下游任务的准确性,而不是直接评估它们的推理步骤。虽然对LLMs生成的原理进行了一些误差分析(Wei et al., 2022b; Kojima et al., 2022, inter alia),这种分析的深度往往有限。已经有一些努力来开发指标和基准,以便对LLM中的推理进行更正式的分析。Golovneva等人(2022)设计了ROSCOE,一套可解释的、详细的分步评估指标,涵盖了语义对齐、逻辑推理、语义相似度和语言一致性等多个角度。Saparov和他(2022)创建了一个名为PrOntoQA的合成数据集,该数据集是根据真实或虚构的本体生成的。数据集中的每个示例都有一个唯一的证明,可以转换为简单的句子,然后再转换回来,允许对每个推理步骤进行形式化分析。Han等人(2022)引入了一个名为FOLIO的数据集来测试LLM的一阶逻辑推理能力。FOLIO包含一阶逻辑推理问题,需要模型在给定一组前提的情况下确定结论的正确性。总之,大多数现有研究主要报告了模型在下游推理任务中的表现,没有详细检查产生的基础的质量。这留下了一个问题,即模型是否真的能够以类似于人类推理的方式进行推理,或者它们是否能够通过其他方法在任务上取得良好的性能。还需要进一步的研究来更正式地分析LLM的推理能力。

