编辑:袁榭
【新智元导读】最近,DeepMind的研究人员发表论文称,大型Transformer模型之所以处理自然语言的表现独佳,是由于人类语言的特殊统计学质性最适合。
众所周知,像GPT-3这种大模型,极为擅长写情诗、编故事,以及回答各种问题。
然而,同样的优异表现却很难在其他数据类型上重现。
为此,DeepMind在进行了一番研究之后发现:既有Transformer架构特征的贡献,自然语言本身特色的优势也不容忽视。
根据DeepMind的新研究论文「Transformer模型中数据分布属性驱动的小样本学习」,这可能是因为人类语言的特殊统计学质性,让神经网络模型可以容易地预测并处理自然语言数据中的意外变化。
论文地址:https://arxiv.org/abs/2205.05055
从统计学的角度来看,自然语言具有「非统一」的特质,比如有一词可以代表多种事物的「多义词」,和相同发音代表不同字眼的同音异义字现象。
例如前段时间将「淦」特意混同于「干」的网络中文语言现象,和「干」字本身的丰富意涵。
类似的语言性质在DeepMind新论文中有被关注到。
研究人员的思路是从探索类似GPT-3的大模型如何完成「小样本学习」开始,也就是厘清GPT们如何解决它们所面临的各种未被预训练过的任务。
例如,GPT-3可以回答有多个候选项的选择题,而不需要预先明确编程来回答这种形式的问题,只需由人类用户输入选择题和正确答案的配对例子来提示就行。
论文作者们称,这可以代表「基于Transformer的大型语言处理模型能够胜任小样本学习/上下文学习,而不需要被明确地为之预训练好。」
然后研究人员进一步诠释:「我们假设自然语言的特定分布属性,可能会是这种现象的诱因。」
研究人员推测,大型语言模型程序们的这种表现就像另一种机器学习模式,也就是元学习。
DeepMind近年来一直在探索的元学习程序,其功能是能够对跨越不同数据集的数据模式进行建模。这类程序经过训练,不是为单一的数据分布建模,而是为数据集的分布建模。
这里的关键是「不同数据集」的概念。按研究人员的猜测,自然语言的所有「非统一」性,如多义词和使用频率相对极低的词,这些奇怪特征-中的每一个都类似于独立的数据集分布。
论文地址:https://arxiv.org/abs/1605.06065
事实上,研究人员认为,自然语言就像是介于有规律的受监督训练数据、和有大量不同性质数据的元学习之间的东西。
在监督训练中,词汇等训练项目确实会重复出现,而且项目与标签的映射—如自然语言中的词义—在某种程度上是固定的。
同时,长尾分布确定了自然语言中存在许多罕见的词汇,它们在不同的语境窗口中有规律重复出现的频率很低,但在语境窗口中可能是出现多次突发的。
所以可以把自然语言中罕见词、同音词、同形词、多义词,看作是完全不固定的数据分布中,项目-标签映射的弱化版本。这些映射在每一个训练回合中都会发生变化,在少数的元学习训练中使用。
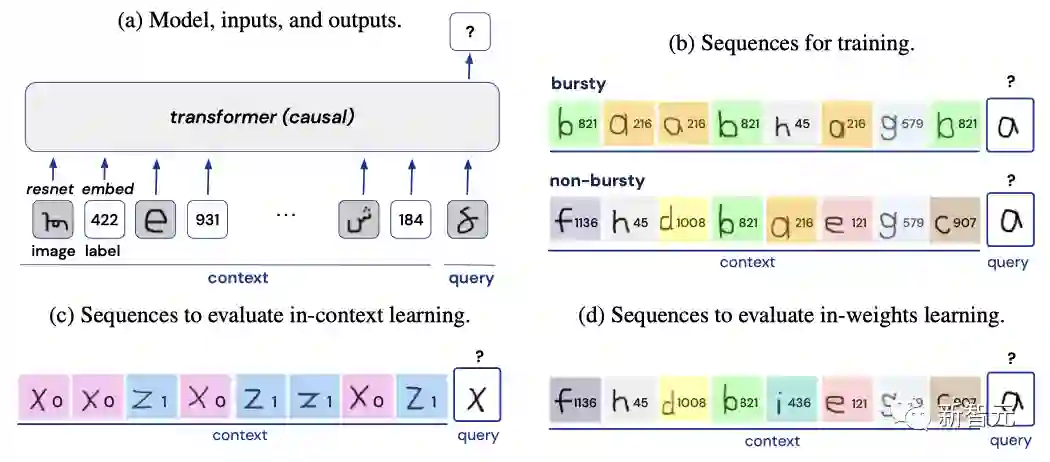
为了测试这一假设,研究人员采取了一种有创意的方法:他们并不从AI模型的语言任务训练开始。相反,他们训练一个Transformer神经网络来解决一个视觉任务。
Omniglot是一个为1623个手写字符字形分配正确的分类标签的挑战程序,由纽约大学、卡内基梅隆大学和麻省理工学院的学者于2016年推出。
在此次DeepMind的研究中,首先需要将手写字符的分类标签随机打乱,把Omniglot挑战改变为one-shot学习任务,这样神经网络就能在各个「情节」中进行学习。
研究人员表示,与标签在所有序列中都是固定的训练类型不同的是,这两个图像类别的标签在每个序列中都是随机重新分配的。
由于标签在每个序列中都是随机重新分配的,所以模型必须使用当前序列中的上下文,以便对所查询图像进行标签预测(一个双向的分类问题)。
除非另有说明,小样本学习总是在训练中从未出现过的保留图像类别上进行评估。
以这种方式,研究人员将字符这一视觉数据改变得体现出自然语言的非统一性。
结论:图形数据越像自然语言,Transformer学习力就越好
在模型训练中,研究人员将Omniglot图像和标签置于各种被自然语言启发的分布质性的序列中。
例如,研究人员逐渐增加可以分配给一个特定字符的类型标签的数量,以此使字符接近多义词的质性。
在评估模型学习结果时,研究人员再评估这些特性是否会能提高模型的小样本学习性能。
研究人员发现,随着他们将某一字符的标签数量成倍增加,神经网络在进行小样本学习时表现更好。
「增加分配给每个词的标签数量,这个模拟多义词的因素的增长,也会增加小样本学习的成功几率。换言之,将有规律概况性难题的难度提高,反而让小样本学习的性能体现得更强大。」
同时,研究人员发现Transformer类神经网络AI的架构特点也有助于小样本学习。
作为对照组,研究人员测试了「一个原始无修饰的递归神经网络」,并发现这样的神经网络从来没有达到小样本学习的能力。
「与递归模型相比,Transformer类模型在小样本学习上体现出显著更高的优势」。
研究人员的结论是,数据的特性、诸如自然语言的长尾分布,和神经网络的性质、诸如Transformer类模型的架构特点,都在小样本学习中有重要作用。不只偏具一边,而是二者兼具。
作者列举了一些未来可以探索的途径。其中之一是与人类认知的联系,因为从婴儿期开始,人类就表现出小样本学习的能力。
例如,婴儿能迅速学习到自然语言的统计学分布特性。这些分布特征是可以帮助婴儿获得快速学习的能力,或者作为以后学习任务的预训练起作用?
而在其他如视觉等感官经验领域,类似的非统一性分布性质,是否也能在发育中发挥作用?
其实可以看出,此项研究并非一项只注重语言的研究。其实研究的目的是通过重现Omniglot图像视觉数据的非统一性,来模仿自然语言的应有统计特性。
研究人员没有解释从一种模态到另一种模态的转换,是否对此项研究的意义有任何影响。相反,研究人员称他们期望将研究工作扩展到自然语言的更多方面:
「如何与强化学习与监督学习损失互动?在复制语言建模和自然语言的其他方面的实验中,这些训练结果会有什么不同?」
需要注意的是,作者还在对论文进行修改和完善,刚才的这些应该只是一个初步的结论。
参考资料:
https://www.zdnet.com/article/deepmind-why-is-ai-so-good-at-language-its-something-in-language-itself/
https://arxiv.org/abs/2205.05055
![]()
![]()